 Basado en mis actuaciones en Highload ++ y DataFest Minsk 2019
Basado en mis actuaciones en Highload ++ y DataFest Minsk 2019Para muchos, el correo de hoy es una parte integral de la vida en línea. Con su ayuda, realizamos correspondencia comercial, almacenamos todo tipo de información importante relacionada con las finanzas, reservas de hotel, pago y mucho más. A mediados de 2018, formulamos una estrategia de producto de desarrollo de correo. ¿Qué debería ser el correo moderno?
El correo debe ser
inteligente , es decir, ayudar a los usuarios a navegar por la creciente cantidad de información: filtrar, estructurar y proporcionarla de la manera más conveniente. Debería ser
útil , ya que permite directamente en el buzón resolver varios problemas, por ejemplo, pagar multas (una función que, desafortunadamente, uso). Y al mismo tiempo, por supuesto, el correo debe proporcionar protección de la información cortando el correo no deseado y protegiendo contra los piratas informáticos, es decir, estar
seguro .
Estas áreas determinan una serie de tareas clave, muchas de las cuales pueden resolverse eficazmente mediante el aprendizaje automático. Aquí hay ejemplos de características existentes desarrolladas como parte de la estrategia, una para cada dirección.
- Respuesta inteligente Hay una función de respuesta inteligente en el correo. La red neuronal analiza el texto de la carta, comprende su significado y propósito, y como resultado ofrece las tres opciones de respuesta más adecuadas: positiva, negativa y neutral. Esto ayuda a ahorrar significativamente tiempo al responder cartas, y también a menudo responde de manera no estándar y divertida para usted.
- Agrupación de cartas relacionadas con pedidos en tiendas online. A menudo hacemos compras en Internet y, por regla general, las tiendas pueden enviar varias cartas para cada pedido. Por ejemplo, desde AliExpress, el servicio más grande, hay muchas letras para un pedido, y pensamos que en el caso de la terminal su número puede llegar a 29. Por lo tanto, usando el modelo de Reconocimiento de Entidades con Nombre, seleccionamos el número de pedido y otra información del texto y grupo Todas las letras en un hilo. También mostramos la información básica sobre el pedido en un cuadro separado, lo que facilita el trabajo con este tipo de letras.
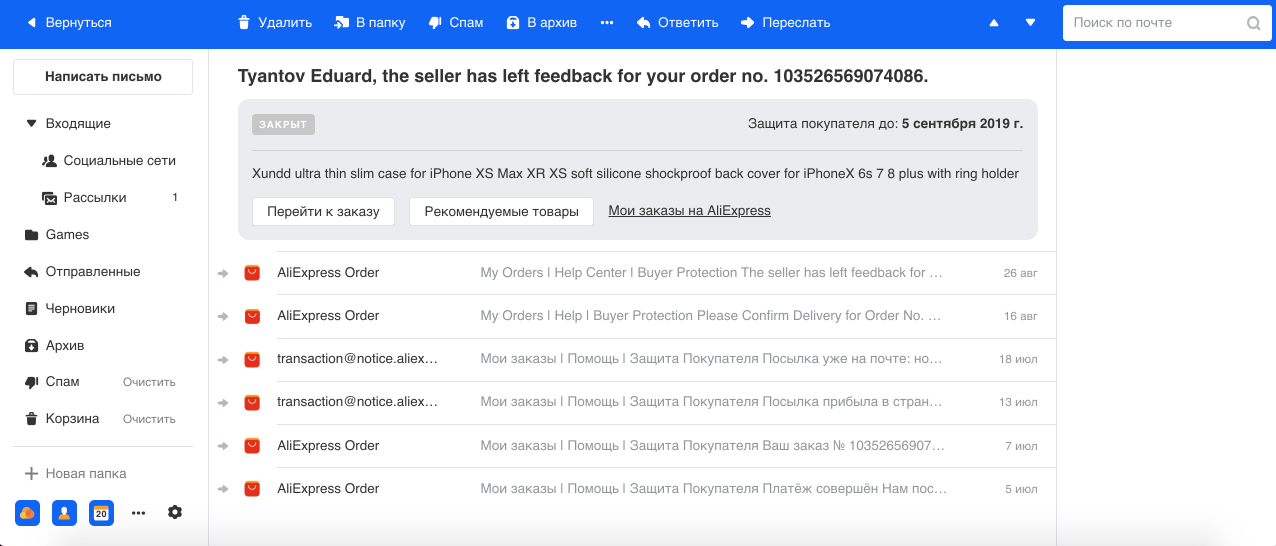
- Antiphishing El phishing es un tipo de correo electrónico fraudulento particularmente peligroso con la ayuda de los atacantes que intentan obtener información financiera (incluidas las tarjetas bancarias de los usuarios) e inicios de sesión. Dichas cartas imitan las reales enviadas por el servicio, incluso visualmente. Por lo tanto, con la ayuda de Computer Vision, reconocemos los logotipos y el estilo de las letras de las grandes empresas (por ejemplo, Mail.ru, Sberbank, Alpha) y tenemos esto en cuenta, junto con el texto y otros signos en nuestros clasificadores de spam y phishing.
Aprendizaje automático
Un poco sobre el aprendizaje automático en el correo en general. El correo es un sistema altamente cargado: en nuestros servidores, un promedio de 1.500 millones de cartas por día pasa a 30 millones de usuarios de DAU. Sirve todas las funciones y características necesarias de unos 30 sistemas de aprendizaje automático.
Cada carta pasa por un transportador de clasificación completo. Primero cortamos el spam y dejamos buenos correos electrónicos. Los usuarios a menudo no notan la operación de antispam, porque el 95-99% del spam ni siquiera entra en la carpeta correspondiente. El reconocimiento de spam es una parte muy importante de nuestro sistema, y lo más difícil, ya que en la esfera anti-spam hay una adaptación constante entre los sistemas de defensa y ataque, lo que proporciona un desafío continuo de ingeniería para nuestro equipo.
A continuación, separamos las letras de las personas y los robots. Las cartas de las personas son las más importantes, por lo que para ellas ofrecemos funciones como Respuesta inteligente. Las cartas de los robots se dividen en dos partes: transaccionales: son cartas importantes de los servicios, por ejemplo, confirmación de compras o reservas de hotel, finanzas e información, son publicidad comercial, descuentos.
Creemos que las cartas transaccionales tienen el mismo valor que la correspondencia personal. Deben estar a la mano, porque a menudo es necesario encontrar rápidamente información sobre el pedido o reservar un boleto, y pasamos tiempo buscando estas cartas. Por lo tanto, por conveniencia, los dividimos automáticamente en seis categorías principales: viajes, reservas, finanzas, boletos, registros y, finalmente, multas.
Los boletines son el grupo más grande y probablemente menos importante que no requiere una reacción instantánea, ya que nada significativo cambiará en la vida del usuario si no lee dicha carta. En nuestra nueva interfaz, los colapsamos en dos hilos: redes sociales y boletines informativos, lo que borra visualmente el buzón y deja solo a la vista cartas importantes.

Operación
Una gran cantidad de sistemas causa muchas dificultades en la operación. Después de todo, los modelos se degradan con el tiempo, como cualquier software: los signos se descomponen, las máquinas fallan, se despliega un código. Además, los datos cambian constantemente: se agregan nuevos, se transforma el patrón de comportamiento del usuario, etc., por lo tanto, el modelo sin el soporte adecuado funcionará peor y peor con el tiempo.
No debemos olvidar que cuanto más profundo es el aprendizaje automático que penetra en la vida de los usuarios, mayor es el impacto que tienen en el ecosistema y, como resultado, más pérdidas financieras o ganancias pueden obtener los jugadores del mercado. Por lo tanto, en un número cada vez mayor de áreas, los jugadores se están adaptando al trabajo de los algoritmos ML (ejemplos clásicos son publicidad, búsqueda y antispam ya mencionados).
Además, las tareas de aprendizaje automático tienen una peculiaridad: cualquier cambio, aunque insignificante, en el sistema puede generar mucho trabajo con el modelo: trabajar con datos, reentrenamiento, implementación, lo que puede llevar semanas o meses. Por lo tanto, cuanto más rápido sea el entorno en el que operan sus modelos, más esfuerzo requiere su soporte. Un equipo puede crear muchos sistemas y disfrutarlos, y luego gastar casi todos los recursos en su soporte, sin la capacidad de hacer algo nuevo. Una vez nos encontramos con tal situación una vez en un equipo anti-spam. Y llegaron a la conclusión obvia de que el mantenimiento debería automatizarse.
Automatización
¿Qué se puede automatizar? De hecho, casi todo. Identifiqué cuatro áreas que definen la infraestructura del aprendizaje automático:
- recolección de datos;
- educación continua;
- despliegue;
- pruebas y monitoreo.
Si el entorno es inestable y cambia constantemente, entonces toda la infraestructura alrededor del modelo es mucho más importante que el modelo en sí. Puede ser el buen clasificador lineal antiguo, pero si aplica correctamente los signos y establece buenos comentarios de los usuarios, funcionará mucho mejor que los modelos de vanguardia con todas las campanas y silbatos.
Bucle de retroalimentación
Este ciclo combina la recopilación de datos, más capacitación e implementación; de hecho, todo el ciclo de actualización del modelo. ¿Por qué es esto importante? Mira el calendario de inscripción por correo:

El desarrollador de aprendizaje automático ha introducido un modelo antibot que evita que los bots se registren por correo. El gráfico cae a un valor donde solo quedan usuarios reales. ¡Todo es genial! Pero pasan cuatro horas, los botvods ajustan sus guiones, y todo vuelve al punto de partida. En esta implementación, el desarrollador pasó un mes agregando características y un modelo de capacitación, pero el spammer pudo adaptarse en cuatro horas.
Para no ser tan dolorosamente doloroso y no tener que rehacer todo más tarde, debemos pensar inicialmente en cómo se verá el ciclo de retroalimentación y qué haremos si cambia el entorno. Comencemos recopilando datos: este es el combustible para nuestros algoritmos.
Recogida de datos
Está claro que las redes neuronales modernas, cuantos más datos, mejor, y de hecho, generan usuarios del producto. Los usuarios pueden ayudarnos marcando los datos, pero no puede abusar de ellos, porque en algún momento los usuarios se cansarán de completar sus modelos y cambiarán a otro producto.
Uno de los errores más comunes (aquí hago una referencia sobre Andrew Ng) es que la orientación a las métricas en el conjunto de datos de prueba es demasiado fuerte, y no a los comentarios del usuario, que en realidad es la medida principal de la calidad del trabajo, ya que creamos un producto para el usuario. Si el usuario no entiende o no le gusta el trabajo del modelo, entonces todo es perecedero.
Por lo tanto, el usuario siempre debe poder votar, debe darle una herramienta para comentarios. Si creemos que una carta relacionada con las finanzas ha llegado al cuadro, debemos marcarla como "finanzas" y dibujar un botón en el que el usuario pueda hacer clic y decir que no es finanzas.
Calidad de retroalimentación
Hablemos de la calidad de los comentarios de los usuarios. En primer lugar, usted y el usuario pueden poner diferentes significados en un concepto. Por ejemplo, usted y los gerentes de producto piensan que “finanzas” son cartas del banco, y el usuario cree que la carta de mi abuela sobre la jubilación también se refiere a las finanzas. En segundo lugar, hay usuarios a los que les encanta presionar botones sin ninguna lógica. En tercer lugar, el usuario puede estar profundamente equivocado en sus conclusiones. Un vívido ejemplo de nuestra práctica es la introducción del clasificador de
spam nigeriano , un tipo muy divertido de spam, cuando se le pide al usuario que recolecte varios millones de dólares de un pariente lejano que se encuentra repentinamente en África. Después de presentar este clasificador, verificamos los clics de "No spam" en estas letras, y resultó que el 80% de ellos son jugosos spam nigerianos, lo que sugiere que los usuarios pueden ser extremadamente confiables.
Y no olvidemos que no solo las personas pueden presionar los botones, sino todo tipo de bots que pretenden ser un navegador. Así que la retroalimentación cruda no es buena para aprender. ¿Qué se puede hacer con esta información?
Usamos dos enfoques:
- Comentarios de ML relacionados . Por ejemplo, tenemos un sistema de antibióticos en línea que, como mencioné, toma una decisión rápida en función de un número limitado de signos. Y hay un segundo sistema lento que funciona ex post. Ella tiene más datos sobre el usuario, sobre su comportamiento, etc. Como resultado, se toma la decisión más equilibrada, respectivamente, tiene mayor precisión e integridad. Puede dirigir la diferencia en el trabajo de estos sistemas en el primero como datos para la capacitación. Por lo tanto, un sistema más simple siempre intentará acercarse a un rendimiento más complejo.
- Clasificación de clics . Simplemente puede clasificar cada clic del usuario, evaluar su validez y capacidad de uso. Hacemos esto en el correo antispam utilizando los atributos del usuario, su historial, los atributos del remitente, el texto en sí y el resultado de los clasificadores. Como resultado, obtenemos un sistema automático que valida los comentarios de los usuarios. Y dado que es necesario entrenarlo con mucha menos frecuencia, su trabajo puede convertirse en el principal para todos los demás sistemas. La precisión es la principal prioridad en este modelo, porque entrenar a un modelo en datos inexactos está lleno de consecuencias.
Mientras limpiamos datos y reentrenamos nuestros sistemas ML, no debemos olvidarnos de los usuarios, porque para nosotros miles, millones de errores en un gráfico son estadísticas, y para un usuario, cada error es una tragedia. Además del hecho de que el usuario necesita vivir de alguna manera con su error en el producto, él, después de la retroalimentación, espera la exclusión de una situación similar en el futuro. Por lo tanto, siempre debe dar a los usuarios no solo la oportunidad de votar, sino también corregir el comportamiento de los sistemas ML, creando, por ejemplo, heurística personal para cada clic de retroalimentación, en el caso del correo, es posible filtrar dichos mensajes por remitente y encabezado para este usuario.
También debe utilizar el modelo en función de algunos informes o llamadas de soporte en modo semiautomático o manual, para que otros usuarios tampoco sufran problemas similares.
Heurística para el aprendizaje
Hay dos problemas con estas heurísticas y muletas. La primera es que el número cada vez mayor de muletas es difícil de mantener, sin mencionar su calidad y rendimiento a larga distancia. El segundo problema es que el error puede no ser de frecuencia, y unos pocos clics para volver a entrenar el modelo no serán suficientes. Parecería que estos dos efectos no relacionados pueden nivelarse sustancialmente si se aplica el siguiente enfoque.
- Crea una muleta temporal.
- Dirigimos sus datos al modelo; se recupera regularmente, incluidos los datos recibidos. Aquí, por supuesto, es importante que la heurística tenga una alta precisión para no reducir la calidad de los datos en el conjunto de entrenamiento.
- Luego colgamos el monitoreo para el funcionamiento de la muleta, y si después de algún tiempo la muleta ya no funciona y está completamente cubierta por el modelo, puede retirarla con seguridad. Ahora es poco probable que este problema se repita.
Entonces el ejército de muletas es muy útil. Lo principal es que su servicio es urgente, no permanente.
Educación adicional
La reentrenamiento es el proceso de agregar nuevos datos obtenidos como resultado de los comentarios de los usuarios u otros sistemas, y capacitar el modelo existente sobre ellos. Puede haber varios problemas con el reciclaje:
- Es posible que un modelo simplemente no sea compatible con la educación superior y aprenda solo desde cero.
- En ninguna parte del libro de la naturaleza está escrito que la educación continua ciertamente mejorará la calidad del trabajo en la producción. A menudo sucede todo lo contrario, es decir, solo es posible el deterioro.
- Los cambios pueden ser impredecibles. Este es un punto bastante sutil que hemos identificado por nosotros mismos. Incluso si el nuevo modelo en la prueba A / B muestra resultados similares en comparación con el actual, esto no significa en absoluto que funcionará de manera idéntica. Su trabajo puede diferir en un uno por ciento, lo que puede traer nuevos errores o devolver los ya corregidos. Tanto nosotros como los usuarios ya sabemos cómo vivir con los errores actuales, y cuando ocurre una gran cantidad de errores nuevos, el usuario también puede no entender lo que está sucediendo, porque espera un comportamiento predecible.
Por lo tanto, lo más importante en el reentrenamiento está garantizado para mejorar el modelo, o al menos no empeorarlo.
Lo primero que viene a la mente cuando hablamos de educación continua es el enfoque de aprendizaje activo. ¿Qué significa esto? Por ejemplo, el clasificador determina si la carta se relaciona con las finanzas, y alrededor de su límite de toma de decisiones, agregamos una selección de ejemplos marcados. Esto funciona bien, por ejemplo, en publicidad, donde hay muchos comentarios y puedes entrenar al modelo en línea. Y si hay poca retroalimentación, obtenemos una muestra fuertemente sesgada en relación con la producción de la distribución de datos, en base a la cual es imposible evaluar el comportamiento del modelo durante la operación.
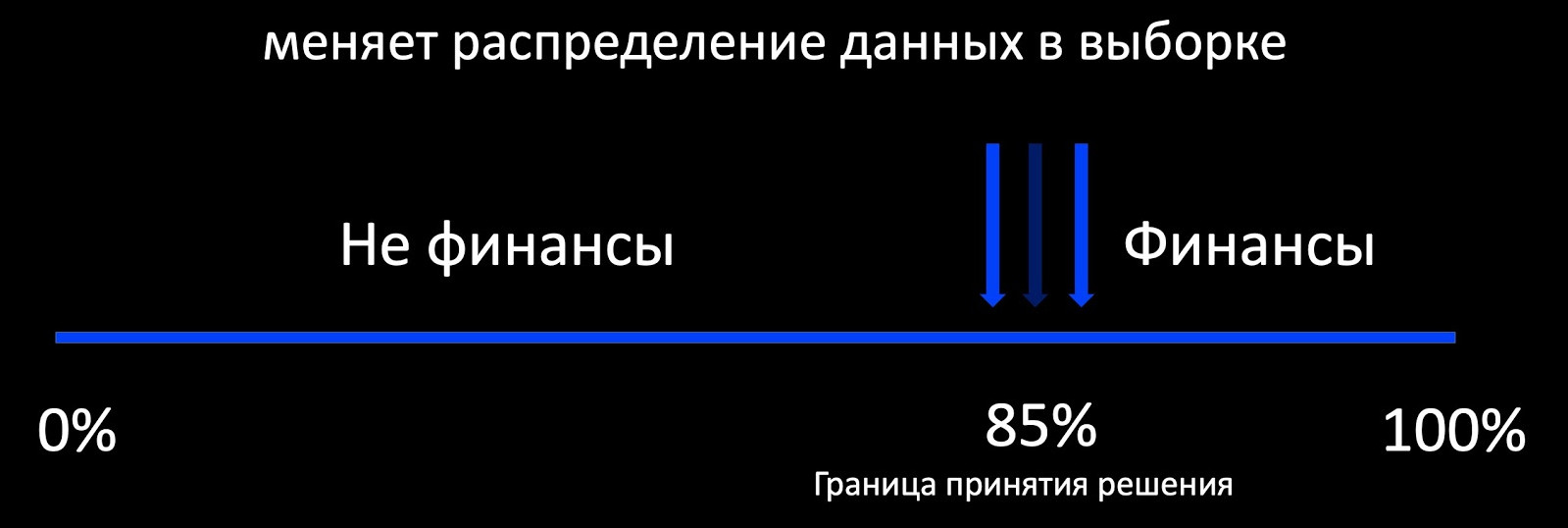
De hecho, nuestro objetivo es preservar patrones antiguos, modelos ya conocidos, y adquirir otros nuevos. Aquí, la continuidad es importante. El modelo, que a menudo lanzamos con gran dificultad, ya funciona, por lo que podemos centrarnos en su rendimiento.
En el correo, se utilizan diferentes modelos: árboles, lineales, redes neuronales. Para cada uno, hacemos nuestro propio algoritmo de reentrenamiento. En el proceso de reentrenamiento, obtenemos no solo datos nuevos, sino también características nuevas que tendremos en cuenta en todos los algoritmos a continuación.
Modelos lineales
Digamos que tenemos una regresión logística. Creamos el modelo de pérdida a partir de los siguientes componentes:
- LogLoss en nuevos datos;
- regularizamos el peso de los nuevos signos (no tocamos los viejos);
- aprendemos de datos antiguos para preservar patrones antiguos;
- y, quizás, lo más importante: adjuntamos la regularización armónica, que garantiza un ligero cambio en los pesos en relación con el modelo anterior de acuerdo con la norma.
Dado que cada componente de pérdida tiene coeficientes, podemos elegir los valores óptimos para nuestra tarea de validación cruzada o en función de los requisitos del producto.

Arboles
Pasemos a los árboles de decisión. Filmamos el siguiente algoritmo de reentrenamiento de árbol:
- Un bosque de 100-300 árboles funciona en el producto, que fue entrenado en el antiguo conjunto de datos.
- Al final, eliminamos M = 5 piezas y agregamos 2M = 10 nuevas, entrenadas en todo el conjunto de datos, pero con un alto peso de los nuevos datos, lo que naturalmente garantiza un cambio incremental en el modelo.
Obviamente, con el tiempo, el número de árboles aumenta significativamente, y deben reducirse periódicamente para adaptarse a los tiempos. Para hacer esto, utilizamos la ahora omnipresente destilación de conocimiento (KD). Brevemente sobre el principio de su trabajo.
- Tenemos el modelo actual "complejo". Comenzamos en el conjunto de datos de entrenamiento y obtenemos la distribución de probabilidad de las clases en la salida.
- A continuación, enseñamos al modelo de estudiante (un modelo con menos árboles en este caso) a repetir los resultados del modelo, utilizando la distribución de clases como una variable objetivo.
- Es importante tener en cuenta aquí que no usamos marcado de conjunto de datos de ninguna manera, y por lo tanto podemos usar datos arbitrarios. Por supuesto, usamos una muestra de datos de la secuencia de combate como muestra de entrenamiento para el modelo de estudiante. Por lo tanto, el conjunto de entrenamiento nos permite garantizar la precisión del modelo, y una muestra del flujo garantiza un rendimiento similar en la distribución de producción, compensando el desplazamiento de la muestra de entrenamiento.
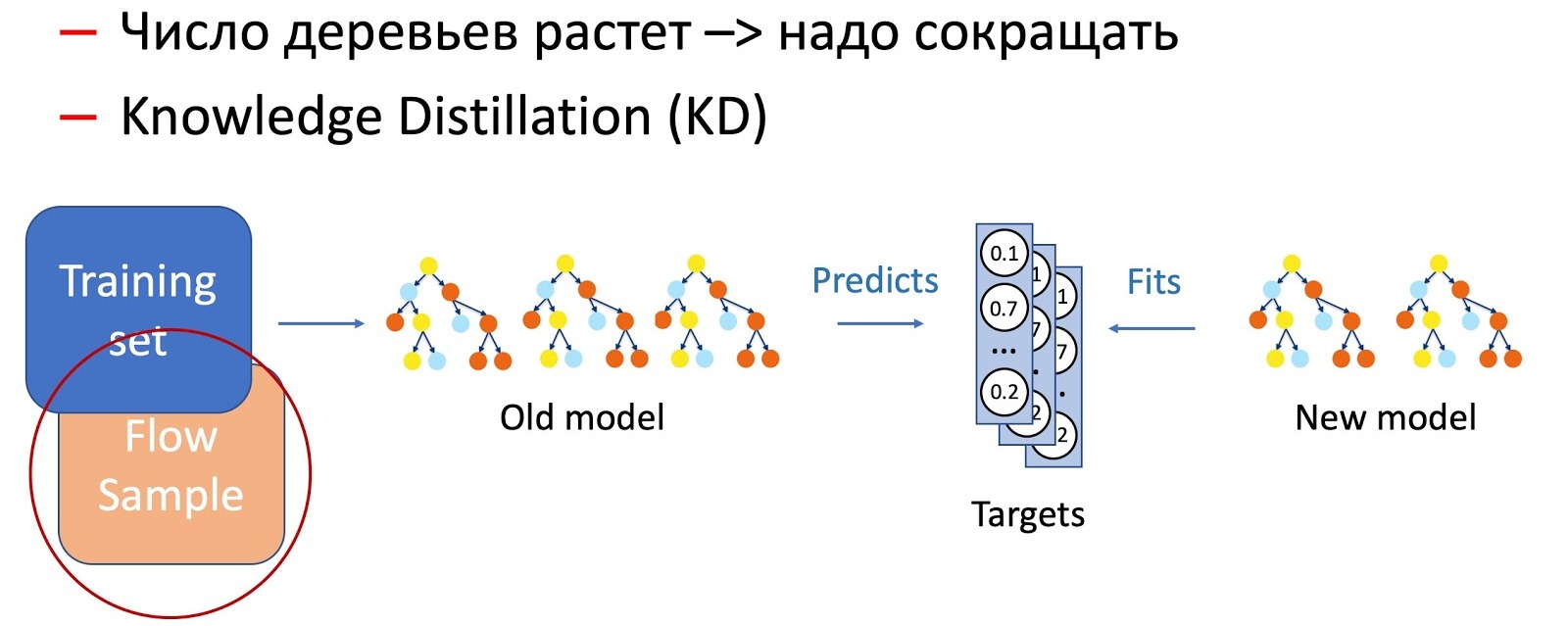
La combinación de estas dos técnicas (agregar árboles y reducir periódicamente su número mediante la Destilación del conocimiento) garantiza la introducción de nuevos patrones y una continuidad completa.
Con la ayuda de KD, también realizamos la distinción de operaciones con características de un modelo, por ejemplo, eliminación de características y trabajo en pases. En nuestro caso, tenemos una serie de características estadísticas importantes (por remitentes, hashes de texto, URL, etc.) que se almacenan en una base de datos que tiene la propiedad de rechazar. El modelo, por supuesto, no está listo para tal desarrollo de eventos, ya que no hay situaciones de falla en el conjunto de entrenamiento. En tales casos, combinamos KD y técnicas de aumento: cuando entrenamos para una parte de los datos, eliminamos o ponemos a cero los signos necesarios, y tomamos las etiquetas (salidas del modelo actual) como las iniciales, el modelo de estudiante nos enseña a repetir esta distribución.
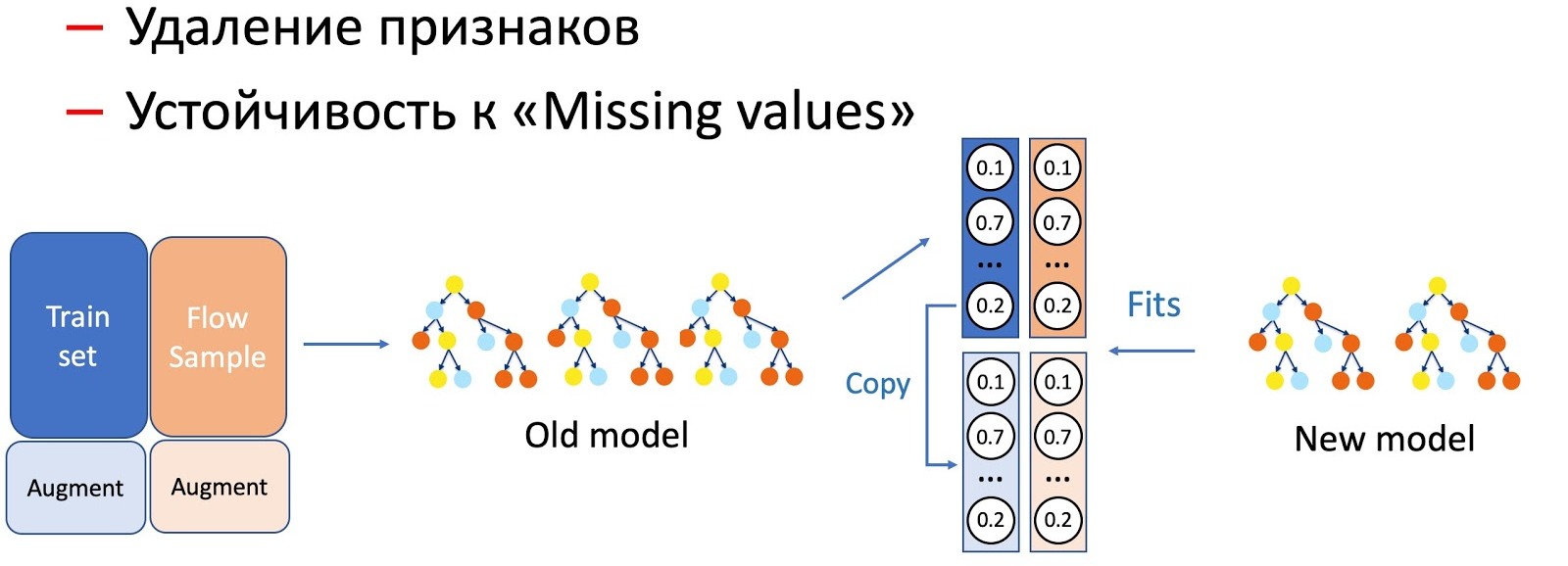
Notamos que cuanto más grave es la manipulación de los modelos, mayor es el porcentaje de flujo de muestra requerido.
Para eliminar características, la operación más simple, solo se requiere una pequeña parte del flujo, ya que solo cambian un par de características, y el modelo actual estudiado en el mismo conjunto: la diferencia es mínima. Para simplificar el modelo (reduciendo el número de árboles varias veces), ya se requieren de 50 a 50. Y omitir características estadísticas importantes que afectan seriamente el rendimiento del modelo requiere aún más flujo para igualar el trabajo del nuevo modelo, que es resistente a las omisiones, en todo tipo de letras.
Texto rápido
Pasemos a FastText. Permítame recordarle que la representación (incrustación) de una palabra consiste en la suma de la incrustación de la palabra en sí y de todas sus letras N-gramas, generalmente trigramas. Dado que los trigramas pueden ser bastante, se utiliza Bucket Hashing, es decir, la conversión de todo el espacio en un cierto hashmap fijo. Como resultado, la matriz de peso se obtiene por la dimensión de la capa interna por el número de palabras + cubo.
Durante la educación superior, aparecen nuevos signos: palabras y trigramas. En el entrenamiento posterior estándar de Facebook, no sucede nada significativo. Solo se vuelven a entrenar los pesos antiguos con entropía cruzada en datos nuevos. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
Implementar
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
Resumen
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- Implementar . La métrica automática reduce en gran medida el tiempo que lleva implementar modelos. Al monitorear las estadísticas y la distribución de la toma de decisiones, el número de caídas de los usuarios es obligatorio para su buen sueño y días libres productivos.
Bueno, espero que lo que lea le ayude a mejorar sus sistemas de ML más rápido, acelerar su lanzamiento al mercado y hacerlos más confiables, reduciendo la cantidad de estrés del trabajo.