Muy a menudo, al desarrollar aplicaciones móviles (quizás el mismo problema con las aplicaciones web), los desarrolladores se encuentran en una situación en la que el backend no funciona o no proporciona los métodos necesarios.
Esta situación puede ocurrir por varias razones. Sin embargo, con mayor frecuencia al comienzo del desarrollo, el backend simplemente no está escrito y el cliente comienza sin él. En este caso, el inicio del desarrollo se retrasa de 2 a 4 meses.
A veces el servidor simplemente se apaga (se bloquea), a veces no tiene tiempo para implementar los métodos necesarios, a veces hay problemas de datos, etc. Todos estos problemas nos llevaron a escribir un pequeño servicio Mocker, que le permite reemplazar el backend real.

¿Cómo llegué a esto?¿Cómo llegué a esto? Mi primer año en la compañía estaba terminando y me pusieron en un nuevo proyecto de comercio electrónico. El gerente dijo que el proyecto debe completarse en 4 meses, pero el equipo de back-end (en el lado del cliente) comenzará el desarrollo solo después de 1,5 meses. Y durante este tiempo tenemos que lanzar muchas funciones de UI.
Sugerí escribir un backend moch (antes de convertirme en desarrollador de iOS, jugué con .NET en la uni). La idea de implementación era simple: de acuerdo con una especificación dada, era necesario escribir métodos de código auxiliar que tomaran datos de archivos JSON preparados previamente. Se decidieron por eso.
Después de 2 semanas, me fui de vacaciones y pensé: "¿Por qué no genero automáticamente todo esto?" Entonces, durante 2 semanas de vacaciones, escribí una especie de intérprete que toma la especificación APIBlueprint y genera la aplicación web .NET a partir de ella (código C #).
Como resultado, apareció la primera versión de esta cosa y la vivimos durante casi 2.5 meses. No puedo dar cifras reales, cuánto nos ayudó esto, pero recuerdo cómo dijeron en retrospectiva que si no fuera por este sistema, no habría lanzamiento.
Ahora, después de varios años, tomé en cuenta los errores cometidos por mí (y hubo muchos de ellos) y reescribí completamente el instrumento.
Aprovechando esta oportunidad, muchas gracias a los colegas que ayudaron con sus comentarios y consejos. Y también a los líderes que soportaron toda mi "arbitrariedad de ingeniería".
Introduccion
Como regla, cualquier aplicación cliente-servidor se ve así:
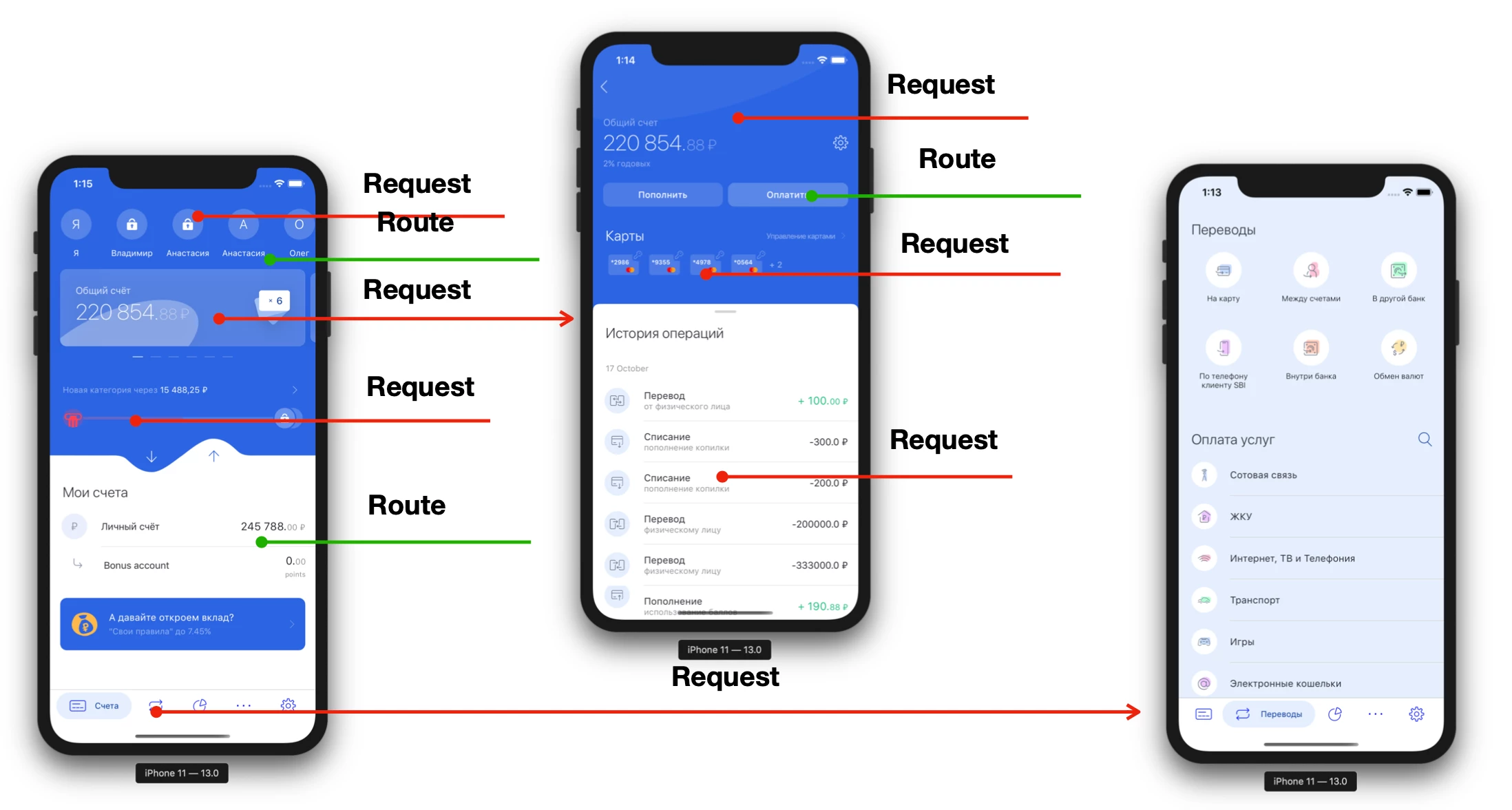
Cada pantalla tiene al menos 1 consulta (y a menudo más). Moviéndonos profundamente en las pantallas, necesitamos hacer más y más solicitudes. A veces ni siquiera podemos hacer la transición hasta que el servidor nos diga "Mostrar el botón". Es decir, la aplicación móvil está muy vinculada al servidor, no solo durante su trabajo inmediato, sino también en la etapa de desarrollo. Considere el ciclo de desarrollo de producto abstracto:

- Primero diseñamos. Descomponemos, describimos y discutimos.
- Habiendo recibido las tareas y requisitos, comenzamos el desarrollo. Escribimos el código, tipografía, etc.
- Después de que hayamos implementado algo, se está preparando un ensamblaje, que pasa a pruebas manuales, donde se verifica la aplicación para diferentes casos.
- Si todo está bien con nosotros, y los probadores prueban el ensamblaje, el cliente lo lleva a cabo.
Cada uno de estos procesos es muy importante. Especialmente lo último, ya que el cliente debe comprender en qué etapa estamos realmente y, a veces, debe informar los resultados a la gerencia o a los inversores. Como regla, tales informes ocurren, incluso en el formato de una demostración de una aplicación móvil. En mi práctica, hubo un caso en el que un cliente demostró solo la mitad del MVP, que solo funcionaba en mokas. La aplicación mok se parece al presente y grazna como el presente. Entonces es real (:
Sin embargo, este es un sueño rosado. Veamos qué sucede realmente si no tenemos un servidor.

- El proceso de desarrollo será más lento y doloroso, ya que no podemos escribir servicios normalmente, tampoco podemos verificar todos los casos, tenemos que escribir talones que deberán eliminarse más adelante.
- Después de que hicimos la asamblea por la mitad con pena, llega a los evaluadores que la miran y no entienden qué hacer con ella. No puede verificar nada, la mitad no funciona en absoluto, porque no hay servidor. Como resultado, se pierden muchos errores: tanto lógicos como visuales.
- Bueno, después de "cómo podrían haberse visto", debe entregar el ensamblaje al cliente y luego comienza lo más desagradable. El cliente realmente no puede evaluar el trabajo, ve 1-2 casos fuera de todo posible y ciertamente no puede mostrárselo a sus inversores.
En general, todo va cuesta abajo. Y desafortunadamente, tales situaciones ocurren casi siempre: a veces no hay servidor durante un par de meses, a veces medio año, a veces solo en el proceso, el servidor llega muy tarde o debe verificar rápidamente los casos límite que se pueden reproducir utilizando manipulaciones de datos en un servidor real.
Por ejemplo, queremos verificar cómo se comporta la aplicación si el pago del usuario es mayor que la fecha de vencimiento. Es muy difícil (y largo) reproducir tal situación en el servidor y necesitamos hacerlo artificialmente.
Por lo tanto, existen los siguientes problemas:
- Falta el servidor por completo. Debido a esto, es imposible diseñar, probar y presentar.
- El servidor no tiene tiempo, lo que interfiere con el desarrollo y puede interferir con las pruebas.
- Queremos probar los casos límite, y el servidor no puede permitir esto sin gestos largos.
- Afecta las pruebas y las presentaciones amenazantes.
- El servidor se bloquea (una vez, durante el desarrollo estable, perdimos el servidor durante 3,5 días).
Para combatir estos problemas, se creó Mocker.
Principio de funcionamiento
Mocker es un pequeño servicio web que está alojado en algún lugar, escucha el tráfico en un puerto específico y puede responder con datos preparados previamente a solicitudes de red específicas.
La secuencia es la siguiente:
1. El cliente envía una solicitud.
2. Mocker recibe la solicitud.
3. Mocker encuentra el simulacro deseado.
4. Mocker devuelve el simulacro deseado.
Si todo está claro con los puntos 1,2 y 4, 3 plantea preguntas.
Para entender cómo el servicio encuentra el simulacro necesario para el cliente, primero consideramos la estructura del simulacro en sí.
Mock es un archivo JSON en el siguiente formato:
{ "url": "string", "method": "string", "statusCode": "number", "response": "object", "request": "object" }
Analicemos cada campo por separado.
url
Este parámetro se utiliza para especificar la URL de la solicitud a la que accede el cliente.
Por ejemplo, si una aplicación móvil realiza una solicitud para url
host.dom/path/to/endpoint , entonces en el campo
url necesitamos escribir
/path/to/endpoint .
Es decir, este campo almacena la
ruta relativa al punto final .
Este campo debe formatearse en el formato de plantilla de URL, es decir, se permiten los siguientes formatos:
/path/to/endpoint : dirección URL normal. Cuando se recibe la solicitud, el servicio comparará las líneas carácter por carácter./path/to/endpoint/{number} : url con patrón de ruta. Un simulacro con dicha URL responderá a cualquier solicitud que coincida con este patrón./path/to/endpoint/data?param={value} - url con patrón de parámetros. Simulacros con tal url activará una solicitud que contenga los parámetros dados. Además, si uno de los parámetros no está en la solicitud, no coincidirá con la plantilla.
Por lo tanto, al controlar los parámetros de URL, puede determinar claramente que un simulacro determinado volverá a una URL específica.
método
Este es el método http esperado. Por ejemplo
POST o
GET .
La cadena debe contener solo letras mayúsculas.
statusCode
Este es el código de estado http para la respuesta. Es decir, al solicitar este simulacro, el cliente recibirá una respuesta con el estado registrado en el campo statusCode.
respuesta
Este campo contiene el objeto JSON que se enviará al cliente en el cuerpo de la respuesta a su solicitud.
solicitud
Este es el cuerpo de la solicitud que se espera recibir del cliente, que se utilizará para dar la respuesta deseada según el cuerpo de la solicitud. Por ejemplo, si queremos cambiar las respuestas según los parámetros de la solicitud.
{ "url": "/auth", "method": "POST", "statusCode": 200, "response": { "token": "cbshbg52rebfzdghj123dsfsfasd" }, "request": { "login": "Tester", "password": "Valid" } }
{ "url": "/auth", "method": "POST", "statusCode": 400, "response": { "message": "Bad credentials" }, "request": { "login": "Tester", "password": "Invalid" } }
Si el cliente envía una solicitud con el cuerpo:
{ "login": "Tester", "password": "Valid" }
Luego, en respuesta, recibirá:
{ "token": "cbshbg52rebfzdghj123dsfsfasd" }
Y en caso de que queramos verificar cómo funcionará la aplicación si la contraseña se ingresa incorrectamente, se enviará una solicitud con el cuerpo:
{ "login": "Tester", "password": "Invalid" }
Luego, en respuesta, recibirá:
{ "message": "Bad credentials" }
Y podemos verificar el caso con la contraseña incorrecta. Y así para todos los demás casos.
Y ahora descubriremos cómo funciona la agrupación y la búsqueda del moq deseado.

Para buscar rápida y fácilmente el mok deseado, el servidor carga todos los mokas en la memoria y los agrupa de la manera correcta. La imagen de arriba muestra un ejemplo de agrupación.
El servidor combina diferentes mokas por
url y
método . Esto es necesario, entre otras cosas, para que podamos crear muchos moks diferentes en una url.
Por ejemplo, deseamos que constantemente tire de Pull-To-Refresh, lleguen diferentes respuestas y el estado de la pantalla cambie todo el tiempo (para verificar todos los casos límite).
Luego podemos crear muchos moks diferentes con el mismo
método y parámetros de
URL , y el servidor nos los devolverá de forma iterativa (a su vez).
Por ejemplo, tengamos tales mokas:
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "product", "currency": 1, "value": 20 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": null }
{ "url": "/products", "method": "GET", "statusCode": 400, "response": null }
Luego, cuando llamamos al método GET / productos por primera vez, primero obtendremos la respuesta:
{ "name": "product", "currency": 1, "value": 20 }
Cuando llamamos por segunda vez, el puntero iterador cambiará al siguiente elemento y volverá a nosotros:
{ "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 }
Y podemos comprobar cómo se comporta la aplicación si obtenemos algunos valores importantes. Y así sucesivamente.
Bueno, y cuando lleguemos al último elemento y llamemos al método nuevamente, el primer elemento volverá a nosotros nuevamente, porque el iterador volverá al primer elemento.
Proxy de almacenamiento en caché
Mocker puede funcionar en modo proxy de almacenamiento en caché. Esto significa que cuando un servicio recibe una solicitud de un cliente, saca la dirección del host en el que se encuentra el servidor real y el esquema (para determinar el protocolo). Luego toma la solicitud recibida (con todos sus encabezados, por lo que si el método requiere autenticación, entonces está bien, su
Authorization: Bearer ... transferido) y corta la información del servicio (el mismo
host y
scheme ) y envía la solicitud al servidor real.
Después de recibir la respuesta con el código 200, Mocker guarda la respuesta en el archivo Mock (sí, puede copiarlo o cambiarlo) y devuelve al cliente lo que recibió del servidor real. Además, no solo guarda el archivo en un lugar aleatorio, sino que organiza los archivos para que luego pueda trabajar con ellos manualmente. Por ejemplo, Mocker envía una solicitud a la siguiente URL:
hostname.dom/main/products/loans/info . Luego creará una carpeta
hostname.dom , luego dentro de ella creará una carpeta
main , dentro de ella una carpeta de
products ...
Para evitar simulacros duplicados, el nombre se forma sobre la base del
método http (GET, PUT ...) y un
hash del cuerpo de respuesta del servidor real . En este caso, si ya hay un simulacro en una respuesta específica, simplemente se sobrescribirá.
Esta característica se puede activar individualmente para cada solicitud. Para hacer esto, agregue tres encabezados a la solicitud:
X-Mocker-Redirect-Is-On: "true", X-Mocker-Redirect-Host: "hostaname.ex:1234", X-Mocker-Redirect-Scheme: "http"
Indicación explícita de la ruta a los simulacros.
A veces quieres que Mocker devuelva solo los mokas que queremos, y no todos los que están en el proyecto.
Especialmente relevante para probadores. Sería conveniente para ellos tener algún tipo de conjunto de mokas preparado para cada uno de los casos de prueba. Y luego, durante las pruebas, el control de calidad solo selecciona la carpeta que necesita y funciona silenciosamente, porque no hay más ruido de simulacros de terceros.
Ahora esto es posible. Para habilitar esta función, debe usar un encabezado especial:
X-Mocker-Specific-Path: path
Por ejemplo, deje que Mocker tenga dicha estructura de carpetas en la raíz
root/ block_card_test_case/ mocks.... main_test_case/ blocked_test_case/ mocks...
Si necesita ejecutar un caso de prueba sobre tarjetas bloqueadas, entonces
X-Mocker-Specific-Path: block_card_test_caseSi necesita ejecutar un caso de prueba asociado con el bloqueo de la pantalla principal, entonces
X-Mocker-Specific-Path: main_test_case/blocked_test_caseInterfaz
Al principio trabajamos con mokas directamente a través de ssh, pero con un aumento en el número de mokas y usuarios, cambiamos a una opción más conveniente. Ahora estamos usando CloudCommander.
En el ejemplo docker-compose, se une al contenedor Mocker.
Se parece a esto:
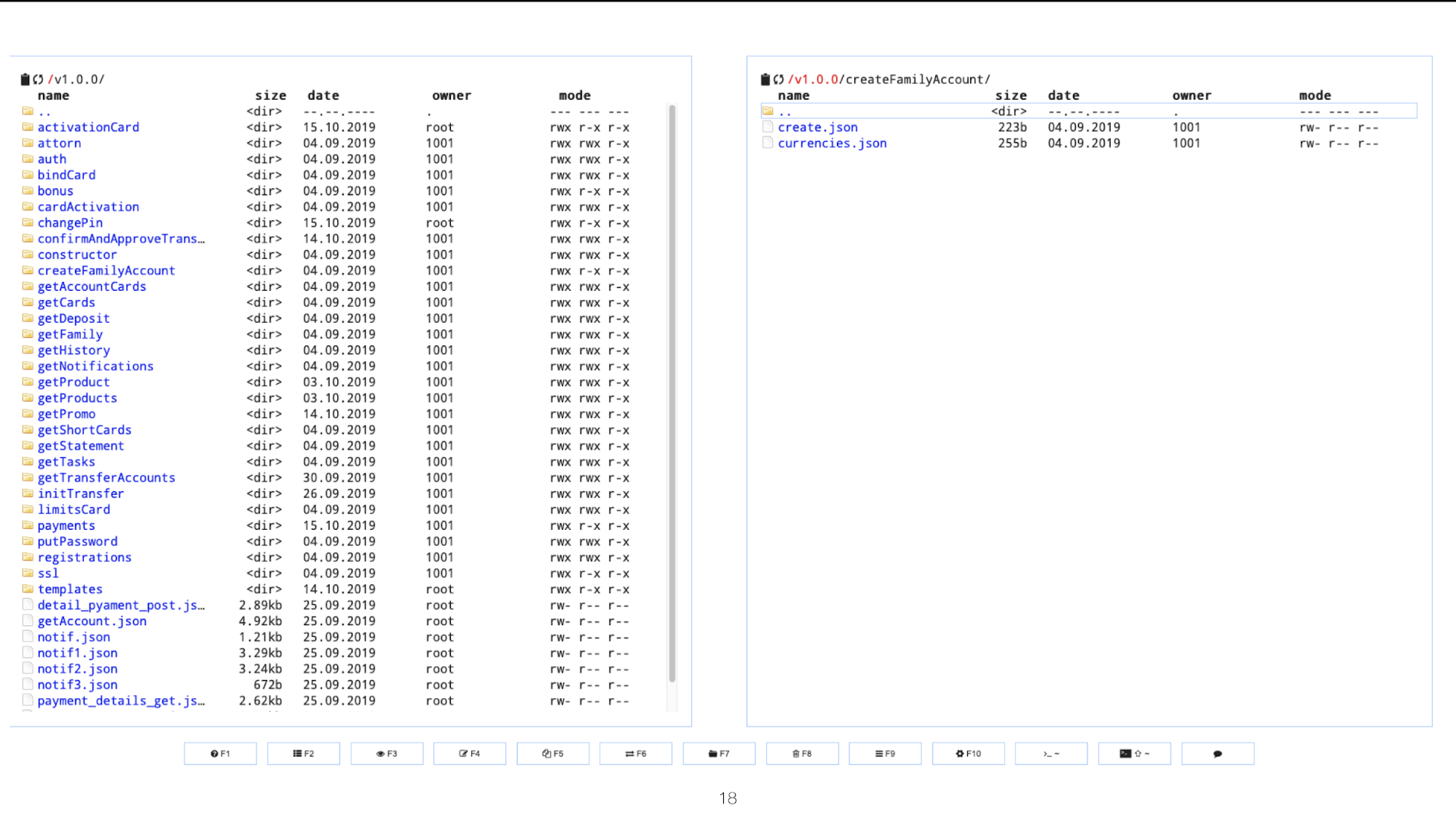
Bueno, el bono es un editor web, que le permite agregar / cambiar moki directamente desde el navegador.

Esta también es una solución temporal. En los planes para evitar trabajar con moks a través del sistema de archivos a alguna base de datos. Y en consecuencia, será posible controlar los propios mokas desde la GUI a este DB.
Despliegue
La forma más fácil de implementar Mocker es usar Docker. Además, la implementación del servicio desde la ventana acoplable desplegará automáticamente una interfaz basada en web a través de la cual es más conveniente trabajar con mokas. Los archivos necesarios para la implementación a través de Docker están en el repositorio.
Sin embargo, si esta opción no le conviene, puede ensamblar independientemente el servicio desde la fuente. Suficiente para esto:
git clone https://github.com/LastSprint/mocker.git cd mocker go build .
Luego debe escribir un archivo de configuración (
ejemplo ) e iniciar el servicio:
mocker config.json
Problemas conocidos
- Después de cada archivo nuevo, debe hacer
curl mockerhost.dom/update_models para que el servicio lea los archivos nuevamente. No encontré una manera rápida y elegante de actualizarlo de otra manera - A veces, los errores de CloudCommander (o hice algo mal) y no permiten editar moki que se crearon a través de la interfaz web. Se trata borrando la memoria caché del navegador.
- El servicio solo funciona con
application/json . Los planes admiten form-url-encoding .
Resumen
Mocker es un servicio web que resuelve los problemas de desarrollar aplicaciones cliente-servidor cuando el servidor no está listo por alguna razón.
El servicio le permite crear muchos simulacros diferentes en una sola URL, le permite conectar Solicitud y Respuesta entre sí especificando explícitamente los parámetros en la URL, o directamente configurando el cuerpo de solicitud esperado. El servicio tiene una interfaz basada en la web que simplifica enormemente la vida de los usuarios.
Cada usuario del servicio puede agregar independientemente el punto final necesario y la solicitud que necesita. En este caso, en el cliente, para cambiar a un servidor real, es suficiente simplemente reemplazar la constante con la dirección del host.
Espero que este artículo ayude a las personas que sufren problemas similares y, quizás, trabajaremos juntos para desarrollar esta herramienta.
Repositorio de GitHub .