Siempre queremos escribir código rápidamente, pero hay que pagarlo. En lenguajes flexibles de alto nivel, los programas se pueden desarrollar rápidamente, pero se ejecutan lentamente después del lanzamiento. Por ejemplo, es monstruosamente lento leer algo pesado en Python puro. Los lenguajes tipo C funcionan mucho más rápido, pero es más fácil cometer errores en ellos, cuya búsqueda reducirá toda la ganancia de velocidad a la nada.
Por lo general, este dilema se resuelve de la siguiente manera: primero escriben el prototipo en algo flexible, por ejemplo, en Python o R, y luego lo reescriben en C / C ++ o Fortran. Pero este ciclo es demasiado largo, ¿puedes prescindir de él?

Quizás haya una solución. Julia es un lenguaje de programación de alto nivel y flexible pero rápido. Julia tiene despacho múltiple, un compilador inteligente integrado y herramientas de metaprogramación.
Gleb Ivashkevich (
phtRaveller ), fundador de datarythmics, que desarrolla sistemas de aprendizaje automático para la industria y otras industrias, un ex físico, le contará más sobre lo que tiene Julia.
Gleb explicará por qué se necesitan nuevos lenguajes y por qué a veces falta Python. Él le dirá lo que es interesante en Julia, sobre sus fortalezas y debilidades, lo comparará con otros idiomas y le mostrará cuáles son las perspectivas del aprendizaje automático y la informática en general.
Descargo de responsabilidad. No habrá análisis sintáctico. Habrazhiteli experimentó desarrolladores, por lo que no tiene sentido mostrar cómo escribir un bucle, por ejemplo.El problema de dos idiomas.
Si escribe código rápidamente, los programas se ejecutan lentamente. Si los programas funcionan rápido, escríbalos durante mucho tiempo.
Python clásico cae en la primera categoría. Si elimina NumPy, considere algo en Python puro lentamente. Por otro lado, hay lenguajes como C y C ++. Es difícil encontrar un equilibrio, por lo que a menudo primero escriben un prototipo en algo flexible y, después de depurar el algoritmo, lo reescriben en el idioma más rápido. Este es un ejemplo de un
problema claro en dos idiomas : un ciclo largo cuando tiene que escribir en Python y reescribirlo en C o en Cython, por ejemplo.
Los especialistas en aprendizaje automático y ciencia de datos tienen NumPy, Sklearn, TensorFlow. Han estado resolviendo sus problemas durante años sin una sola línea en C, y parece que el problema de los dos lenguajes no les concierne. Esto no es así, el problema se manifiesta
implícitamente , porque el código en NumPy o en TensorFlow no es realmente Python. Se utiliza como metalenguaje para lanzar lo que hay dentro. Dentro hay exactamente C / Fortran (en el caso de NumPy) o C ++ (en el caso de TensorFlow).
Esta "característica" es poco visible, por ejemplo, en PyTorch, pero en Numpy es claramente visible. Por ejemplo, si un ciclo clásico de Python apareció en los cálculos, entonces algo salió mal. En el código productivo, no se necesitan bucles; debe reescribir todo para que NumPy pueda vectorizarlo y calcularlo rápidamente.
Al mismo tiempo, a muchos les parece que NumPy es rápido y que todo está bien. Veamos qué tiene NumPy debajo del capó para ver esto.
- NumPy está tratando de solucionar el problema de flexibilidad de tipo Python, por lo que tiene un sistema de tipo bastante estricto . Si la matriz tiene un cierto tipo, entonces no puede haber nada más; si
Float64 está Float64 , no se puede hacer nada al respecto. - Despacho. Dependiendo de los tipos de matrices y de la operación que necesita realizar, NumPy dentro de sí mismo decidirá a qué función llamar para hacer los cálculos lo más rápido posible. La biblioteca intentará sacar Python clásico del ciclo de cálculo.
Resulta que Numpy no es tan rápido como parece. Por eso hay proyectos como
Cython o
Numba . El primero genera código C a partir del "híbrido" de Python y C, y el segundo compila el código en Python y, por lo general, esto es más rápido.
Si NumPy fuera realmente tan rápido como parece para muchos, entonces la existencia de Cython y Numba no tendría sentido.
Reescribimos todo en Cython si queremos encontrar rápidamente algo grande y complejo. Uno de los criterios para la calidad de un contenedor en Cython es la presencia o ausencia de llamadas puras de Python en el código generado.
Un ejemplo simple: agregamos el tipo (bueno) o no agregamos (malo), y obtenemos dos códigos completamente diferentes, aunque además de los tipos, las opciones iniciales no son diferentes.

Cuando generamos el código C, en el primer caso obtenemos lo siguiente:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
Y en el segundo
result =0. se convertirá en esto:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
Cuando se especifica un tipo, el código C se ejecuta a la velocidad del rayo. Si no se especifica el tipo, vemos Python normal, pero desde el lado C: llamadas estándar de Python, donde por alguna razón se crean
float desde el
double , se cuentan los enlaces y muchos otros códigos basura. Este código es lento porque llama a Python para cada operación.
¿Es posible resolver todos los problemas a la vez?
Es curioso que cuando pensamos en algo, tratamos de eliminar Python puro. Hay dos opciones sobre cómo hacer esto.
- Usando Cython u otras herramientas. Hay muchas maneras en que puede optimizar su código de Cython para terminar casi sin llamadas de Python. Pero esta no es la actividad más agradable: no todo es tan obvio en Cython, y solo se gasta un poco menos de tiempo que si solo escribe todo en C. El módulo resultante se puede usar en Python, pero aún así lleva mucho tiempo, se producen errores, el código no siempre es obvio y no siempre está claro cómo optimizarlo.
- Usando Numba, que hace una compilación JIT .
Pero tal vez hay una mejor manera, y creo que esta es
Julia .
Julia
Los creadores afirman que este es un lenguaje
rápido , de
alto nivel y
flexible , que es comparable a Python en términos de facilidad para escribir código. En mi opinión, Julia es como un
lenguaje de script: no necesita hacer lo que tiene que hacer en C, donde todo es de muy bajo nivel, incluidas las estructuras de datos. Al mismo tiempo, puede trabajar en una consola normal, como Python y otros idiomas.
Julia usa
la compilación Just-In-Time : este es uno de los elementos que le da velocidad. Pero el lenguaje es bueno con los cálculos, porque fue desarrollado para ellos. Julia se utiliza para tareas científicas y obtener un rendimiento decente.
Aunque Julia está tratando de parecer un lenguaje de propósito general, Julia es buena para la informática y no muy buena para los servicios web. Usar Julia en lugar de Django, por ejemplo, no es la mejor opción.
Veamos las características del lenguaje como un ejemplo de una función primitiva.
function f(x) α = 1 + 2x end julia> methods(f)
Cuatro características son notables en este código.
- Prácticamente no hay restricciones para usar Unicode . Puede tomar fórmulas de un artículo sobre aprendizaje profundo o modelado numérico, reescribir con los mismos caracteres y todo funcionará: Unicode está cosido en casi todas partes.
- No hay signo de multiplicación. Sin embargo, no siempre es posible prescindir de él, por ejemplo, en 2.x (un número de coma flotante multiplicado por x) que Julia jurará.
- Sin
return En general, se recomienda que escriba return para poder ver lo que está sucediendo, pero el ejemplo devolverá α , porque la asignación es una expresión. - No tipos Parecería que si hay velocidad, ¿en algún momento deberían aparecer los tipos? Sí, aparecerán, pero más tarde.
Julia tiene tres características que dan flexibilidad y velocidad:
despacho múltiple, metaprogramación y paralelismo . Hablaremos de los dos primeros, y dejaremos la paralelización para un estudio independiente para usuarios avanzados.
Programación múltiple
La llamada a los
methods(f) en el ejemplo anterior se ve inesperadamente: ¿qué tipo de métodos tiene la función? Estamos acostumbrados al hecho de que tenemos objetos de clase, las clases tienen métodos. Pero en Julia todo se da vuelta al revés: las funciones tienen métodos, porque el lenguaje usa el despacho múltiple.
La programación múltiple significa que la variante de una función particular que se ejecutará está determinada por todo el conjunto de tipos de parámetros de esta función.
Describiré brevemente cómo funciona esto en un ejemplo ya familiar.
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
Las variantes de la misma función para diferentes conjuntos de tipos se denominan métodos. Hay dos en el código: el primero para todos los números de coma flotante y el segundo para todo lo demás. Cuando llamamos por primera vez a la función, Julia decidirá qué método usar y si debe compilarlo. Si ya ha sido llamado y compilado, tomará el que es.
Dado que en Julia todo no es como estamos acostumbrados, aquí puede agregar funciones a los tipos definidos por el usuario, pero estos no serán métodos de tipo en el sentido de OOP. Simplemente será el campo en el que se escribe la función, porque la
función es el mismo objeto completo que todo lo demás.
Para saber qué se activará exactamente, hay macros especiales. Comienzan con
@ . En el ejemplo, la macro
@which permite averiguar qué método se llamó para un caso específico.

En el primer caso, Julia decidió que dado que 2 es un número entero, no encaja en
AbstractFloat , y llamó a la primera opción. En el segundo caso, decidió que era
Float y ya había pedido una versión especializada. Aproximadamente esto funcionará si agrega otros métodos para algunos tipos específicos.
LLVM y JIT
Julia usa el marco LLVM para compilar. La biblioteca de compilación JIT viene en un paquete de idiomas. La primera vez que se llama a la función, Julia busca si la función se ha utilizado con este conjunto de tipos y la compila si es necesario. El primer lanzamiento llevará algún tiempo, y luego todo funcionará rápidamente.
La función se compilará en el momento de la primera llamada para este conjunto de parámetros.
Características del compilador
- El compilador es razonablemente razonable porque LLVM es un buen producto.
- Los desarrolladores más avanzados pueden analizar el proceso de compilación y ver qué genera.
- La compilación de Julia y Numba son similares . En Numba, también crea un decorador JIT, pero en Numba no puede "entrar" tanto y decidir qué optimizar o cambiar.
Para ilustrar el trabajo del compilador, daré un ejemplo de una función simple:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
La macro
@code_llvm permite ver el resultado de la generación. Este
LLVM IR es
una representación intermedia , una especie de ensamblador.
En el código, el argumento de la función se multiplica por 3, se agrega 1 al resultado, se devuelve el resultado. Todo es lo más sencillo posible. Si define la función un poco diferente, por ejemplo, reemplace 3 con 2, entonces todo cambiará.
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
Parecería, ¿cuál es la diferencia: 2, 3, 10? Pero Julia y LLVM ven que cuando llamas a una función para un entero, puedes hacerlo un poco más inteligente. Multiplicar por dos un número entero es un desplazamiento a la izquierda por un bit: es más rápido que el producto. Pero, por supuesto, esto solo funciona para enteros, no funcionará desplazar
Float izquierda por 1 bit y obtener el resultado de multiplicar por 2.
Tipos personalizados
Los tipos personalizados en Julia son tan rápidos como los tipos integrados. Se realiza una programación múltiple en ellos, y será tan rápido como para los tipos incorporados. En este sentido, el mecanismo de despacho múltiple está profundamente incrustado en el lenguaje.
Es lógico esperar que las variables no tengan tipos, solo los valores las tienen. Las variables sin tipo son solo un marcador, una etiqueta en algún contenedor.
El sistema de tipos es jerárquico. No podemos crear descendientes de tipos concretos; los tipos abstractos solo pueden tenerlos. Sin embargo, los tipos abstractos no pueden ser instanciados. Este matiz no será de interés para todos.
Como explicaron los autores del lenguaje cuando desarrollaron a Julia, querían obtener el resultado, y si algo era difícil de hacer, lo rechazaron. Tal sistema de tipo jerárquico fue más fácil de desarrollar. Este no es un problema catastrófico, pero si no vuelves la cabeza al principio, será un inconveniente.
Los tipos se pueden parametrizar , que es un poco como C / C ++. Por ejemplo, podemos tener una estructura dentro de la cual hay campos, pero los tipos de estos campos no están especificados: estos son parámetros. Especificamos un tipo específico en la instanciación.
En la mayoría de los casos, los tipos se pueden omitir . Por lo general, son necesarios cuando el tipo ayuda al compilador a adivinar la mejor forma de compilar. En este caso, es mejor especificar los tipos. También debe especificar tipos si desea lograr un mejor rendimiento.
Veamos qué es posible y qué no se puede instanciar.

El primer tipo de
AbstractPoint no puede ser instanciado. Este es solo un padre común para todos que podemos especificar en los métodos, por ejemplo. La segunda línea dice que
PlanarPoint{T} es un descendiente de este punto abstracto. Debajo de los campos comienzan, aquí puede ver la parametrización. Puede poner un
float ,
int u otro tipo aquí.
El primer tipo no puede ser instanciado, y para todo lo demás es imposible crear descendientes. Además, por defecto son
inmutables . Para poder cambiar los campos, esto debe especificarse explícitamente.
Cuando todo esté listo, puede continuar, por ejemplo, calcular la distancia para diferentes tipos de puntos. En el ejemplo, el primer punto en el plano es
PlanarPoint , luego en la esfera y en el cilindro. Dependiendo de los dos puntos entre los que calculamos la distancia, necesitamos usar diferentes métodos. En general, la función se verá así:
function describe(p::AbstractPoint) println("Point instance: $p") end
Para
Float64 ,
Float32 ,
Float16 será:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
Y para los enteros, el método de cálculo de distancia se verá así:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
Para los puntos de cada tipo, se llamarán diferentes métodos.
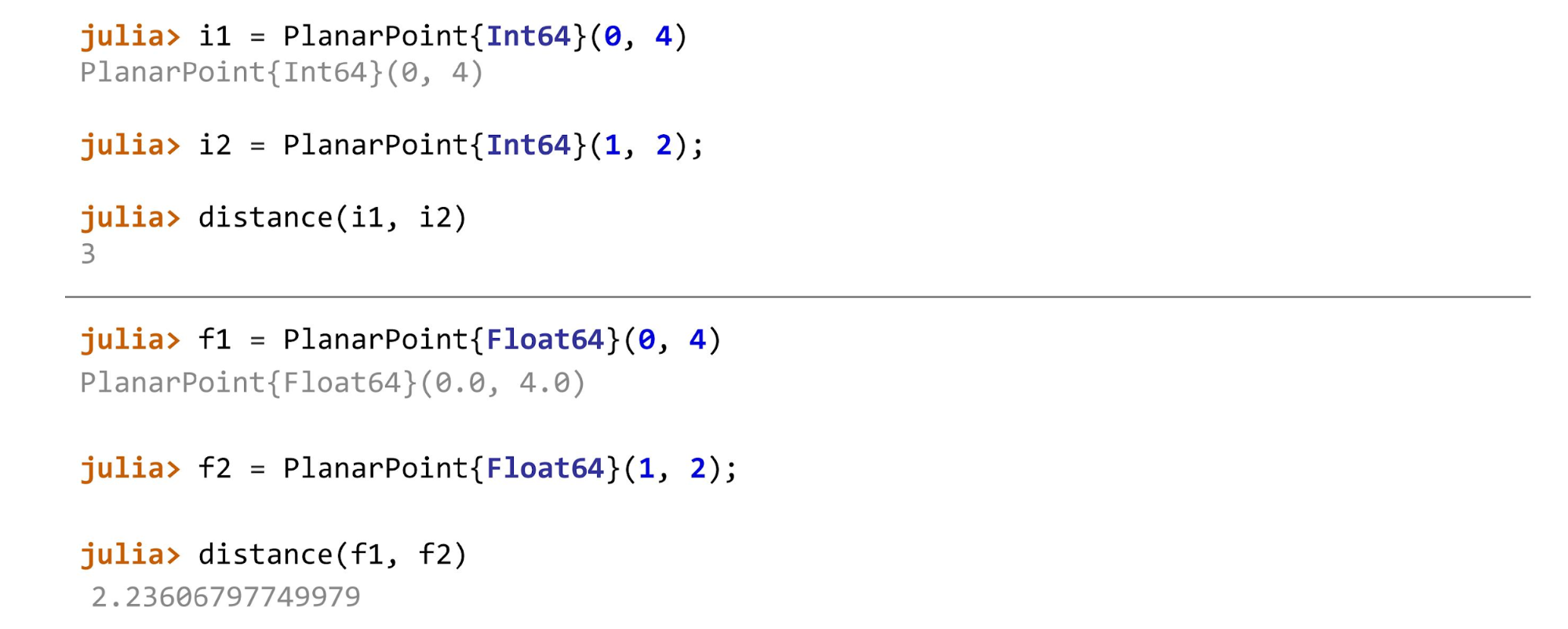
Si hace trampa y, por ejemplo, aplica
distance(f1, i2) , Julia jurará: “¡No conozco este método! Me preguntaste tales métodos y dijiste que ambos son del mismo tipo. No me dijiste cómo contar esto cuando un parámetro es
float y el otro es
int ".
Velocidad
Es posible que ya haya estado encantado: “Hay una compilación JIT: escribir es fácil, funcionará rápidamente. ¡Tira a Python y comienza a escribir en Julia!
Pero no tan simple. No todas las características de Julia serán rápidas. Depende de dos factores.
- Del desarrollador . No hay idiomas en los que ninguna función sea rápida. Un desarrollador inexperto incluso escribirá código en C que funcionará mucho más lentamente que el código Python de un desarrollador experimentado. Cualquier idioma tiene sus propios trucos y matices de los que depende el rendimiento. El compilador, ya sea un estático regular o un JIT, no puede proporcionar todas las opciones imaginables y optimizar todo en absoluto.
- De tipo estabilidad . En una versión más rápida, se compilarán las funciones que son estables por tipo.
Estabilidad tipo
¿Qué es la estabilidad de tipo? Cuando el compilador no puede adivinar de manera suficientemente confiable lo que sucede con los tipos, tiene que generar mucho código envoltorio para que todo lo que llegue a la entrada funcione.
Un ejemplo simple para entender la estabilidad de tipos.

Los especialistas en aprendizaje automático dirán que esta es una activación de relu normal: si x> 0, devuélvelo como está, de lo contrario, devuelve cero. Un problema es el cero después del entero de signo de interrogación. Esto significa que si llamamos a esta función para un número de punto flotante, en un caso, se devolverá un número de punto flotante y, en el otro, un número entero.
El compilador no puede adivinar el tipo de resultado solo por el tipo de argumento de función. Él también necesita saber el significado. Por lo tanto, genera mucho código.
Luego, creamos una matriz de 100 por 100 números aleatorios de 0 a 1, la cambiamos por 0.5 para distribuir uniformemente los números positivos y negativos, y medimos el resultado. Hay dos puntos interesantes: el punto y la función. El punto después de
rand(100,100) significa "aplicar a cada elemento". Si tienes algún tipo de colección y función escalar, ponle fin, y Julia hará el resto. Podemos suponer que esto es tan efectivo como un bucle normal en un lenguaje compilado normal. No hay necesidad de escribir, todo se hará por usted.
No hay problemas en este momento: el
problema está dentro de la función misma . El tiempo de ejecución estimado de tal opción en una computadora decente para dicha matriz es de microsegundos. Pero en realidad, milisegundos, que es demasiado para una matriz tan pequeña.
Cambia solo una línea.

La función
zero(x) ejecuta genera un cero del mismo tipo que el argumento
(x) . Esto significa que no importa cuál sea el valor de
x , el tipo de resultado siempre será conocido por el tipo de
x sí.
Cuando miramos solo el tipo de argumentos y ya conocemos el tipo de resultado, estas son funciones que son de tipo estable.
Si necesitamos ver el significado de los argumentos, estas no son funciones estables.
Cuando el compilador puede optimizar el código, la diferencia en el tiempo de ejecución se obtiene en dos órdenes de magnitud. En el segundo ejemplo, solo se asignó exactamente a una nueva matriz, un par más de decenas de bytes y nada más. Esta opción es mucho más efectiva que la anterior.
Esto es lo principal a tener en cuenta cuando escribimos código en Julia. Si escribe como en Python, funcionará como en Python. Si realiza las mismas operaciones en NumPy, entonces cero con o sin un punto no juega un papel. Pero en Julia, esto puede socavar en gran medida el rendimiento.
Afortunadamente, hay un método para averiguar si existe un problema. Esta es la macro
@code_warntype , que le permite averiguar si el compilador puede adivinar dónde están los tipos y optimizar si todo está bien.

En la primera opción (izquierda), el compilador no está seguro del tipo y lo muestra en rojo. En el segundo caso, siempre habrá
Float64 para tal argumento, por lo que puede generar código mucho más corto.
Esto todavía no es LLVM, pero el código de Julia etiquetado,
return 0 o
return 0.0 da una diferencia de rendimiento de dos órdenes de magnitud.
Metaprogramación
La metaprogramación es cuando creamos programas en un programa y los ejecutamos sobre la marcha.
Este es un método poderoso que le permite hacer muchas cosas interesantes diferentes. Un ejemplo clásico es Django ORM, que crea campos utilizando metaclases.
Mucha gente conoce el descargo de responsabilidad de
Tim Peters , autor de Zen of Python:
“Las metaclases son una magia más profunda de la que el 99% de los usuarios nunca deberían preocuparse. Si se pregunta si se necesitan metaclases en Python, no las necesita. Si los necesita, entonces sabe exactamente por qué y cómo usarlos ".
Con la metaprogramación, la situación es similar, pero en Julia se cose mucho más profundo, esta es una característica importante de todo el lenguaje. El código de Julia tiene la misma estructura de datos que cualquier otro, puede manipular, combinar, crear expresiones, y todo esto funcionará.
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
Las macros son una de las herramientas de metaprogramación en Julia : les damos algo, miran, agregan la correcta, eliminan lo innecesario y dan el resultado. En todos los ejemplos anteriores, pasamos la llamada a la función, y la macro dentro analizó la llamada. Todo esto sucede al nivel de trabajar con el árbol de sintaxis.
Puede analizar expresiones muy simples: si es, por ejemplo,
(x+1) , esta es una llamada a la función
+ (la suma no es un operador, como en muchos otros idiomas, sino una función) y dos argumentos: un carácter (dos puntos significa que es un carácter ), y el segundo es solo una constante.
Otro ejemplo macro simple:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
Utilizando macros, por ejemplo, se crean indicadores de progreso o filtros para marcos de datos; este es un mecanismo común en Julia.
Las macros no se ejecutan en el momento de la llamada, sino al analizar el código.
Esta es la principal característica macro en Julia. - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
Ecosistema
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.