
Estoy seguro de que el titular causó una reacción saludable: "Bueno, comenzó de nuevo ..." Pero permítame captar su atención durante 5 a 10 minutos e intentaré no engañar a las expectativas.
La estructura del artículo será la siguiente: se toma una declaración estereotípica y se revela la "naturaleza" de la aparición de este estereotipo. Espero que esto le permita ver la elección del paradigma de intercambio de datos en sus proyectos desde un nuevo ángulo.
Para dejar en claro qué es RPC, propongo considerar el estándar JSON-RPC 2.0 . No hay claridad con REST. Y no debería ser. Todo lo que necesita saber sobre REST es indistinguible de HTTP .
Las solicitudes RPC son más rápidas y más eficientes porque permiten solicitudes por lotes.
El punto es que en RPC es posible hacer una llamada a varios procedimientos en una sola solicitud. Por ejemplo, cree un usuario, agréguele un avatar y, en la misma solicitud, firme sobre algunos temas. ¡Solo una solicitud, y cuánto bien!
De hecho, si solo tiene un nodo de fondo, esto parecerá más rápido con una solicitud por lotes. Porque tres solicitudes REST requerirán el triple de recursos de un nodo para establecer conexiones.
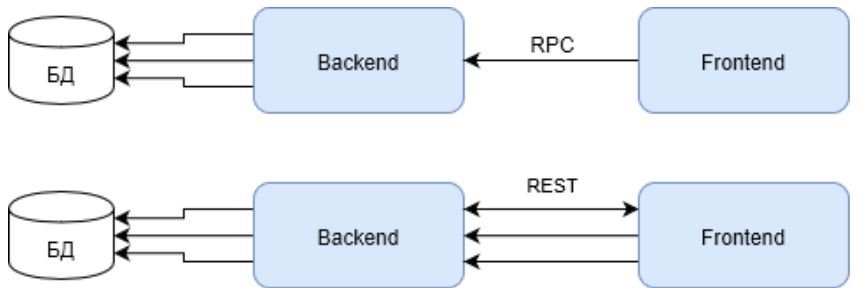
Tenga en cuenta que la primera solicitud en el caso de REST debe devolver el ID de usuario para solicitudes posteriores. Lo que también afecta negativamente el resultado general.
Pero tales infraestructuras se pueden encontrar, quizás, en soluciones internas y Enterprise. Como último recurso, en pequeños proyectos WEB. Pero las soluciones WEB completas, y también llamadas HighLoad, no deberían construirse así. Su infraestructura debe cumplir con los criterios de alta disponibilidad y carga de trabajo. Y la imagen está cambiando.
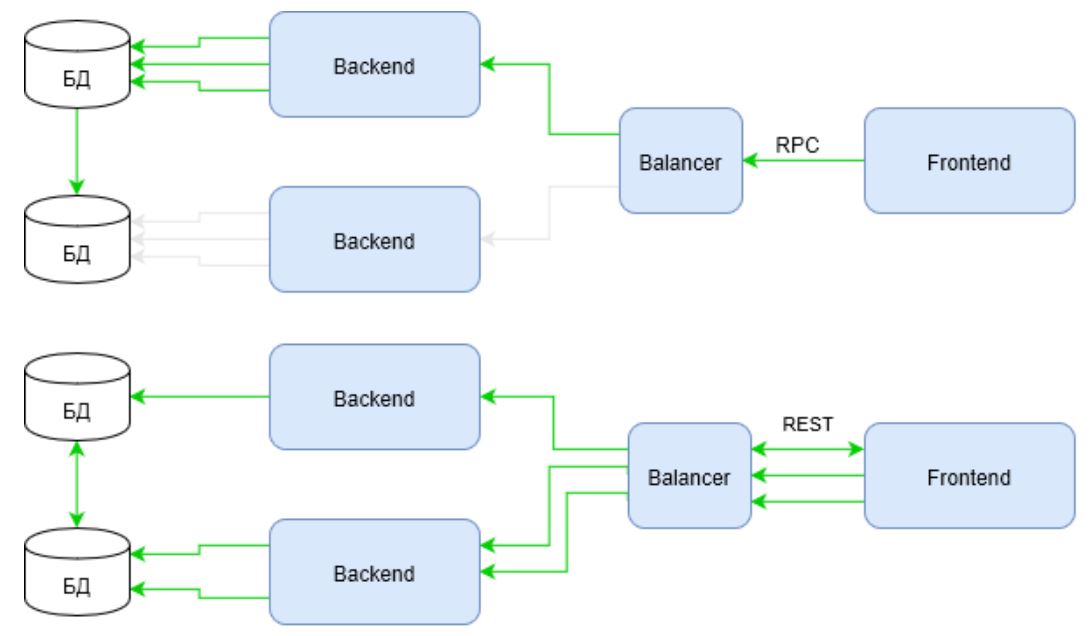
El verde indica canales de actividad de infraestructura en el mismo escenario. Observe cómo se comporta RPC ahora. La solicitud utiliza la infraestructura solo un hombro desde el equilibrador hasta el backend. Mientras que REST todavía pierde en la primera solicitud, compensa el tiempo perdido usando toda la infraestructura.
Es suficiente ingresar en el guión no dos solicitudes de enriquecimiento, sino, digamos, cinco o diez ... y la respuesta a la pregunta "¿quién gana ahora?" Se vuelve obvia.
Propongo mirar aún más el problema. El diagrama muestra cómo se utilizan los canales de infraestructura, pero la infraestructura no se limita a los canales. Un componente importante de una infraestructura muy cargada son las cachés. Consigamos algunos artefactos de usuario ahora. Varias veces Dilo 32 veces.
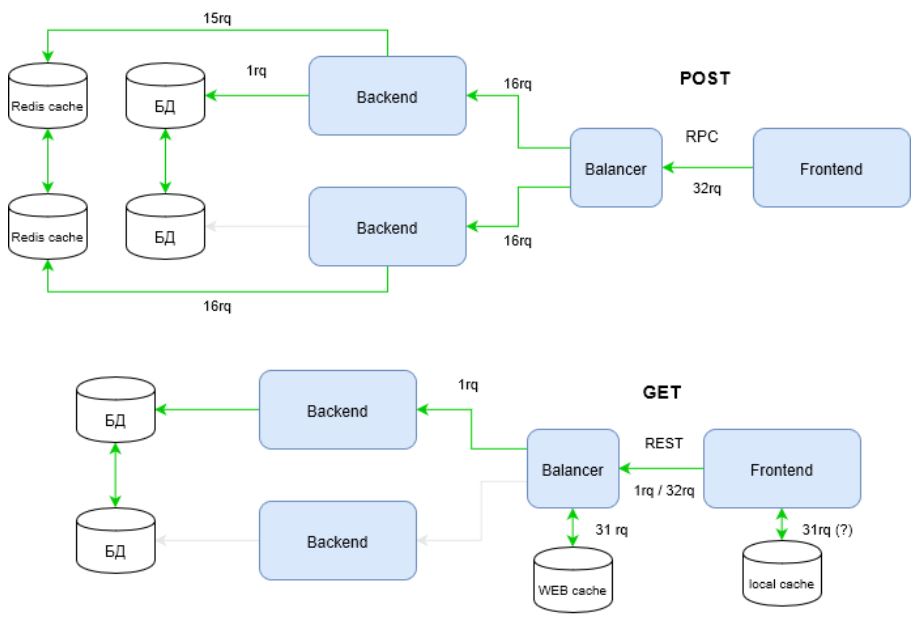
Vea cómo la infraestructura en el RPC se ha "recuperado" visiblemente para satisfacer las demandas de alta carga. La cuestión es que REST usa toda la potencia del protocolo HTTP, a diferencia de RPC. En el diagrama anterior, esta potencia se realiza a través del método de solicitud: GET.
Los métodos HTTP, entre otras cosas, tienen estrategias de almacenamiento en caché. Puede conocerlos en la documentación de HTTP . Para RPC, se utilizan solicitudes POST que no se consideran idempotentes, es decir, la repetición repetida de las mismas solicitudes POST puede devolver resultados diferentes (por ejemplo, después de que se envíe cada comentario, aparecerá otra copia de este comentario) ( fuente ).
En consecuencia, los RPC no pueden usar eficientemente cachés de infraestructura. Esto lleva al hecho de que tiene que "importar" cachés de software. El diagrama muestra a Redis en este rol. La memoria caché flexible, a su vez, requiere que el desarrollador tenga una capa de código adicional y cambios significativos en la arquitectura.
Ahora calculemos cuántas solicitudes "dieron a luz" a REST y RPC en la infraestructura en consideración.
[*] en el mejor de los casos (si se usa el caché local) 1 solicitud (¡una!), en las peores 32 solicitudes entrantes.
En comparación con el primer esquema, la diferencia es sorprendente. La victoria REST ahora es evidente. Pero propongo no detenerse allí. La infraestructura desarrollada incluye CDN. A menudo, también resuelve el problema de contrarrestar los ataques DDoS y DoS. Obtenemos:

Aquí para RPC, todo se vuelve muy deplorable. RPC simplemente no puede delegar el trabajo con la carga de CDN. Uno solo puede confiar en los sistemas para contrarrestar los ataques.
¿Es posible terminar esto? Y de nuevo, no. Los métodos HTTP, como se mencionó anteriormente, tienen su propia "magia". Y por una buena razón, el método GET se usa totalmente en Internet. Tenga en cuenta que este método puede acceder a parte del contenido, puede establecer condiciones que pueden interpretar los elementos de la infraestructura antes de transferir el control a su código, etc. Todo esto le permite crear infraestructuras flexibles y manejables que pueden digerir flujos de solicitudes realmente grandes. Y en RPC, este método ... se ignora.
Entonces, ¿por qué el mito es tan persistente que las solicitudes por lotes (RPC) son más rápidas? Personalmente, me parece que la mayoría de los proyectos simplemente no alcanzan ese nivel de desarrollo cuando REST puede demostrar su fortaleza. Además, en proyectos pequeños, es más probable que muestre su debilidad.
La elección de REST o RPC no es una elección voluntaria de un individuo en el proyecto. Esta elección debe cumplir con los requisitos del proyecto. Si el proyecto es capaz de exprimir de REST todo lo que realmente puede, y realmente es necesario, entonces REST será una excelente opción.
Pero si para obtener todas las ganancias de REST, necesitará contratar desarrolladores para escalar rápidamente la infraestructura, administradores para administrar la infraestructura, un arquitecto para diseñar todas las capas del servicio WEB ... y el proyecto venderá tres paquetes de margarina por día ... I se detendría en RPC desde Este protocolo es más utilitario. No requiere un conocimiento profundo de la operación de cachés e infraestructura, pero enfoca al desarrollador en llamadas simples y comprensibles a los procedimientos necesarios. El negocio estará complacido.
Las solicitudes RPC son más confiables porque pueden ejecutar solicitudes por lotes en una sola transacción
Esta propiedad de RPC es una ventaja definitiva, ya que Es fácil mantener la base de datos en un estado coherente. Pero con REST, todo es más complicado. Las solicitudes pueden llegar de manera inconsistente a diferentes nodos de fondo.
Este "inconveniente" de REST es el otro lado de sus ventajas descritas anteriormente: la capacidad de utilizar de manera efectiva todos los recursos de infraestructura. Si la infraestructura está mal diseñada, y más aún si la arquitectura del proyecto y la base de datos en particular están mal diseñadas, entonces esto es realmente un gran dolor.
Pero, ¿las solicitudes por lotes son tan confiables como parecen? Veamos el caso: cree un usuario, enriquezca su perfil con alguna descripción y envíele un SMS con un secreto para completar el registro. Es decir Tres llamadas en una solicitud de lote.
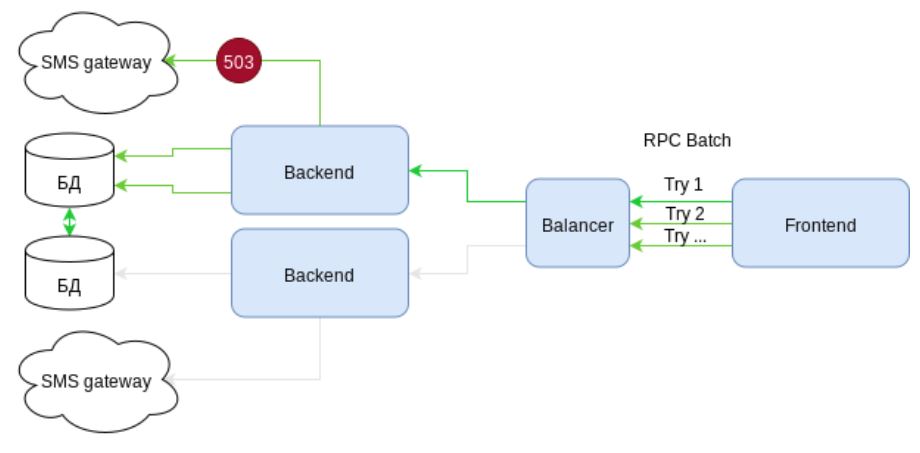
Consideremos el esquema. Presenta la infraestructura con elementos de alta disponibilidad. Hay dos canales de comunicación independientes con pasarelas SMS. Pero ... ¿qué vemos? Al enviar SMS, se produce el error 503: el servicio no está disponible temporalmente. Porque el envío de SMS se empaqueta en una solicitud por lotes, luego toda la solicitud debe revertirse. Las acciones en el DBMS se cancelan. El cliente recibe un error.
El siguiente intento es una lotería. O la solicitud va al mismo nodo nuevamente y devuelve un error, o tiene suerte y se ejecutará. Pero lo principal es que al menos una vez nuestra infraestructura ya ha funcionado en vano. Había una carga, pero ninguna ganancia.
Bueno, imaginemos que nos tensamos (!) Y pensamos en la opción donde la solicitud podría completarse parcialmente con éxito. Y el resto, trataremos de cumplir nuevamente después de un intervalo de tiempo (¿Cuál? ¿Decide el frente?). Pero la lotería se mantuvo. Una solicitud para enviar un SMS con una probabilidad de 50/50 fallará nuevamente.
De acuerdo, del lado del cliente, el servicio no parece tan confiable como nos gustaría ... pero ¿qué pasa con REST?

REST usa magia HTTP nuevamente, pero ahora con códigos de respuesta. Si se produce un error 503 en la puerta de enlace de SMS, el backend transmite este error al equilibrador. El equilibrador que recibe este error, y sin interrumpir la conexión con el cliente, envía la solicitud a otro nodo que procesa la solicitud con éxito. Es decir el cliente recibe el resultado esperado y la infraestructura confirma su alto rango de "altamente accesible". El usuario esta contento.
Y de nuevo, esto no es todo. El equilibrador no solo recibió el código de respuesta 503. Es recomendable proporcionar este código con el encabezado "Reintentar después" al responder. El encabezado deja claro al equilibrador que no debe perturbar este nodo en esta ruta durante un tiempo específico. Y las siguientes solicitudes de envío de SMS se enviará de inmediato a un nodo que no tenga problemas con la puerta de enlace de SMS.
Como podemos ver, la confiabilidad de JSON-RPC está sobrevalorada. De hecho, es más fácil organizar la consistencia de la base de datos. Pero la víctima, en este caso, será la fiabilidad del sistema en su conjunto.
La conclusión es muy similar a la anterior. Cuando la infraestructura es simple, lo obvio de JSON-RPC es sin duda su ventaja. Si un proyecto implica una alta disponibilidad con una gran carga, REST parece una solución más precisa, aunque más compleja.
Umbral de entrada REST por debajo
Creo que el análisis anterior, desacreditando los estereotipos establecidos sobre RPC, mostró claramente que el umbral para ingresar a REST es indudablemente más alto que en RPC. Esto se debe a la necesidad de una comprensión profunda de HTTP, así como a la necesidad de tener un conocimiento suficiente sobre los elementos de infraestructura existentes que pueden y deben usarse en proyectos WEB.
Entonces, ¿por qué muchas personas piensan que REST será más fácil? Mi opinión personal es que esta aparente simplicidad proviene del REST que se manifiesta. Es decir REST no es un protocolo, sino un concepto ... REST no tiene un estándar, hay algunas recomendaciones ... REST no es más complicado que HTTP. La aparente libertad y anarquía atrae a los "artistas libres".
Sin lugar a dudas, REST no es más complicado que HTTP. Pero HTTP en sí es un protocolo bien diseñado que ha sido probado durante décadas. Si no hay una comprensión profunda de HTTP en sí, REST no puede ser juzgado.
Pero sobre RPC, puedes. Es suficiente para tomar su especificación. Entonces, ¿necesitas un tonto JSON-RPC ? ¿O es astuto REST? Depende de usted.
Sinceramente espero no haber perdido su tiempo en vano.