Hola
¿Sueles ver comentarios tóxicos en las redes sociales? Probablemente depende del contenido que está viendo. Propongo experimentar un poco sobre este tema y enseñar a la red neuronal a determinar los comentarios que odian.
Por lo tanto, nuestro objetivo global es determinar si un comentario es agresivo, es decir, estamos tratando con una clasificación binaria. Escribiremos una red neuronal simple, la entrenaremos en un conjunto de datos de comentarios de diferentes redes sociales, y luego haremos un análisis simple con visualización.
Para el trabajo usaré Google Colab. Este servicio le permite ejecutar Jupyter Notebooks y tener acceso a la GPU (NVidia Tesla K80) de forma gratuita, lo que acelerará el aprendizaje. Necesitaré el backend TensorFlow, la versión predeterminada en Colab 1.15.0, así que solo actualice a 2.0.0.
Importamos el módulo y lo actualizamos.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Puedes ver la versión actual como esta.
print(tf.__version__)
Se realiza el trabajo preparatorio, importamos todos los módulos necesarios.
import os import numpy as np
Descripción de bibliotecas usadas
- os - para trabajar con el sistema de archivos
- numpy - para trabajar con matrices
- pandas: una biblioteca para analizar datos tabulares
- keras - para construir un modelo
- keras.preprocessing.Text: para el procesamiento de texto, para enviarlo en forma numérica para entrenar una red neuronal
- sklearn.train_test_split: para separar los datos de prueba del entrenamiento
- matplotlib - para visualizar el proceso de aprendizaje
- sklearn.normalize: para normalizar los datos de prueba y entrenamiento
Análisis de datos con Kaggle
Cargo datos directamente en la computadora portátil Colab. Además, sin ningún problema, ya los estoy extrayendo.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
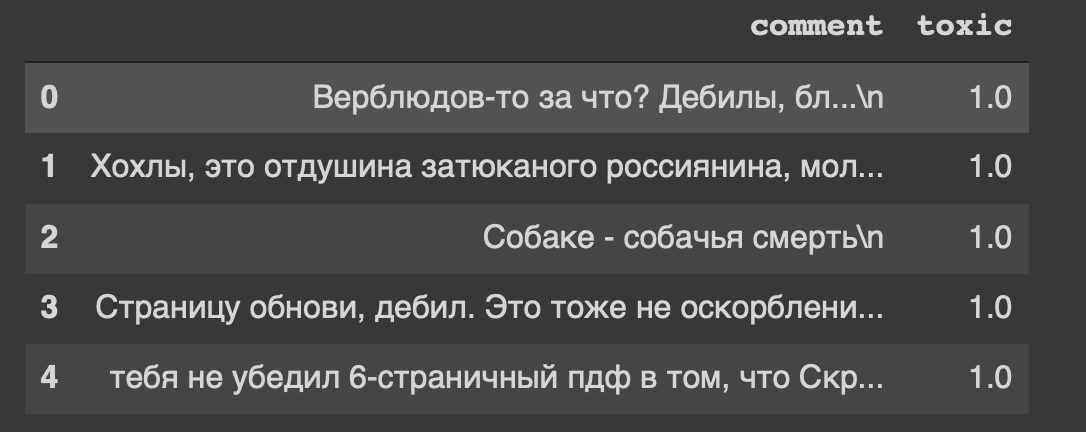
Y este es el encabezado de nuestro conjunto de datos ... Yo también, de alguna manera, me siento incómodo por "actualizar página, imbécil".
Entonces, nuestros datos están en la tabla, los dividiremos en dos partes: datos para capacitación y para el modelo de prueba. Pero todo esto es texto, hay que hacer algo.
Procesamiento de datos
Elimine los caracteres de nueva línea del texto.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
Los comentarios tienen un tipo de datos real, necesitamos traducirlos a un número entero. Luego, guárdelo en una variable separada.
target = np.array(df['toxic'].astype('uint8')) target[:5]
Ahora procesaremos ligeramente el texto usando la clase Tokenizer. Escribamos una copia de ella.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
Rápidamente sobre los parámetros- num_words - número de palabras fijas (más común)
- filtros: una secuencia de caracteres que se eliminarán
- lower: un parámetro booleano que controla si el texto estará en minúsculas
- split - el símbolo principal para dividir una oración
- char_level: indica si un solo carácter se considerará una palabra
Y ahora procesaremos el texto usando la clase.
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
Tenemos 14k filas de muestra y 30k columnas de características.

Estoy construyendo un modelo a partir de dos capas: Denso y Abandono.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
Normalizamos la matriz y dividimos los datos en dos partes, según lo acordado (capacitación y prueba).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
Entrenamiento modelo
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
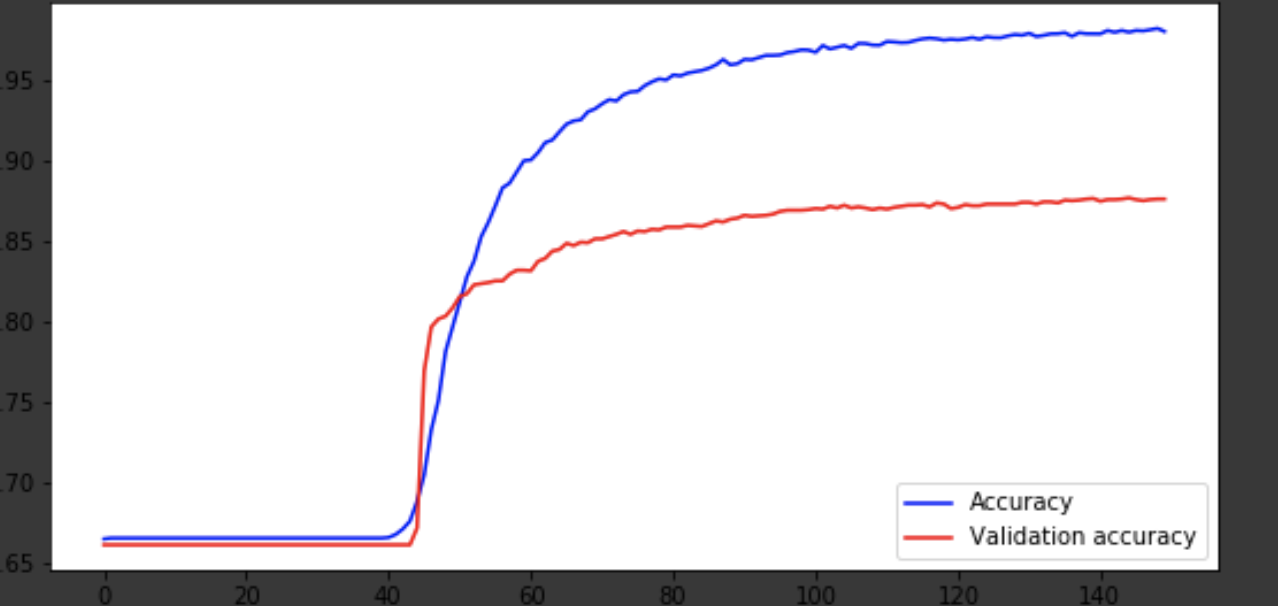
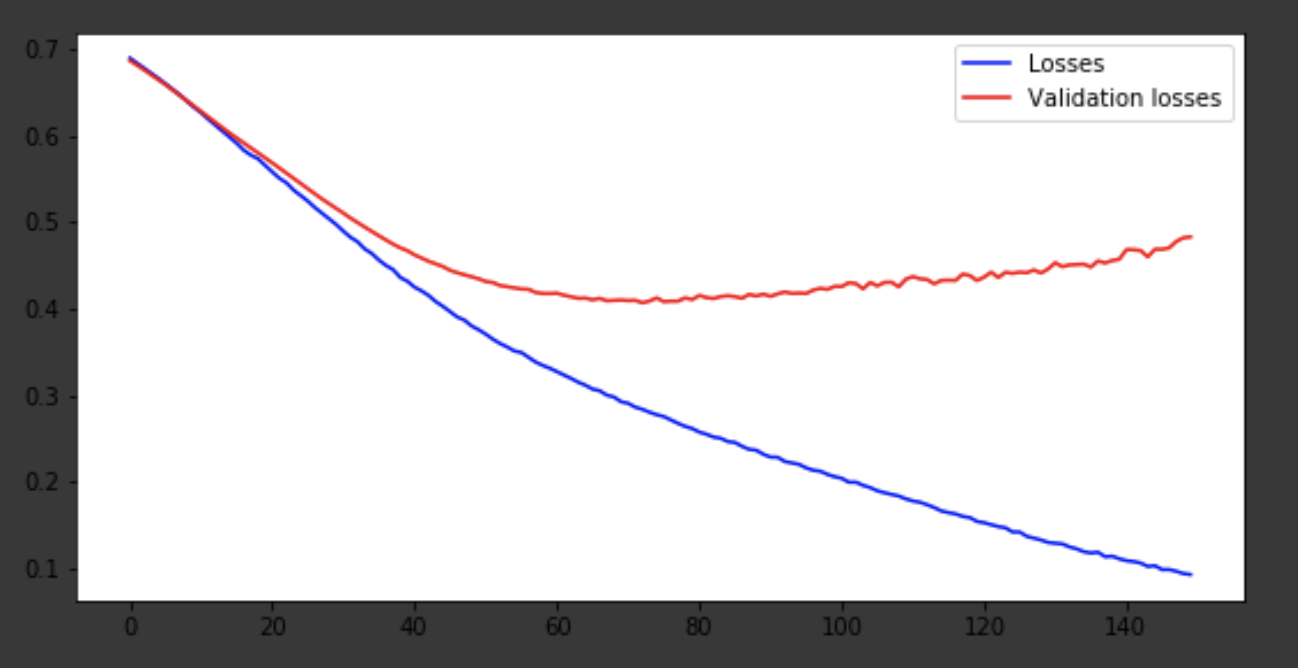
Mostraré el proceso de aprendizaje en las últimas iteraciones.

Visualización del proceso de aprendizaje.
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
Conclusión
El modelo salió alrededor de la era 75 y luego se comporta mal. La precisión de 0,85 no molesta. Puede divertirse con la cantidad de capas, hiperparámetros e intentar mejorar el resultado. Siempre es interesante y es parte del trabajo. Escriba sobre sus pensamientos en los comentarios, veremos cuántos sombreros ganará este artículo.