¿Cómo suavizar la caída?

No encontré una guía completa para el manejo de errores en las aplicaciones React, así que decidí compartir la experiencia adquirida en este artículo. El artículo está destinado a desarrolladores principiantes y puede ser un punto de partida para sistematizar el manejo de errores en la aplicación.
Problemas y fijación de objetivos
El lunes por la mañana, bebe café con calma y se jacta de haber reparado más errores que la semana pasada y luego el gerente viene corriendo y agita sus manos: "Nos hemos caído, todo es muy triste, estamos perdiendo dinero". Ejecutas y abres tu Mac, vas a la versión de producción de tu SPA, haces un par de clics para reproducir el error, ves la pantalla en blanco y solo el Todopoderoso sabe lo que sucedió allí, sube a la consola, comienza a cavar, dentro del componente t hay un componente con el nombre de voz b, en el que el error no puede leer la propiedad getId de undefined. N horas de investigación y te apresuras con un grito victorioso para lanzar una revisión. Tales redadas ocurren con cierta frecuencia y se han convertido en la norma, pero ¿qué pasa si digo que todo puede ser diferente? ¿Cómo reducir el tiempo de errores de depuración y construir el proceso para que el cliente prácticamente no note errores de cálculo durante el desarrollo que son inevitables?
Examinemos en orden los problemas que hemos encontrado:- Incluso si el error es insignificante o localizado dentro del módulo, en cualquier caso, la aplicación completa deja de funcionar
Antes de React versión 16, los desarrolladores no tenían un solo mecanismo estándar de captura de errores, y hubo situaciones en las que la corrupción de datos provocó una caída en el procesamiento solo en los siguientes pasos o un comportamiento extraño de la aplicación. Cada desarrollador manejó los errores porque estaba acostumbrado, y el modelo imperativo con try / catch generalmente no se ajustaba bien a los principios declarativos de React. En la versión 16, apareció la herramienta de Límites de error, que trató de resolver estos problemas, consideraremos cómo aplicarla. - El error se reproduce solo en el entorno de producción o no se puede reproducir sin datos adicionales.
En un mundo ideal, el entorno de desarrollo es el mismo que el de producción y podemos reproducir cualquier error localmente, pero vivimos en el mundo real. No hay herramientas de depuración en el sistema de combate. Es difícil y no productivo descubrir tales incidentes, básicamente tiene que lidiar con el código ofuscado y la falta de información sobre el error, y no con la esencia del problema. No consideraremos la cuestión de cómo aproximar las condiciones del entorno de desarrollo a las condiciones de producción, sin embargo, consideraremos herramientas que le permitan obtener información detallada sobre los incidentes ocurridos.
Todo esto reduce la velocidad de desarrollo y la lealtad del usuario al producto de software, por lo que me puse los 3 objetivos más importantes:
- Mejore la experiencia del usuario con la aplicación en caso de errores;
- Reduzca el tiempo entre el error que entra en producción y su detección;
- Acelere el proceso de búsqueda y depuración de problemas en la aplicación para el desarrollador.
¿Qué tareas deben resolverse?- Manejar errores críticos con límite de error
Para mejorar la experiencia del usuario con la aplicación, debemos interceptar los errores críticos de la IU y procesarlos. En el caso en que la aplicación consta de componentes independientes, esta estrategia permitirá al usuario trabajar con el resto del sistema. También podemos intentar tomar medidas para restaurar la aplicación después de un bloqueo, si es posible.
- Guardar información de error extendida
Si se produce un error, envíe información de depuración al servidor de supervisión, que filtrará, almacenará y mostrará información sobre incidentes. Esto nos ayudará a detectar rápidamente y depurar fácilmente errores después de la implementación.
Manejo de errores críticosA partir de la versión 16, React ha cambiado el comportamiento estándar de manejo de errores. Ahora, las excepciones que no se detectaron con el Límite de error conducirán a desmontar todo el árbol React y, como resultado, a la inoperancia de toda la aplicación. Esta decisión se argumenta por el hecho de que es mejor no mostrar nada que darle al usuario la oportunidad de obtener resultados impredecibles. Puede leer más en la
documentación oficial de React .
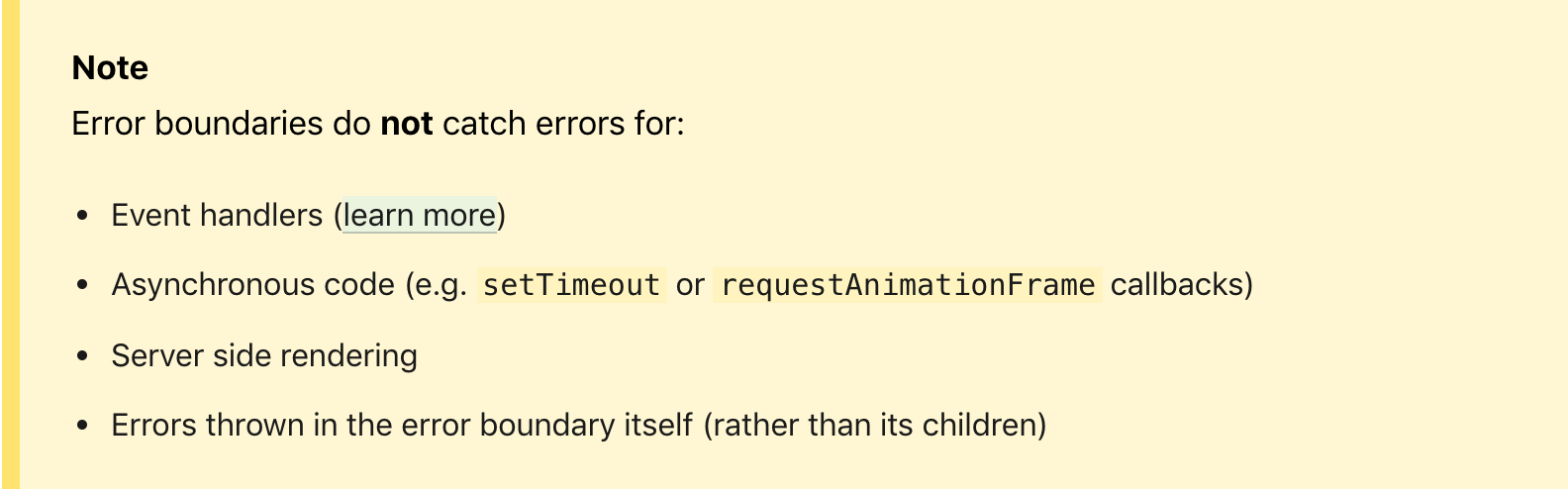
Además, muchos están confundidos por la nota de que el Límite de error no detecta los errores de los controladores de eventos y el código asincrónico, pero si lo piensa, cualquier controlador puede cambiar el estado, en función del cual se llamará un nuevo ciclo de representación, que, en última instancia la cuenta puede causar un error en el código de la interfaz de usuario. De lo contrario, este no es un error crítico para la interfaz de usuario y se puede manejar de una manera específica dentro del controlador.
Desde nuestro punto de vista, un error crítico es una excepción que ocurrió dentro del código de la interfaz de usuario y si no se procesa, todo el árbol React se desmontará. Los errores restantes no son críticos y pueden procesarse de acuerdo con la lógica de la aplicación, por ejemplo, mediante notificaciones.
En este artículo, nos centraremos en el manejo de errores críticos, a pesar del hecho de que los errores no críticos también pueden conducir a la inoperancia de la interfaz en el peor de los casos. Su procesamiento es difícil de separar en un bloque común y cada caso individual requiere una decisión dependiendo de la lógica de la aplicación.
En general, los errores no críticos pueden ser muy críticos (como un juego de palabras), por lo que la información sobre ellos debe registrarse de la misma manera que para los críticos.
Ahora estamos diseñando Error Boundary para nuestra sencilla aplicación, que consistirá en una barra de navegación, un encabezado y el espacio de trabajo principal. Es lo suficientemente simple como para centrarse solo en el manejo de errores, pero tiene una estructura típica para muchas aplicaciones.
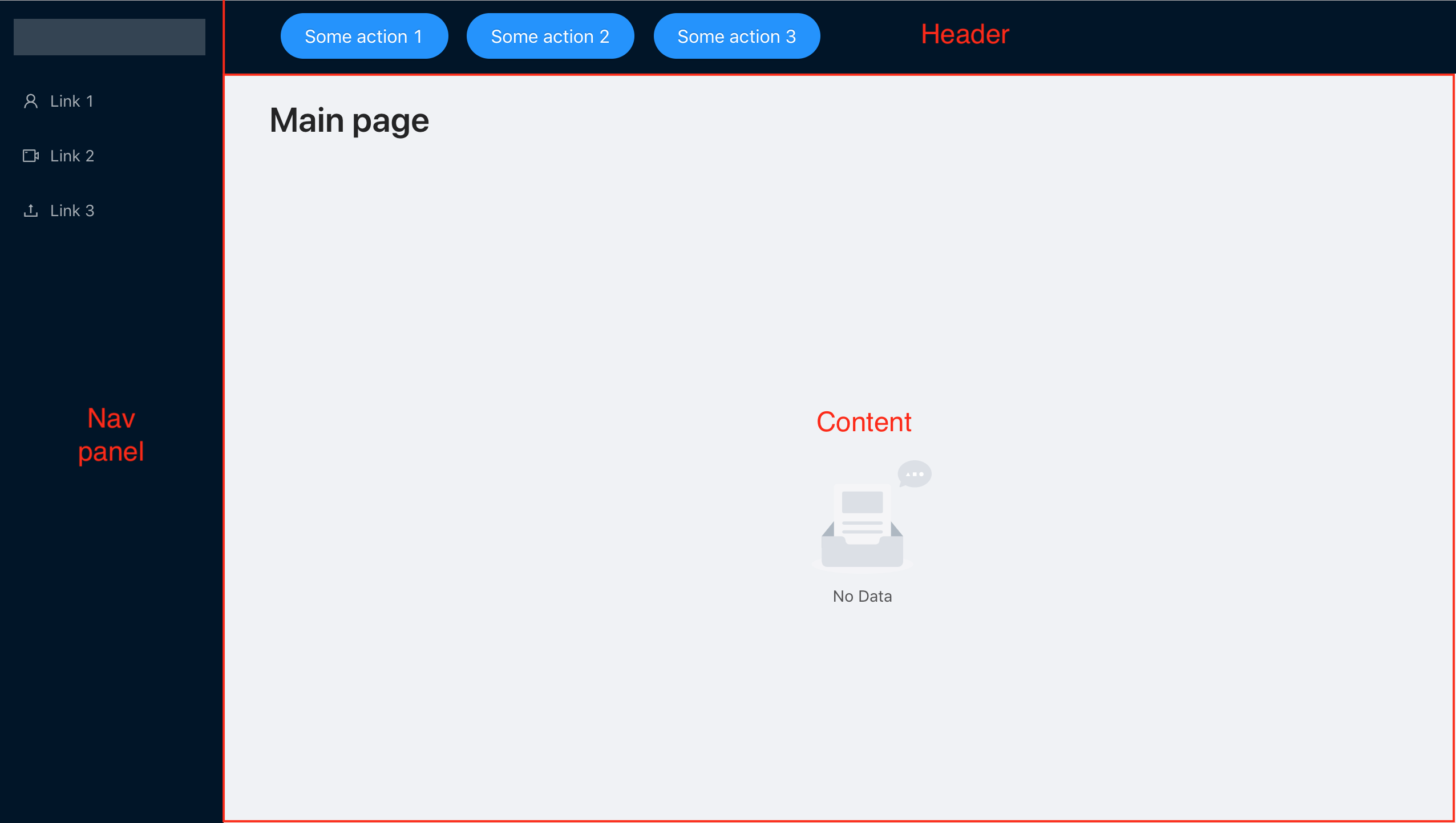
Tenemos un panel de navegación de 3 enlaces, cada uno de los cuales conduce a componentes independientes entre sí, por lo que queremos lograr un comportamiento que, incluso si uno de los componentes no funciona, podamos seguir trabajando con los demás.
Como resultado, tendremos ErrorBoundary para cada componente al que se puede acceder a través del menú de navegación y el ErrorBoundary general, que informa sobre el bloqueo de toda la aplicación, en caso de que ocurra un error en el componente de encabezado, panel de navegación o dentro de ErrorBoundary, pero no lo resolvimos procesar y descartar más.
Considere enumerar una aplicación completa que está envuelta en ErrorBoundary
const AppWithBoundary = () => ( <ErrorBoundary errorMessage="Application has crashed"> <App/> </ErrorBoundary> )
function App() { return ( <Router> <Layout> <Sider width={200}> <SideNavigation /> </Sider> <Layout> <Header> <ActionPanel /> </Header> <Content> <Switch> <Route path="/link1"> <Page1 title="Link 1 content page" errorMessage="Page for link 1 crashed" /> </Route> <Route path="/link2"> <Page2 title="Link 2 content page" errorMessage="Page for link 2 crashed" /> </Route> <Route path="/link3"> <Page3 title="Link 3 content page" errorMessage="Page for link 3 crashed" /> </Route> <Route path="/"> <MainPage title="Main page" errorMessage="Only main page crashed" /> </Route> </Switch> </Content> </Layout> </Layout> </Router> ); }
No hay magia en ErrorBoundary, es solo un componente de clase en el que se define el método componentDidCatch, es decir, cualquier componente puede convertirse en ErrorBoundary, si define este método en él.
class ErrorBoundary extends React.Component { state = { hasError: false, } componentDidCatch(error) {
Así es como ErrorBoundary busca el componente de Página, que se representará en el bloque de Contenido:
const PageBody = ({ title }) => ( <Content title={title}> <Empty className="content-empty" /> </Content> ); const MainPage = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary>
Dado que ErrorBoundary es un componente React regular, podemos usar el mismo componente ErrorBoundary para ajustar cada página en su propio controlador, simplemente pasando diferentes parámetros a ErrorBoundary, ya que estas son instancias diferentes de la clase, su estado no dependerá el uno del otro .
IMPORTANTE: ErrorBoundary puede detectar errores solo en los componentes que están debajo de él en el árbol.En el listado a continuación, el error no será interceptado por el ErrorBoundary local, sino que será arrojado e interceptado por el controlador sobre el árbol:
const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> {null.toString()} </ErrorBoundary> );
Y aquí el error es detectado por el ErrorBoundary local:
const ErrorProneComponent = () => null.toString(); const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> <ErrorProneComponent /> </ErrorBoundary> );
Después de envolver cada componente por separado en nuestro ErrorBoundary, logramos el comportamiento necesario, colocamos el código deliberadamente erróneo en el componente usando link3 y vemos qué sucede. Nos olvidamos intencionalmente de pasar el parámetro de pasos:
const PageBody = ({ title, steps }) => ( <Content title={title}> <Steps current={2} direction="vertical"> {steps.map(({ title, description }) => (<Step title={title} description={description} />))} </Steps> </Content> ); const Page = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary> );
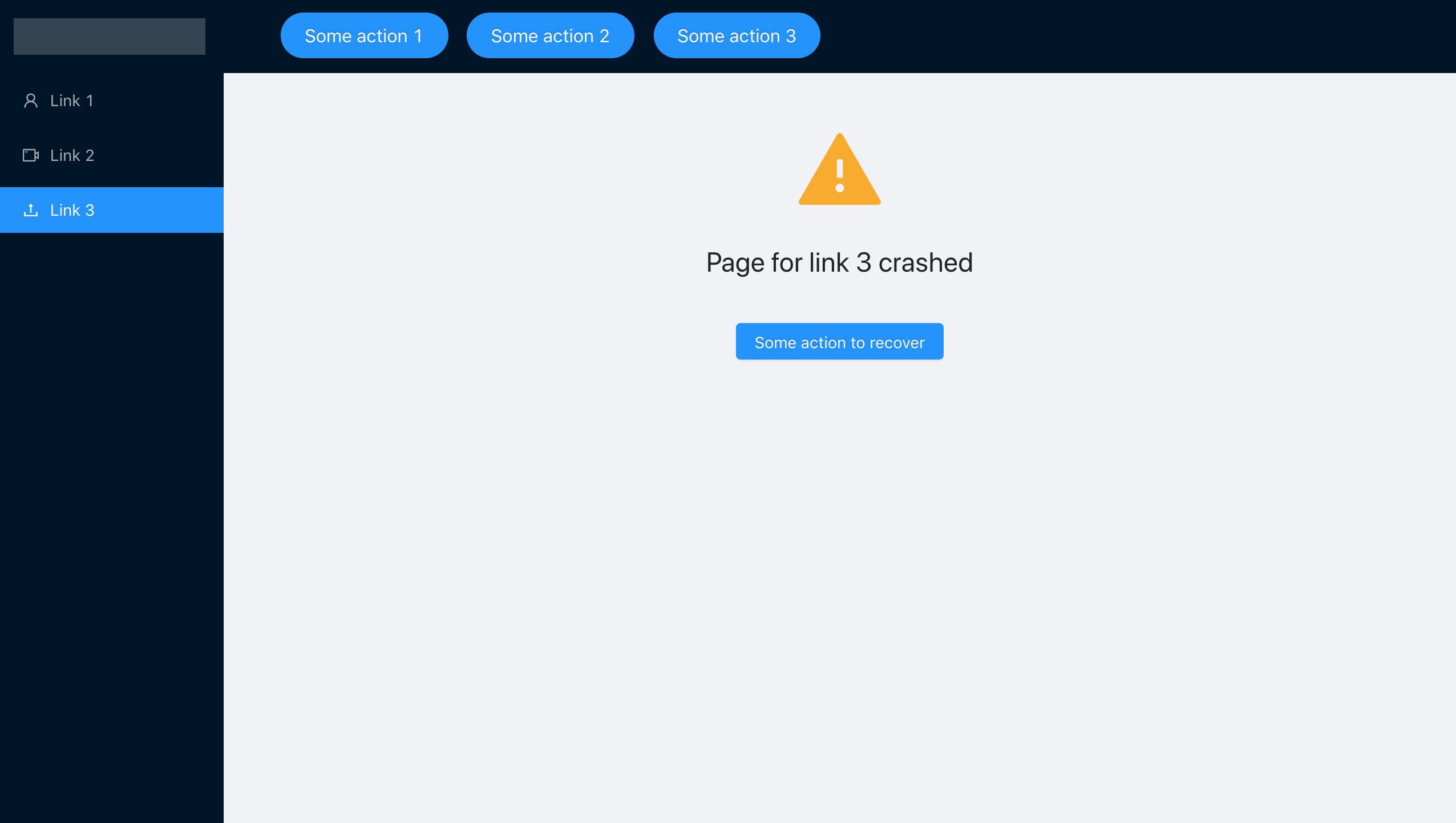
La aplicación nos informará que se ha producido un error, pero no se caerá por completo, podemos navegar por el menú de navegación y trabajar con otras secciones.
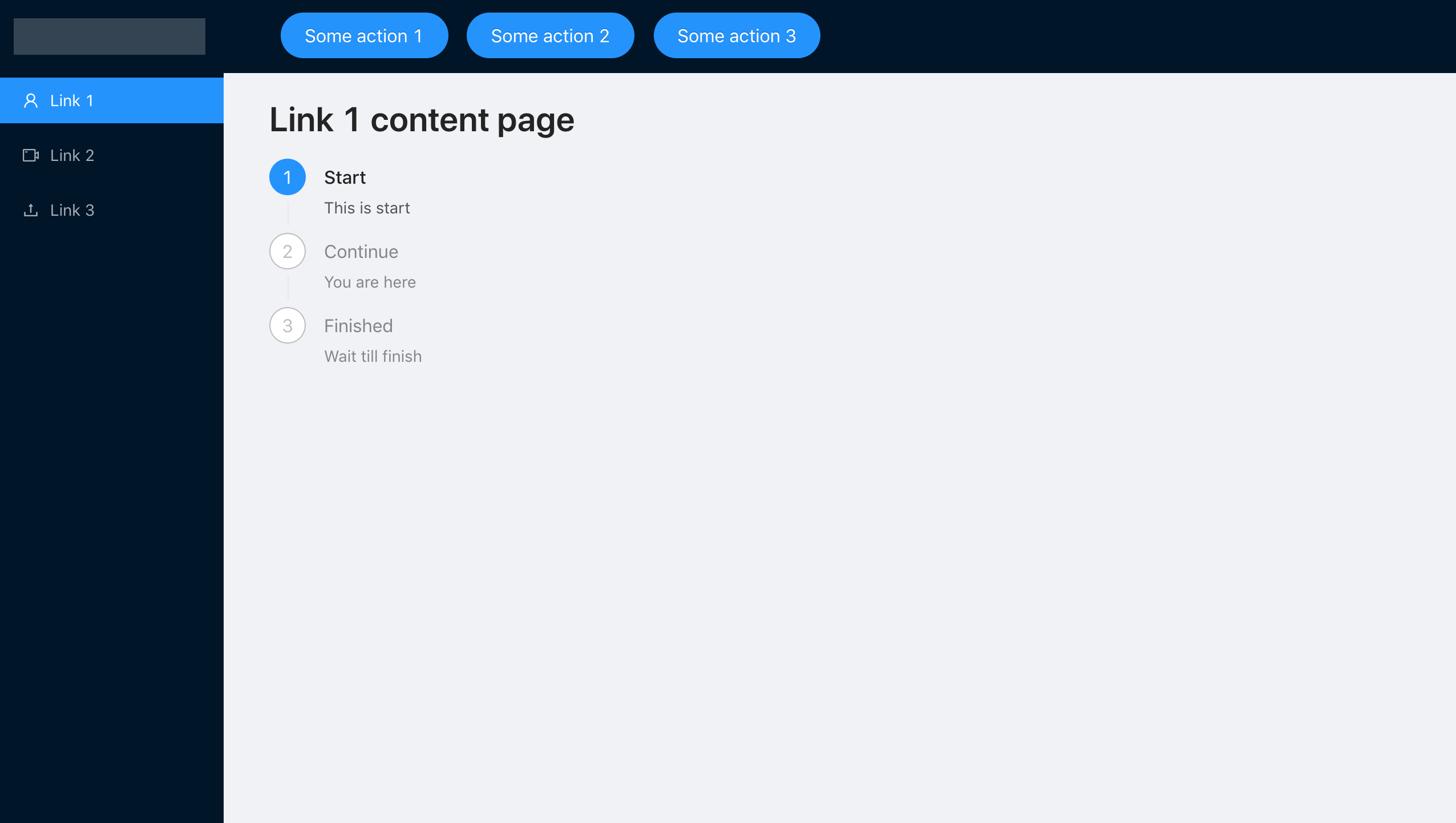
Una configuración tan simple nos permite lograr fácilmente nuestro objetivo, pero en la práctica, pocas personas prestan mucha atención al manejo de errores, planificando solo la ejecución regular de la aplicación.
Guardando información de errorAhora que hemos colocado suficiente ErrorBoundary en nuestra aplicación, es necesario guardar información sobre los errores para detectarlos y corregirlos lo más rápido posible. La forma más fácil es utilizar los servicios SaaS, como Sentry o Rollbar. Tienen una funcionalidad muy similar, por lo que puede usar cualquier servicio de monitoreo de errores.
Mostraré un ejemplo básico en Sentry, porque en solo un minuto puedes obtener una funcionalidad mínima. Al mismo tiempo, Sentry mismo detecta excepciones e incluso modifica console.log para obtener toda la información del error. Después de eso, todos los errores que ocurrirán en la aplicación serán enviados y almacenados en el servidor. Sentry tiene mecanismos para filtrar eventos, ofuscar datos personales, vincular a comunicados y mucho más. Consideraremos solo el escenario de integración básica.
Para conectarse, debe registrarse en su sitio web oficial y seguir la guía de inicio rápido, que lo guiará inmediatamente después del registro.
En nuestra aplicación, agregamos solo un par de líneas y todo despega.
import * as Sentry from '@sentry/browser'; Sentry.init({dsn: “https:
Nuevamente, haga clic en el enlace / link3 en nuestra aplicación y obtenga la pantalla de error, luego de lo cual vamos a la interfaz de centinela, aparentemente se ha producido un evento y falla dentro.
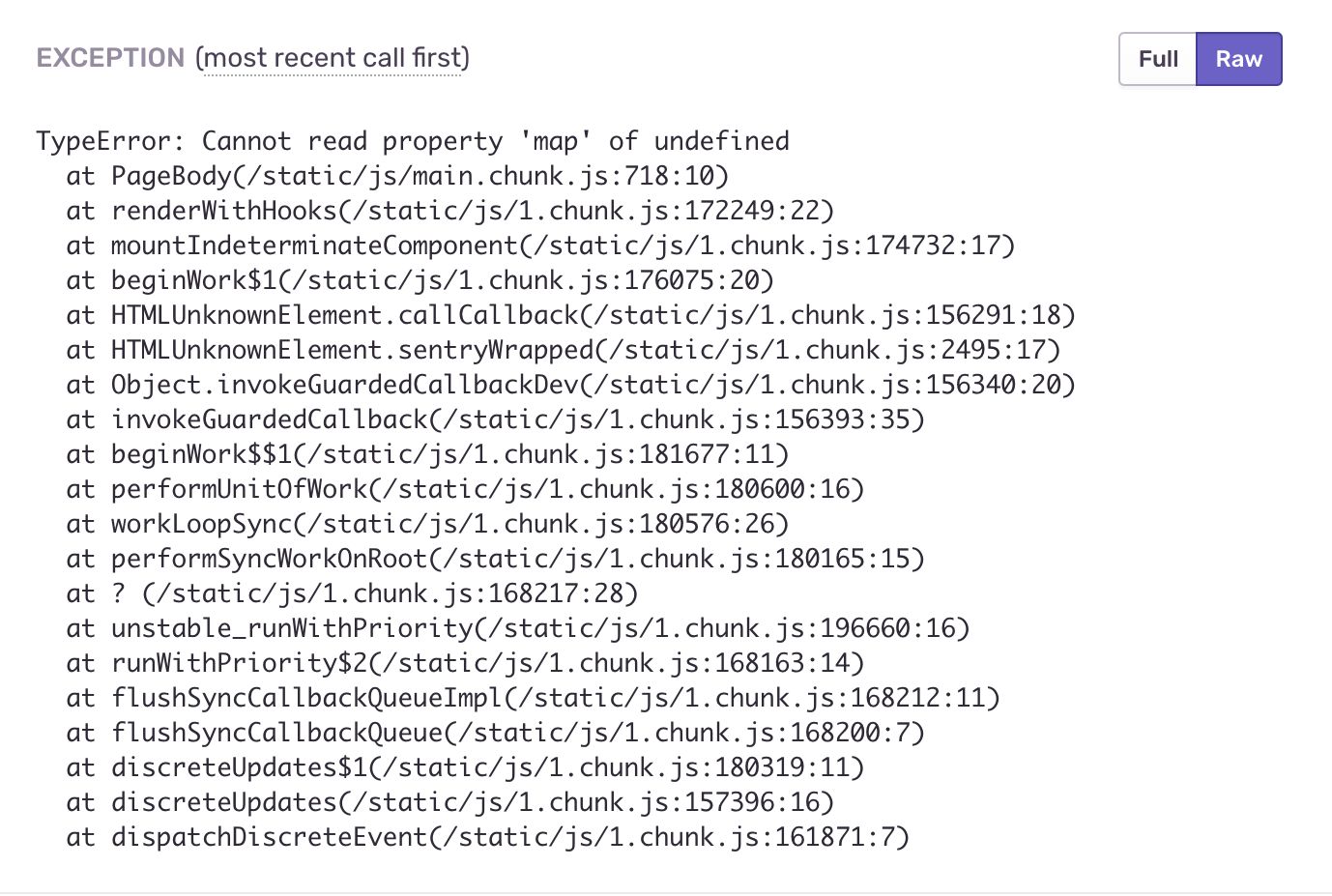
Los errores se agrupan automáticamente por tipo, frecuencia y hora de ocurrencia; se pueden aplicar varios filtros. Tenemos un evento: caemos en él y en la siguiente pantalla vemos un montón de información útil, por ejemplo, seguimiento de pila

y la última acción del usuario antes del error (migas de pan).
Incluso con una configuración tan simple, podemos acumular y analizar información de error y usarla para una mayor depuración. En este ejemplo, se envía un error desde el cliente en modo de desarrollo, por lo que podemos observar la información completa sobre el componente y los errores. Para obtener información similar del modo de producción, debe configurar adicionalmente la sincronización de los datos de lanzamiento con Sentry, que almacenará el mapa fuente en sí mismo, lo que le permitirá guardar suficiente información sin aumentar el tamaño del paquete. No consideraremos dicha configuración en el marco de este artículo, pero trataré de hablar sobre las trampas de tal solución en un artículo separado después de su implementación.
El resultado:El manejo de errores usando ErrorBoundary nos permite suavizar las esquinas con un bloqueo parcial de la aplicación, lo que aumenta la experiencia del usuario del sistema y el uso de sistemas especializados de monitoreo de errores para reducir el tiempo de detección y depuración de problemas.
Piense cuidadosamente en una estrategia para procesar y monitorear los errores de su aplicación, en el futuro esto le ahorrará mucho tiempo y esfuerzo.
Una estrategia bien pensada mejorará principalmente el proceso de trabajar con incidentes, y solo entonces afectará la estructura del código.PD : Puede probar varias opciones de configuración de ErrorBoundary o conectar Sentry a la aplicación usted mismo en la rama feature_sentry, reemplazando las claves con las obtenidas durante el registro en el sitio.
Aplicación de demostración de Git-hubDocumentación oficial de límite de error de React