 El diagrama de la computadora CS-1 muestra que la mayoría está dedicada a alimentar y enfriar el motor de escala de oblea (WSE) gigante "procesador en placa". Foto: Sistemas Cerebras
El diagrama de la computadora CS-1 muestra que la mayoría está dedicada a alimentar y enfriar el motor de escala de oblea (WSE) gigante "procesador en placa". Foto: Sistemas CerebrasEn agosto de 2019, Cerebras Systems y su socio de fabricación TSMC anunciaron el
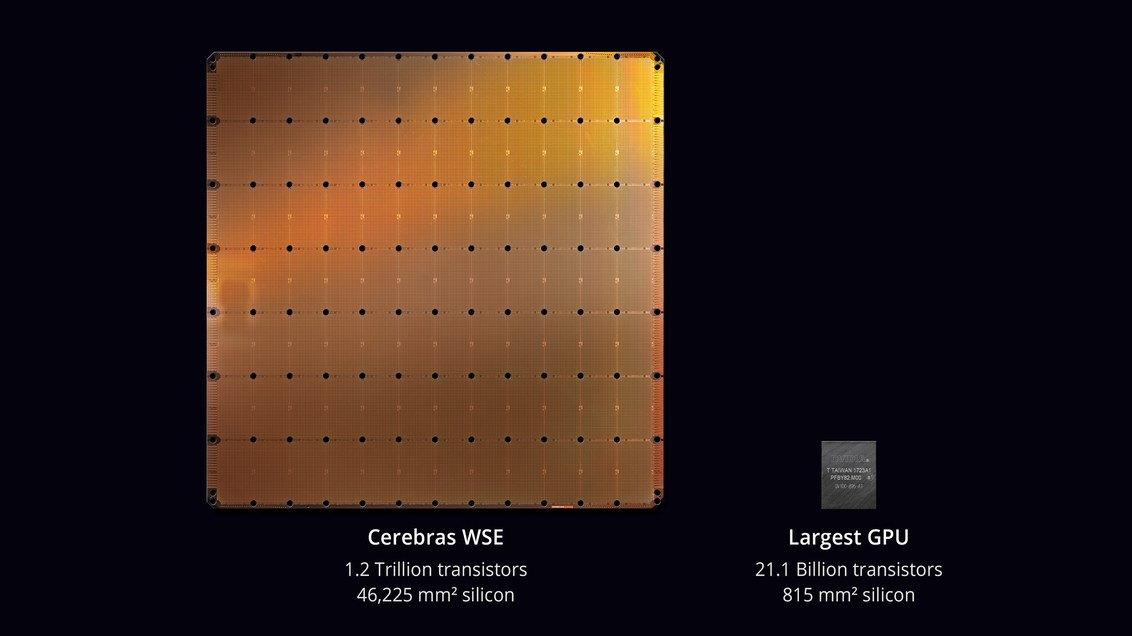
chip más grande en la historia de la tecnología informática . Con un área de 46,225 mm² y 1.2 trillones de transistores, el chip Wafer Scale Engine (WSE) es aproximadamente 56.7 veces más grande que la GPU más grande (21.1 billones de transistores, 815 mm²).
Los escépticos dijeron que desarrollar un procesador no es la tarea más difícil. ¿Pero así es como funcionará en una computadora real? ¿Cuál es el porcentaje de trabajo defectuoso? ¿Qué potencia y enfriamiento se requerirán? ¿Cuánto costará tal máquina?
Parece que los ingenieros de Cerebras Systems y TSMC pudieron resolver estos problemas. El 18 de noviembre de 2019, en la conferencia
Supercomputing 2019 , presentaron oficialmente el
CS-1 , "la computadora más rápida del mundo para la computación en el campo del aprendizaje automático y la inteligencia artificial".
Las primeras copias de CS-1 ya se han enviado a los clientes. Uno de ellos está instalado en el Laboratorio Nacional Argonne del Departamento de Energía de EE. UU., En el que comenzará el ensamblaje de la supercomputadora más poderosa en los EE. UU. A partir de los
módulos Aurora en la nueva arquitectura de GPU Intel . Otro cliente fue el Laboratorio Nacional de Livermore.
El procesador con 400,000 núcleos está diseñado para centros de datos para procesar computación en el campo del aprendizaje automático y la inteligencia artificial. Cerebras afirma que la computadora entrena los sistemas de inteligencia artificial por órdenes de magnitud de manera más eficiente que el equipo existente. El rendimiento CS-1 es equivalente a "cientos de servidores basados en GPU" que consumen cientos de kilovatios. Al mismo tiempo, ocupa solo 15 unidades en el bastidor del servidor y consume unos 17 kW.
 Procesador WSE. Foto: Sistemas Cerebras
Procesador WSE. Foto: Sistemas CerebrasAndrew Feldman, CEO y cofundador de Cerebras Systems, dice que el CS-1 es "la computadora de inteligencia artificial más rápida del mundo". Lo comparó con los grupos de TPU de Google y observó que cada uno de ellos "toma 10 bastidores y consume más de 100 kilovatios para proporcionar un tercio del rendimiento de una sola instalación CS-1".
 Computadora CS-1. Foto: Sistemas Cerebras
Computadora CS-1. Foto: Sistemas CerebrasAprender redes neuronales grandes puede llevar semanas en una computadora estándar. Instalar un CS-1 con un chip procesador de 400,000 núcleos y 1.2 billones de transistores realiza esta tarea en minutos o incluso segundos,
escribe IEEE Spectrum. Sin embargo, Cerebras no proporcionó resultados de pruebas reales para probar declaraciones de alto rendimiento como
las pruebas MLPerf . En cambio, la compañía estableció contactos directamente con clientes potenciales y permitió entrenar sus propios modelos de redes neuronales en CS-1.
Los analistas dicen que este enfoque no es inusual: "Todos manejan sus propios modelos que han desarrollado para su propio negocio", dijo
Karl Freund , analista de inteligencia artificial de Moor Insights & Strategies. "Esto es lo único que le importa a los clientes".
Muchas compañías están desarrollando chips especializados para IA, incluidos representantes tradicionales de la industria como Intel, Qualcomm, así como varias nuevas empresas en los Estados Unidos, el Reino Unido y China. Google ha desarrollado un chip específicamente para redes neuronales: un procesador tensorial o TPU. Varios otros fabricantes hicieron lo mismo. Los sistemas de inteligencia artificial funcionan en modo de subprocesos múltiples, y el cuello de botella está moviendo datos entre los chips: "Conectar los chips en realidad los ralentiza y requiere mucha energía",
explica Subramanian Iyer, profesor de la Universidad de California en Los Ángeles que se especializa en Desarrollo de chips para inteligencia artificial. Los fabricantes de equipos están explorando muchas opciones diferentes. Algunos intentan expandir las conexiones entre procesos.
Fundada hace tres años, la startup Cerebras, que recibió más de $ 200 millones en financiamiento de riesgo, ha propuesto un nuevo enfoque. La idea es guardar todos los datos en un chip gigante, y así acelerar los cálculos.

Toda la placa de microcircuito se divide en 400,000 secciones más pequeñas (núcleos), dado que algunas de ellas no funcionarán. El chip está diseñado con la capacidad de enrutar áreas defectuosas. Los núcleos programables SLAC (núcleos de álgebra lineal dispersa) están optimizados para álgebra lineal, es decir, para cálculos en espacio vectorial. La compañía también desarrolló la tecnología de "cosecha dispersa" para mejorar el rendimiento informático en cargas de trabajo dispersas (que contienen ceros), como el aprendizaje profundo. Los vectores y las matrices en el espacio vectorial generalmente contienen muchos elementos cero (del 50% al 98%), por lo que en las GPU tradicionales, la mayor parte del cálculo se desperdicia. En contraste, los núcleos SLAC prefiltran los datos nulos.
El sistema Swarm proporciona comunicaciones entre los núcleos con un rendimiento de 100 petabits por segundo. Enrutamiento de hardware, latencia medida en nanosegundos.
El costo de una computadora no se llama. Los expertos independientes creen que el precio real depende del porcentaje de matrimonio. Además, el rendimiento del chip y cuántos núcleos están operativos en muestras reales no se conocen de manera confiable.
Software
Cerebras ha anunciado algunos detalles sobre la parte de software del sistema CS-1. El software permite a los usuarios crear sus propios modelos de aprendizaje automático utilizando marcos estándar como
PyTorch y
TensorFlow . Luego, el sistema distribuye 400,000 núcleos y 18 gigabytes de memoria SRAM en el chip a las capas de la red neuronal para que todas las capas completen su trabajo aproximadamente al mismo tiempo que sus vecinos (tarea de optimización). Como resultado, la información es procesada por todas las capas sin demora. Con un subsistema de E / S Ethernet de 12 puertos y 100 Gigabits, el CS-1 puede procesar 1.2 terabits de datos por segundo.
La conversión de la red neuronal de origen a una representación ejecutable optimizada (Cerebras Linear Algebra Intermediate Representation, CLAIR) es realizada por el Cerebras Graph Compiler (CGC). El compilador asigna recursos informáticos y memoria para cada parte del gráfico, y luego los compara con la matriz informática. Luego, la ruta de comunicación se calcula de acuerdo con la estructura interna de la placa, única para cada red.
 Distribución de operaciones matemáticas de una red neuronal por núcleos de procesador. Foto : Cerebras
Distribución de operaciones matemáticas de una red neuronal por núcleos de procesador. Foto : CerebrasDebido al enorme tamaño de WSE, todas las capas en una red neuronal se ubican simultáneamente en ella y funcionan en paralelo. Este enfoque es exclusivo de WSE: ningún otro dispositivo tiene suficiente memoria interna para adaptarse a todas las capas en un chip a la vez, dice Cerebras. Tal arquitectura con la colocación de toda la red neuronal en un chip proporciona enormes ventajas debido a su alto rendimiento y baja latencia.
El software puede realizar la tarea de optimización para múltiples computadoras, permitiendo que el grupo de computadoras actúe como una máquina grande. Un grupo de 32 computadoras CS-1 muestra un aumento de rendimiento de aproximadamente 32 veces, lo que indica una escalabilidad muy buena. Feldman dice que esto es diferente de los clústeres basados en GPU: “Hoy, cuando creas un clúster de GPU, no se comporta como una gran máquina. Tienes muchos autos pequeños ”.
El
comunicado de prensa dice que el Laboratorio Nacional de Argonne ha estado trabajando con Cerebras durante dos años: "Al implementar CS-1, aumentamos dramáticamente la velocidad de entrenamiento de redes neuronales, lo que nos permitió aumentar la productividad de nuestra investigación y lograr un éxito significativo".
Una de las primeras cargas para CS-1 será una
simulación de red neuronal de una colisión de agujeros negros y ondas gravitacionales, que se crean como resultado de esta colisión. La versión anterior de esta tarea funcionaba en 1024 de 4392 nodos de la supercomputadora
Theta .