En el proceso de trabajar en un proyecto grande, tomar prestados módulos de otras personas y soluciones llave en mano ahorra una gran cantidad de tiempo de desarrollador y dinero de los inversores. Uno de los mayores depósitos de tales soluciones es, con mucho, Github.
Hay un pequeño truco debajo del gato que uso cuando busco y elijo soluciones github.
Imagine la tarea de desarrollar un gran sistema
OSINT , digamos que necesitamos mirar todas las soluciones disponibles en github en esta dirección. Utilizamos la búsqueda estándar global de github para la palabra clave osint. Obtenemos 1124 repositorios, la capacidad de filtrar por la ubicación de la búsqueda de palabras clave (código, commits, issuse, etc.), por el lenguaje de ejecución. Y ordene por varios atributos (como mayoría / pocos inicios, horquillas, etc.).
La decisión se toma de acuerdo con varios criterios: funcionalidad, número de estrellas, soporte de proyectos, lenguaje de desarrollo.
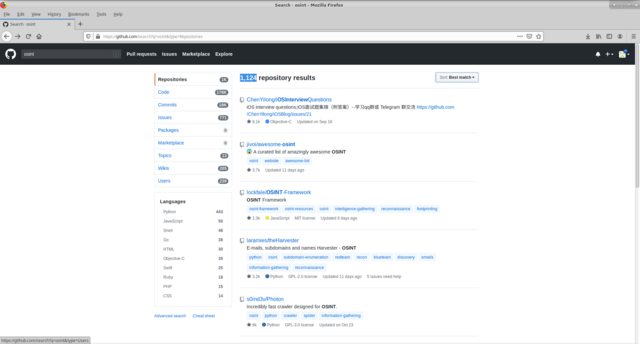
Las decisiones que me interesaron se resumieron en una tabla donde se completaron los campos indicados anteriormente, se tomaron las notas apropiadas en función de los resultados de una prueba en particular.
La desventaja de esta vista, me parece, es la falta de la capacidad de ordenar y filtrar simultáneamente en múltiples campos.
Usando
api_github y python3, describimos un script simple y simple que forma un documento csv para nosotros con los campos que nos interesan.
Ejecute el script
python3 git_repo_search.py osint
tenemos
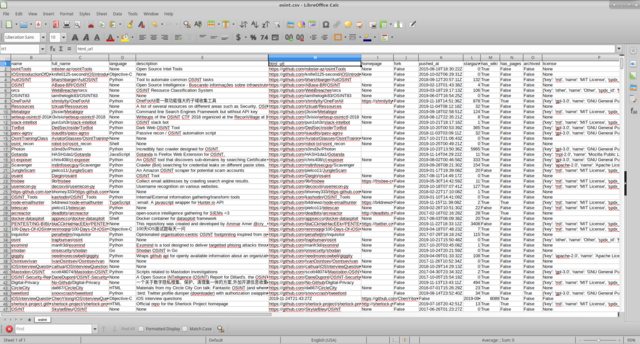
Me parece que trabajar con información es más conveniente, después de ocultar columnas innecesarias.
Codigo
aquiEspero que alguien sea útil.