
Según los analistas, el mercado de centros de datos en los próximos años crecerá un 38% por año y crecerá a $ 35 mil millones en cinco años, y el nicho más intensivo en recursos (en términos de intensidad informática) es el aprendizaje profundo, las redes neuronales y las tareas de inteligencia artificial.
Por supuesto, Intel no será indiferente para ver cómo Nvidia (y AMD, en menor medida) con sus GPU capturan este mercado, incluido el sector de más rápido crecimiento. La semana pasada, el gigante de la industria microelectrónica hizo varios anuncios de alto perfil a la vez:
- procesadores para las redes neuronales Nervana NNP-T1000 y NNP-I1000 (NNP: procesadores de red neuronal), así como el chip Movidius VPU ;
- Procesadores escalables Xeon de 10 nm (con nombre en código Sapphire Rapids);
- interfaces de programación unificadas oneAPI (para CPU, GPU, FPGA) - un competidor de Nvidia CUDA;
- Una GPU de 7 nm para centros de datos, con el nombre en código Ponte Vecchio, sobre la nueva arquitectura X e .
Módulos de computación Aurora
En estas CPU, GPU y oneAPI, compondrán los módulos informáticos Aurora para la supercomputadora homónima con un nivel de rendimiento de 1 exaflops (10 ^ 18 operaciones por segundo). Se supone que esta máquina se instalará en el Laboratorio Nacional Argonne del Departamento de Energía de EE. UU.

Cada módulo de cómputo tiene dos procesadores Sapphire Rapids y seis GPU conectados a través del bus CXL.

Según las
estimaciones de AnandTech , en un sistema de 200 bastidores, como se indicó, si resta la reserva para la red y las unidades, caben aproximadamente 2400 nodos Aurora de dos unidades. Eso es un total de aproximadamente 5,000 procesadores Sapphire Rapids y 15,000 Ponte Vecchio. Si dividimos el rendimiento declarado de 1 exaflops por la cantidad de GPU, entonces salen aproximadamente 66.6 teraflops por GPU. Además, suponiendo un rendimiento de CPU de 14 teraflops, todavía obtenemos unos 50 teraflops, es decir, este es un aumento de cinco veces en el rendimiento de la GPU en los centros de datos para 2021.
Por supuesto, los planes no se limitan a una supercomputadora para el Departamento de Energía. Intel anunció que Lenovo y Atos ya se están preparando para lanzar plataformas de servidor basadas en la CPU Xeon, X
e GPU y oneAPI. Por lo tanto, los módulos informáticos Aurora de alguna forma encontrarán aplicación en otros centros de datos.
La supercomputadora debería lanzarse en 2021. Al mismo tiempo, las GPU X
e X de 7 nanómetros deberían aparecer en el mercado.
Según Intel, ahora las soluciones tradicionales de alto rendimiento (HPC) convergen con AI, pasando a cargas de trabajo que utilizan el aprendizaje profundo. HPC, AI y análisis son las tres cargas de trabajo principales que impulsan la demanda de recursos informáticos: “Esta variedad de necesidades informáticas fomenta la informática heterogénea.
Dijo Rajeeb Hazra, vicepresidente y gerente general de Intel Enterprise and Government. - Las soluciones universales ya no son adecuadas aquí. En esta era de convergencia, debe observar arquitecturas que estén ajustadas a las diferentes necesidades de los diferentes tipos de cargas de trabajo ".
GPU para centros de datos

Ponte Vecchio es la primera GPU en la nueva arquitectura X
e . La arquitectura en sí se convertirá en la base de la GPU en varios segmentos:
- informática de alto rendimiento;
- aprendizaje profundo;
- Computación en la nube
- gráficos;
- transcodificación de medios;
- estaciones de trabajo
- computadoras de juego;
- PC de escritorio normales;
- dispositivos móviles y ultramóviles.

Ari Rauch, vicepresidente de arquitectura, gráficos y software de Intel, dice que una arquitectura de GPU brindará a los desarrolladores una "estructura común", pero como parte de esta arquitectura, la compañía está desarrollando "muchas microarquitecturas que proporcionan el rendimiento más eficiente para cada estas cargas de trabajo ".
La GPU Ponte Vecchio se basa en la microarquitectura X
e específicamente para HPC y AI, y las características de microarquitectura incluyen un motor de matriz paralela flexible con matrices vectoriales, alto rendimiento de cálculos de punto flotante de doble precisión (FP64) y un rendimiento ultra alto de caché y memoria. Para los formatos INT8, Bfloat16 y FP32 habrá un motor de matriz separado para el procesamiento paralelo de matrices (posiblemente un análogo de TensorCore), y para FP64 la aceleración será de hasta 40 veces para cada unidad de computación.
"Esta carga de trabajo requiere un alto rendimiento computacional, por lo que nos enfocamos en agregar una gran cantidad de módulos vectoriales y matriciales y computación paralela que están adaptados y optimizados para esta carga de trabajo", dijo Rauch.
Ponte Vecchio será la primera GPU de la nueva generación. Implementa varias tecnologías nuevas que Intel ha estado desarrollando en los últimos años:
- proceso de producción 7 nm;
- diseño en capas de circuitos integrados Foveros 3D;
- EMIB (Embedded Multi-Die Interconnect Bridge) para conectar varios cristales en un sustrato;
- X e Link en el nuevo estándar de interconexión CXL (basado en PCI Express 5.0): acceso a la GPU a través de un solo espacio de memoria.

 Circuitos integrados 3D en capas de Foveros de la presentación de Intel de diciembre de 2018
Circuitos integrados 3D en capas de Foveros de la presentación de Intel de diciembre de 2018Las especificaciones técnicas del chip aún no se han anunciado. Dicen que en estas GPU habrá miles de unidades ejecutivas conectadas a través de XEMF (XE Memory Fabric) con memoria y caché.

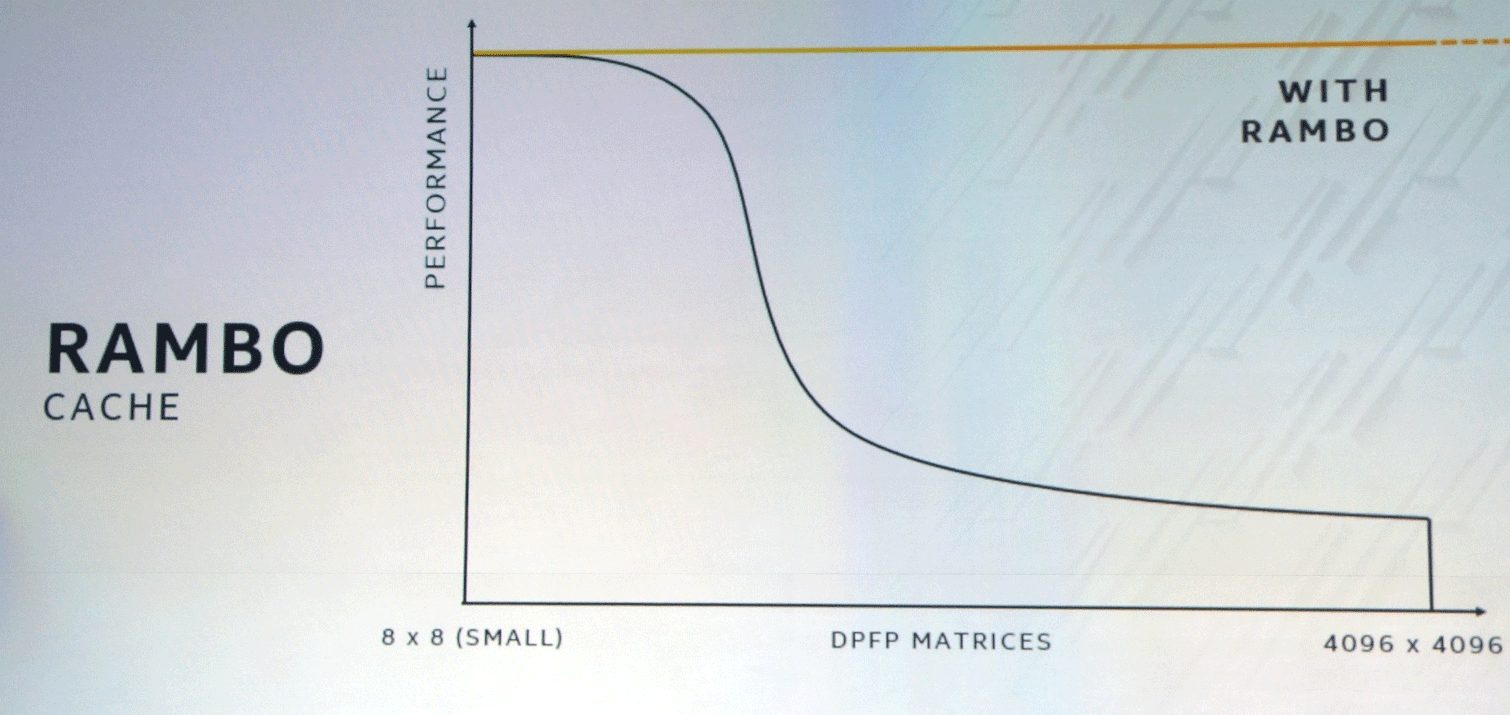
El bus XEMF funciona con el caché Rambo Cache ultrarrápido especial para eliminar el cuello de botella del acceso a la memoria. Este caché se conecta a las unidades informáticas a través de Foveros, y EMIB se utilizará para conectar la memoria HBM.
La combinación de enfoques SIMT y SIMD específicos para la GPU y la CPU, respectivamente, y las instrucciones de vector de longitud variable proporcionarán un aumento significativo del rendimiento en algunas clases de tareas.

Muchos esperan que Intel compita con Nvidia y AMD en el mercado de centros de datos e inteligencia artificial. No se trata solo de la competencia de precios, sino también del surgimiento de plataformas tecnológicas alternativas, que estimularán el progreso tecnológico general.
OneAPI: vértice de abstracción para hierro heterogéneo
Además del anuncio de nuevos equipos, Intel lanzó una versión beta de las interfaces de software unificadas oneAPI. Están diseñados para facilitar el trabajo de los desarrolladores que, para optimizar sus programas al máximo, tradicionalmente han tenido que cambiar entre diferentes lenguajes de programación y bibliotecas utilizando middleware y frameworks.
Por defecto, se acepta en la industria que a un nivel bajo, se debe preparar un código diferente para cada arquitectura. Por ejemplo, TensorFlow estaba inicialmente completamente optimizado en el momento del lanzamiento para la GPU de un proveedor (para Nvidia CUDA).
"OneAPI está tratando de resolver estos problemas ofreciendo una interfaz común de bajo nivel para hardware heterogéneo con un rendimiento sin concesiones", dijo Bill Savage, vicepresidente de la división de arquitectura, gráficos y software de Intel. "Para que los desarrolladores puedan escribir programas directamente en el hardware a través de lenguajes y bibliotecas comunes a diferentes arquitecturas y proveedores, así como asegurarse de que el middleware y los marcos funcionen en oneAPI y estén completamente optimizados para los desarrolladores que están en la cima de esta abstracción".
Intel promociona oneAPI como un "estándar abierto para apoyar a la comunidad y la industria", que permitirá "reutilizar código en arquitecturas y hardware de diferentes fabricantes".
La especificación oneAPI incluirá el lenguaje de programación estándar DPC ++ de arquitectura cruzada basado en C ++ y SYCL, así como "API potentes para acelerar funciones específicas de dominio clave".
Además del compilador DPC ++ y la biblioteca API, se lanzarán herramientas especiales, incluido VTune Inspector Advisor, un depurador y una "herramienta de compatibilidad" para portar código CUDA (Nvidia) a DPC ++.
Para estimular la transición a oneAPI, Intel lanzó un sandbox en
DevCloud para desarrollar y probar programas en varias CPU, GPU y FPGA. Trabajar con el sandbox no requiere la instalación de ningún hardware o software.
Mientras tanto, los ingresos de Nvidia para el trimestre
aumentaron a $ 3 mil millones , mientras que en el mercado de centros de datos, el crecimiento en los tres meses fue del 11% ($ 726 millones). Las ventas de procesadores V100 y T4 están batiendo todos los récords. Intel todavía lo está mirando desde afuera, pero ya sabemos cuál será la respuesta. Lo más interesante recién comienza.