
La empresa para la que trabajo escribe su propio sistema de filtrado de tráfico y protege a la empresa con ataques DDoS, bots, analizadores y mucho más. El producto se basa en un proceso como
el proxy inverso , con la ayuda del cual analizamos grandes volúmenes de tráfico en tiempo real y, al final, solo permitimos solicitudes legítimas de los usuarios, filtrando todos los maliciosos.
La característica principal es que nuestros servicios funcionan con tráfico entrante ilimitado, por lo que es muy importante utilizar todos los recursos de las estaciones de trabajo de la manera más eficiente posible. Una gran experiencia de desarrollo en C ++ moderno nos ayuda con esto, incluidos los últimos estándares y un conjunto de bibliotecas llamadas Boost.
Proxy inverso
Volvamos al proxy inverso y veamos cómo puedes implementarlo en C ++ y boost.asio. En primer lugar, necesitamos dos objetos llamados sesiones de servidor y cliente. La sesión del servidor establece y mantiene una conexión con el navegador; la sesión del cliente establece y mantiene una conexión con el servicio. También necesitará un búfer de flujo que encapsule el trabajo con memoria interna, en el que la sesión del servidor lee desde el socket y desde el cual la sesión del cliente escribe en el socket. Se pueden encontrar ejemplos de sesiones de servidor y cliente en la documentación de boost.asio. Aquí se puede encontrar cómo trabajar con el búfer de flujo.
Después de recopilar el prototipo de proxy inverso de los ejemplos, quedará claro que tal aplicación probablemente no servirá tráfico entrante ilimitado. Entonces comenzaremos a aumentar la complejidad del código. Pensemos en subprocesos múltiples, wokers y pools para contextos io, y mucho más. En particular, sobre optimizaciones prematuras relacionadas con la copia de memoria entre el servidor y las sesiones del cliente.
¿De qué tipo de copia de memoria estamos hablando? El hecho es que cuando se filtra, el tráfico no siempre se transmite sin cambios. Mire el ejemplo a continuación: en él eliminamos un encabezado y agregamos dos en su lugar. El número de consultas de usuarios sobre las cuales se realizan acciones similares aumenta con la complejidad de la lógica dentro del servicio. ¡En ningún caso puede copiar datos sin pensar en tales casos! Si solo cambia el 1% del total de la solicitud y el 99% permanece sin cambios, entonces debe asignar nueva memoria solo para este 1%. Le ayudará con este boost :: asio :: const_buffer y boost :: asio :: mutable_buffer, con la ayuda de los cuales puede representar varios bloques continuos de memoria con una entidad.
Solicitud del usuario:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
El problema
Como resultado, obtuvimos una aplicación lista para usar que puede escalar bien y está dotada de todo tipo de optimizaciones. Al lanzarlo en producción, estuvimos muy contentos por el tiempo que funcionó bien y de manera estable.
Con el tiempo, comenzamos a tener más y más clientes, con el advenimiento de que el tráfico también ha crecido. En algún momento, nos enfrentamos con el problema de la falta de rendimiento al rechazar grandes ataques. Después de analizar el servicio utilizando la utilidad
perf , notamos que todas las operaciones con el montón bajo carga están en la parte superior. Luego, recreamos una situación similar en el circuito de prueba utilizando
yandex-tank y cartuchos generados en función del tráfico real. Conectando un servicio a través de un
amplificador, vimos la siguiente imagen ...
Captura de pantalla del amplificador (woslab):
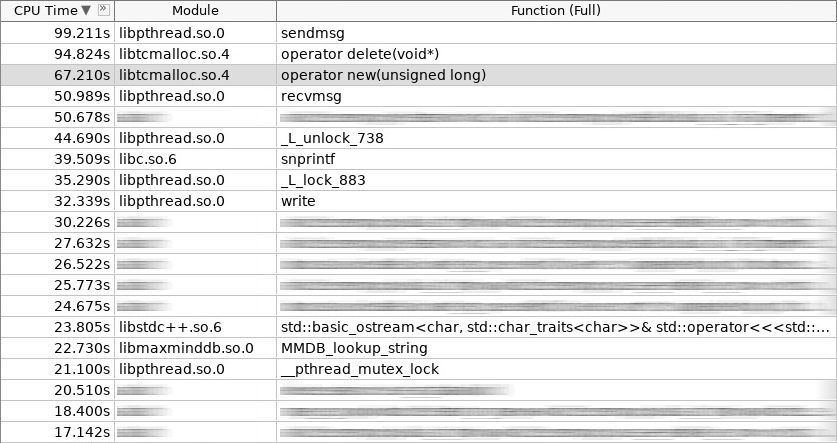
En la captura de pantalla, el operador nuevo trabajó 67 segundos y el operador eliminó aún más: 97 segundos.
Esta situación nos molestó. ¿Cómo reducir el tiempo de permanencia de la aplicación en operador nuevo y eliminar operador? Es lógico que esto se pueda hacer abandonando las asignaciones constantes de objetos frecuentemente creados y eliminados en el montón. Nos decidimos por tres enfoques. Dos de ellos son estándar:
grupo de objetos y
asignación de pila . Las sesiones de cliente que se organizan en un grupo en la etapa de inicio de la aplicación están bien ubicadas en el primer enfoque. El segundo enfoque se usa en todas partes donde se procesa una solicitud de usuario de principio a fin en la misma pila, en otras palabras, en el mismo controlador de contexto io. No nos detendremos en esto con más detalle. Será mejor que hablemos del tercer enfoque, como el más complejo e interesante. Se llama
asignación de losas o distribución de losas.
La idea de la distribución de losas no es nueva. Fue inventado e implementado en Solaris, luego migró al kernel de Linux, y consiste en el hecho de que los objetos del mismo tipo que se usan con frecuencia son más fáciles de almacenar en el grupo. Simplemente tomamos el objeto del grupo cuando lo necesitamos, y al finalizar el trabajo lo devolvemos. ¡No hay llamadas al operador nuevo y operador eliminado! Además, un mínimo de inicialización. En el núcleo de losa, la distribución se utiliza para semáforos, descriptores de archivos, procesos y subprocesos. En nuestro caso, cayó perfectamente en las sesiones de servidor y cliente, así como en todo lo que está dentro de ellas.
Gráfico (distribución de losas):

Además del hecho de que los asignadores de losas están en el núcleo, sus implementaciones también existen en el espacio del usuario. Hay pocos de ellos, y los que se están desarrollando activamente son generalmente pocos. Nos instalamos en una biblioteca llamada
libsmall , que es parte de
tarantool . Tiene todo lo que necesitas.
- pequeño :: asignador
- small :: slab_cache (hilo local)
- pequeño :: losa
- pequeño :: arena
- pequeño :: cuota
La estructura small :: slab es un grupo con un tipo específico de objeto. La estructura small :: slab_cache es un caché que contiene varias listas de grupos con un tipo específico de objetos. La estructura small :: allocator es un código que selecciona el caché necesario, busca un grupo adecuado en él, en el que se distribuye el objeto solicitado. Lo que hacen los objetos small :: arena y small :: quota quedará claro en los ejemplos a continuación.
Envolver
La biblioteca libsmall está escrita en C, no en C ++, por lo que tuvimos que desarrollar varios contenedores para una integración transparente en la biblioteca estándar de C ++.
- variti :: slab_allocator
- variti :: losa
- variti :: thread_local_slab
- variti :: slab_allocate_shared
La clase variti :: slab_allocator implementa los requisitos mínimos establecidos por el estándar al escribir su propio asignador. Dentro de las clases variti :: slab, todo el trabajo con la biblioteca libsmall está encapsulado. ¿Por qué se necesita variti :: thread_local_slab? El hecho es que las cachés de losas de distribución son objetos locales de hilo. Esto significa que cada hilo tiene su propio conjunto de cachés. Esto se hace para reducir a cero el número de operaciones bloqueadas al distribuir un nuevo objeto. Por lo tanto, en la memoria de cada subproceso, colocamos nuestra instancia de la clase variti :: slab, y el acceso a esta se regula mediante el contenedor variti :: thread_local_slab. Te contaré sobre la función de plantilla variti :: slab_allocate_shared más adelante.
Dentro de la clase variti :: slab_allocator, todo es bastante simple. Tiene la capacidad de volver a vincular de un tipo a otro, por ejemplo, de vacío a char. Curiosamente, puede prestar atención a la prevalencia de nullptr a la excepción std :: bad_alloc en el caso de que la memoria se agote de la losa de distribución. El resto es reenviar llamadas dentro del contenedor variti :: thread_local_slab.
Fragmento (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Veamos cómo se implementa el constructor y destructor variti :: slab. En el constructor, asignamos un total de no más de 1 GiB de memoria para todos los objetos. El tamaño de cada grupo en nuestro caso no supera 1 MiB. El objeto mínimo que podemos distribuir es de 2 bytes (de hecho, libsmall lo aumentará al mínimo requerido: 8 bytes). Los objetos restantes disponibles a través de nuestra distribución de losa serán múltiplos de dos (establecidos por la constante 2.f). Total, puede distribuir objetos de tamaño 8, 16, 32, etc. Si el objeto solicitado tiene un tamaño de 24 bytes, se producirá una sobrecarga de la memoria. La distribución le devolverá este objeto, pero se colocará en un grupo que corresponde a un objeto de 32 bytes de tamaño. Los 8 bytes restantes estarán inactivos.
Fragmento (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
Todas estas restricciones se aplican a una instancia particular de la clase variti :: slab. Dado que cada subproceso tiene su propio (piense en el subproceso local), el límite total del proceso no será de 1 GiB, sino que será directamente proporcional al número de subprocesos que utilizan la distribución de losa.
Gráfico (std :: thread :: id):
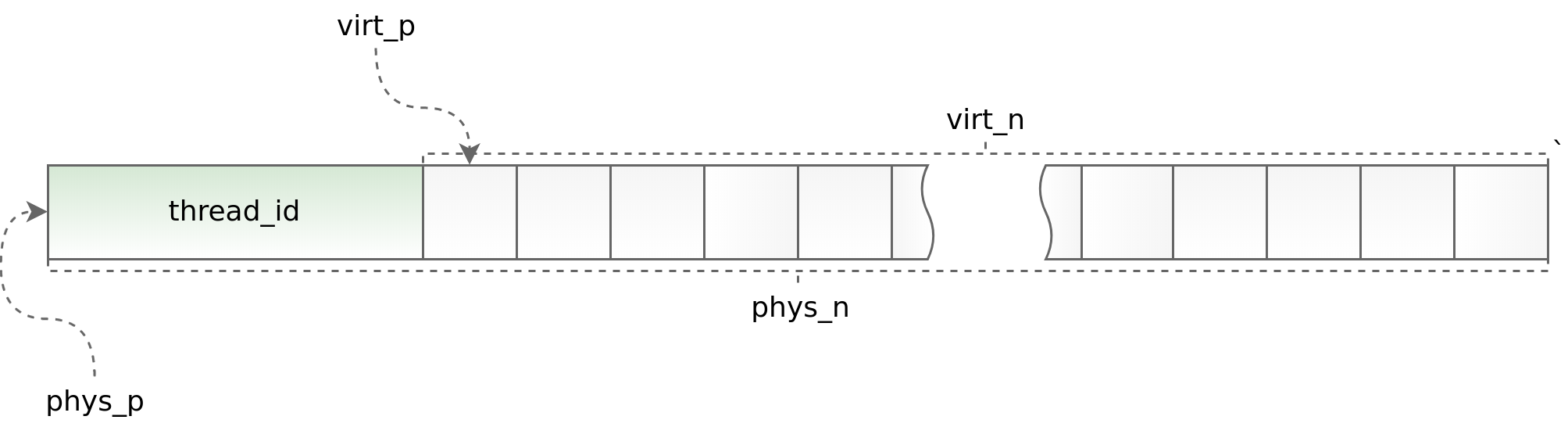
Por un lado, el uso de hilo local le permite acelerar el trabajo de distribución de losas en una aplicación multiproceso, por otro lado, impone restricciones serias en la arquitectura de la aplicación asincrónica. Debe solicitar y devolver un objeto en la misma secuencia. Hacer esto como parte de boost.asio a veces es muy problemático. Para rastrear situaciones obviamente erróneas, al comienzo de cada objeto colocamos el identificador de la secuencia en la que se llama el método de asignación. Este identificador se verifica en el método de desasignación. Los ayudantes phys_to_virt_p y virt_to_phys_p ayudan en esto.
Fragmento (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Fragmento (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
Cuando se pierde el control sobre la secuencia (cuando se transfiere un objeto entre diferentes contextos io), un puntero inteligente permite la liberación correcta del objeto. Todo lo que hace es distribuir el objeto, recordando su contexto io, y luego envolverlo en std :: shared_ptr con un divisor personalizado, que no devuelve inmediatamente el objeto a la distribución, sino que lo hace en el contexto io guardado anteriormente. Esto funciona bien cuando cada contexto io se ejecuta en un solo hilo. De lo contrario, desafortunadamente, este enfoque no es aplicable.
Fragmento (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Solución
Después de completar el trabajo de ajuste de libsmall, primero movimos los asignadores de chun dentro del búfer de flujo a losa. Esto fue bastante fácil de hacer. Habiendo recibido un resultado positivo, seguimos adelante y aplicamos los asignadores de losas primero al búfer de flujo en sí, y luego a todos los objetos dentro de las sesiones de servidor y cliente.
- variti :: trozo
- variti :: streambuf
- variti :: server_session
- variti :: sesión_cliente
Al mismo tiempo, era necesario resolver problemas adicionales, a saber: transferir objetos simples, objetos compuestos y colecciones a asignadores de losas. Y si no hubo serias dificultades con las dos primeras clases de objetos (los objetos compuestos se reducen a simples), entonces al traducir colecciones nos encontramos con serias dificultades.
- std :: list
- std :: deque
- std :: vector
- std :: string
- std :: mapa
- std :: unordered_map
Una de las principales limitaciones cuando se trabaja con la distribución de losas es que el número de objetos de diferentes tipos no debe ser demasiado grande (cuanto menor sea, mejor). En este contexto, algunas colecciones pueden caer en el concepto de asignadores de losas, mientras que otras no.
Para std :: list slab, los asignadores funcionan muy bien. Esta colección se implementa internamente utilizando una lista vinculada, cada elemento del cual tiene un tamaño fijo. Por lo tanto, con la adición de nuevos datos a la lista std :: en la distribución de losa, no aparecen nuevos tipos de objetos. ¡La condición indicada arriba está satisfecha! El std :: map está organizado de manera similar. La única diferencia es que dentro no hay una lista vinculada, sino un árbol.
En el caso de std :: deque, las cosas son más complicadas. Esta colección se implementa a través de un bloque contiguo de memoria que contiene punteros a fragmentos. Si bien los fragmentos son bastante precisos, std :: deque se comporta igual que std :: list, pero cuando finalizan, este mismo bloque de memoria se redistribuye. Desde el punto de vista de los asignadores de losas, cada redistribución de memoria es un objeto con un nuevo tipo. El número de objetos agregados a la colección depende directamente del usuario y puede crecer sin control. Esta situación no es aceptable, por lo que limitamos preliminarmente el tamaño de std :: deque donde era posible o preferimos std :: list.
Si tomamos std :: vector y std :: string, entonces aún son más complicados. La implementación de estas colecciones es algo similar a std :: deque, excepto que su bloque de memoria continua crece significativamente más rápido. Reemplazamos std :: vector y std :: string con std :: deque, y en el peor de los casos con std :: list. Sí, perdimos en funcionalidad y en algún lugar incluso en rendimiento, pero esto afectó la imagen final mucho menos que las optimizaciones para las cuales todo fue concebido.
Hicimos exactamente lo mismo con std :: unordered_map, abandonándolo a favor del variti :: flat_map auto-escrito implementado a través de std :: deque. Al mismo tiempo, simplemente almacenamos en caché las claves de uso frecuente en variables separadas, por ejemplo, como se hace con los encabezados de solicitud http en nginx.
Conclusión
Una vez finalizada la transferencia completa de las sesiones de servidor y cliente a los asignadores de losas, redujimos el tiempo dedicado a trabajar con un grupo más de una vez y media.
Captura de pantalla del amplificador (coldslab):
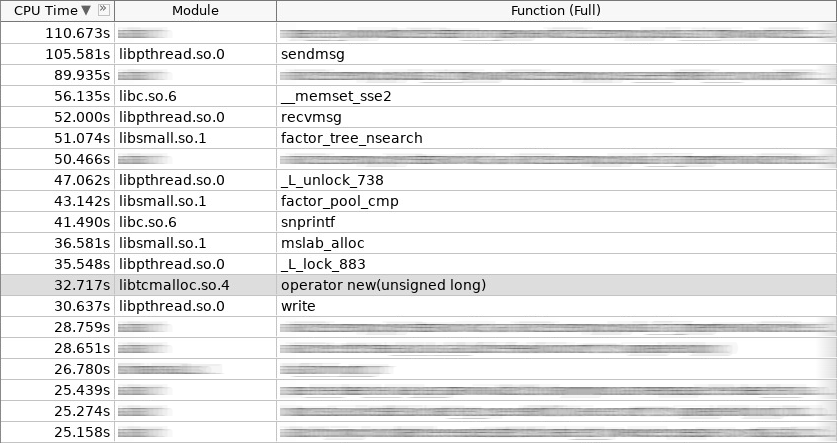
En la captura de pantalla, el operador nuevo trabajó 32 segundos y el operador eliminó - 24 segundos. En este momento, se agregaron otras funciones para trabajar con el montón: smalloc - 21 segundos, mslab_alloc - 37 segundos, smfree - 8 segundos, mslab_free - 21 segundos. Total, 143 segundos versus 161 segundos.
Pero estas mediciones se realizaron inmediatamente después de comenzar el servicio sin inicializar los cachés en la distribución de losas. Después de disparos repetidos desde un tanque yandex, la imagen general mejoró.
Captura de pantalla del amplificador (hotslab):
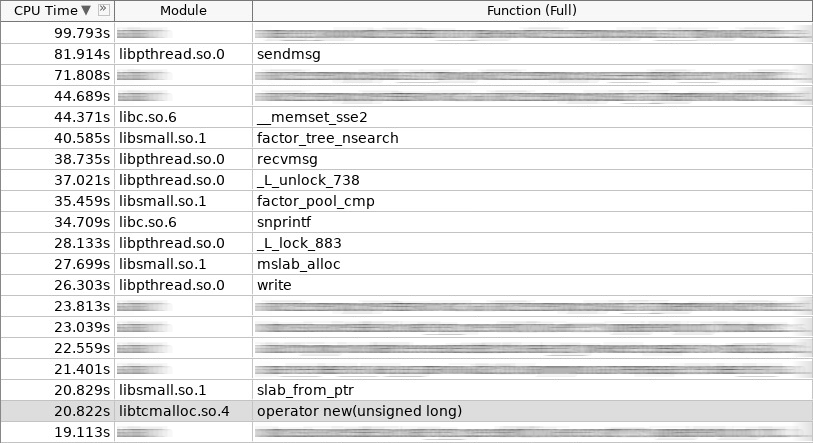
En la captura de pantalla, el operador nuevo trabajó 20 segundos, smalloc - 16 segundos, mslab_alloc - 27 segundos, el operador eliminó - 16 segundos, smfree - 7 segundos, mslab_free - 17 segundos. Total 103 segundos contra 161 segundos.
Tabla de medidas:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
En la vida real, el resultado debería ser aún mejor, ya que los asignadores de losas resuelven no solo el problema de la asignación y liberación de memoria prolongada, sino que también reducen la fragmentación. Sin losa, con el tiempo, la operación del operador nuevo y la eliminación del operador solo deberían disminuir. Con losa, siempre se mantendrá al mismo nivel.
Como podemos ver, los asignadores de losas resuelven con éxito el problema de asignación de memoria de los objetos de uso frecuente. Preste atención a ellos si el tema de la creación y eliminación frecuente de objetos es relevante para usted. ¡Pero no se olvide de las limitaciones que imponen a la arquitectura de su aplicación! No todos los objetos complejos se pueden colocar simplemente en la distribución de losas. ¡A veces tienes que rendirte mucho! Bueno, cuanto más compleja sea la arquitectura de su aplicación, más a menudo tendrá que encargarse de devolver el objeto a la caché correcta en términos de subprocesamiento múltiple. Puede ser simple cuando calculó de inmediato la arquitectura de la aplicación, teniendo en cuenta el uso de asignadores de losas, pero definitivamente causará dificultades cuando decida integrarlos en una etapa tardía.
App
¡Mira el código fuente
aquí !