El artículo analiza enfoques para crear recomendaciones personalizadas de productos y contenido, y posibles casos de uso.
Las recomendaciones personalizadas de productos y contenido se utilizan para aumentar la conversión, la verificación promedio y mejorar la experiencia del usuario.

Un ejemplo de uso del enfoque es Amazon y Netflix. Amazon comenzó a utilizar un enfoque de filtrado colaborativo en los primeros años de su existencia y logró un crecimiento de los ingresos solo a través del algoritmo en un 10%. Netflix aumenta la cantidad de contenido visto debido al enfoque basado en el algoritmo del sistema de recomendación en un 40%. Ahora, es más fácil nombrar una empresa que no utiliza este enfoque que enumerar a todos los que lo utilizan.
Netflix tiene una historia fascinante relacionada con esta tecnología. En 2006-2009 (incluso antes de que el lugar de la competencia Kaggle ML se hiciera popular), Netflix anunció un concurso abierto para mejorar el algoritmo con un premio de $ 1,000,000. La competencia duró 2 años y varios miles de desarrolladores y científicos participaron en ella. Si Netflix los contrató en el estado, los costos serían muchas veces más altos que el premio prometido. Como resultado, uno de los equipos ganó enviando una solución con la calidad requerida 2 horas antes que el otro equipo, repitiendo el resultado del ganador. Como resultado, el dinero fue a un equipo rápido. La competencia se ha convertido en un catalizador de cambios cualitativos en el campo de las recomendaciones personalizadas.
El enfoque principal para resolver el problema de construir sistemas de recomendación es el filtrado colaborativo.
La idea del filtrado colaborativo es simple: si un usuario realizó una compra de un producto o vio contenido, encontraremos usuarios con gustos similares y le recomendaremos a nuestro cliente que personas como él hayan consumido, pero el cliente no. Este es un enfoque basado en el usuario.
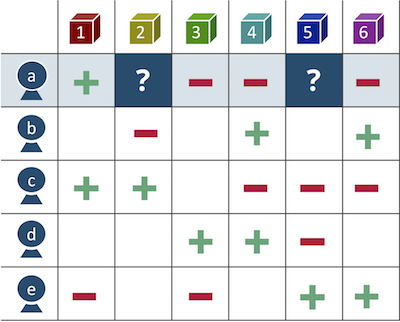 Figura 1 - Matriz de preferencia de producto
Figura 1 - Matriz de preferencia de productoDel mismo modo, puede ver el problema desde el punto de vista de los productos y recoger productos complementarios en la cesta del cliente aumentando el cheque promedio o reemplazando los productos que no están en stock por un análogo. Este es un enfoque basado en elementos.
En el caso más simple, se utiliza el algoritmo para encontrar los vecinos más cercanos.
Ejemplo: si a María le gustan las películas "Titanic" y "Star Wars", el usuario más cercano a sus gustos será Anya, que también vio "Hachiko" además de estas películas. Vamos a recomendar a María la película "Hachiko". Vale la pena aclarar que generalmente no usan un vecino más cercano, sino varios, con un promedio de los resultados.
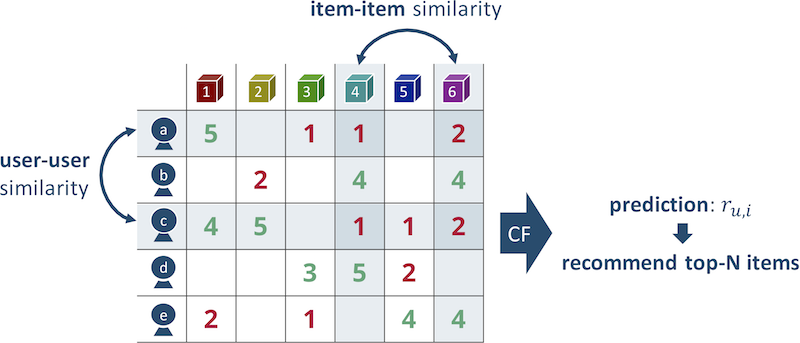 Fig. 2 El principio de funcionamiento del algoritmo de los vecinos más cercanos.
Fig. 2 El principio de funcionamiento del algoritmo de los vecinos más cercanos.Todo parece ser simple, pero la calidad de las recomendaciones que utilizan este enfoque es pequeña.
Considere algoritmos complejos de sistemas de recomendación basados en la propiedad de las matrices, o más bien, en la descomposición de las matrices.
El algoritmo clásico es SVD (descomposición matricial singular).
El significado del algoritmo es que la matriz de preferencias de producto (la matriz donde las filas son usuarios y las columnas son los productos con los que interactúan los usuarios) se representa como el producto de tres matrices.
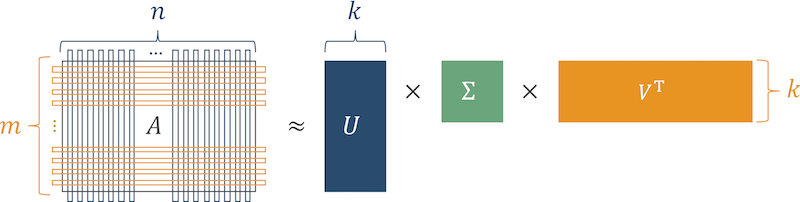 Fig. 3 Algoritmo SVD
Fig. 3 Algoritmo SVDDespués de restaurar la matriz original, las celdas donde el usuario tenía ceros y aparecían números "grandes", muestran el grado de interés latente en el producto. Organice estos números y obtenga una lista de productos relevantes para el usuario.
Durante esta operación, el usuario y el producto aparecen signos "latentes". Estos son signos que muestran el estado "oculto" del usuario y del producto.
Pero se sabe que tanto el usuario como el producto, además de los "latentes", también tienen signos obvios. Esto es género, edad, recibo de compra promedio, región, etc.
Intentemos enriquecer nuestro modelo con estos datos.
Para hacer esto, utilizamos el algoritmo de la máquina de factorización.
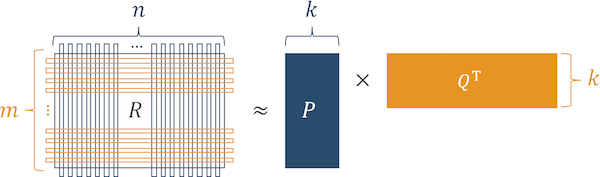 Fig. 4 Algoritmo de operación de máquinas de factorización.
Fig. 4 Algoritmo de operación de máquinas de factorización.Según nuestra experiencia, en
Data4 , los estudios de casos en el campo de la construcción de sistemas de recomendación para tiendas en línea, a saber, máquinas de factorización, dan el mejor resultado. Entonces, utilizamos máquinas de factorización para construir un sistema de recomendación para nuestro cliente, KupiVip. El crecimiento en la métrica RMSE fue de 6-7%.
Pero los enfoques basados en matrices tienen sus inconvenientes. El número de patrones generalizados de combinación mutua de bienes no es grande. Para resolver este problema, es recomendable utilizar redes neuronales. Pero una red neuronal requiere volúmenes de datos que solo las grandes empresas tienen.
Según nuestra experiencia, en
Data4 , solo un cliente tiene una red neuronal para recomendaciones personalizadas de productos que dieron el mejor resultado. Pero, con éxito, puede obtener hasta el 10% de la métrica RMSE. Las redes neuronales se utilizan en YouTube y en algunos de los sitios de contenido más grandes.
Casos de uso
Para tiendas en línea
- Recomendar productos relevantes para el usuario en las páginas de la tienda en línea.
- Use el bloque "puede que le guste" en la tarjeta del producto
- En la cesta recomendamos productos complementarios (control remoto para TV)
- Si el producto no está en stock, recomiende un análogo
- Hacer boletines personalizados
Para el contenido
- Aumente la participación recomendando artículos, películas, libros y videos relevantes.
Otros
- Recomendar personas en aplicaciones de citas
- Recomienda platos en un restaurante
En el artículo discutimos los conceptos básicos de los sistemas de recomendación de dispositivos y estudios de casos. Aprendimos que el principio principal es recomendar productos que les gusten a las personas con gustos similares y el uso del algoritmo de filtrado colaborativo.
En el próximo artículo , se considerarán los trucos de vida de los sistemas de recomendación basados en casos comerciales reales. Mostramos qué métricas se utilizan mejor y qué coeficiente de proximidad elegir para la predicción.