
Hace un par de años, Kubernetes
ya se discutió en el blog oficial de GitHub. Desde entonces, se ha convertido en la tecnología estándar para implementar servicios. Kubernetes ahora gestiona una parte importante de los servicios internos y públicos. A medida que nuestros grupos crecieron y los requisitos de rendimiento se volvieron más estrictos, comenzamos a notar que algunos servicios en Kubernetes muestran esporádicamente demoras que no pueden explicarse por la carga de la aplicación en sí.
De hecho, en las aplicaciones, se produce un retraso de red aleatorio de hasta 100 ms o más, lo que conduce a tiempos de espera o reintentos. Se esperaba que los servicios pudieran responder a solicitudes mucho más rápido que 100 ms. Pero esto no es posible si la conexión en sí misma toma tanto tiempo. Por separado, observamos consultas MySQL muy rápidas, que se suponía que tomarían milisegundos, y MySQL realmente se manejó en milisegundos, pero desde el punto de vista de la aplicación solicitante, la respuesta tomó 100 ms o más.
De inmediato se hizo evidente que el problema solo ocurre cuando se conecta al host Kubernetes, incluso si la llamada proviene de fuera de Kubernetes. La forma más fácil de reproducir el problema es en la prueba
Vegeta , que se ejecuta desde cualquier host interno, prueba el servicio Kubernetes en un puerto específico y registra esporádicamente un gran retraso. En este artículo, veremos cómo logramos localizar la causa de este problema.
Eliminar la complejidad innecesaria en la cadena de fallas
Después de reproducir el mismo ejemplo, queríamos reducir el enfoque del problema y eliminar las capas adicionales de complejidad. Inicialmente, había demasiados elementos en la secuencia entre Vegeta y las vainas en Kubernetes. Para identificar un problema de red más profundo, debe excluir algunos de ellos.
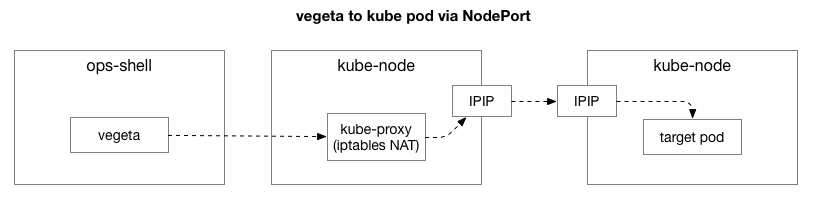
El cliente (Vegeta) crea una conexión TCP con cualquier nodo en el clúster. Kubernetes actúa como una red superpuesta (encima de la red del centro de datos existente) que usa
IPIP , es decir, encapsula los paquetes IP de la red superpuesta dentro de los paquetes IP del centro de datos. Cuando se conecta al primer nodo, la
traducción de la dirección de red de Network Address Translation (NAT) se realiza con monitoreo de estado para convertir la dirección IP y el puerto del host Kubernetes en la dirección IP y el puerto en la red superpuesta (en particular, el pod con la aplicación). Para los paquetes recibidos, se realiza la secuencia inversa. Este es un sistema complejo con muchos estados y muchos elementos que se actualizan y cambian constantemente a medida que los servicios se implementan y mueven.
La utilidad
tcpdump en la prueba Vegeta genera un retraso durante el protocolo de enlace TCP (entre SYN y SYN-ACK). Para eliminar esta complejidad innecesaria, puede usar
hping3 para "pings" simples con paquetes SYN. Compruebe si hay un retraso en el paquete de respuesta y luego restablezca la conexión. Podemos filtrar los datos al incluir solo paquetes de más de 100 ms, y obtener una opción más simple para reproducir el problema que la prueba completa de nivel de red 7 en Vegeta. Estos son los "pings" del host Kubernetes que utilizan TCP SYN / SYN-ACK en el host "puerto" del servicio (30927) con un intervalo de 10 ms, filtrado por las respuestas más lentas:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msInmediatamente puede hacer la primera observación. Los números de serie y los tiempos muestran que no se trata de congestión de una sola vez. La demora a menudo se acumula y finalmente se procesa.
A continuación, queremos averiguar qué componentes pueden estar involucrados en la aparición de congestión. ¿Quizás estos son algunos de los cientos de reglas de iptables en NAT? ¿O algunos problemas con el túnel IPIP en la red? Una forma de verificar esto es verificar cada paso del sistema excluyéndolo. Qué sucede si elimina la lógica de NAT y firewall, dejando solo una parte de IPIP:
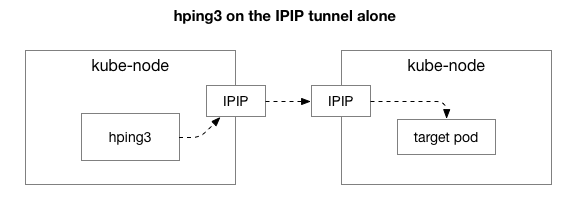
Afortunadamente, Linux facilita el acceso directo a la capa de superposición de IP si la máquina está en la misma red:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msA juzgar por los resultados, ¡el problema aún persiste! Esto excluye iptables y NAT. Entonces, ¿el problema está en TCP? Veamos qué tan regular es el ping ICMP:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msLos resultados muestran que el problema no ha desaparecido. Tal vez este es un túnel IPIP? Simplifiquemos la prueba:
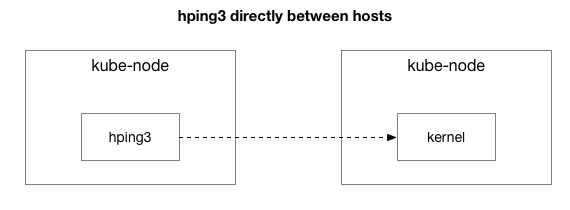
¿Se envían todos los paquetes entre estos dos hosts?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msSimplificamos la situación a dos hosts Kubernetes que se envían cualquier paquete, incluso el ping ICMP. Todavía ven un retraso si el host objetivo es "malo" (algunos peores que otros).
Ahora la última pregunta: ¿por qué la demora solo ocurre en los servidores de nodo kube? ¿Y sucede cuando kube-node es el emisor o receptor? Afortunadamente, esto también es bastante fácil de resolver enviando un paquete desde un host fuera de Kubernetes, pero con el mismo destinatario "conocido malo". Como puede ver, el problema no ha desaparecido:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msLuego realizamos las mismas solicitudes desde el nodo kube de origen anterior al host externo (que excluye el host original, ya que el ping incluye los componentes RX y TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msDespués de examinar las capturas de paquetes retrasadas, obtuvimos información adicional. En particular, que el remitente (abajo) ve este tiempo de espera, pero el receptor (arriba) no lo ve; vea la columna Delta (en segundos):

Además, si observa la diferencia en el orden de los paquetes TCP e ICMP (por números de serie) en el lado del destinatario, los paquetes ICMP siempre llegan en la misma secuencia en la que se enviaron, pero con un tiempo diferente. Al mismo tiempo, los paquetes TCP a veces se alternan y algunos se atascan. En particular, si examinamos los puertos de los paquetes SYN, en el lado del remitente van en orden, pero en el lado del destinatario no.
Existe una sutil diferencia en cómo
las tarjetas de red de los servidores modernos (como en nuestro centro de datos) procesan los paquetes que contienen TCP o ICMP. Cuando llega un paquete, el adaptador de red "lo pasa por la conexión", es decir, intenta romper las conexiones por turnos y enviar cada cola a un núcleo de procesador separado. Para TCP, este hash incluye la dirección IP y el puerto de origen y destino. En otras palabras, cada conexión es hash (potencialmente) de manera diferente. Para ICMP, solo se codifican las direcciones IP, ya que no hay puertos.
Otra observación nueva: durante este período, vemos retrasos en ICMP en todas las comunicaciones entre los dos hosts, pero TCP no. Esto nos dice que la razón probablemente se deba al hash de las colas RX: es casi seguro que la congestión se produce en el procesamiento de paquetes RX, en lugar de enviar respuestas.
Esto excluye el envío de paquetes de la lista de posibles razones. Ahora sabemos que el problema con el procesamiento de paquetes está en el lado receptor en algunos servidores de nodo kube.
Comprensión del procesamiento de paquetes en el kernel de Linux
Para entender por qué ocurre el problema con el destinatario en algunos servidores de nodo kube, veamos cómo el kernel de Linux maneja los paquetes.
Volviendo a la implementación tradicional más simple, la tarjeta de red recibe el paquete y envía una
interrupción al kernel de Linux, que es el paquete que debe procesarse. El kernel detiene otra operación, cambia el contexto al controlador de interrupciones, procesa el paquete y luego vuelve a las tareas actuales.

Este cambio de contexto es lento: la latencia puede no haber sido notable en las tarjetas de red de 10 megabytes en la década de 1990, pero en las tarjetas 10G modernas con un rendimiento máximo de 15 millones de paquetes por segundo, cada núcleo de un pequeño servidor de ocho núcleos puede interrumpirse millones de veces por segundo.
Para no lidiar constantemente con el manejo de interrupciones, hace muchos años Linux agregó
NAPI : una API de red que todos los controladores modernos usan para aumentar el rendimiento a altas velocidades. A bajas velocidades, el núcleo aún acepta las interrupciones de la tarjeta de red de la manera anterior. Tan pronto como llega un número suficiente de paquetes que excede el umbral, el núcleo deshabilita las interrupciones y en su lugar comienza a sondear el adaptador de red y a tomar paquetes en lotes. El procesamiento se realiza en softirq, es decir, en el
contexto de las interrupciones de software después de las llamadas al sistema y las interrupciones de hardware cuando el núcleo (a diferencia del espacio del usuario) ya se está ejecutando.
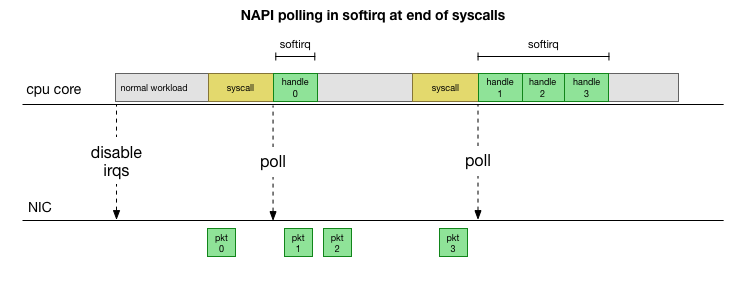
Esto es mucho más rápido, pero causa un problema diferente. Si hay demasiados paquetes, todo el tiempo que lleva procesar paquetes desde la tarjeta de red y los procesos de espacio de usuario no tienen tiempo para vaciar realmente estas colas (lectura de conexiones TCP, etc.). Al final, las colas se llenan y comenzamos a soltar paquetes. Intentando encontrar un equilibrio, el núcleo establece un presupuesto para el número máximo de paquetes procesados en el contexto softirq. Una vez que se supera este presupuesto, se
ksoftirqd subproceso
ksoftirqd separado (verá uno de ellos en
ps para cada núcleo), que procesa estos softirqs fuera de la ruta normal de llamada / interrupción. Este hilo se planifica utilizando un planificador de procesos estándar que intenta distribuir los recursos de manera justa.
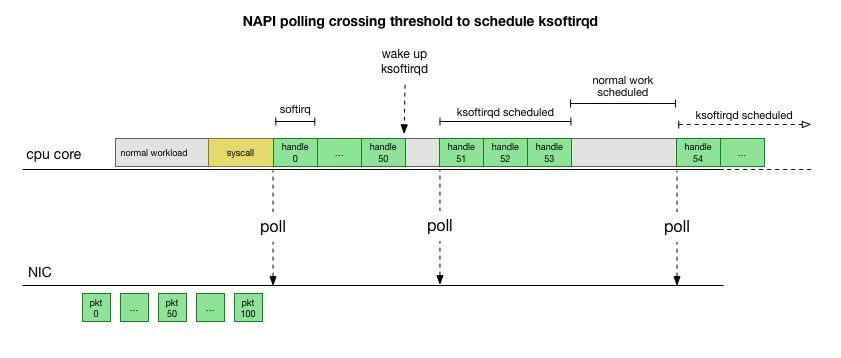
Después de examinar cómo procesa los paquetes el núcleo, puede ver que existe una cierta probabilidad de congestión. Si las llamadas de softirq se reciben con menos frecuencia, los paquetes tendrán que esperar un tiempo para procesarse en la cola RX en la tarjeta de red. Quizás esto se deba a que alguna tarea bloquea el núcleo del procesador, o algo más impide que el núcleo inicie softirq.
Limitamos el procesamiento al núcleo o método
Los retrasos de Softirq son solo una suposición. Pero tiene sentido, y sabemos que estamos viendo algo muy similar. Por lo tanto, el siguiente paso es confirmar esta teoría. Y si se confirma, busque el motivo de los retrasos.
De vuelta a nuestros paquetes lentos:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msComo se discutió anteriormente, estos paquetes ICMP se combinan en una sola cola NIC RX y son procesados por un solo núcleo de CPU. Si queremos entender cómo funciona Linux, es útil saber dónde (en qué núcleo de CPU) y cómo (softirq, ksoftirqd) se procesan estos paquetes para rastrear el proceso.
Ahora es el momento de usar herramientas que permitan el monitoreo en tiempo real del kernel de Linux. Aquí usamos
bcc . Este kit de herramientas le permite escribir pequeños programas en C que interceptan funciones arbitrarias en el núcleo y los eventos del búfer en un programa Python en el espacio del usuario que puede procesarlos y devolverle el resultado. Los ganchos para funciones arbitrarias en el núcleo son complejos, pero la utilidad está diseñada para la máxima seguridad y está diseñada para rastrear con precisión los problemas de producción que no son fáciles de reproducir en un entorno de prueba o desarrollo.
El plan aquí es simple: sabemos que el núcleo procesa estos pings ICMP, por lo que
conectamos la función del núcleo
icmp_echo , que recibe el paquete ICMP de solicitud de eco entrante e inicia el envío de la respuesta ICMP de respuesta de eco. Podemos identificar el paquete aumentando el número icmp_seq, que muestra
hping3 arriba.
El código de
script bcc parece complicado, pero no da tanto miedo como parece. La función
icmp_echo pasa
struct sk_buff *skb : este es el paquete con la solicitud "echo request". Podemos rastrearlo, extraer la secuencia
echo.sequence (que se asigna a
icmp_seq desde hping3
) y enviarla al espacio del usuario. También es conveniente capturar el nombre / identificador actual del proceso. A continuación se muestran los resultados que vemos directamente durante el procesamiento de paquetes por el núcleo:
NOMBRE DEL PROCESO TGID PID ICMP_SEQ
0 0 swapper / 11,770
0 0 swapper / 11,771
0 0 swapper / 11 772
0 0 swapper / 11 773
0 0 swapper / 11,774
20041 20086 prometeo 775
0 0 swapper / 11,776
0 0 swapper / 11,777
0 0 swapper / 11 778
4512 4542 informe-radios-s 779
Cabe señalar aquí que en el contexto de
softirq procesos que hacen que las llamadas al sistema aparezcan como "procesos", aunque en realidad este núcleo procesa paquetes de forma segura en el contexto del núcleo.
Con esta herramienta podemos establecer la conexión de procesos específicos con paquetes específicos que muestran un retraso en
hping3 . Hacemos un
grep simple en esta captura para valores específicos de
icmp_seq . Los paquetes correspondientes a los valores icmp_seq anteriores se marcaron con su RTT, que observamos anteriormente (entre paréntesis se encuentran los valores RTT esperados para los paquetes que filtramos debido a valores RTT inferiores a 50 ms):
TGID PID NOMBRE DEL PROCESO ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79 ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59 ms
76 76 ksoftirqd / 11 1958 ** (49 ms)
76 76 ksoftirqd / 11 1959 ** (39 ms)
76 76 ksoftirqd / 11 1960 ** (29 ms)
76 76 ksoftirqd / 11 1961 ** (19 ms)
76 76 ksoftirqd / 11 1962 ** (9 ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75 ms
76 76 ksoftirqd / 11 2071 ** 65 ms
76 76 ksoftirqd / 11 2072 ** 55 ms
76 76 ksoftirqd / 11 2073 ** (45 ms)
76 76 ksoftirqd / 11 2074 ** (35 ms)
76 76 ksoftirqd / 11 2075 ** (25 ms)
76 76 ksoftirqd / 11 2076 ** (15 ms)
76 76 ksoftirqd / 11 2077 ** (5 ms)
Los resultados nos dicen algunas cosas. Primero, el contexto
ksoftirqd/11 maneja todos estos paquetes. Esto significa que para este par particular de máquinas, los paquetes ICMP se procesaron en el núcleo 11 en el extremo receptor. También vemos que en cada atasco de tráfico hay paquetes que se procesan en el contexto de la
cadvisor sistema de
cadvisor . Entonces
ksoftirqd asume la tarea y cumple con la cola acumulada: exactamente el número de paquetes que se acumularon después del
cadvisor .
El hecho de que un
cadvisor siempre trabaje inmediatamente antes de esto implica su participación en el problema. Irónicamente, el propósito de
cadvisor es "analizar la utilización de recursos y las características de rendimiento de los contenedores en ejecución", en lugar de causar este problema de rendimiento.
Al igual que con otros aspectos del manejo de contenedores, todas estas son herramientas extremadamente avanzadas de las cuales se pueden esperar problemas de rendimiento en algunas circunstancias imprevistas.
¿Qué hace cadvisor que ralentiza la cola de paquetes?
Ahora tenemos una buena comprensión de cómo ocurre la falla, qué proceso la causa y en qué CPU. Vemos que debido al bloqueo duro, el kernel de Linux no tiene tiempo para programar
ksoftirqd . Y vemos que los paquetes se procesan en el contexto de
cadvisor . Es lógico suponer que
cadvisor inicia una llamada syscall lenta, después de lo cual se procesan todos los paquetes acumulados en este momento:
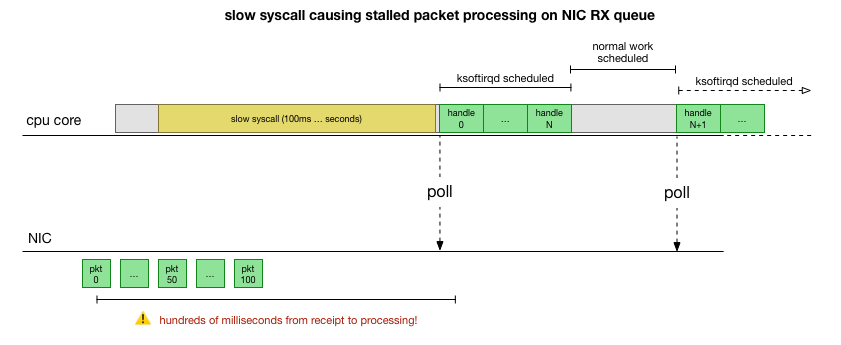
Esta es una teoría, pero ¿cómo probarla? Lo que podemos hacer es rastrear el funcionamiento del núcleo de la CPU a lo largo de este proceso, encontrar el punto donde se excede el presupuesto por la cantidad de paquetes y se llama a ksoftirqd, y luego mirar un poco antes: qué funcionó exactamente en el núcleo de la CPU justo antes de ese momento. Es como una radiografía de una CPU cada pocos milisegundos. Se verá más o menos así:
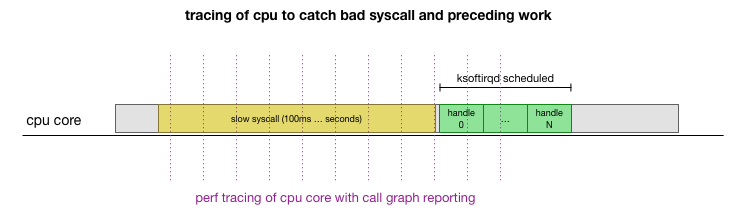
Convenientemente, todo esto se puede hacer con las herramientas existentes. Por ejemplo, el
registro de rendimiento verifica el núcleo de CPU especificado con la frecuencia indicada y puede generar una programación de llamadas a un sistema en ejecución, que incluye tanto el espacio de usuario como el kernel de Linux. Puede tomar este registro y procesarlo utilizando una pequeña bifurcación del programa
FlameGraph de Brendan Gregg, que conserva el orden de seguimiento de la pila. Podemos guardar trazas de pila de una línea cada 1 ms, y luego seleccionar y guardar la muestra durante 100 milisegundos antes de que
ksoftirqd entre en la traza:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100Aquí están los resultados:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runAquí hay muchas cosas, pero lo principal es que encontramos la plantilla "cadvisor antes de ksoftirqd" que vimos anteriormente en el trazador ICMP. ¿Qué significa esto?
Cada línea es un rastro de la CPU en un punto particular en el tiempo. Cada llamada hacia abajo en la pila en una línea está separada por un punto y coma. En el medio de las líneas vemos syscall llamado:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... Por lo tanto, cadvisor pasa mucho tiempo en la llamada al sistema
read() , relacionada con las funciones
mem_cgroup_* (parte superior de la pila de llamadas / final de línea).
En el seguimiento de llamadas, es inconveniente ver qué se está leyendo exactamente, así que ejecute
strace y vea qué hace el asesor, y encuentre llamadas del sistema de más de 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>Como es de esperar, aquí vemos llamadas de
read() lenta
read() . A partir del contenido de las operaciones de lectura y el contexto
mem_cgroup ,
mem_cgroup puede ver que estas llamadas
read() se refieren al archivo
memory.stat , que muestra el uso de la memoria y las limitaciones de cgroup (tecnología de aislamiento de recursos de Docker). La herramienta cadvisor sondea este archivo para obtener información sobre el uso de recursos para contenedores. Veamos si este núcleo o asesor hace algo inesperado:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $Ahora podemos reproducir el error y comprender que el kernel de Linux se enfrenta a una patología.
¿Qué hace que leer sea tan lento?
En este punto, es mucho más fácil encontrar mensajes de otros usuarios sobre problemas similares. Al final resultó que, en el rastreador de cadvisor, este error se informó como un
problema de uso excesivo de la CPU , pero nadie notó que el retraso también se reflejaba al azar en la pila de la red. De hecho, se notó que cadvisor consume más tiempo de procesador de lo esperado, pero esto no se le dio mucha importancia, ya que nuestros servidores tienen muchos recursos de procesador, por lo que no estudiamos cuidadosamente el problema.
El problema es que los grupos de control (cgroups) tienen en cuenta el uso de memoria dentro del espacio de nombres (contenedor). Cuando todos los procesos en este cgroup finalizan, Docker libera un grupo de control de memoria. Sin embargo, "memoria" no es solo una memoria de proceso. Aunque la memoria de proceso en sí ya no se usa, resulta que el núcleo también asigna contenido en caché, como dentries e inodes (directorio y metadatos de archivos), que se almacenan en caché en cgroup de memoria. De la descripción del problema:
cgroups zombies: grupos de control en los que no hay procesos y se eliminan, pero para los cuales todavía se asigna memoria (en mi caso, desde el caché de dentry, pero también se puede asignar desde el caché de página o tmpfs).
Verificar por el núcleo todas las páginas en el caché cuando se libera cgroup puede ser muy lento, por lo que se elige el proceso diferido: espere hasta que estas páginas se soliciten nuevamente, e incluso cuando la memoria sea realmente necesaria, finalmente borre cgroup. Hasta ahora, cgroup todavía se tiene en cuenta al recopilar estadísticas.
En términos de rendimiento, sacrificaron memoria por rendimiento: aceleraron la limpieza inicial debido al hecho de que queda un poco de memoria en caché. Esto es normal Cuando el kernel usa la última parte de la memoria en caché, cgroup finalmente se borra, por lo que esto no se puede llamar una "fuga". Desafortunadamente, la implementación específica del mecanismo de búsqueda
memory.stat en esta versión del kernel (4.9), combinada con la gran cantidad de memoria en nuestros servidores, lleva al hecho de que lleva mucho más tiempo restaurar los últimos datos almacenados en caché y eliminar zombies de cgroup.
Resulta que había tantos zombis cgroup en algunos de nuestros nodos que la lectura y la latencia excedieron un segundo.
Una solución alternativa para el problema de cadvisor es borrar inmediatamente las cachés de dentries / inodes en todo el sistema, lo que elimina inmediatamente la latencia de lectura y la latencia de red en el host, ya que la eliminación de la caché incluye páginas en caché cgroup zombie, y también se liberan. Esta no es una solución, pero confirma la causa del problema.
Resultó que las versiones más nuevas del kernel (4.19+) mejoraron el rendimiento de la llamada
memory.stat , por lo que cambiar a este kernel solucionó el problema. Al mismo tiempo, teníamos herramientas para detectar nodos problemáticos en los grupos de Kubernetes, drenándolos con gracia y reiniciando. Revisamos todos los grupos, encontramos los nodos con un retraso suficientemente alto y los reiniciamos. Esto nos dio tiempo para actualizar el sistema operativo en el resto de los servidores.
Para resumir
Dado que este error detuvo el procesamiento de las colas NIC RX durante cientos de milisegundos, simultáneamente causó un gran retraso en las conexiones cortas y un retraso en el medio de la conexión, por ejemplo, entre las consultas MySQL y los paquetes de respuesta.
, Kubernetes, . Kubernetes .