Quizás todos los programadores conozcan las palabras de Kent Beck: "Haz que funcione, hazlo bien, hazlo rápido". Primero debe hacer que el programa funcione, luego debe hacerlo funcionar correctamente, y solo entonces puede proceder a la optimización.
El autor del artículo, cuya traducción publicamos, dice que recientemente decidió retomar el perfil de su Go-project
Flipt de código
abierto . Quería encontrar código en el proyecto que pudiera optimizarse sin esfuerzo y así acelerar el programa. Durante la creación de perfiles, descubrió algunos problemas inesperados en el popular proyecto de código abierto que Flipt utilizó para organizar el enrutamiento y el soporte de middleware. Como resultado, fue posible reducir la cantidad de memoria asignada por la aplicación durante la operación en 100 veces. Esto, a su vez, condujo a una reducción en el número de operaciones de recolección de basura y mejoró el rendimiento general del proyecto. Así es como fue.
Generación de alto tráfico.
Antes de poder comenzar a crear perfiles, sabía que primero necesitaba generar una gran cantidad de tráfico que ingresara a la aplicación, lo que me ayudaría a ver algunos patrones de su comportamiento. Aquí, inmediatamente me encontré con un problema, ya que no tengo nada que pueda usar Flipt en producción y obtener algo de tráfico que me permita evaluar el trabajo del proyecto bajo carga. Como resultado, encontré una gran herramienta para proyectos de prueba de carga. Este es
Vegeta . Los autores del proyecto dicen que Vegeta es una herramienta HTTP universal para pruebas de carga. Este proyecto nació de la necesidad de cargar servicios HTTP con una gran cantidad de solicitudes que llegan a los servicios con una frecuencia dada.
El proyecto Vegeta resultó ser exactamente la herramienta que necesitaba, ya que me permitió crear un flujo continuo de solicitudes a la aplicación. Con estas solicitudes, puede "shell" la aplicación tanto como sea necesario para descubrir indicadores como la asignación / uso de memoria en el montón, las características de las rutinas, el tiempo dedicado a la recolección de basura.
Después de realizar algunos experimentos, fui a la siguiente configuración del lanzamiento de Vegeta:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 1000 -duration 1m -body evaluate.json
Este comando inicia
Vegeta en modo de
attack , enviando solicitudes HTTP POST al
REST API Flipt a una velocidad de 1000 solicitudes por segundo (que, ciertamente, es una carga seria) durante un minuto. Los datos JSON enviados por Flipt no son particularmente importantes. Solo son necesarios para la correcta formación del cuerpo de la solicitud. Dicha solicitud fue recibida por el servidor Flipt, que podría realizar el procedimiento de
verificación de solicitud.
Tenga en cuenta que primero decidí probar el
/evaluate Flipt
/evaluate . El hecho es que ejecuta la mayor parte del código que implementa la lógica del proyecto y realiza cálculos de servidor "complejos". Pensé que analizar los resultados de este punto final me daría los datos más valiosos sobre las áreas de la aplicación que podrían mejorarse.
Medidas
Ahora que tenía una herramienta para generar una cantidad de tráfico suficientemente grande, necesitaba encontrar una manera de medir el impacto que este tráfico tenía en una aplicación en ejecución. Afortunadamente, Go tiene un conjunto de herramientas estándar bastante bueno que puede medir el rendimiento del programa. Se trata del paquete
pprof .
No entraré en detalles sobre el uso de pprof. No creo que lo haga mejor que Julia Evans, quien escribió
este maravilloso artículo sobre el perfil de los programas Go con pprof (si no lo ha leído, definitivamente le recomiendo que lo eche un vistazo).
Dado que el enrutador HTTP en Flipt se implementa usando
go-chi / chi , no fue difícil para mí habilitar pprof usando el controlador intermedio Chi
adecuado .
Entonces, en una ventana, Flipt trabajó para mí, y Vegeta, llenando a Flipt con solicitudes, trabajó en otra ventana. Lancé la tercera ventana de terminal para recopilar y examinar datos de perfiles de montón:
pprof -http=localhost:9090 localhost:8080/debug/pprof/heap
Utiliza la herramienta pprof de Google, que puede visualizar datos de creación de perfiles directamente en el navegador.
Primero verifiqué las
inuse_space inuse_objects e
inuse_space para comprender lo que está sucediendo en el montón. Sin embargo, no pude encontrar nada notable. Pero cuando decidí echar un vistazo a las
alloc_space alloc_objects y
alloc_space , algo me alertó.
Análisis de resultados de perfilado ( original )Había una sensación de que algo llamado
flate.NewWriter asignó 19370 MB de memoria por un minuto. ¡Y esto, por cierto, es más de 19 gigabytes! Aquí, obviamente, algo extraño estaba sucediendo. ¿Pero qué exactamente? Si observa detenidamente el original del esquema anterior, resulta que es
flate.NewWriter se llama desde
gzip.(*Writer).Write , que, a su vez, se llama desde
middleware.(*compressResponseWriter).Write . Rápidamente me di cuenta de que lo que estaba sucediendo no tenía nada que ver con el código Flipt. El problema estaba en algún lugar del código de middleware
Chi utilizado para comprimir las respuestas de la API.
// r.Use(middleware.Compress(gzip.DefaultCompression))
Comenté la línea anterior y volví a ejecutar las pruebas. Como se esperaba, una gran cantidad de operaciones de asignación de memoria han desaparecido.
Antes de comenzar a buscar una solución a este problema, quería ver estas operaciones de asignación de memoria desde el otro lado y comprender cómo afectan el rendimiento. En particular, estaba interesado en su impacto en el tiempo que le toma al programa recolectar basura. Recordé que Go todavía tiene una herramienta de
rastreo que le permite analizar programas durante su ejecución y recopilar información sobre ellos durante ciertos períodos de tiempo. Los datos recopilados por trace incluyen indicadores tan importantes como el uso del montón, la cantidad de gorutinas que se ejecutan, información sobre solicitudes de red y sistema y, lo que fue especialmente valioso para mí, información sobre el tiempo que pasé en el recolector de basura.
Para recopilar información sobre un programa en ejecución de manera efectiva, necesitaba reducir la cantidad de solicitudes por segundo enviadas a la aplicación usando Vegeta, ya que el servidor regularmente me daba
socket: too many open files errores de
socket: too many open files . Asumí que esto se debe a que
ulimit estaba demasiado bajo en mi computadora, pero no quería entrar en eso entonces.
Entonces, reinicié Vegeta con este comando:
echo 'POST http://localhost:8080/api/v1/evaluate' | vegeta attack -rate 100 -duration 2m -body evaluate.json
Como resultado, si comparamos esto con el escenario anterior, solo una décima parte de las solicitudes se enviaron al servidor, pero esto se hizo por un período de tiempo más largo. Esto me permitió recopilar datos de alta calidad sobre el trabajo del programa.
En otra ventana de terminal, ejecuté este comando:
wget 'http://localhost:8080/debug/pprof/trace?seconds=60' -O profile/trace
Como resultado, tuve a mi disposición un archivo con datos de rastreo recopilados en 60 segundos. Puede examinar este archivo con el siguiente comando:
go tool trace profile/trace
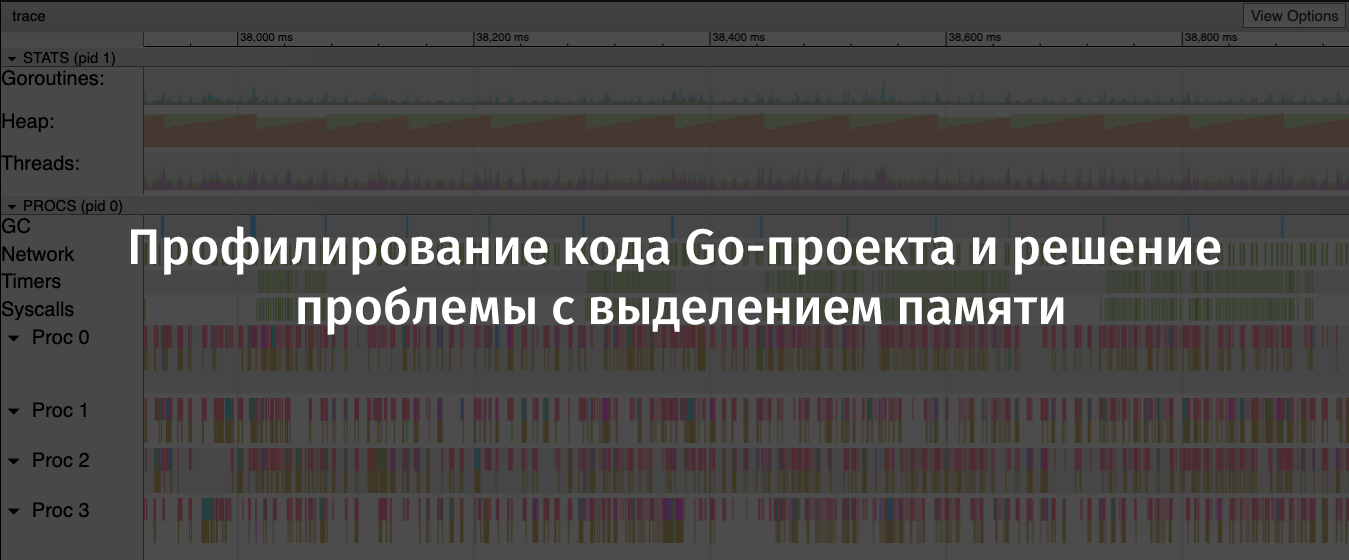
La ejecución de este comando condujo al descubrimiento de la información recopilada en el navegador. Se presentaron en una forma gráfica conveniente para su estudio.
Los detalles sobre el
go tool trace se pueden encontrar en
este buen artículo.
Flipt traza resultados. Un gráfico de diente de sierra de asignación de memoria en el montón es claramente visible ( original )En este gráfico, es fácil ver que la cantidad de memoria asignada en el montón tiende a crecer con bastante rapidez. En este caso, después del crecimiento debería haber una fuerte caída. Los lugares donde cae la memoria asignada son las operaciones de recolección de basura. Aquí puede ver las pronunciadas columnas azules en el área de GC, que representan el tiempo dedicado a la recolección de basura.
Ahora he reunido toda la evidencia del "crimen" que necesito y podría comenzar a buscar una solución al problema de asignación de memoria.
Resolución de problemas
Para averiguar la razón por la cual llamar a
flate.NewWriter condujo a tantas asignaciones de memoria, tuve que mirar el código fuente de
Chi . Para saber qué versión de Chi estoy usando, ejecuté el siguiente comando:
go list -m all | grep chi github.com/go-chi/chi v3.3.4+incompatible
Al llegar al código fuente
chi / middleware / compress.go @ v3.3.4 , pude encontrar el siguiente método:
func encoderDeflate(w http.ResponseWriter, level int) io.Writer { dw, err := flate.NewWriter(w, level) if err != nil { return nil } return dw }
En una investigación adicional, descubrí que el método
flate.NewWriter , a través de un controlador intermedio, se solicitó para cada respuesta. Esto correspondió a la gran cantidad de operaciones de asignación de memoria que vi anteriormente, cargando la API con mil solicitudes por segundo.
No quería negarme a comprimir las respuestas de la API o buscar un nuevo enrutador HTTP y una nueva biblioteca de soporte de middleware. Por lo tanto, en primer lugar decidí averiguar si es posible hacer frente a mi problema simplemente actualizando Chi.
go get -u -v "github.com/go-chi/chi" , actualicé a Chi 4.0.2, pero el código de middleware para la compresión de datos se veía, como me parecía, igual que antes. Cuando volví a ejecutar las pruebas, el problema no desapareció.
Antes de poner fin a este problema, decidí buscar problemas o mensajes de relaciones públicas en el repositorio Chi que mencionen algo como "middleware de compresión". Encontré un RP con el siguiente encabezado: "Reescribí la biblioteca de compresión de middleware". El autor de este PR dijo lo siguiente: "Además, sync.Pool se usa para codificadores, que tiene un método de reinicio (io.Writer), que permite reducir la carga de memoria".
Aqui esta! Afortunadamente, este PR se agregó a la rama
master , pero como no se creó una nueva versión de Chi, tuve que actualizar así:
go get -u -v "github.com/go-chi/chi@master"
Esta actualización, que me gustó mucho, era compatible con versiones anteriores, su uso no requería cambios en el código de mi aplicación.
Resultados
Ejecuté las pruebas de carga y el perfil nuevamente. Esto me permitió verificar que la actualización Chi resolvió el problema.
Ahora plano. NewWriter utiliza una centésima parte de la cantidad de memoria asignada utilizada anteriormente ( original )Mirando nuevamente los resultados de seguimiento, vi que el tamaño del montón ahora está creciendo mucho más lentamente. Además, el tiempo requerido para la recolección de basura ha disminuido.
Adiós - "sierra" ( original )Después de un tiempo,
actualicé el repositorio Flipt, teniendo más confianza que antes de que mi proyecto podrá hacer frente adecuadamente a la gran carga.
Resumen
Estas son las conclusiones que hice después de que logré encontrar y solucionar los problemas anteriores:
- No debe confiar en el supuesto de que las bibliotecas de código abierto (incluso las populares) se han optimizado o que no tienen problemas obvios.
- Un problema inocente puede llevar a graves consecuencias, a manifestaciones del "efecto dominó", especialmente bajo cargas pesadas.
- Si es posible, debe usar sync.Pool .
- Es útil tener a mano las herramientas para probar proyectos bajo carga y para perfilarlos.
- Go Toolkit y Open Source - ¡Genial!
Estimados lectores! ¿Cómo investiga el desempeño de sus proyectos Go?
