Quiero compartir con ustedes mi primera experiencia exitosa en la restauración de la funcionalidad completa de la base de datos de Postgres. Conocí Postgres DBMS hace medio año, antes de eso no tenía experiencia en administración de bases de datos.

Trabajo como ingeniero semi-DevOps en una gran empresa de TI. Nuestra empresa está desarrollando software para servicios altamente cargados, pero yo soy responsable del rendimiento, el mantenimiento y la implementación. Establecieron una tarea estándar para mí: actualizar la aplicación en un servidor. La aplicación está escrita en Django, durante la actualización, se realizan migraciones (cambiando la estructura de la base de datos), y antes de este proceso eliminamos el volcado completo de la base de datos a través del programa estándar pg_dump por si acaso.
Se produjo un error inesperado al eliminar el volcado (la versión de Postgres es la 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
El error
"página no válida en bloque" indica problemas en el nivel del sistema de archivos, lo cual es muy malo. En varios foros, sugirieron hacer
VACÍO COMPLETO con la opción
zero_damaged_pages para resolver este problema. Bueno, popprobeum ...
Preparación de recuperación
ATENCION! Asegúrese de hacer una copia de seguridad de Postgres antes de cualquier intento de restaurar la base de datos. Si tiene una máquina virtual, detenga la base de datos y tome una instantánea. Si no es posible tomar una instantánea, detenga la base de datos y copie el contenido del directorio de Postgres (incluidos los archivos wal) en un lugar seguro. Lo principal en nuestro negocio es no empeorar las cosas. Lee
estoComo la base de datos funcionó para mí en general, me limité al volcado de la base de datos habitual, pero excluí la tabla con datos dañados (opción
-T, --exclude-table = TABLE en pg_dump).
El servidor era físico, era imposible tomar una instantánea. La copia de seguridad se elimina, sigue adelante.
Comprobación del sistema de archivos
Antes de intentar restaurar la base de datos, debe asegurarse de que todo esté en orden con el sistema de archivos. Y en caso de errores, corríjalos, porque de lo contrario solo puede empeorarlo.
En mi caso, el sistema de archivos con la base de datos se montó en
"/ srv" y el tipo fue ext4.
Paramos la base de datos:
systemctl stop postgresql@9.5-main.service y verificamos que el sistema de archivos no sea utilizado por nadie y que pueda desmontarse usando el
comando lsof :
lsof + D / srvTodavía tenía que detener la base de datos redis, ya que también usaba
"/ srv" . A continuación, desmonté
/ srv (umount).
La comprobación del sistema de archivos se realizó utilizando la utilidad
e2fsck con la opción -f (
forzar la comprobación incluso si el sistema de archivos está marcado como limpio ):
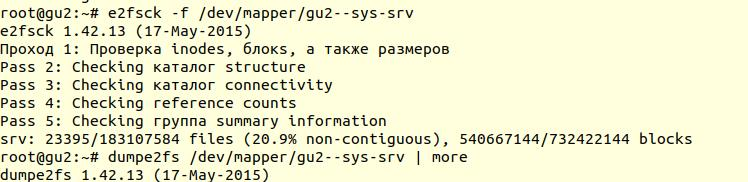
A continuación, utilizando la utilidad
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep chequeado ), puede verificar que la verificación se haya realizado:
 e2fsck
e2fsck dice que no se encontraron problemas en el nivel del sistema de archivos ext4, lo que significa que puede continuar intentando restaurar la base de datos, o más bien volver al
vacío completo (por supuesto, debe volver a montar el sistema de archivos e iniciar la base de datos).
Si su servidor es físico, asegúrese de verificar el estado de los discos (a través de
smartctl -a / dev / XXX ) o el controlador RAID para asegurarse de que el problema no esté en el nivel de hardware. En mi caso, el RAID resultó ser "de hierro", por lo que le pedí al administrador local que verificara el estado del RAID (el servidor estaba a varios cientos de kilómetros de mí). Dijo que no hubo errores, lo que significa que definitivamente podemos comenzar la restauración.
Intento 1: zero_damaged_pages
Nos conectamos a la base de datos a través de la cuenta psql con derechos de superusuario. Necesitamos exactamente el superusuario, porque solo él puede cambiar la opción
zero_damaged_pages . En mi caso, esto es postgres:
psql -h 127.0.0.1 -U postgres -s [nombre_base_datos]La opción
zero_damaged_pages es necesaria para ignorar los errores de lectura (del sitio web postgrespro):
Cuando se detecta un título de página dañado, Postgres Pro generalmente informa un error y cancela la transacción actual. Si el parámetro zero_damaged_pages está habilitado, en su lugar, el sistema emite una advertencia, borra la página dañada en la memoria y continúa el procesamiento. Este comportamiento destruye los datos, es decir, todas las líneas en la página dañada.
Active la opción e intente hacer tablas de vacío completo:
VACUUM FULL VERBOSE
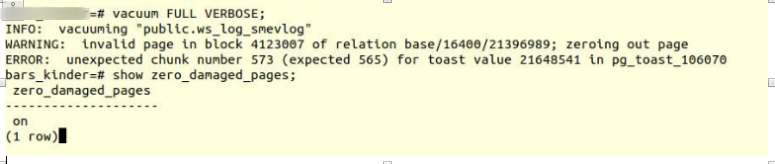
Lamentablemente, el fracaso.
Encontramos un error similar:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast : el mecanismo para almacenar "datos largos" en Postgres, si no caben en la misma página (8kb por defecto).
Intento 2: reindexar
El primer consejo de google no ayudó. Después de unos minutos de búsqueda, encontré un segundo consejo:
reindexar una tabla dañada. Conocí este consejo en muchos lugares, pero no inspiró confianza. Hacer reindexar:
reindex table ws_log_smevlog
 reindex
reindex completado sin problemas.
Sin embargo, esto no ayudó,
VACUUM FULL se bloqueó con un error similar. Como estaba acostumbrado a los fracasos, comencé a buscar consejos en Internet y encontré un
artículo bastante interesante.
Intento 3: SELECCIONAR, LIMITAR, DESPLAZAR
El artículo anterior sugirió mirar la tabla línea por línea y eliminar los datos problemáticos. Para comenzar, era necesario observar todas las líneas:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
¡En mi caso, la tabla contenía
1,628,991 filas! En el buen sentido, era necesario ocuparse de la
partición de los datos , pero este es un tema para una discusión por separado. Era sábado, ejecuté este comando en tmux y me fui a dormir:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
Por la mañana, decidí comprobar cómo iban las cosas. Para mi sorpresa, descubrí que en 2 horas solo se escaneó el 2% de los datos. No quise esperar 50 días. Otro completo fracaso.
Pero no me rendí. Me preguntaba por qué la exploración tardó tanto. De la documentación (nuevamente en postgrespro) descubrí:
OFFSET indica omitir el número especificado de líneas antes de comenzar a producir líneas.
Si se especifican OFFSET y LIMIT, el sistema primero omite las líneas de OFFSET y luego comienza a contar las líneas para limitar el LIMIT.
Al usar LIMIT, también es importante usar la cláusula ORDER BY para que las líneas de resultado se devuelvan en un orden específico. De lo contrario, se devolverán subconjuntos impredecibles de cadenas.
Obviamente, el comando anterior era erróneo: en primer lugar, no había ningún
orden , el resultado podría ser erróneo. En segundo lugar, Postgres primero tuvo que escanear y omitir las líneas de DESPLAZAMIENTO, y con un aumento en el
DESPLAZAMIENTO, el rendimiento disminuiría aún más.
Intento 4: eliminar el volcado en forma de texto
Además, se me ocurrió una idea aparentemente brillante: eliminar el volcado en forma de texto y analizar la última línea grabada.
Pero primero,
veamos la estructura de la tabla
ws_log_smevlog :

En nuestro caso, tenemos una columna
"id" , que contenía un identificador único (contador) para la fila. El plan era este:
- Comenzamos a eliminar el volcado en forma de texto (en forma de comandos sql)
- En un momento determinado, el volcado se interrumpiría debido a un error, pero el archivo de texto aún se guardaría en el disco
- Observamos el final del archivo de texto, por lo tanto, encontramos el identificador (id) de la última línea que se disparó con éxito.
Empecé a eliminar el volcado en forma de texto:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
El volcado de volcado, como se esperaba, se interrumpió con el mismo error:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Además, a través de la
cola, miré al final del volcado (
tail -5 ./my_dump.dump ) y descubrí que el volcado se interrumpió en la línea con id
186 525 . "Entonces, ¡el problema está en la línea con el id 186 526, está roto y necesita ser eliminado!", Pensé. Pero al hacer una solicitud a la base de datos:
"
Seleccione * de ws_log_smevlog donde id = 186529 " resultó que todo estaba bien con esta línea ... Las líneas con índices 186 530 - 186 540 también funcionaron sin problemas. Otra "idea brillante" falló. Más tarde, entendí por qué sucedió esto: al eliminar / cambiar datos de la tabla, no se eliminan físicamente, sino que se marcan como "tuplas muertas", luego aparece el
vacío automático y marca estas líneas como eliminadas y permite el uso de estas líneas nuevamente. Para comprender, si los datos de la tabla se modifican y se activa el vacío automático, no se almacenan secuencialmente.
Intento 5: SELECCIONAR, DESDE, DONDE id =
Las fallas nos hacen más fuertes. Nunca debes rendirte, debes llegar hasta el final y creer en ti mismo y en tus capacidades. Por lo tanto, decidí probar una opción más: solo ver todas las entradas en la base de datos de una en una. Conociendo la estructura de mi tabla (ver arriba), tenemos un campo de identificación que es único (clave primaria). En la tabla, tenemos 1,628,991 filas y la
identificación va en orden, lo que significa que simplemente podemos recorrerlas una por una:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Si alguien no entiende, el comando funciona de la siguiente manera: escanea la tabla línea por línea y envía stdout a
/ dev / null , pero si el comando SELECT falla, se muestra el texto del error (stderr se envía a la consola) y se genera una línea que contiene el error (gracias a ||, que significa que select tuvo problemas (el código de retorno del comando no es 0)).
Tuve suerte, tuve índices creados en el campo
id :

Esto significa que encontrar la línea con la identificación deseada no debería llevar mucho tiempo. En teoría, debería funcionar. Bueno, ejecuta el comando en
tmux y ve a dormir.
Por la mañana, descubrí que se vieron alrededor de 90,000 registros, lo que representa poco más del 5%. ¡Excelente resultado en comparación con el método anterior (2%)! Pero no quería esperar 20 días ...
Intento 6: SELECCIONAR, DESDE, DONDE id> = e id <
Se asignó un excelente servidor para el cliente en la base de datos: procesador dual
Intel Xeon E5-2697 v2 , ¡en nuestra ubicación había 48 hilos! La carga del servidor fue promedio, pudimos tomar alrededor de 20 hilos sin ningún problema. RAM también fue suficiente: ¡hasta 384 gigabytes!
Por lo tanto, el comando necesitaba ser paralelo:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Aquí fue posible escribir un guión hermoso y elegante, pero elegí la forma más rápida de paralelizar: dividir manualmente el rango 0-1628991 en intervalos de 100,000 registros y ejecutar 16 comandos del formulario por separado:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Pero eso no es todo. En teoría, conectarse a una base de datos también requiere algo de tiempo y recursos del sistema. Conectar 1,628,991 no fue muy razonable, de acuerdo. Por lo tanto, extraigamos 1000 filas en una conexión en lugar de una. Como resultado, el equipo se transformó en esto:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Abra 16 ventanas en la sesión tmux y ejecute los comandos:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
¡Un día después, obtuve los primeros resultados! A saber (los valores XXX y ZZZ no se han conservado):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Esto significa que tenemos tres líneas que contienen un error. la identificación del primer y segundo registro de problemas estaba entre 829,000 y 830,000, la identificación del tercero estaba entre 146,000 y 147,000. Luego, solo teníamos que encontrar el valor de identificación exacto de los registros del problema. Para hacer esto, mire nuestro rango con registros de problemas en el paso 1 e identifique la identificación:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Final feliz
Encontramos las líneas problemáticas. Entramos en la base de datos a través de psql e intentamos eliminarlos:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
Para mi sorpresa, las entradas se eliminaron sin ningún problema, incluso sin la opción
zero_damaged_pages .
Luego me conecté a la base de datos, hice
VACUUM FULL (creo que no era necesario hacerlo) y finalmente
eliminé la copia de seguridad con
éxito usando
pg_dump . El basurero protagonizó sin ningún error! El problema se resolvió de una manera tan estúpida. ¡No había límite para la alegría, después de tantos fracasos logramos encontrar una solución!
Agradecimientos y conclusiones
Esta es mi primera experiencia en la restauración de una base de datos real de Postgres. Recordaré esta experiencia por mucho tiempo.
Y finalmente, me gustaría agradecer a PostgresPro por la documentación traducida al ruso y por los
cursos en línea completamente gratuitos que ayudaron mucho durante el análisis del problema.