
En el foro RAIF 2019, que se celebró en Skolkovo como parte de Open Innovations, hablé sobre cómo se está implementando la introducción de modelos de aprendizaje automático. En relación con las características de la profesión, paso varios días a la semana en producción, introduciendo modelos de aprendizaje automático y el resto del tiempo desarrollando estos modelos. Esta publicación es una grabación de un informe en el que intenté resumir mi experiencia.
Comenzamos describiendo el proceso en grandes trazos, entrando gradualmente en los detalles de cada etapa.
Ya sea que contemos con optimizar la producción en función de los resultados de una encuesta completa (idealmente), o simplemente recolectando ideas, "optimización de retazos", el resultado es de alguna manera la
formación de una lista de iniciativas . Es necesario comprender qué áreas de producción optimizaremos. Este proceso generalmente toma alrededor de dos meses.
Luego procedemos a la fase de
prueba , tomará de tres a cuatro meses: debemos construir un modelo básico y comprender si el aprendizaje automático es aplicable y qué beneficios puede aportar a los negocios.
La siguiente etapa, que es mucho más larga en el tiempo, no tiene mucho aprendizaje automático: la
implementación es cuando necesita integrar, construir los sistemas actuales y comenzar a obtener los beneficios que predijimos en la segunda etapa. La implementación generalmente toma de seis meses a nueve meses.
La etapa de
control completa el proceso. Una cosa es hacer un modelo y mostrar, y otra es mantener el modelo por algún tiempo. La producción está cambiando, las máquinas herramienta están siendo reemplazadas. En estas condiciones, el modelo tiene que "girar" constantemente y buscar nuevas oportunidades para la optimización.
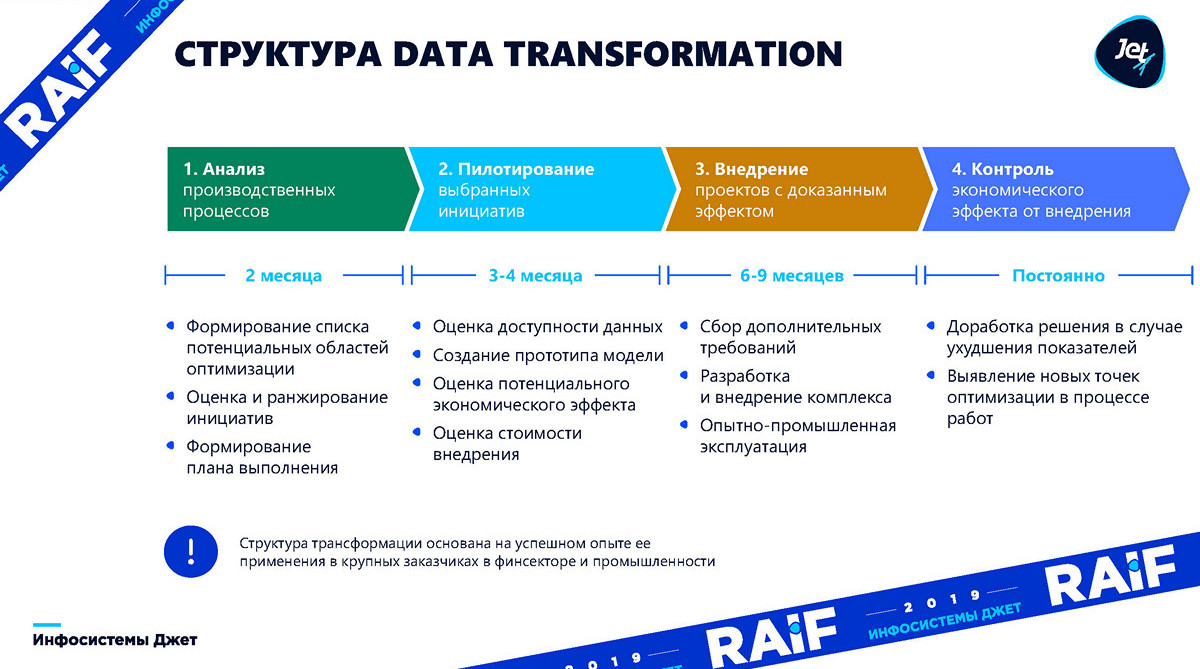
Ahora con más detalle en orden:
Buscando una hipótesis
¿De dónde viene la hipótesis? ¿Quién la nominará?
Por lo general, es común acudir al departamento de TI para obtener hipótesis, pero las personas que pueden configurar sistemas trabajan allí, saben sobre integración y no saben nada sobre aprendizaje automático. Además, no son tan conscientes de la producción. No tienen competencia para comprender en la práctica cómo funciona el aprendizaje automático.
El intento número dos es ir a la hipótesis de producción. De hecho, los especialistas cercanos a la producción conocen las características técnicas del proceso, pero ... no conocen el aprendizaje automático. Por lo tanto, no pueden decir dónde es aplicable y dónde no.
En este caso, ¿de dónde puede venir la hipótesis? Para hacer esto, se les ocurrió una posición especial: Director de Transformación Digital. Esta es una persona que se dedica a la transformación digital. O Chief Date Officer: una persona que conoce los datos y cómo se pueden aplicar. Si estas dos personas no están en la empresa, entonces las hipótesis deben provenir de la alta dirección. Es decir, especialistas que entienden completamente el negocio y se dedican a la tecnología moderna.
Si la empresa no tiene ni el Director de Transformación Digital ni el Director de Fecha, y la alta gerencia no puede dar a luz una hipótesis, entonces ... los competidores vendrán al rescate. Si han implementado algo, no se les puede quitar esto. Pero, una compañía integradora conectada al proyecto puede decir qué y cómo se puede optimizar.

¿Cómo elegir una idea?
Aquí hay cuatro factores importantes:
- La rotación del proceso a optimizar.
- Desviaciones significativas en el proceso. Existe una metodología de seis sigma, que sugiere que todos los procesos deben desviarse en no más de seis desviaciones estándar de sus resultados. Si tiene más de estas desviaciones, entonces necesita analizarlas, y el aprendizaje automático lo ayudará.
- Disponibilidad y disponibilidad de datos. Si, por ejemplo, recibe datos de sensores sobre el funcionamiento del equipo después de 12 meses, no implementará el aprendizaje automático.
- La complejidad de implementar la digitalización en el proceso. El costo de presentar su modelo, en comparación con el costo de lo que puede ahorrar.
¿Cuáles son los datos?
La estructura de los datos son:
Estructurado: algunas tablas, lecturas, todo es simple. Cuando queremos usar datos de redes sociales o conjuntos de fotos, tenemos que lidiar con datos no estructurados. Es necesario establecer que dichos datos también deben estructurarse, convirtiéndose en números que el aprendizaje automático pueda percibir. El tercer tipo de datos está enhebrado. Si trabajamos con datos que cambian cada milisegundo, debemos pensar de inmediato en el equilibrio de carga: ¿puede nuestro sistema soportar la velocidad de su recepción?

Por origen, los datos se dividen en:
Automatizado: los sensores generan algún tipo de números, confiamos en ellos o no. Pero son casi lo mismo. Ingresado manualmente: aquí debe comprender que puede haber un error relacionado con el factor humano. Y el modelo debe ser resistente a esto. Datos externos: tal vez nos interesarán los tipos de cambio si la implementación está relacionada con transacciones financieras o pronósticos meteorológicos si predecimos los intercambios de calor por temperatura. Los datos estáticos son todo lo que se puede reutilizar.

Problemas de datos
- Integridad: el momento en que se pueden omitir algunos datos / meses.
- El error de cambio: si, por ejemplo, su sensor tiene un error de 5 milisegundos, entonces el modelo con una precisión de dos milisegundos, no podrá hacerlo, ya que los datos de entrada comienzan a divergir.
- Accesibilidad en línea: si desea hacer un pronóstico "ahora", los datos deben estar listos.
- Tiempo de almacenamiento: si desea usar tendencias anuales y necesita pronosticar la demanda, y los datos se almacenan solo durante seis meses, no creará un modelo.
Trabajar con datos
Escuche a los profesionales, pero solo crea los datos. Debe ir al taller, hablar con profesionales, ir a la fábrica, hablar con operadores, comprender sus negocios. Pero crea solo los datos. Hubo muchos ejemplos cuando los operadores dicen que esto no puede ser, mostramos los datos, resulta que esto realmente está sucediendo. Un ejemplo interesante: una vez que el modelo mostró que el día de la semana afecta la producción. Los lunes, un coeficiente, los viernes, otro.
El efecto es comprensible solo en la batalla: la creación rápida de prototipos es muy importante. Lo más importante es ver rápidamente cómo funciona el modelo en la vida cotidiana. En presentaciones y en computadoras portátiles locales, el proyecto puede verse completamente diferente de lo que realmente es: como regla, de hecho, los problemas completamente diferentes son lo primero.
Solo un modelo interpretado tiene una posibilidad de mejora. Siempre debe comprender claramente por qué el modelo decidió de esta manera y no de otra manera.
Trabajar con métricas
En realidad, la dependencia de la precisión del beneficio puede ser cualquiera. Hasta que comprendamos cómo esta precisión afecta el efecto, la cuestión de la precisión no tiene ningún sentido. Siempre necesitas traducirlo en ganancias. Los gráficos a continuación muestran que las ganancias pueden variar según la precisión del modelo. El primer gráfico ilustra lo difícil que es determinar de antemano exactamente en qué punto la precisión del modelo es suficiente para el crecimiento de las ganancias:
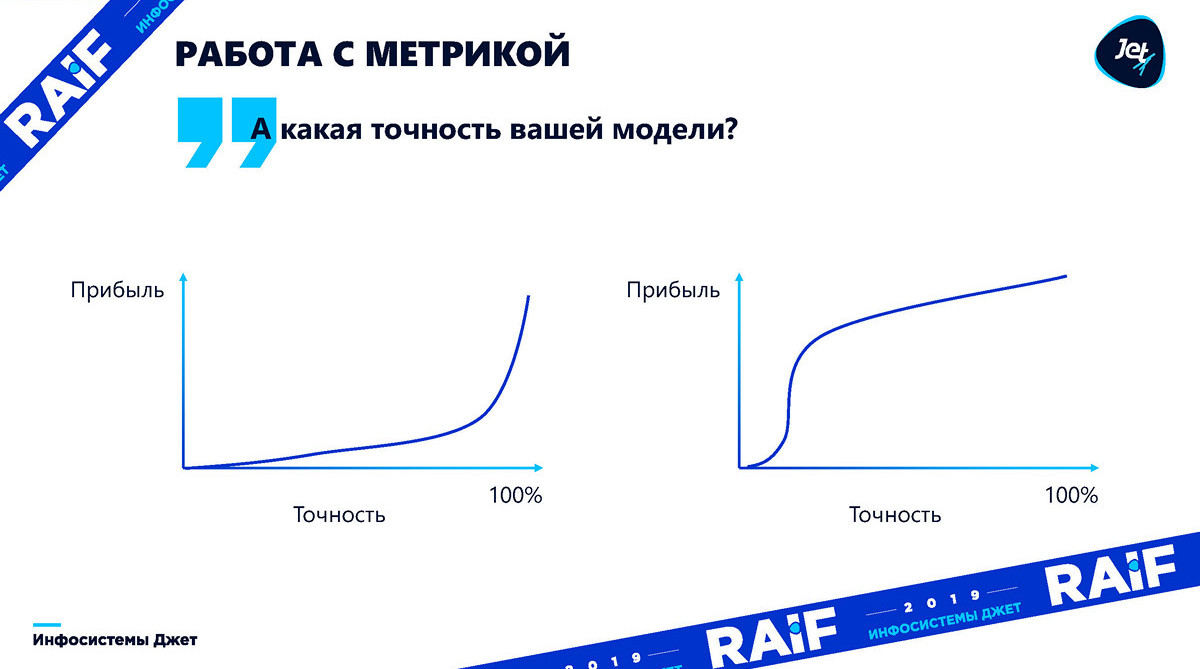
Además, para algunos casos con una precisión insuficiente del modelo, simplemente traerá pérdidas:

Puntos clave sobre la integración:
- La integración lleva más tiempo que el desarrollo del modelo.
- Nuevas ideas A veces resulta que el proyecto se beneficia donde no se esperaba.
- Entrenamiento Las personas se adaptan más rápido que el hierro.
Otro punto que a menudo olvidan los expertos en datos es el objetivo de presentar el modelo: pronóstico o recomendación. Por lo general, las recomendaciones se basan en el modelo predictivo, pero en este caso el modelo predictivo debe construirse especialmente, porque es bastante difícil encontrar la caja negra mínima con efectos repentinos desagradables. Si hablamos de métricas de rendimiento, según el propósito de la implementación:
- Emitir un pronóstico, - evaluar el resultado de aplicar el conocimiento;
- Dar recomendaciones: evaluar la comparación con el proceso anterior.
Matices importantes de la fase de implementación:
Implementación / Entrenamiento
- Alfabetización estadística: la implementación es mucho más exitosa cuando los empleados locales comienzan a operar con términos estadísticos correctos.
- La motivación de varias unidades estructurales: todos deben entender por qué sucede esto y no tener miedo al cambio.
- Cambios organizativos: al menos un empleado analizará los resultados del modelo, lo que significa que cambiarán su enfoque del proceso. A menudo resulta que la gente no está lista para esto.
Apoyo
No olvide que las condiciones están cambiando y que el modelo tiene que "torcerse" constantemente y buscar nuevas oportunidades de optimización. Aquí son importantes:
- Las estrategias de gestión de modelos y la reacción a los pronósticos son un poco de autopromoción: en Jet Infosystems pensamos mucho en esto y desarrollamos nuestro propio sistema JET GALATEA.
- El factor humano: los principales problemas del modelo a menudo se asocian con su uso o intervención humana, que el modelo no podía prever.
- Análisis regular del trabajo con profesionales del campo: es poco probable que todo se reduzca a un número, lo que indicará lo que debe mejorarse, será necesario analizar cada dudoso pronóstico o recomendación. Prepárese para aprender otra profesión para hablar el mismo idioma con tecnólogos y operadores de dispositivos en el lugar de trabajo.

Publicado por Nikolay Knyazev, Jefe del Grupo de Aprendizaje Automático, Jet Infosystems