En un
artículo anterior, hablamos sobre pronosticar series temporales. Una continuación lógica será un artículo sobre la identificación de anomalías.
Solicitud
La detección de anomalías se usa en áreas tales como:
1) Predicción de averías de equipos
Entonces, en 2010, las centrifugadoras iraníes fueron atacadas por el virus Stuxnet, que puso el equipo en un modo óptimo y deshabilitó parte del equipo debido al desgaste acelerado.
Si se usaran algoritmos de búsqueda de anomalías en el equipo, se podrían evitar situaciones de falla.

La búsqueda de anomalías en la operación de equipos se utiliza no solo en la industria nuclear, sino también en la metalurgia y la operación de turbinas de aviones. Y en otras áreas donde el uso del diagnóstico predictivo es más barato que las posibles pérdidas en caso de avería impredecible.
2) Predecir fraude
Si la tarjeta que usa en Podolsk se retira en Albania, es posible que la transacción se verifique más.
3) Identificar patrones de consumo anormales
Si algunos clientes exhiben un comportamiento anormal, puede haber un problema que desconoce.
4) Identificación de demanda y carga anormales
Si las ventas en la tienda FMCG han caído por debajo del límite del intervalo de confianza previsto, debe encontrar la razón de lo que está sucediendo.
Enfoques de detección de anomalías
1) El método de vectores de soporte con una clase SVM de una clase
Adecuado cuando los datos en el conjunto de entrenamiento obedecen a la distribución normal, mientras que el conjunto de prueba contiene anomalías.
El método de vector de soporte de clase única construye una superficie no lineal alrededor del origen. Es posible establecer el límite de corte, cuyos datos se consideran anormales.
Según la experiencia de nuestro equipo DATA4, One-Class SVM es el algoritmo más utilizado para resolver el problema de búsqueda de anomalías.

2) Método de bosque aislado - bosque aislado
Con el método "aleatorio" de construcción de árboles, las emisiones caerán en las hojas en las primeras etapas (a poca profundidad del árbol), es decir. las emisiones son más fáciles de "aislar". Los valores anómalos se extraen en las primeras iteraciones del algoritmo.

3) Envoltura elíptica y métodos estadísticos.
Se usa cuando los datos se distribuyen normalmente. Cuanto más cerca esté la medida de la cola de la mezcla de distribuciones, más anómalo será el valor.
Se pueden atribuir otros métodos estadísticos a esta clase.

 Imagen de dyakonov.org
Imagen de dyakonov.org4) métodos métricos
Los métodos incluyen algoritmos como k vecinos más cercanos, k-ésimo vecino más cercano, ABOD (detección de valores atípicos basados en ángulos) o LOF (factor de valores atípicos locales).
Adecuado si la distancia entre los valores en los signos es equivalente o normalizada (para no medir la boa en los loros).
El algoritmo de k vecinos más cercanos sugiere que los valores normales se encuentran en una determinada región del espacio multidimensional, y la distancia a las anomalías será mayor que al hiperplano de separación.
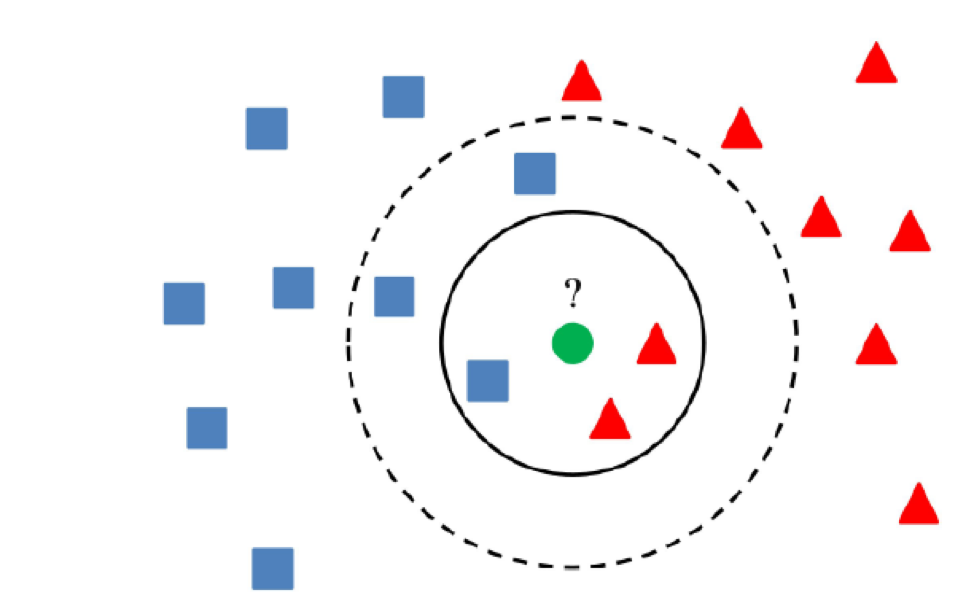
5) Métodos de agrupamiento
La esencia de los métodos de clúster es que si el valor está a más de una cierta distancia de los centros de los clústeres, el valor puede considerarse anómalo.
Lo principal es usar un algoritmo que agrupe correctamente los datos, que depende de la tarea específica.
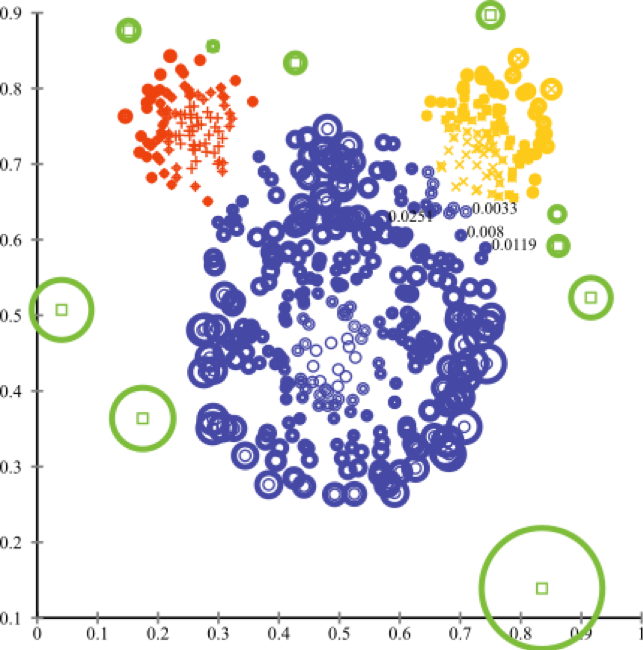
6) Método del componente principal
Adecuado donde se resaltan las áreas de mayor variación en la varianza.
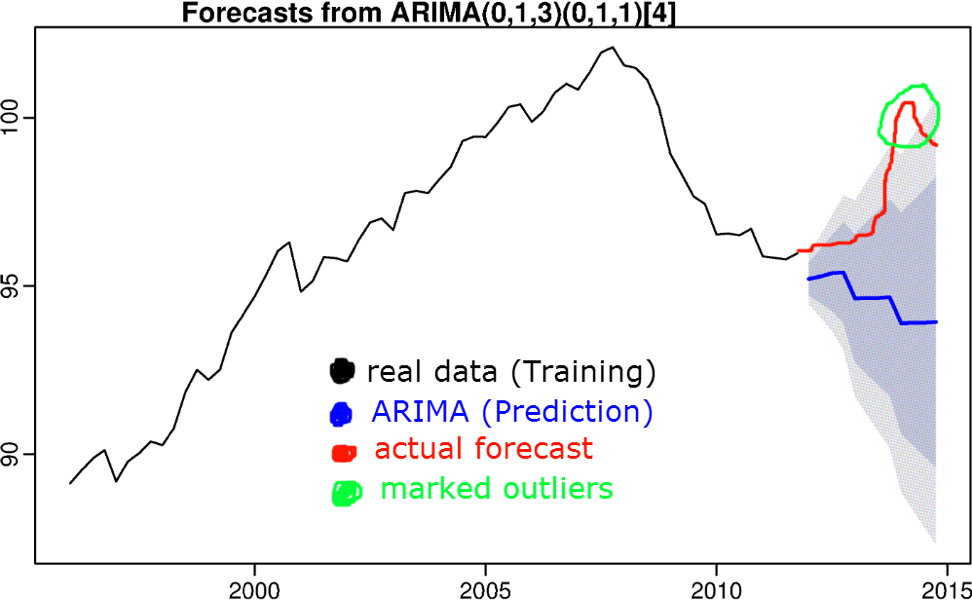
7) Algoritmos basados en pronósticos de series de tiempo
La idea es que si un valor se elimina de un intervalo de confianza de predicción, el valor se considera anormal. Algoritmos como triple anti-aliasing, S (ARIMA), refuerzo, etc. se utilizan para predecir las series de tiempo.
Los algoritmos de pronóstico de series de tiempo se discutieron en un artículo anterior.
8) Entrenamiento con un profesor (regresión, clasificación)
Si los datos lo permiten, utilizamos algoritmos de regresión lineal a redes recurrentes. Medimos la diferencia entre la predicción y el valor real, y concluimos cuánto se eliminan los datos de la norma. Es importante que el algoritmo tenga suficiente capacidad de generalización y que la muestra de entrenamiento no contenga valores anormales.
9) pruebas modelo
Abordamos el problema de buscar anomalías como la tarea de buscar recomendaciones. Descomponemos nuestra matriz de características usando SVD o máquinas de factorización, y los valores en la nueva matriz, significativamente diferentes de los originales, se consideran anormales.
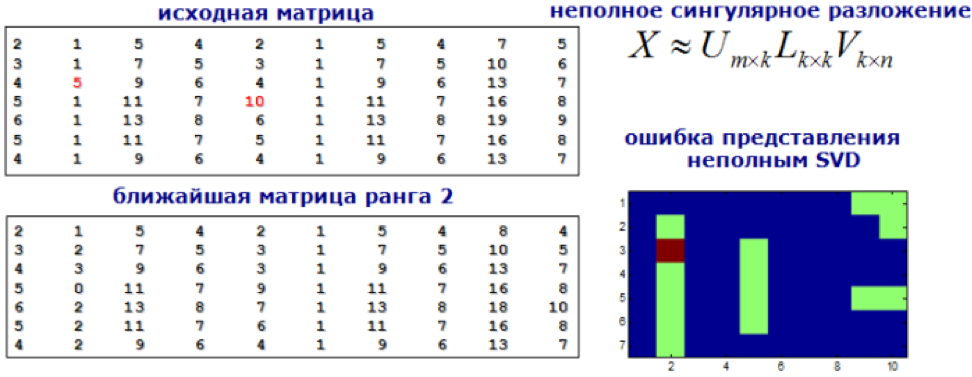 Imagen de dyakonov.org
Imagen de dyakonov.orgConclusión
En este artículo, examinamos los enfoques básicos para detectar anomalías.
La búsqueda de anomalías puede llamarse arte de muchas maneras. No existe un algoritmo o enfoque ideal cuya aplicación resuelva todos los problemas. Muy a menudo, se utiliza un conjunto de métodos para resolver un caso específico. Se buscan anomalías utilizando el método de clase única de vectores de soporte, aislando bosques, métodos métricos y de agrupamiento, así como utilizando los componentes principales y las series de tiempo de pronóstico.
Si conoce otros métodos, escríbalos en la sección de comentarios del artículo.