En la víspera del lanzamiento del curso Backend PHP Developer, tuvimos una lección abierta tradicional . Esta vez nos familiarizamos con el concepto Serverless, hablamos sobre su implementación en AWS, discutimos los principios de operación, ensamblaje y lanzamiento, y también construimos un simple PHP TG-bot basado en AWS Lambda.
Profesor - Alexander Pryakhin , CTO de Westwing Rusia.

Una breve excursión a la historia.

¿Cómo llegamos a tal vida que apareció la informática sin servidor? Por supuesto, aparecieron no solo así, sino que se convirtieron en una continuación lógica de las tecnologías de virtualización existentes.

¿Qué solemos virtualizar? Por ejemplo, un procesador. También puede virtualizar la memoria resaltando ciertas áreas de la memoria y haciéndolas accesibles para algunos usuarios e inaccesibles para otros. Puede virtualizar una red VPN. Y así sucesivamente.

La virtualización es buena porque utilizamos mejor los recursos y aumentamos la productividad. Pero también hay desventajas, por ejemplo, en un momento hubo problemas de compatibilidad. Sin embargo, prácticamente no hay arquitecturas que sean incompatibles con las máquinas virtuales modernas.
El siguiente inconveniente es que agregamos una capa adicional de abstracción, agregamos un hipervisor, agregamos una máquina virtual por sí misma y, por supuesto, podemos perder un poco de velocidad. Algo complicado y el uso del servidor.
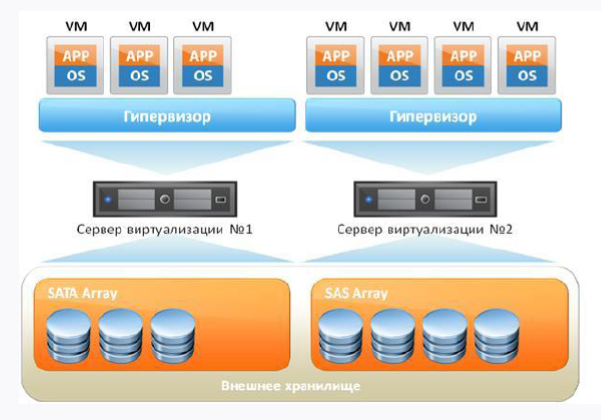
Si llevamos una máquina virtual estándar con usted, se verá más o menos así:

En primer lugar, tenemos un servidor de hierro y, en segundo lugar, el sistema operativo en el que girará nuestro hipervisor. Y además de todo esto, nuestras máquinas virtuales están girando, en las que hay un sistema operativo invitado, bibliotecas y aplicaciones. Si piensas lógicamente, entonces vemos algunos gastos generales en presencia del sistema operativo invitado, porque de hecho gastamos recursos adicionales.
¿Cómo puedo resolver el problema general? Rechazar máquinas virtuales y colocar un sistema de administración de contenedores encima del sistema operativo principal. Por supuesto, el sistema más popular ahora es el motor Docker. Luego, las bibliotecas dentro del contenedor utilizarán el núcleo del host del sistema operativo.

De esta manera, eliminamos la sobrecarga, pero Docker tampoco es ideal, y tiene sus propios problemas y características de trabajo que no le gustan a todos.
Lo principal a entender es que Docker y la máquina virtual son enfoques diferentes, y no hay necesidad de igualarlos. Docker no es un microvirtual con el que puede trabajar como con una máquina virtual, porque el contenedor es para eso y el contenedor. Pero el contenedor nos permite proporcionar flexibilidad y un enfoque completamente diferente a la entrega continua, cuando entregamos cosas a la producción y entendemos que ya están probados y funcionando.
Tecnología en la nube
Con el desarrollo adicional de la virtualización, las tecnologías en la nube también comenzaron a desarrollarse. Esta es una buena solución, pero vale la pena mencionar de inmediato que las nubes no son una bala de plata ni una panacea para todos los males. Aquí uno no puede evitar recordar una famosa cita:
"Cuando escucho a alguien promocionando la nube como una bala mágica para todos los problemas informáticos, silenciosamente reemplazo" nube "con" payaso "y continúo con una sonrisa zen".
Amy rica
Sin embargo, para las empresas medianas que desean recibir un cierto nivel de servicio y tolerancia a fallas sin grandes inyecciones financieras, las nubes son una gran opción. Y para muchas empresas, mantener su centro de datos con el mismo SLA será mucho más costoso que ser atendido en la nube. Además, podemos usar las nubes para nuestras necesidades, ya que proporcionan algunas cosas con solo unos pocos clics del mouse, lo cual es muy conveniente. Por ejemplo, la capacidad de levantar una máquina virtual o red en unos pocos clics.
Sí, existen restricciones, por ejemplo, la 152a Ley Federal que prohíbe el almacenamiento de datos personales en el extranjero, por lo que el mismo Amazon no será adecuado para nosotros durante una auditoría. No te olvides de Vendor-lock. Muchas soluciones en la nube no se transfieren entre sí, aunque la mayoría de los proveedores admiten el mismo almacenamiento compatible con S3.
Las nubes nos brindan la oportunidad de recibir diferentes niveles de servicio sin un conocimiento limitado. Cuanto menos conocimiento necesite, más pagaremos. En la figura siguiente, puede ver la pirámide, donde, de abajo hacia arriba, se muestra la disminución de los requisitos de conocimiento técnico al usar la nube:

Sin servidor y FaaS (Función como servicio)
Sin servidor es una forma bastante joven de ejecutar scripts en las nubes, por ejemplo, como AWS (en términos de AWS, el servidor se implementa en Lambda). Los enfoques * aaS enumerados en la pirámide anterior ya son familiares: IaaS (EC2, VDS), PaaS (Hosting compartido), SaaS (Office 365, Tilda). Entonces, Serverless es una implementación del enfoque FaaS. Y este enfoque consiste en proporcionar al usuario una plataforma preparada para el desarrollo, lanzamiento y administración de ciertas funciones sin la necesidad de preparación y configuración.
Imagine que tiene una máquina que se dedica al procesamiento nocturno de documentos, realiza tareas de 00:00 a 6:00, y durante el resto de las horas está inactiva. La pregunta es: ¿por qué pagar durante el día? ¿Y por qué no usar recursos gratuitos para otra cosa? Este deseo de optimización y el deseo de gastar dinero solo en lo que realmente usa, condujo a la aparición de FaaS.
Sin servidor es un recurso para ejecutar código y nada más. Esto no significa que no haya un servidor detrás de nuestro script, lo es, pero, de hecho, no tenemos ningún recurso asignado específicamente en el que se lanzará nuestro Lambda. Cuando ejecutamos nuestro script, la micro-infraestructura se despliega inmediatamente debajo de él, y este no es su problema en principio: solo piensa que tiene el código ejecutado y no necesita pensar en nada más.
Esto requiere, por supuesto, un cierto enfoque para el desarrollo de su código. Por ejemplo, no puede almacenar nada en este entorno, debe eliminarlo todo. Si se trata de datos, se necesita una base de datos externa, si es un registro, luego un servicio de registro externo, si es un archivo, luego un almacenamiento de archivos externo. Afortunadamente, cualquier proveedor sin servidor proporciona la capacidad de conectarse a sistemas externos.
Solo tienes código, trabajas en el paradigma sin estado, no tienes estado. Para el mismo mundo de PHP, esto significa, por ejemplo, que puede olvidarse del mecanismo de sesión estándar. En principio, incluso puede construir su Serverless, y recientemente en Habré había un artículo sobre este tema .
La idea principal de Serverless es que la infraestructura no requiere soporte del equipo. Todo recae sobre los hombros de la plataforma, por lo que, de hecho, pagas dinero. De las desventajas: usted no controla el entorno de ejecución y no sabe dónde se realiza lo que se realiza.
Entonces sin servidor:
- no significa ausencia física del servidor;
- no es un asesino de virtualoks y Docker;
- No exagero aquí y ahora.
Sin servidor debe ser empujado consciente y deliberadamente. Por ejemplo, si necesita probar rápidamente una hipótesis sin involucrar a la mitad del equipo. Entonces obtienes Function As A Service. La función responderá a algunos eventos, y dado que hay una reacción a los eventos, estos eventos deben ser llamados por algo; para esto, hay muchos desencadenantes en el mismo AWS.
Características de FaaS:
- la infraestructura no requiere configuración;
- Modelo de evento "fuera de la caja";
- Apátrida;
- El escalado es muy fácil y se realiza automáticamente de acuerdo con las necesidades del usuario.
AWS Lambda
La primera implementación de FaaS disponible públicamente es AWS Lambda. Si es una tesis, entonces tiene las siguientes características:
- disponible desde 2014;
- soporta Java, Node.js, Python, Go y tiempos de ejecución personalizados listos para usar;
- pagamos por:
número de llamadas;
plazo de entrega
AWS Lambda: por qué es necesario:
Eliminación Paga solo por el tiempo cuando el servicio se está ejecutando.
Velocidad. Lambda se eleva y trabaja muy rápido.
Funcional Lambda tiene muchas características para integrarse con los servicios de AWS.
Rendimiento Poner una lambda es bastante difícil. En paralelo, se puede realizar según la región desde un máximo de 1000 a 3000 copias. Y si lo desea, este límite puede incrementarse escribiendo apoyo.
Tenemos un cuerpo lambda, un editor en línea, VPC como una cuadrícula virtual de cálculos, registros, el código en sí, variables de entorno y desencadenantes que causan lambda (por cierto, el control de versiones funciona muy bien). Excelente anatomía Lambda se describe en este artículo .
El código se almacena en el cuerpo (si se trata de idiomas admitidos de fábrica) o en capas. Tenemos un disparador que llama a la lambda, la lambda lee los entornos temporales, los atrae hacia sí y ejecuta nuestro código:

Si tenemos un tiempo de ejecución personalizado, tendremos que colocar el código en una capa. Si trabajó con Docker, entonces la capa de Docker es muy similar a la capa en lambda, una especie de cuasi-depósito en el que se encuentra nuestro enlace necesario. Allí tenemos el archivo ejecutable del entorno (si estamos hablando de PHP, debe colocar el binario PHP compilado de antemano), el archivo de arranque lambda (ubicado de forma predeterminada) y los scripts directamente llamados que se ejecutarán.

Con la entrega, no todo es tan color de rosa:

Es decir, se nos ofrece tomar archivos con el código, subirlo al archivo zip, subirlo a la capa y ejecutar nuestro código. Es completamente genial que esto se ofrezca en la documentación oficial de Amazon.

Por supuesto, esto no corresponde a las realidades modernas y al olor de dos milésimas en el aire. Afortunadamente, personas amables probaron e hicieron varios frameworks, por lo que usaremos el framework Serverless desarrollado en Node.js y que nos permite administrar aplicaciones basadas en AWS Lambda. Además, cuando hablamos de implementación y desarrollo, por supuesto, realmente no quiero implementar manualmente, pero hay un deseo de hacer algo flexible y automatizado.
Entonces, necesitamos:
- AWS CLI: interfaz de línea de comandos para trabajar con servicios de AWS;
- el framework Serverless ya mencionado anteriormente (la versión de desarrollo es gratuita y su funcionalidad es suficiente para los ojos);
- La biblioteca Bref, necesaria para escribir código. Esta biblioteca se instala utilizando Composer, por lo que el código será compatible con cualquier marco. Una gran solución, especialmente teniendo en cuenta que AWS Lambda no admite la llamada a secuencias de comandos PHP listas para usar.

Personaliza tu entorno y AWS
AWS CLI
Comencemos creando una cuenta e instalando AWS CLI. La consola de AWS se basa en Python 2.7+ o 3.4+. Dado que AWS recomienda la versión 3 de Python, no discutiremos.
Los siguientes ejemplos son para Ubuntu.
sudo apt-get -y install python3-pip
Luego instale directamente AWS CLI:
pip3 install awscli --upgrade --user
Verifique la instalación:
aws --version
Ahora necesita conectar AWS CLI a su cuenta. Puede usar su nombre de usuario y contraseña existentes, pero sería mejor si crea un usuario separado a través de AWS IAM, definiéndole solo los derechos de acceso necesarios. Llamar a la configuración no causará problemas:
aws configure
A continuación, necesitará AWS Secret y AWS Access Key. Se pueden obtener en ASW IAM en la pestaña "Credenciales de seguridad" (ubicada en la página del usuario deseado). El botón "Crear clave de acceso" ayudará a generar claves de acceso. Mantenlos contigo.

Para registrar un nuevo bot en Telegram, use @BotFather y el comando / newbot. Como resultado, se le devolverá el token necesario para conectarse a su bot. Ciérralo también.
Marco sin servidor
Para instalar Serverless Framework, necesitará una cuenta en https://serverless.com/ .
Después de completar el registro, procederemos a la instalación en nuestra estación de trabajo. Se requerirá Node.js 6th y superior.
sudo apt-get -y install nodejs
Para garantizar el lanzamiento correcto en nuestro entorno, seguimos los pasos recomendados:
mkdir ~/.npm-global export PATH=~/.npm-global/bin:$PATH source ~/.profile npm config set prefix '~/.npm-global'
También agregue:
~/.npm-global/bin:$PATH
al archivo / etc / environment.
Ahora ponga sin servidor:
npm install -g serverless
Aws
Bueno, es hora de cambiar a la interfaz de AWS y agregar un nombre de dominio. Creamos una zona AWS Route 53, un registro DNS y un certificado SSL para ello.
Además, necesita el ELB, que creamos en el servicio EC2 -> Balanceadores de carga. Por cierto, al crear un ELB, debe seguir todos los pasos del asistente, indicando el certificado creado.
En cuanto al equilibrador, puede crearlo a través de la CLI de AWS con el siguiente comando:
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3
Se necesitará un equilibrador después de la primera implementación. En este caso, debe enviarle solicitudes a nuestro dominio. Para implementar esto, en la configuración del registro DNS (campo "Alias target"), comience a ingresar el nombre del ELB creado. Como resultado, verá una lista desplegable, por lo que queda seleccionar la entrada deseada y guardarla.

Ahora ve al código.
Escribir un código
Usaremos Bref para escribir el código. Como se mencionó anteriormente, esta biblioteca se instala utilizando Composer, por lo que el código será compatible con cualquier marco. Por cierto, los desarrolladores ya han descrito el proceso de uso de Bref con Laravel y Symfony . Pero es aconsejable que trabajemos en el PHP "desnudo"; esto ayudará a comprender mejor la esencia.
Comenzamos con las dependencias:
{ "require": { "php": ">=7.2", "bref/bref": "^0.5.9", "telegram-bot/api": "*" }, "autoload": { "psr-4": { "App\": "src/" } } }
Escribiremos en PHP 7.2 y versiones posteriores, y para trabajar con Telegram, este shell para la API es adecuado para nosotros: https://github.com/TelegramBot/Api . En cuanto al código en sí, se colocará en el directorio src.
Entonces, el entorno sin servidor está pasando por un diálogo de consola. Se requiere una aplicación HTTP, y desde el punto de vista de Lambda, esto significará que las llamadas de script se ejecutarán de la misma manera que Nginx. La interpretación será realizada por PHP-FPM. En general, esto es más como una llamada de script de consola estándar. Este es un punto importante, porque sin tener en cuenta esta característica, no podremos llamar a los scripts a través de HTTP.
Realizamos:
vendor/bin/bref init
En el cuadro de diálogo, seleccione el elemento "Aplicación HTTP" y no olvide especificar la región, ya que la aplicación debería funcionar en la misma región en la que funciona el equilibrador.
Después de la inicialización, aparecerán 2 archivos nuevos:
index.php - el archivo llamado;
serverless.yml: archivo de configuración de implementación.
La carpeta .serverless deberá agregarse inmediatamente a .gitignore (aparecerá después del primer intento de implementación).
Una vez que tengamos una aplicación web, colocaremos index.php en la carpeta pública, cambiando inmediatamente a serverless.yml. Así es como se vería en nuestra implementación:
# lambda- service: app # provider: name: aws # ! region: eu-central-1 # runtime: provided # , bref 1024. memoryLimit: 256 # stage: dev # environment: BOT_TOKEN: ${ssm:/app/bot-token} # bref plugins: - ./vendor/bref/bref # Lambda- functions: # php-api-dev # service-function-stage api: handler: public/index.php description: '' # in seconds (API Gateway has a timeout of 29 seconds) timeout: 28 layers: - ${bref:layer.php-73-fpm} # API Gateway events: - http: 'ANY /' - http: 'ANY /{proxy+}' # environment: MY_VARIABLE: ${ssm:/app/my_variable}
Ahora analicemos las líneas no obvias. Necesitamos principalmente variables de entorno. No queremos codificar conexiones de bases de datos, API externas, etc. Si nos conectamos a Telegram, tendremos nuestro propio token, que se recibe de BotFather. Y no se recomienda almacenar este token en serverless.yml, por lo que es mejor enviarlo al almacenamiento de AWS ssm:
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value '___BOTFATHER'
Por cierto, nos referimos a él en la configuración.
Estas variables están disponibles como variables de entorno, y puede acceder a ellas en PHP utilizando la función getenv. Si hablamos de nuestro ejemplo, entonces mantengamos el token bot en el alcance global para simplificar. También podemos transferir el token al alcance de una sola función, y la llamada en sí no cambiará a partir de esto.
Sigamos adelante. Ahora creemos una clase simple de BotApp: será responsable de generar una respuesta para el bot y responderá a los comandos. Los desarrolladores de Telegram recomiendan agregar soporte para los comandos / help y / start para todos los bots. Agreguemos otro comando por diversión. La clase en sí es bastante simple y hace posible implementar el controlador frontal en index.php sin cargar el archivo de llamada en sí. Para obtener una lógica más compleja, la arquitectura debe ser desarrollada y complicada.
<?php namespace App; use TelegramBot\Api\Client; use Telegram\Bot\Objects\Update; class BotApp { function run(): void{ $token = getenv('BOT_TOKEN'); $bot = new Client($token); // start $bot->command('start', function ($message) use ($bot) { $answer = ' !'; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('help', function ($message) use ($bot) { $answer = ': /help - '; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('hello', function ($message) use ($bot) { $answer = '-, - , Serverless '; $bot->sendMessage($message->getChat()->getId(), $answer); }); $bot->run(); } }
Y aquí está la lista de index.php:
<?php require_once('../vendor/autoload.php'); use App\BotApp; try{ $botApp = new BotApp(); $botApp->run(); } catch (Exception $e){ echo $e->getMessage(); print_r($e->getTrace(), 1); }
Puede parecer extraño, pero todo está listo para que nos vayamos a Producción. Hagamos esto ejecutando el comando en la carpeta serverless.yml:
sls deploy
En modo normal, serverless empacará los archivos en archivos zip, creará un bucket de S3 donde colocarlos, luego creará o actualizará la Aplicación AWS adjunta a Lambda, y colocará el código y el tiempo de ejecución en una capa separada.
Durante el primer lanzamiento, se creará la API de Gateway (la dejamos para que sea más fácil probar las llamadas, pero es recomendable eliminarla). También deberá configurar la llamada de Lambda a través de ELB, para lo cual seleccionamos "Agregar disparador" en la ventana de control de funciones y seleccionamos "Balanceador de carga de aplicaciones" en la lista desplegable. Deberá especificar el ELB creado anteriormente, establecer la conexión a través de HTTPS, dejar el Host vacío y, en Ruta, especificar la ruta que Lambda llamará (por ejemplo, / lambda / mytgbot). Como resultado, su Lambda estará disponible en la URL con la ruta especificada.
Ahora puede registrar la parte de respuesta del bot en Telegram para que el mensajero entienda dónde obtener los mensajes. Para hacer esto, llame a la siguiente URL en el navegador, pero no olvide sustituir sus propios parámetros:
https://api.telegram.org/bot_/setWebhook?url=https://my-elb-host.com/lambda/mytgbot
Como resultado, la API devolverá "OK", después de lo cual el bot estará disponible.

Probar el bot en locales
Bot se puede probar antes de la implementación. El hecho es que Serverless Framework admite el inicio en entornos locales que utilizan contenedores Docker para esto. Comando de llamada:
sls invoke local --docker -f myFunction
No olvide que utilizamos variables de entorno, por lo que durante la llamada también deben establecerse en el formato:
sls invoke local --docker -f myFunction --env VAR1=val1
Registros
De forma predeterminada, la salida de la llamada se registrará en CloudWatch; está disponible en el panel Monitoreo de la función Lambda correspondiente. Aquí puede leer los rastreos de llamadas en caso de un volcado en el lado de PHP. Además, puede conectar servicios de monitoreo avanzados, pero costarán unos pocos centavos adicionales cada mes.
Total
Como resultado, obtuvimos una solución bastante rápida, flexible, escalable y también relativamente económica. Sí, Lambda no siempre gana en comparación con las máquinas virtuales y los contenedores estándar, pero hay situaciones en las que la aplicación Serverless ayuda a "disparar" de manera rápida y eficiente. Y el ejemplo del bot creado simplemente demuestra esto.
Materiales útiles sobre el tema: