Los lenguajes OO más populares proporcionan una herramienta como un modificador para acceder a un método o campo. Y esto es bueno para programadores experimentados, pero ese no es el lugar para comenzar con la encapsulación. A continuación explicaré por qué.
 Descargo de responsabilidad.
Descargo de responsabilidad. Este artículo no es un llamado a la acción y no establece que existe la única forma razonablemente correcta de ocultar datos. Este artículo está destinado a ofrecer al lector una perspectiva posiblemente nueva sobre la encapsulación. Hay muchas situaciones en las que los modificadores de acceso son preferibles, pero esta no es una razón para guardar silencio sobre las interfaces.
En general, la encapsulación se define como un medio de ocultar la implementación interna de un objeto del cliente para mantener la integridad del objeto y ocultar la complejidad de esta implementación muy interna.
Hay varias formas de lograr este ocultamiento. Uno es el uso de modificadores de acceso, el otro es el uso de interfaces (protocolos, archivos de encabezado, ...). Hay otras características difíciles, pero el artículo no trata sobre ellas.
Los modificadores de acceso a primera vista pueden parecer más poderosos en términos de ocultar la implementación, ya que dan control sobre cada campo individualmente y dan más opciones de acceso. En realidad, esto es en parte solo un atajo para crear varias interfaces para la clase. Los modificadores de acceso proporcionan oportunidades no más amplias que las interfaces, porque se expresan a sí mismas excepto por un detalle. Sobre ella abajo.
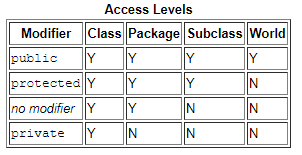 Visibilidad de campo indicada por diferentes modificadores de acceso en Java.
Visibilidad de campo indicada por diferentes modificadores de acceso en Java.El fragmento de código a continuación muestra una clase con modificadores de acceso a métodos y representaciones equivalentes en forma de interfaces.
public class ConsistentObject { public void methodA() { } protected void methodB() { } void methodC() { } private void methodD() { } } public interface IPublicConsistentObject { void methodA() { } } public interface IProtectedConsistentObject: IPublicConsistentObject { void methodB() { } } public interface IDefaultConsistentObject: IProtectedConsistentObject { void methodC() { } }
Los protocolos tienen varias ventajas. Es suficiente mencionar que este es el principal medio para implementar el polimorfismo en OOP, que llega a los recién llegados mucho más tarde de lo que podría.
La única dificultad para abordar los protocolos es que necesita controlar el proceso de creación de objetos. Se necesitan plantillas de generación precisamente para proteger el código peligroso que contiene tipos específicos del código puro que funciona con interfaces. Observando esta simple regla, obtenemos la misma encapsulación que con los calificadores, pero al mismo tiempo obtenemos más flexibilidad.
Tal código en C #
public class DataAccessObject { private void readDataFromFixedSource() {
será equivalente a eso para las capacidades del cliente.
public class DataAccessObjectFactory { public IDataAccessObject createNew() { return new DataAccessObject(); } } public interface IDataAccessObject { byte[] getData(); } class DataAccessObject: IDataAccessObject { void readDataFromFixedSource() {
Debido a la existencia de modificadores de acceso, los principiantes no sabrán acerca de las interfaces durante mucho tiempo. Debido a esto, no utilizan el poder real de la OLP. Es decir, hay alguna sustitución de conceptos. Los modificadores de acceso son, sin duda, un atributo de OOP, pero también arrastran la cobertura de las interfaces que abren OOP con mucha más fuerza.
Además, las interfaces le hacen elegir conscientemente qué características puede recibir un cliente de un objeto. Es decir, tenemos la oportunidad de proporcionar protocolos completamente no relacionados para diferentes clientes, mientras que los modificadores no distinguen entre clientes. Esta es una gran ventaja a favor de las interfaces.