La pregunta clásica de que un desarrollador llega a su DBA o al dueño de un negocio, un consultor de PostgreSQL, casi siempre suena igual:
"¿Por qué las consultas se ejecutan en la base de datos durante tanto tiempo?"El conjunto tradicional de razones:
- algoritmo ineficiente
cuando decidiste unirte a varios CTE para un par de decenas de miles de registros - estadísticas irrelevantes
si la distribución real de datos en la tabla ya es muy diferente de la última vez que ANALYZE la recopiló - "Mordaza" por recursos
y la potencia de cálculo asignada de la CPU ya no es suficiente, los gigabytes de memoria se bombean constantemente o el disco no se mantiene al día con toda la "Lista de deseos" de la base de datos - bloqueo de procesos competitivos
Y si las cerraduras son bastante difíciles de capturar y analizar, entonces para todo lo demás, necesitamos
un plan de consulta que se pueda obtener utilizando
el operador EXPLAIN (
mejor, por supuesto, inmediatamente EXPLAIN (ANALYZE, BUFFERS) ... ) o
el módulo auto_explain .
Pero, como se dice en la misma documentación,
"Comprender el plan es un arte, y para dominarlo, necesitas algo de experiencia, ..."
¡Pero puedes prescindir de él si usas la herramienta adecuada!
¿Cómo se ve generalmente un plan de consulta? Algo como esto:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
o así:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Pero leer el plan con el texto "de la hoja" es muy difícil y querido:
- el nodo muestra la suma de los recursos del subárbol
es decir, para comprender cuánto tiempo se tardó en ejecutar un nodo en particular, o exactamente cuánto esta lectura de la tabla generó datos del disco, de alguna manera debe restar uno del otro - el tiempo de nodo debe multiplicarse por bucles
Sí, la resta no es la operación más difícil que debe hacerse "en la mente". Después de todo, el tiempo de ejecución se indica como promedio sobre una ejecución del nodo, y puede haber cientos de ellos. - bueno, y todo esto en conjunto dificulta la respuesta a la pregunta principal, entonces, ¿quién es el "eslabón más débil" ?
Cuando intentamos explicar todo esto a varios cientos de nuestros desarrolladores, nos dimos cuenta de que desde afuera se ve así:

Y eso significa que necesitamos ...
Instrumento
En él, tratamos de recopilar todas las mecánicas clave que ayudan de acuerdo con el plan y solicitan entender "quién tiene la culpa y qué hacer". Bueno, comparta parte de su experiencia con la comunidad.
Conocer y usar -
explicar.tensor.ruPlanes claros
¿Es fácil entender un plan cuando se ve así?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
En realidad no
Pero así,
en forma abreviada , cuando los indicadores clave están separados, ya es mucho más claro:
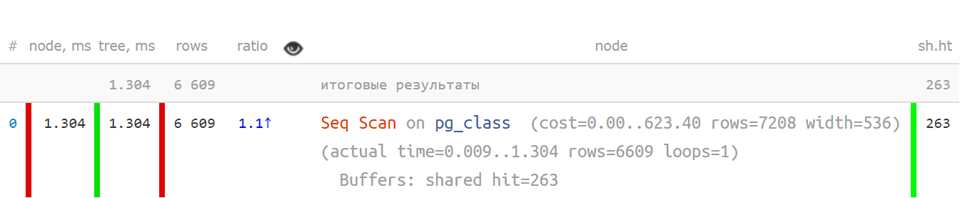
Pero si el plan es más complicado, la
distribución del tiempo del gráfico circular por nodos vendrá al
rescate :
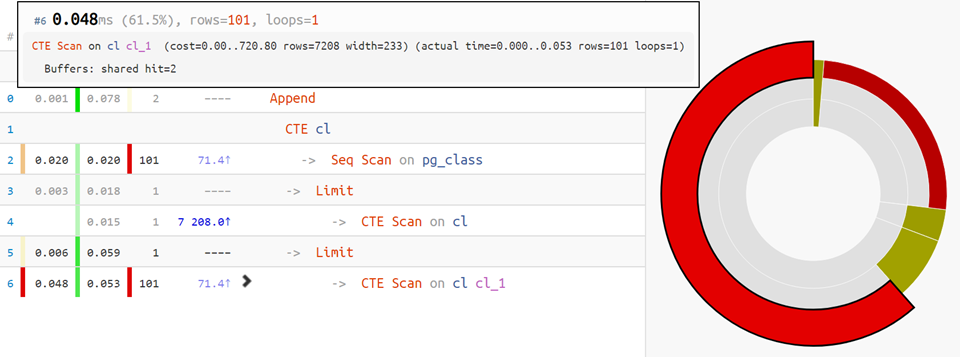
Bueno, para las opciones más difíciles,
el diagrama de ejecución se apresura a ayudar:
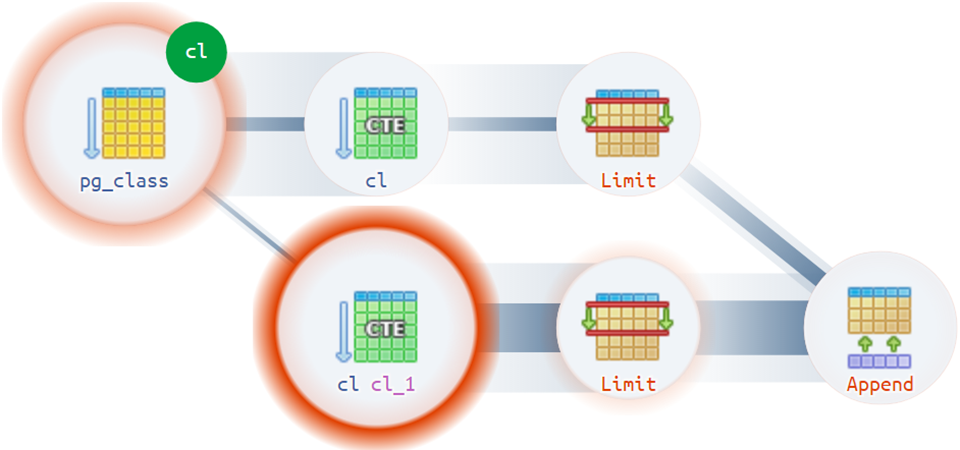
Por ejemplo, hay situaciones bastante triviales en las que un plan puede tener más de una raíz real:
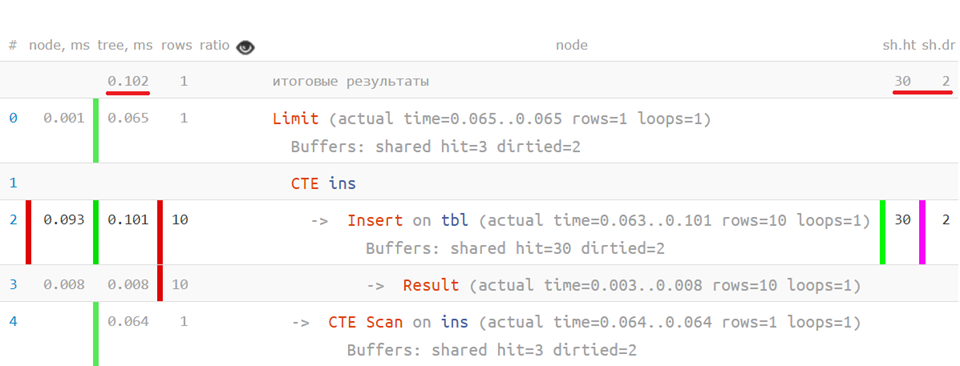
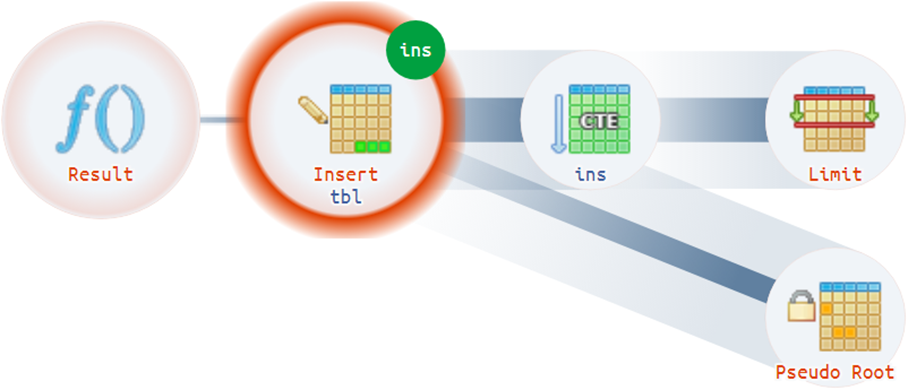
Consejos estructurales
Bueno, y si toda la estructura del plan y sus puntos dolorosos ya están establecidos y visibles, ¿por qué no resaltarlos con el desarrollador y explicarlos con el "idioma ruso"?

Ya hemos recopilado un par de docenas de plantillas de recomendación.
Perfil de consulta
Ahora, si coloca la consulta original en el plan analizado, puede ver cuánto tiempo le tomó a cada operador individual, algo como esto:
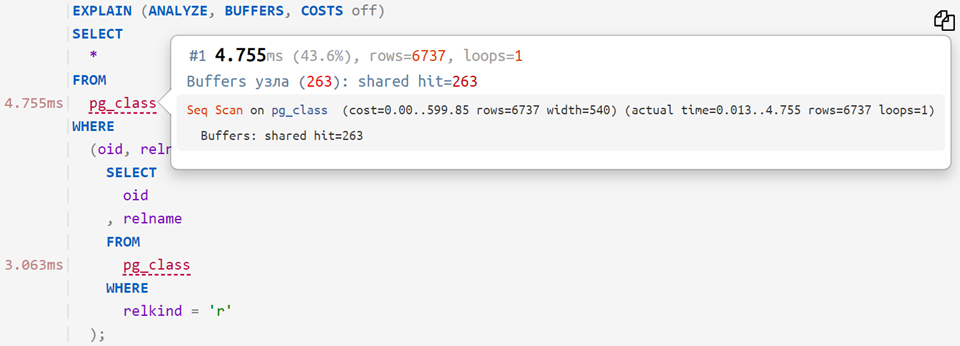
... o aun así:

Sustitución de parámetros en la solicitud.
Si "adjuntó" no solo la solicitud al plan, sino también sus parámetros de la línea DETAIL del registro, puede copiarla adicionalmente en una de las opciones:
- con sustitución de valores en la solicitud
para ejecución directa en su base y más perfiles
SELECT 'const', 'param'::text;
- con sustitución de valor a través de PREPARE / EXECUTE
para emular el trabajo del planificador cuando se puede ignorar la parte paramétrica, por ejemplo, cuando se trabaja en tablas particionadas
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Archivo de planes
Insertar, analizar, compartir con colegas! Los planes permanecerán en el archivo, y puede volver a ellos más adelante:
explicar.tensor.ru/archivePero si no desea que otros vean su plan, no olvide marcar la casilla de verificación "no publicar en el archivo".
En los siguientes artículos hablaré sobre las dificultades y soluciones que surgen en el análisis del plan.