Los procesadores multinúcleo son comunes. Tarde o temprano, cualquier programador práctico tendrá que entrar en el laberinto de la programación multiproceso y encontrarse con los "monstruos" que lo habitan. Hablemos sobre dónde comenzar de esta manera y qué herramientas y enfoques ayudarán a salir victoriosos. Hice este informe a futuros participantes en la
pasantía de Yandex durante todo el
año .
- Me llamo Seva Minkov. Trabajo en el departamento de infraestructura en la nube del departamento de búsqueda. Principalmente trato con el backend. Escribo en diferentes idiomas, pero la mayoría de las veces es Java y los idiomas que se ejecutan en la máquina virtual Java (JVM).
Nuestro equipo está desarrollando una nube interna en la que se lanzan casi todos los servicios de Yandex, tanto conocidos públicamente como Search, Mail y Alice, así como varios servicios internos, máquinas virtuales, así como tareas MapReduce de corta duración y tareas de aprendizaje automático.
Nuestra nube no es estática: la empresa está creciendo, la cantidad de servicios y los recursos que consumen están aumentando. Y nuestro equipo a menudo enfrenta los desafíos de escalar y mejorar el rendimiento. Logramos esto mediante el uso de todas las herramientas disponibles, incluida la escala vertical, es decir, acelerando los componentes individuales del sistema hasta reescribir algunos algoritmos de un solo subproceso para que funcionen más rápido. Hacemos escalado horizontal: trituramos el sistema en partes pequeñas para lograr un mejor rendimiento al agregar servidores, procesadores, núcleos, etc.
Y la programación multiproceso nos ayuda mucho en esto. Hablaremos de él hoy: de dónde vino, por qué es relevante; qué es un modelo de memoria y cómo se representa generalmente en Java. Hablaremos de algunos aspectos prácticos sobre cómo probar sus aplicaciones y verificar su corrección.
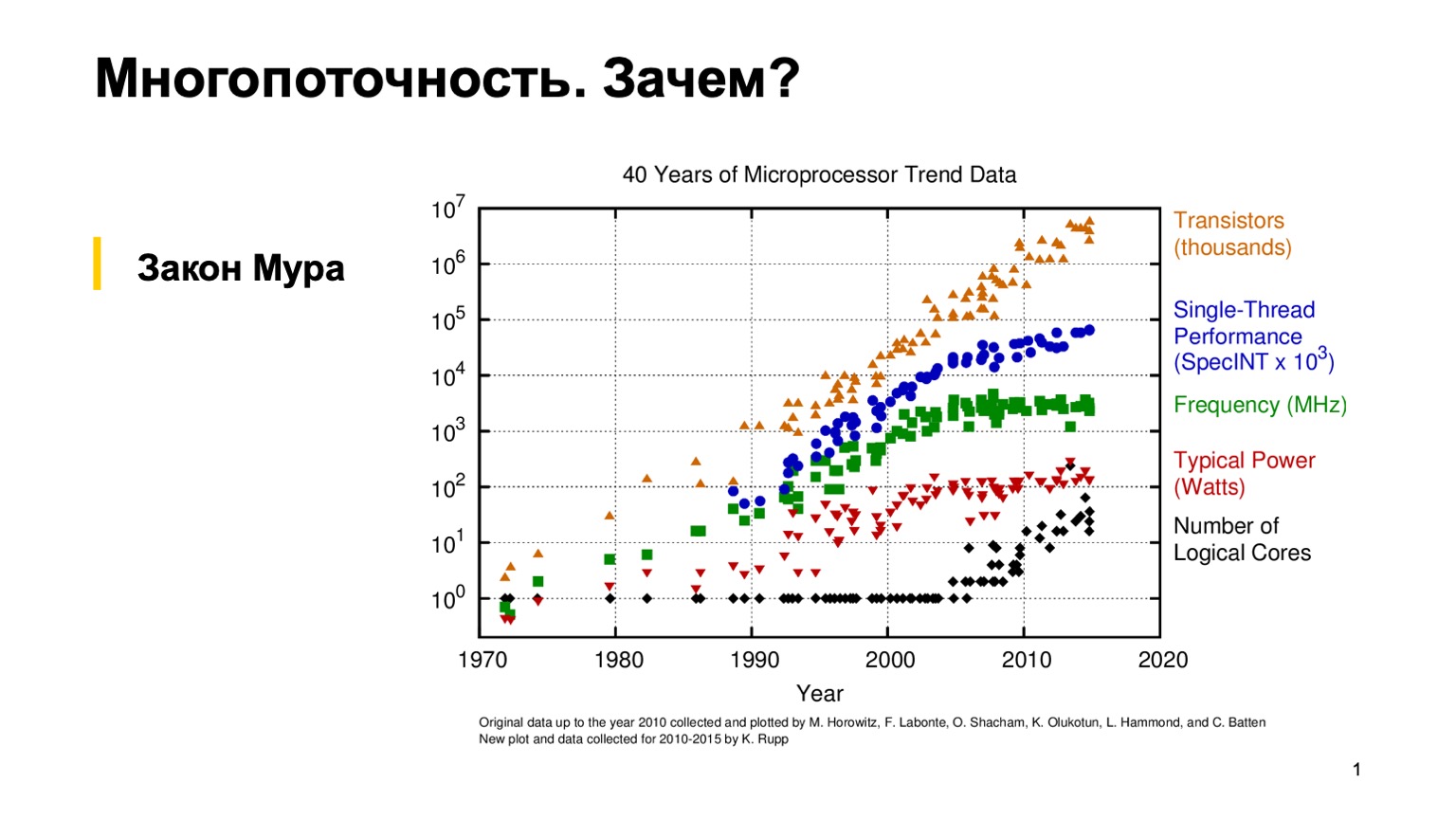
Para comenzar, veamos este interesante cuadro, que muestra las tendencias en las características de los microprocesadores en los últimos 40 años. Hace unos 10-15 años, cuando el césped era más verde y los procesadores tenían un solo subproceso, un programador ordinario podía escribir un programa correcto de un solo subproceso y luego confiar en la ley empírica de Moore. Él dice que los procesadores son dos veces más rápidos cada dos años. Como puede ver, en algún lugar alrededor de 2005, por varias razones, los fabricantes de microprocesadores cambiaron a una arquitectura de múltiples núcleos y comenzaron a aumentar el número de núcleos lógicos. Y la ganancia de rendimiento de un solo núcleo dejó de obedecer la ley de Moore, y el poder de procesamiento de un núcleo comenzó a crecer más lentamente. Esto hizo una revolución, y los programadores comunes tuvieron que usar programación paralela para usar esta ganancia de rendimiento.
Como estamos practicando, trataremos de escribir un programa simple de subprocesos múltiples y veremos por ti mismo cómo funciona.
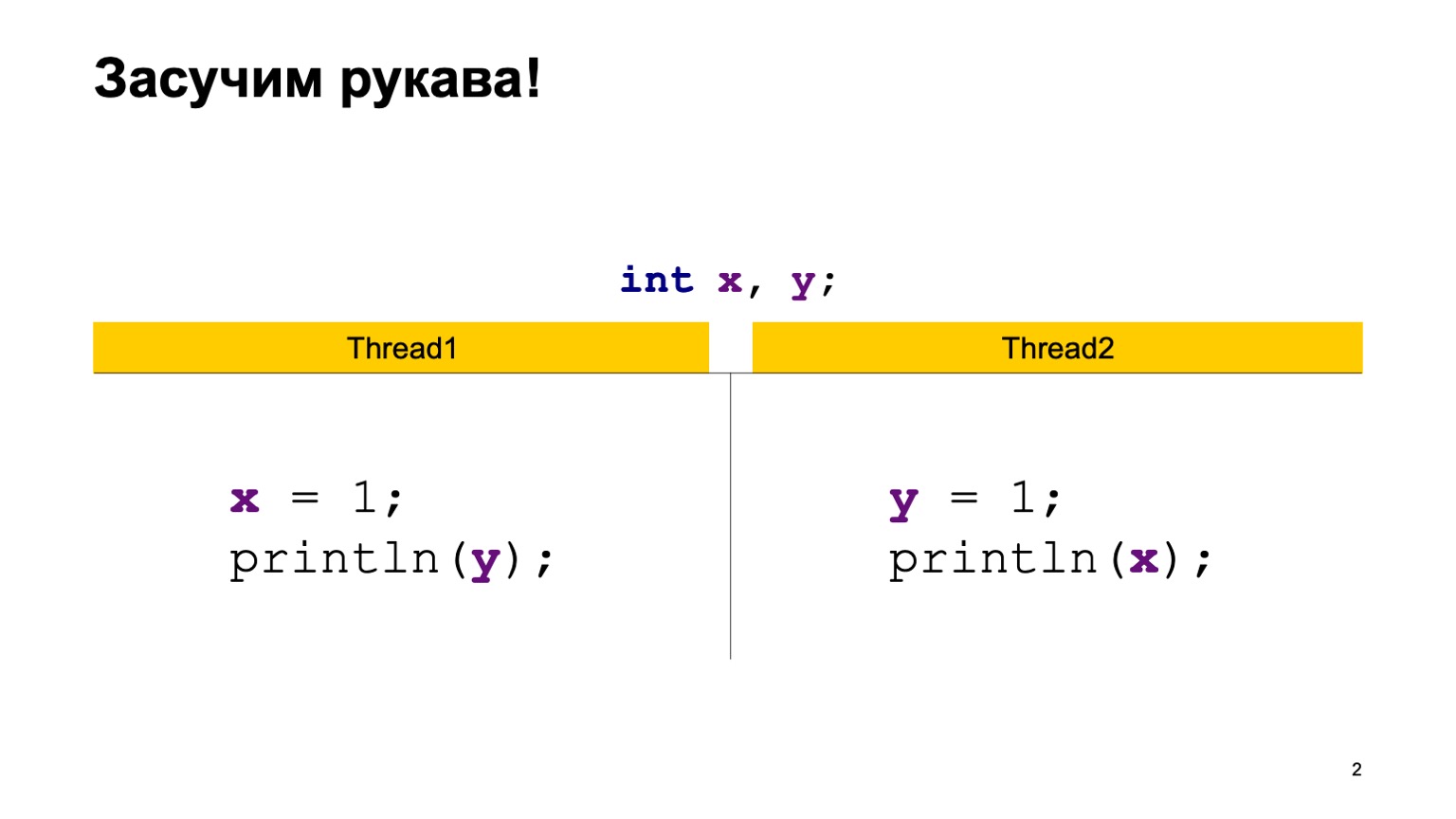
Como ejemplo, tomemos una tarea bastante simple de lectura cruzada de registros. Tengamos dos variables compartidas X e Y, primero inicializadas con el valor predeterminado (cero) y dos flujos. Cada hilo escribe en una variable y lee otra. En este caso, Thread1 escribe una unidad en X y lee Y. El segundo thread hace lo mismo, solo al revés.
Una implementación simple de Java podría verse más o menos así.

Escribiremos la clase ReadWriteTest, tendrá dos variables estáticas X e Y. Directamente en el método principal, construimos dos hilos Thread1 y Thread2, le damos a cada uno de ellos una entrada de función lambda que se ejecutará en el momento en que se ejecute el hilo. Ponga el código de la diapositiva anterior allí y comience dos hilos.
El orden en que comienzan los hilos es, en cierto sentido, impredecible. Depende de cómo el sistema operativo subprocesos subprocesos. En consecuencia, podemos tener diferentes versiones. Parece entender cómo funciona todo esto, tendremos que ejecutar este programa muchas veces, luego agregar el resultado y ver con qué frecuencia se encontrará esta o aquella respuesta en el programa.

Para no reinventar la rueda, podemos usar una herramienta preparada. Esto se llama jcstress, la utilidad de pruebas de estrés de concurrencia de Java que forma parte del proyecto OpenJDK.
Esta utilidad proporciona un marco para escribir pruebas de estrés. En este caso, el código de la diapositiva anterior se reescribe con bastante facilidad. En primer lugar, colgaremos la anotación jcstress Test en la clase, lo que simplemente hace que nuestros scripts de prueba sean visibles para la utilidad. También lo marcamos con la clase State, que dice que la clase contiene datos que pueden cambiar: tanto modificados como leídos desde diferentes flujos. Declaramos dos métodos, thread1 y thread2, y los marcamos con la anotación Actor. La anotación de actor significa que el método debe ejecutarse en un hilo separado. jcstress garantiza que cada uno de estos métodos se ejecutará en un hilo separado en exactamente una instancia de la clase State. El orden en que se lanzarán no se especifica específicamente. Y el resultado se escribirá en algún objeto II_Result que se muestra en la diapositiva. Podemos suponer que se trata de una tupla de dos valores numéricos, que se presentan solo mediante el método de inyección de dependencia, del que Cyril habló en un informe anterior.
Antes de comenzar esta prueba, pensemos qué conclusiones pueden dar los comandos y qué valores podemos agregar en r1 y en r2.

Para hacer esto, usamos el llamado modelo de alternancia. De una forma u otra, cada una de las operaciones: lectura o escritura, se realiza en algún orden. Basta con analizar todas estas opciones y ver qué resultados obtendremos.

Supongamos que una de las posibles variantes de eventos es que el subproceso uno se ejecuta completamente antes que el segundo. Primero, agregamos uno a X, leemos cero desde Y, ya que no había entradas. Luego escribieron uno en Y y leyeron uno en X, ya que la primera transmisión ya había logrado hacer esto.
La primera respuesta es cero uno.

La segunda variante del desarrollo de eventos es exactamente lo contrario: la secuencia dos se ejecutó antes que la secuencia uno.

En consecuencia, obtenemos un resultado espejo de un cero.

Hay alrededor de cuatro opciones más que dan el mismo resultado cuando tenemos la ejecución de hilos completamente confundida. Por ejemplo, registramos una unidad en un flujo en X, en el segundo logramos tener una unidad en Y, y calculamos uno a uno. Luego puede ver qué otras opciones hay como ejercicio en el hogar.

Parece que revisamos todas las opciones posibles, no hay nada más. Ejecutemos la utilidad y veamos qué conclusión da.

La salida se parece a una tabla. La primera columna enumera los resultados que agregamos en II_Result (la utilidad ejecuta este código millones de veces) y la cantidad de casos en los que se encontró un resultado en particular. Pero probablemente este informe no hubiera sido si todo hubiera sido tan simple.
De hecho, en esta conclusión también podemos ver el resultado cero-cero, que es difícil de explicar con el modelo de alternancia. Parece que una de las opciones posibles es que alguien directamente en el código de transmisión tomó y reorganizó las líneas.
Pensemos por qué sucedió y cómo podemos vivir con eso. También le pido que preste atención al hecho de que la opción uno a uno se encontró específicamente en mi máquina muy raramente. De 130 millones de actuaciones, solo 154 actuaciones resultaron en uno a uno. Y por el contrario, cero-cero ocurre muy a menudo, en casi el 30% de los casos.

Entonces, para resumir algunos resultados intermedios que todos vimos con usted. En primer lugar, podríamos entender que la interacción de los flujos a través de la memoria no es trivial. El modelo de rotación que utilizamos no funciona. Vimos algunos cambios. Podría suceder por muchas razones.
Por ejemplo, podríamos ver algunos "efectos relativistas" del hierro. Esto puede pensarse de la siguiente manera: en un ciclo de reloj de un procesador de 3 GHz, la luz viaja unos 10 cm en el vacío. El protocolo para leer y escribir en la memoria del procesador es complicado y a veces se necesitan cientos de ciclos de reloj para transferir el valor de un núcleo a otro. En consecuencia, un núcleo puede parecer ver el pasado. El resultado después del registro ocurrió, pero vemos el valor anterior. Además, los procesadores tampoco se detienen y pueden cambiar las instrucciones en algunos lugares.
Los compiladores de optimización modernos pueden conducir a la misma permutación. Para lograr el máximo rendimiento de un solo subproceso, también pueden intercambiar instrucciones para que esto no rompa la exactitud de un programa de un solo subproceso. Pero en los programas de subprocesos múltiples puede dar lugar a efectos interesantes que hemos visto.
Y la segunda, probablemente la conclusión principal: vimos que los programas multiproceso no están determinados fundamentalmente. Los programas de subproceso único dependen principalmente de algunos invariantes en la entrada y la salida, y son deterministas; dado que el generador de números aleatorios y la entrada del usuario son parámetros de entrada.
Esto hace las cosas muy complicadas: es difícil entender lo que hace el programa y es difícil probarlo.
Sobre la complejidad de las pruebas, podemos agregar que el mismo resultado se encontró solo 154 veces de 130 millones de llamadas. La probabilidad de ocurrencia de este resultado es una millonésima. En producción, esto significa que dicho error puede reproducirse después de semanas. Y ciertamente sucederá en algún lugar el domingo por la noche, cuando no esperabas esto en absoluto.

Pensemos cómo deberíamos ser y qué queremos generalmente de nuestra lengua para dormir tranquilo el domingo por la noche. Primero, necesitamos una herramienta que nos permita predecir el comportamiento del programa y emitir juicios sobre su ejecución. En segundo lugar, necesitamos herramientas de lenguaje que nos permitan influir en las permutaciones y los efectos; pueden ser del hardware, el compilador, etc. Me gustaría saber menos sobre cómo funciona un procesador en particular, qué optimizaciones puede hacer el compilador y usar la abreviatura que vino del mundo de Java. Escribir una vez, ejecutar en cualquier lugar: escriba una vez el código multiproceso correcto para que funcione en todas las plataformas.

Estas preguntas y requisitos que hemos enumerado surgieron en las mentes de los desarrolladores durante mucho tiempo y de los teóricos y profesionales. Como cualquier tarea compleja con un alto nivel de complejidad, se resolvió introduciendo el concepto de alguna máquina abstracta. Todos nosotros, desarrolladores en lenguajes de programación de alto nivel, no escribimos para ningún hardware en particular, no para ese modelo de procesador, sino que escribimos alguna máquina abstracta. Y la especificación del lenguaje está diseñada para describir su comportamiento de tal manera que concilie estos tres mundos. Por un lado, dejemos que los desarrolladores de compiladores y procesadores hagan sus optimizaciones y nos exploten ligeramente, programadores que ya escriben en un lenguaje en particular.
El modelo de memoria ocupa una posición central en esta máquina abstracta. Debería responder una pregunta: si leo una variable X en alguna secuencia, ¿cuál de las últimas entradas puedo ver allí? Se intentó por primera vez formalizar el modelo de memoria en el lenguaje Java, todos los demás modelos de memoria aparecieron más tarde. Digamos que C ++ 11 es casi una copia del modelo de memoria Java con algunos cambios.
Había varios modelos de memoria en Java. Inicialmente, el llamado modelo de memoria "en forma de campana", fue reconocido como infructuoso, ya que obstaculizó el trabajo de los programadores que escriben en Java y prohibió algunas optimizaciones para el compilador, que son bastante apropiadas para ellos. En consecuencia, como parte del proceso comunitario JSR-133, se escribió un modelo de memoria moderno.
Como tenemos la escritura en forma de especificación, intentemos analizarla y comprender lo que realmente está sucediendo dentro.

Hay algun problema Levanta las manos, quien abrió la especificación del idioma y leyó lo que estaba sucediendo allí. ¿Y cuántos de ustedes han leído el modelo de memoria del párrafo 17.4? Una pequeña sorpresa te espera. La especificación del lenguaje se describe básicamente en un lenguaje bastante comprensible. Pero el modelo de memoria está lleno de, digamos, algo de matemática hardcore. Hay inclusiones en griego, muchos términos matemáticos del cierre transitivo de la serie, la unión de dos órdenes, etc.
Lamentablemente, no hay otra manera. La única cosa en la que puede confiar al escribir programas multiproceso es la especificación. Ella tendrá que leer y entender. Te recomiendo mucho Además, cuando leí la especificación por primera vez, tuve esas impresiones.
¿Por qué es tan difícil? Fui por el camino equivocado y te advierto mucho que actúes como yo.
Lo tomé, busqué en Internet qué es un modelo de memoria. Encontré un libro llamado JSR-133 Cookbook for Compiler Writers. Ella describe cómo un desarrollador de compiladores puede implementar este modelo de memoria de una manera simple. El problema es que esta es una implementación específica, y no se puede usar para juzgar todo el modelo de memoria en general.
De todos modos, intentemos hacer un pequeño intento en las principales conclusiones que se pueden entender del modelo de memoria Java.

Puede haber muchas ejecuciones de su programa multiproceso. Nosotros mismos vimos esto en el ejemplo de nuestro programa antes. En el ejemplo más simple, ya tuvimos cuatro resultados de su implementación. Y la tarea del modelo de memoria Java es decir cuáles de estas ejecuciones son correctas y cuáles deberían prohibirse. Y postula tres cosas. La primera es que, dentro del marco de un hilo, su tarea se ejecuta de forma pseudo-secuencial. Esto implica que el compilador puede intercambiar operaciones, el procesador también puede ejecutar instrucciones en paralelo, intercambiarlas. Pero deben hacer esto para que los efectos visibles de la ejecución de su programa sean los mismos que si se ejecutaran directamente secuencialmente.
En segundo lugar, en el lenguaje están prohibidos los llamados significados de la nada tomados de la nada. Desafortunadamente, no tenemos tiempo para mostrarlo, pero hay casos en que el compilador realmente puede realizar una conversión tal que todo será correcto en un programa de subproceso único, y es posible que tenga un registro en un programa de subproceso múltiple que no hizo.
En consecuencia, el modelo de memoria dice que leer cualquier variable devolverá el valor predeterminado o algunos de los resultados de la grabación que alguna vez realizó otro comando. Y las acciones restantes se pueden interpretar como secuenciales, si están conectadas por una relación de orden parcial que ocurre antes. Y este es ahora el único lugar donde necesitamos matemáticas. Relación parcial, esto se debe a que no todas las operaciones de lectura, escritura de variables, están conectadas por relación. Tiene las propiedades de reflexividad, transitividad y antisimetría.

Hablemos con más detalle sobre lo que sucede antes que en sí mismo. La primera regla es que vincula todas las operaciones dentro de un solo hilo. Si ha escrito dentro de un hilo que X es igual a uno, Y es igual a uno; se afirma que las operaciones de escritura en X están relacionadas con lo que sucede antes de Y. Es decir, X sucede antes de Y. Y también vincula algunas acciones especiales, las llamadas acciones de sincronización. Lea más en la especificación. Por ejemplo, esto es escribir y leer desde una variable volátil, bloquear / desbloquear en un monitor, ingresar al bloque sincronizado y salir del bloque sincronizado. Un punto muy importante es que todas las acciones de sincronización en su programa ven subprocesos en exactamente el mismo orden, como si se estuvieran ejecutando uno por uno.
Y sucede antes de vincular algunos pares de estas acciones. No importa en qué acciones de sincronización de subprocesos tengan lugar. Es importante que pasen, por ejemplo, sobre una variable volátil. La especificación dice, digamos, que escribir en la variable volátil ocurre antes de cualquier otra acción posterior. Esto se refiere precisamente a la manera en que tuvimos acciones de sincronización.
Y lo más importante de todo esto es que la regla sucede antes de la coherencia, que solo responde a la pregunta más importante sobre el modelo de memoria. Se puede interpretar de la siguiente manera. Si hay una cadena de operaciones de lectura / escritura en una variable y están conectadas por una cadena de relaciones anteriores, entonces la lectura definitivamente debería ver el último registro en esta cadena. Si no está allí, puede ver cualquier otro valor, cualquier otro registro o valor predeterminado. Ahora puedes exhalar, con las definiciones básicas que hemos terminado.
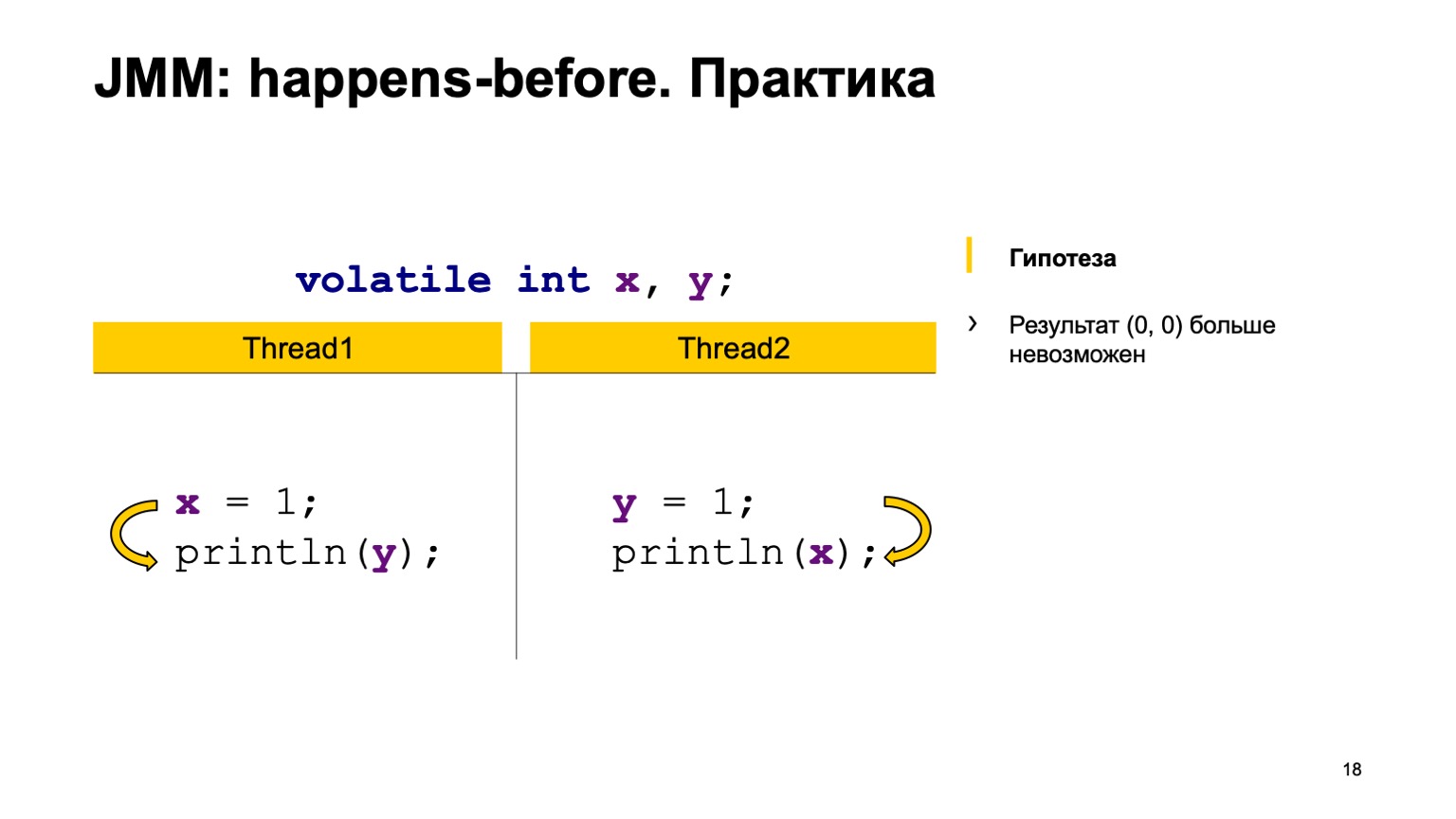
¿Intentamos probar la teoría en la práctica? Tomemos un ejemplo con una lectura cruzada de registros y simplemente agreguemos el modificador volátil a las variables X e Y. Intentemos probar la hipótesis de que ya no veremos el valor cero-cero. Para hacer esto, solo use las reglas que expresé anteriormente.
Arreglaremos sucederá antes en un hilo. Escribir en X sucede antes de leer desde Y y en el segundo hilo. Escribir en Y sucede antes de leer en X.
Y luego tenemos cuatro acciones de sincronización: escribir en X, escribir en Y, leer desde X, leer desde Y. Pueden aparecer en algún orden, y un par puede ocurrir en dos casos.
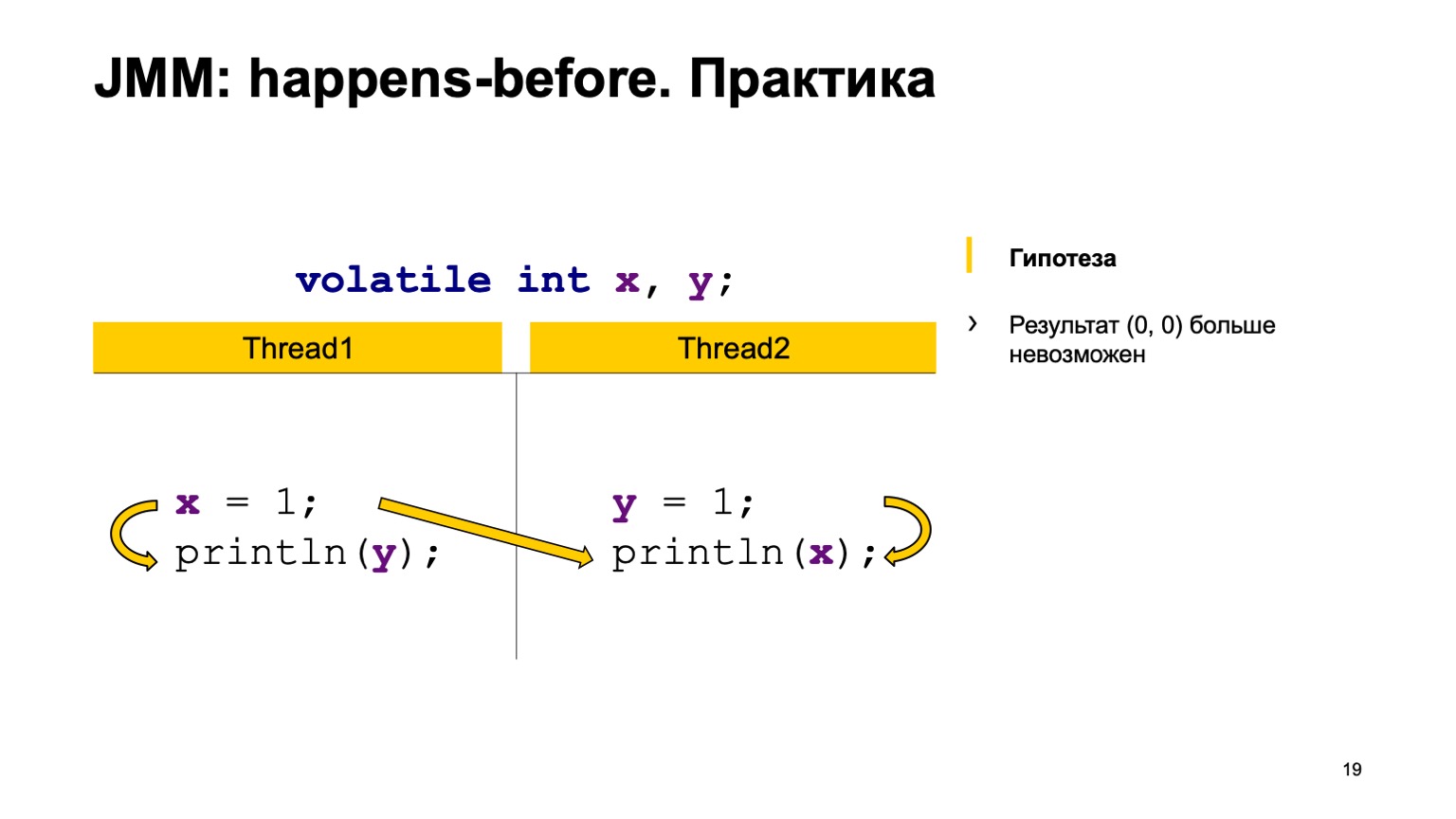
Por ejemplo, escribir en X en la secuencia uno ocurrió antes que leer desde X en la secuencia dos (ocurre antes de que ocurra). Como puede ver aquí, la relación no está relacionada con Y. El resultado de la lectura de Y puede devolvernos el valor predeterminado o el valor que registró la segunda transmisión. Una lectura de X siempre debe ver una unidad. En consecuencia, nuestras opciones pueden ser cero uno, uno.
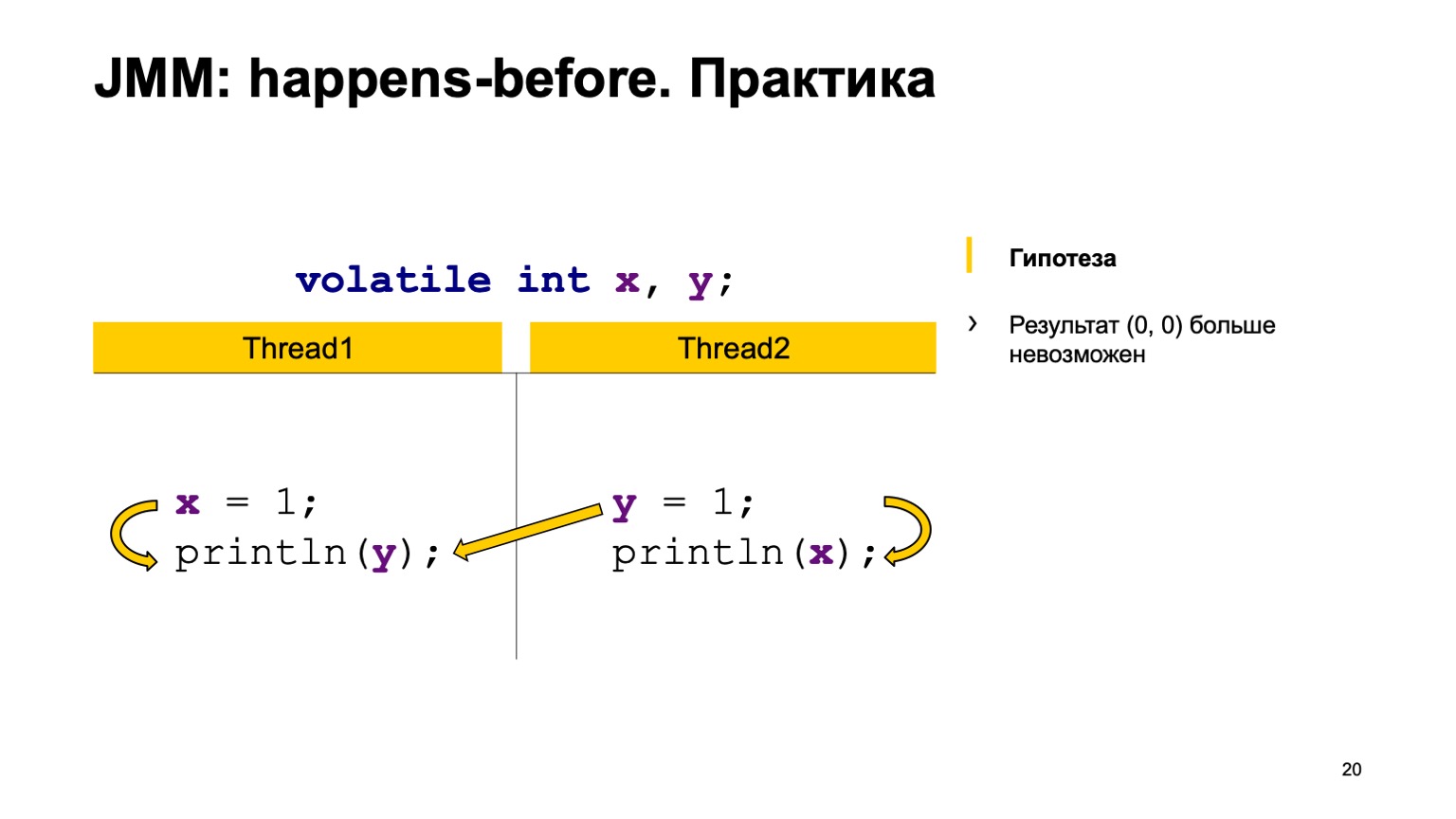
El segundo caso es cuando surge una conexión. Esto es lo mismo: escribir en Y sucede antes de leer desde Y. Además, no hay conexión entre X. En consecuencia, el resultado es el mismo, solo que allí obtienes uno-cero, cero-uno. Teóricamente, podemos probar el comportamiento de nuestro nuevo programa.

Puedes comprobarlo en la práctica. Tome y agregue la palabra clave volátil en nuestra prueba. Corre y observa que, de hecho, en nuestro país este valor nunca se reproducirá. happens-before — . .

, . volatile Z volatile, . , Z; , , , Z. happens-before . , Z , . .
, , — put value. — get value . happens-before , , put value happens-before get value. , happens-before , volatile, . , , — put happens-before get.

, . -, . , , . , . , , . , . , , , , .
-, , jcstress. : , JVM . , .
, . — «The Art of Multiprocessor Programming» . , happens-before, , . . — «Java Concurrency in Practice» . , . , , . . .
, performance- Oracle, Red Hat. , Java- , . JMM.
Puedes leer el blog de Roman Elizarov . Enseñó, en mi opinión, la programación multiproceso ITMO. Tiene un blog ligeramente abandonado, pero puedes leerlo, buscar sus conferencias y discursos en YouTube. En general, muy adecuado, aconsejo. Gracias a todos.