Hemos desarrollado un diseño de una red de centros de datos, que le permite implementar clústeres informáticos de más de 100 mil servidores con un ancho de banda de bisección de más de un petabit por segundo.
A partir del informe de Dmitry Afanasyev, aprenderá sobre los principios básicos del nuevo diseño, el escalado de topologías que surgen con estos problemas, las opciones para resolverlos, sobre las características de enrutamiento y escalado de las funciones del plano de reenvío de dispositivos de red modernos en topologías densamente conectadas con una gran cantidad de rutas ECMP . Además, Dima habló brevemente sobre la organización de la conectividad externa, el nivel físico, el sistema de cable y las formas de aumentar aún más la capacidad.

- Buenas tardes a todos! Mi nombre es Dmitry Afanasyev, soy arquitecto de redes de Yandex y me encargo principalmente del diseño de redes de centros de datos.

Mi historia será sobre la red actualizada del centro de datos de Yandex. Esto es en gran medida una evolución del diseño que teníamos, pero al mismo tiempo hay algunos elementos nuevos. Esta es una presentación de revisión, ya que era necesario incluir mucha información en poco tiempo. Comenzamos eligiendo una topología lógica. Luego habrá una visión general del plano de control y problemas con la escalabilidad del plano de datos, la elección de lo que sucederá en el nivel físico, veamos algunas características de los dispositivos. También tocaremos lo que está sucediendo en el centro de datos con MPLS, del que hablamos hace algún tiempo.

Entonces, ¿qué es Yandex en términos de cargas de trabajo y servicios? Yandex es un hiperescalador típico. Si mira en la dirección de los usuarios, procesamos principalmente las solicitudes de los usuarios. Además, varios servicios de transmisión y salida de datos, porque también tenemos servicios de almacenamiento. Si está más cerca del backend, entonces aparecen cargas de infraestructura y servicios, como almacenes de objetos distribuidos, replicación de datos y, por supuesto, colas persistentes. Uno de los principales tipos de cargas es MapReduce y similares, procesamiento de transmisión, aprendizaje automático, etc.

¿Cómo es la infraestructura sobre la cual sucede todo esto? Una vez más, somos un hiperskaler muy típico, aunque quizás estamos un poco más cerca del lado del espectro donde se encuentran los hiperskalers más pequeños. Pero tenemos todos los atributos. Utilizamos hardware básico y escalado horizontal siempre que sea posible. Tenemos un crecimiento completo de la agrupación de recursos: no trabajamos con máquinas separadas, bastidores separados, sino que los combinamos en un gran grupo de recursos intercambiables con algunos servicios adicionales que se dedican a la planificación y asignación, y trabajamos con todo este grupo.
Entonces tenemos el siguiente nivel: el clúster informático a nivel del sistema operativo. Es muy importante que controlemos completamente la pila de tecnología que utilizamos. Controlamos los puntos finales (hosts), la red y la pila de software.
Tenemos varios grandes centros de datos en Rusia y en el extranjero. Están unidos por una columna vertebral que utiliza la tecnología MPLS. Nuestra infraestructura interna se basa casi por completo en IPv6, pero dado que necesitamos manejar el tráfico externo, que aún se entrega principalmente a través de IPv4, necesitamos entregar de alguna manera las solicitudes que llegan a través de IPv4 a los servidores front-end, y todavía ir un poco a IPv4 externo. Internet, por ejemplo, para indexar.
Las últimas iteraciones del diseño de la red del centro de datos utilizan topologías Clos de varios niveles, y solo se utiliza L3 en ellas. Salimos de L2 hace algún tiempo y soltamos un suspiro de alivio. Finalmente, nuestra infraestructura incluye cientos de miles de instancias de computación (servidor). El tamaño máximo del clúster hace algún tiempo era de unos 10 mil servidores. Esto se debe en gran medida a cómo pueden funcionar los mismos sistemas operativos a nivel de clúster: programadores, asignación de recursos, etc. Como el progreso ha ocurrido en el lado del software de infraestructura, ahora el objetivo es de aproximadamente 100 mil servidores en un clúster informático, y teníamos una tarea: poder construir fábricas de redes que permitan la agrupación eficiente de recursos en dicho grupo.

¿Qué queremos de una red de centros de datos? En primer lugar, una gran cantidad de ancho de banda barato y bastante uniformemente distribuido. Porque la red es ese sustrato a través del cual podemos agrupar recursos. El nuevo tamaño objetivo es de aproximadamente 100 mil servidores en un clúster.
Además, por supuesto, queremos un plano de control escalable y estable, porque en una infraestructura tan grande surgen muchos dolores de cabeza incluso por eventos aleatorios, y no queremos que el plano de control nos cause dolor de cabeza. Al mismo tiempo, queremos minimizar el estado en el mismo. Cuanto más pequeña es la condición, mejor y más estable todo funciona, es más fácil de diagnosticar.
Por supuesto, necesitamos automatización, porque es imposible administrar dicha infraestructura manualmente, y fue imposible hace algún tiempo. Siempre que sea posible, necesitamos apoyo operativo y CI / CD en la medida de lo posible.
Con tales tamaños de centros de datos y clústeres, la tarea de soportar la implementación y expansión incrementales sin interrupción del servicio se ha vuelto bastante aguda. Si en grupos el tamaño de mil automóviles es probablemente cercano a diez mil automóviles, aún podrían desplegarse como una sola operación, es decir, estamos planeando expandir la infraestructura y se agregan varios miles de máquinas como una sola operación, entonces no surge un grupo del tamaño de cien mil automóviles solo así, ha sido construido por algún tiempo. Y es deseable que todo este tiempo lo que ya se ha bombeado, la infraestructura que se implementa, esté disponible.
Y un requisito que teníamos y dejamos: este es el soporte para multitenancy, es decir, virtualización o segmentación de red. Ahora no necesitamos hacer esto en el nivel de fábrica de la red, porque la segmentación se dirigió a los hosts, y esto nos facilitó el escalado. Gracias a IPv6 y un gran espacio de direcciones, no necesitábamos usar direcciones duplicadas en la infraestructura interna, todas las direcciones ya eran únicas. Y debido al hecho de que llevamos el filtrado y la segmentación de red a los hosts, no necesitamos crear ninguna entidad de red virtual en las redes de centros de datos.

Una cosa muy importante es que no necesitamos. Si se pueden eliminar algunas funciones de la red, esto simplifica enormemente la vida y, por regla general, amplía la elección del hardware y software disponibles, y simplifica enormemente los diagnósticos.
Entonces, ¿qué no necesitamos, qué pudimos rechazar, no siempre con alegría en el momento en que esto sucedió, pero con gran alivio, cuando se completó el proceso?
En primer lugar, el rechazo de L2. No necesitamos L2 ni real ni emulado. No se utiliza en gran medida debido al hecho de que controlamos la pila de aplicaciones. Nuestras aplicaciones se escalan horizontalmente, funcionan con direccionamiento L3, no se preocupan realmente de que se haya presentado alguna instancia en particular, simplemente implementan una nueva, no es necesario implementarla en la dirección anterior, porque hay un nivel separado de descubrimiento de servicio y monitoreo de máquinas ubicadas en el clúster . No cambiamos esta tarea a la red. La tarea de la red es entregar paquetes del punto A al punto B.
Además, no tenemos situaciones en las que las direcciones se muevan dentro de la red, y esto debe ser monitoreado. En muchos diseños, esto generalmente es necesario para soportar la movilidad de VM. No utilizamos la movilidad de las máquinas virtuales en la infraestructura interna de exactamente el gran Yandex y, además, creemos que, incluso si esto se hace, esto no debería suceder con el soporte de red. Si realmente necesita hacer esto, debe hacerlo a nivel de host y dirigir las direcciones que pueden migrar a superposiciones para no tocar o hacer demasiados cambios dinámicos en el sistema de enrutamiento (red de transporte).
Otra tecnología que no usamos es la multidifusión. Te puedo decir en detalle por qué. Esto hace la vida mucho más fácil, porque si alguien trata con él y observa cómo es exactamente el plano de control de una multidifusión, en todas las instalaciones, excepto en la más simple, es un gran dolor de cabeza. Y lo que es más, es difícil encontrar una implementación de código abierto que funcione bien, por ejemplo.
Finalmente, diseñamos nuestras redes para que no tengan demasiados cambios. Podemos contar con el hecho de que el flujo de eventos externos en el sistema de enrutamiento es pequeño.

¿Qué problemas surgen y qué limitaciones deben tenerse en cuenta cuando desarrollamos una red de centros de datos? Costo por supuesto. Escalabilidad, a qué nivel queremos crecer. La necesidad de expansión sin detener el servicio. Disponibilidad de ancho de banda. La visibilidad de lo que está sucediendo en la red, para los sistemas de monitoreo, para los equipos operativos. El soporte para la automatización es, de nuevo, tanto como sea posible, ya que se pueden resolver diferentes tareas en diferentes niveles, incluida la introducción de capas adicionales. Bueno y no, [siempre que sea posible], dependencia de los vendedores. Aunque en diferentes períodos históricos, dependiendo de qué sección mirar, esta independencia fue más fácil o más difícil de lograr. Si tomamos una porción de los chips de los dispositivos de red, hasta hace poco, hablamos de independencia de los proveedores, si también quisiéramos chips con alto rendimiento, podría ser muy arbitrario.

¿Qué topología lógica usaremos para construir nuestra red? Este será un Clos de varios niveles. De hecho, actualmente no hay alternativas reales. Y la topología de Clos es lo suficientemente buena, incluso si la comparamos con varias topologías avanzadas que ahora están más en el ámbito de interés académico, si tenemos conmutadores con una gran raíz.
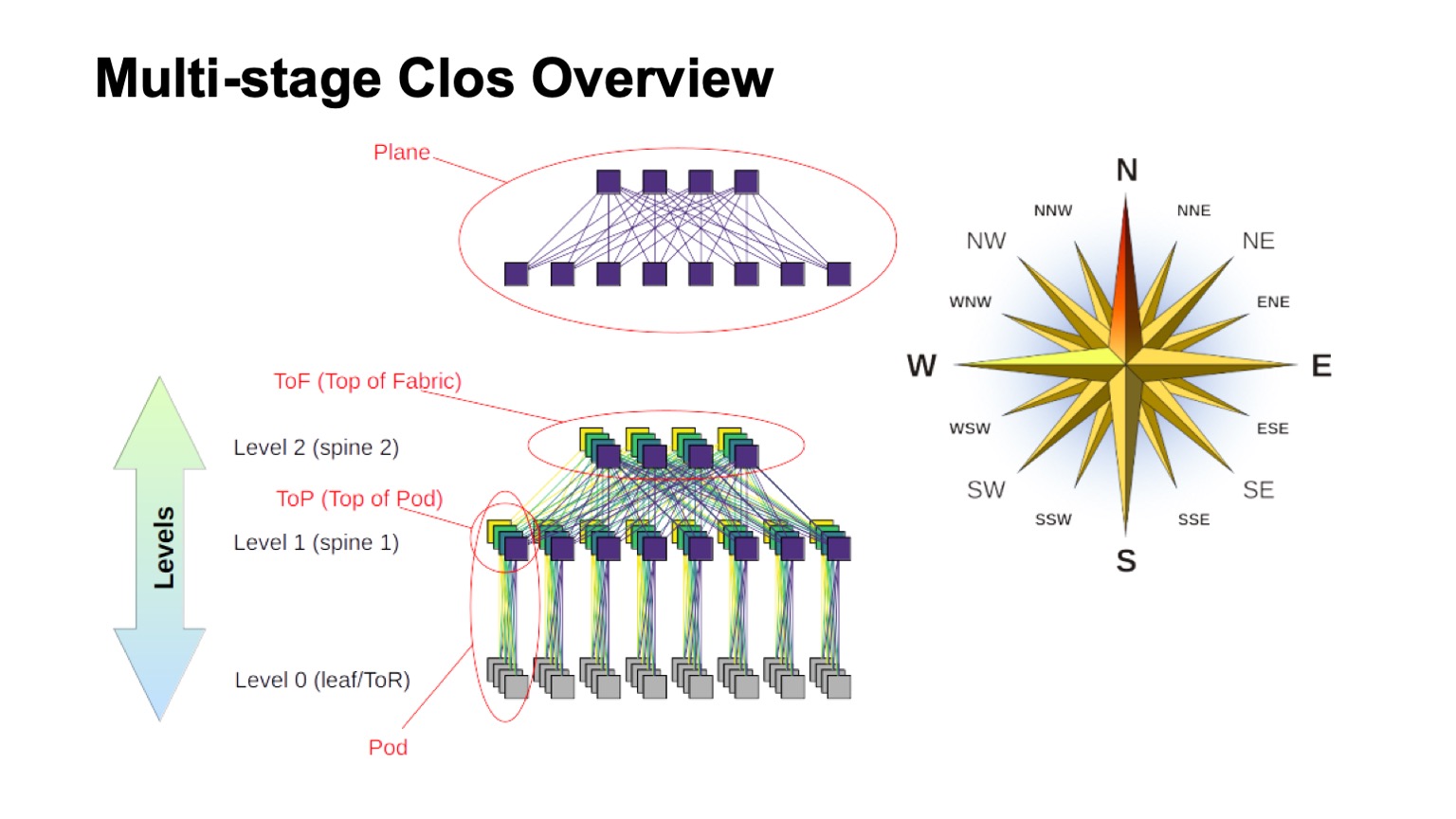
¿Cómo está estructurada la red Clos en capas y cómo se llaman los diferentes elementos en ella? En primer lugar, se levantó el viento para descubrir dónde estaba el norte, dónde estaba el sur, dónde estaba el este, dónde estaba el oeste. Las redes de este tipo generalmente son construidas por aquellos que tienen un tráfico muy grande de oeste a este. En cuanto al resto de los elementos, en la parte superior se muestra un conmutador virtual ensamblado a partir de conmutadores más pequeños. Esta es la idea básica de construir recursivamente redes Clos. Tomamos elementos con algún tipo de raíz y los conectamos para que lo que sucedió pueda considerarse como un interruptor con una raíz más grande. Si necesita aún más, el procedimiento puede repetirse.
En casos, por ejemplo, con Clos de dos niveles, cuando es posible distinguir claramente los componentes que son verticales en mi diagrama, generalmente se denominan planos. Si construimos Clos-con tres niveles de interruptores de columna (todos los que no están en el límite y no son interruptores ToR y que se usan solo para el tránsito), entonces los aviones se verían más complicados, un aspecto de dos niveles como ese. El bloque de ToR o interruptores de hoja y los interruptores de columna asociados de primer nivel que llamamos Pod. Los interruptores de nivel 1 de la columna vertebral en la parte superior del Pod son la parte superior del Pod, la parte superior del Pod. Los interruptores que se encuentran en la parte superior de toda la fábrica son la capa superior de la fábrica, la parte superior de la tela.

Por supuesto, surge la pregunta: las redes de cierre se han construido durante algún tiempo, la idea en sí misma generalmente proviene de los días de la telefonía clásica, las redes TDM. Tal vez algo mejor apareció, tal vez puedes hacer algo mejor de alguna manera? Si y no Teóricamente, sí, en la práctica, en el futuro cercano, definitivamente no. Debido a que hay una serie de topologías interesantes, algunas de ellas incluso se usan en la producción, por ejemplo, Dragonfly se usa en aplicaciones HPC; También hay topologías interesantes como Xpander, FatClique, Jellyfish. Si observa informes en conferencias como SIGCOMM o NSDI en los últimos tiempos, puede encontrar una cantidad bastante grande de documentos sobre topologías alternativas que tienen mejores propiedades (una u otra) que Clos.
Pero todas estas topologías tienen una propiedad interesante. Impide su implementación en las redes de centros de datos, que estamos tratando de construir sobre hardware básico y que cuestan dinero razonablemente razonable. En todas estas topologías alternativas, desafortunadamente, la mayoría de la banda no es accesible a través de los caminos más cortos. Por lo tanto, perdemos de inmediato la capacidad de usar el plano de control tradicional.
Teóricamente, se conoce la solución al problema. Estas son, por ejemplo, modificaciones del estado del enlace utilizando la ruta k-más corta, pero, nuevamente, no hay protocolos que se implementarían en producción y que estuvieran disponibles de forma masiva en los equipos.
Además, dado que la mayor parte de la capacidad no es accesible a través de las rutas más cortas, necesitamos modificar no solo el plano de control para que seleccione todas estas rutas (y, por cierto, este es un estado mucho más grande en el plano de control). Todavía necesitamos modificar el plano de reenvío y, como regla, se requieren al menos dos características adicionales. Esta es una oportunidad para tomar todas las decisiones sobre el reenvío de paquetes una vez, por ejemplo, en un host. Esto es en realidad el enrutamiento de origen, a veces en la literatura sobre redes de interconexión se llama decisiones de reenvío todo a la vez. Y el enrutamiento adaptativo ya es una función que necesitamos en los elementos de la red, que se reduce, por ejemplo, al hecho de que seleccionamos el siguiente salto en función de la información sobre la menor carga en la cola. Como ejemplo, otras opciones son posibles.
Por lo tanto, la dirección es interesante, pero, por desgracia, no podemos aplicarla en este momento.

Bien, se decidió por la topología lógica de Clos. ¿Cómo lo escalaremos? Veamos cómo funciona y qué se puede hacer.

En la red Clos hay dos parámetros principales que de alguna manera podemos variar y obtener ciertos resultados: elementos de la raíz y el número de niveles en la red. Describo esquemáticamente cómo uno y el otro afectan el tamaño. Idealmente, combinamos ambos.
Se puede ver que el ancho total de la red Clos es un producto de todos los niveles de interruptores de columna vertebral de la raíz sur, cuántos enlaces tenemos hacia abajo, cómo se ramifica. Así es como escalamos el tamaño de la red.
En cuanto a la capacidad, especialmente en los conmutadores ToR, hay dos opciones de escala. O podemos, manteniendo la topología general, usar enlaces más rápidos, o podemos agregar más planos.
Si observa la versión detallada de la red Clos (en la esquina inferior derecha) y vuelve a esta imagen con la red Clos a continuación ...
... entonces esta es exactamente la misma topología, pero en esta diapositiva se contrae de manera más compacta y los planos de fábrica se superponen entre sí. Es uno y lo mismo.

¿Cómo se ve escalar una red Clos en números? Aquí tengo datos sobre qué ancho máximo puede obtener una red, qué número máximo de bastidores, conmutadores ToR o conmutadores de hoja, si no están en bastidores, podemos obtener dependiendo de qué raíz de conmutadores usamos para las espinas niveles y cuántos niveles usamos.
Muestra cuántos racks podemos tener, cuántos servidores y cuánto puede consumir todo esto a razón de 20 kW por rack. Un poco antes, mencioné que apuntamos a un tamaño de clúster de aproximadamente 100 mil servidores.
Se puede ver que en toda esta construcción son interesantes dos opciones y media. Hay una opción con dos capas de espinas y conmutadores de 64 puertos, que es un poco corta. Luego, opciones de ajuste perfecto para conmutadores de columna de 128 puertos (con 128 radix) con dos niveles, o conmutadores con 32 radix con tres niveles. Y en todos los casos donde hay más radix y más niveles, puede hacer una red muy grande, pero si observa el consumo esperado, por regla general, hay gigavatios. Puede tender el cable, pero es poco probable que obtengamos tanta electricidad en un sitio. Si observa estadísticas, datos públicos sobre centros de datos, se pueden encontrar muy pocos centros de datos para una capacidad estimada de más de 150 MW. Además, por lo general, los campus de centros de datos, varios centros de datos grandes ubicados bastante cerca uno del otro.
Hay otro parámetro importante. Si observa la columna izquierda, el ancho de banda utilizable se indica allí. Es fácil notar que en una red Clos, una parte importante de los puertos se gasta en conectar los conmutadores entre sí. El ancho de banda utilizable es lo que puede dar, hacia los servidores. Naturalmente, estoy hablando de puertos condicionales y de la franja. Como regla general, los enlaces dentro de la red son más rápidos que los enlaces hacia los servidores, pero por unidad de banda, en la medida en que podemos entregarlo a nuestro equipo de servidor, todavía hay algunas bandas más dentro de la red misma. Y cuantos más niveles hagamos, mayores serán los costos unitarios para proporcionar esta tira al exterior.
Además, incluso esta banda extra no es exactamente la misma. Si bien los tramos son cortos, podemos usar algo como DAC (cobre de conexión directa, es decir, cables twinax) u óptica multimodo, que cuestan dinero aún más o menos razonable. Tan pronto como cambiemos a tramos más auténticos, como regla general, se trata de una óptica de modo único, y el costo de esta banda adicional aumenta notablemente.
Y nuevamente, volviendo a la diapositiva anterior, si hacemos una red Clos sin volver a suscribirnos, entonces es fácil mirar el diagrama, ver cómo se construye la red: agregando cada nivel de interruptores de columna, repetimos toda la tira que estaba debajo. Nivel plus: más toda la misma banda, la misma cantidad de puertos en los conmutadores que en el nivel anterior, la misma cantidad de transceptores. Por lo tanto, el número de niveles de interruptores de columna es muy deseable para minimizar.
Con base en esta imagen, está claro que realmente queremos construir sobre algo como interruptores con una raíz de 128.

Aquí, en principio, todo es lo mismo que acabo de decir, es más probable que esta diapositiva se considere más adelante.

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
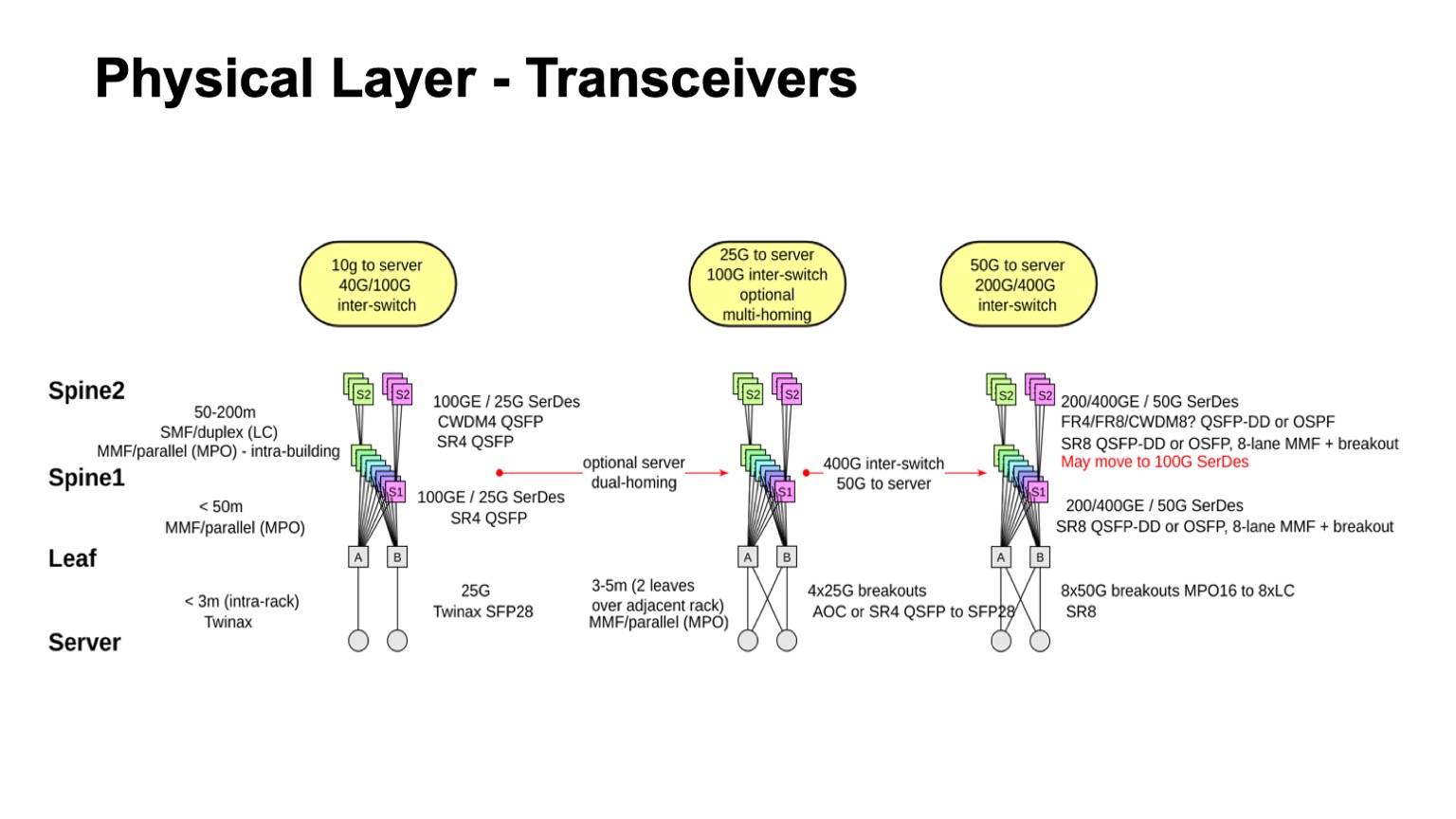
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
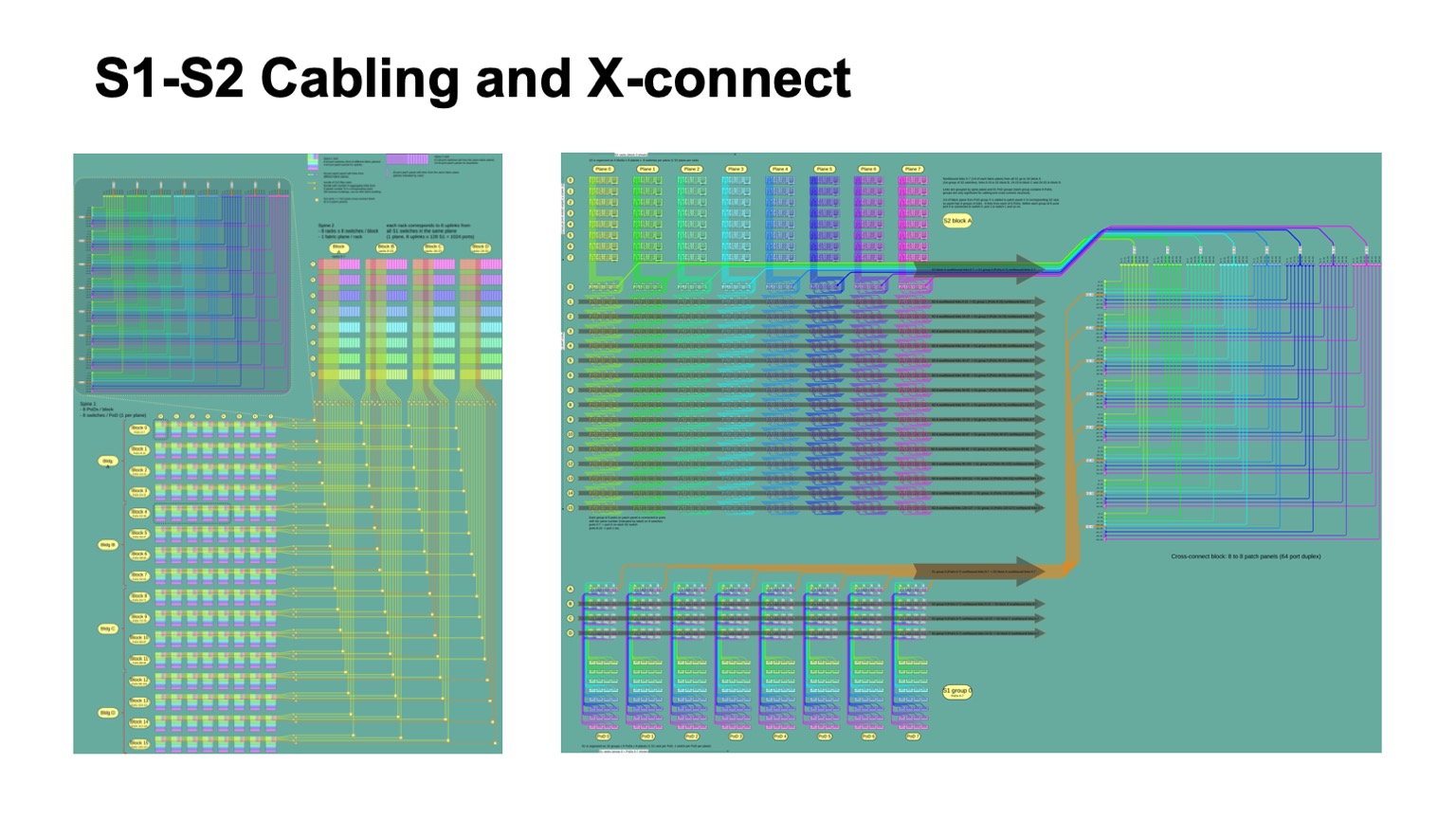
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

Así es como se ve. -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. . , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. Y aquí está el por qué.

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . .