Hola
Sucede que miras una película, y en tu cabeza solo hay una pregunta: "¿Estoy recibiendo clickbait nuevamente?" Resolveremos este problema y solo veremos películas adecuadas. Sugiero experimentar un poco con los datos y escribir una red neuronal simple para evaluar la película.
Nuestro experimento se basa en la tecnología de análisis de sentimientos para determinar el estado de ánimo de la audiencia para un producto. Como datos tomamos un conjunto de datos de reseñas de usuarios en películas de IMDb. El entorno de desarrollo de Google Colab le permitirá entrenar rápidamente su red neuronal gracias al acceso gratuito a la GPU (NVidia Tesla K80).
Utilizo la biblioteca Keras, con la ayuda de la cual construiré un modelo universal para resolver problemas similares de aprendizaje automático. Necesitaré el backend TensorFlow, la versión predeterminada en Colab 1.15.0, así que solo actualice a 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
A continuación, importamos todos los módulos necesarios para el procesamiento previo de datos y la construcción de modelos. En artículos anteriores, el énfasis está en las bibliotecas, puede mirar allí.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Análisis de datos de IMDb
El conjunto de datos de IMDb consta de 50,000 críticas de películas de usuarios marcados como positivos (1) y negativos (0).
- Las revisiones se procesan previamente y cada una de ellas está codificada por una secuencia de índices de palabras en forma de enteros.
- Las palabras en las revisiones se indexan por su frecuencia total en el conjunto de datos. Por ejemplo, el número entero "2" codifica la segunda palabra más utilizada
- 50,000 revisiones se dividen en dos conjuntos: 25,000 para capacitación y 25,000 para pruebas.
Descargue el conjunto de datos integrado en Keras. Dado que los datos se dividen en entrenamiento y prueba en una proporción de 50-50, los combinaré para luego poder dividirlos por 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Exploración de datos.
Veamos con qué estamos trabajando.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

Puede ver que todos los datos pertenecen a dos categorías: 0 o 1, que representa el estado de ánimo de la revisión. El conjunto de datos completo contiene 9998 palabras únicas, el tamaño promedio de revisión es de 234 palabras con una desviación estándar de 173.
Veamos la primera revisión de este conjunto de datos, que está marcada como positiva.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Preparación de datos
Es hora de preparar los datos. Necesitamos vectorizar cada encuesta y llenarla con ceros para que el vector contenga exactamente 10,000 números. Esto significa que cada revisión que tiene menos de 10,000 palabras está llena de ceros. Hago esto porque la descripción general más grande es casi del mismo tamaño, y cada elemento de entrada de nuestra red neuronal debe tener el mismo tamaño. También necesita convertir las variables a un tipo flotante.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
A continuación, divido el conjunto de datos en datos de entrenamiento y prueba según lo acordado 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Crea y entrena un modelo
La cosa es pequeña, solo queda escribir un modelo y entrenarlo. Comience por elegir un tipo. Hay dos tipos de modelos disponibles en Keras: secuenciales y con una API funcional. Luego debe agregar capas de entrada, ocultas y de salida.
Para evitar el reentrenamiento, utilizaremos un "abandono" entre ellos. En cada capa usaremos la función "densa" para conectar completamente las capas entre sí. En capas ocultas usaremos la función de activación "relu", esto casi siempre conduce a resultados satisfactorios. En la capa de salida usamos una función sigmoide que renormaliza los valores en el rango de 0 a 1.
Yo uso el optimizador Adam, cambiará los pesos durante el entrenamiento.
Utilizamos la entropía cruzada binaria como una función de pérdida y la precisión como una medida de medida.
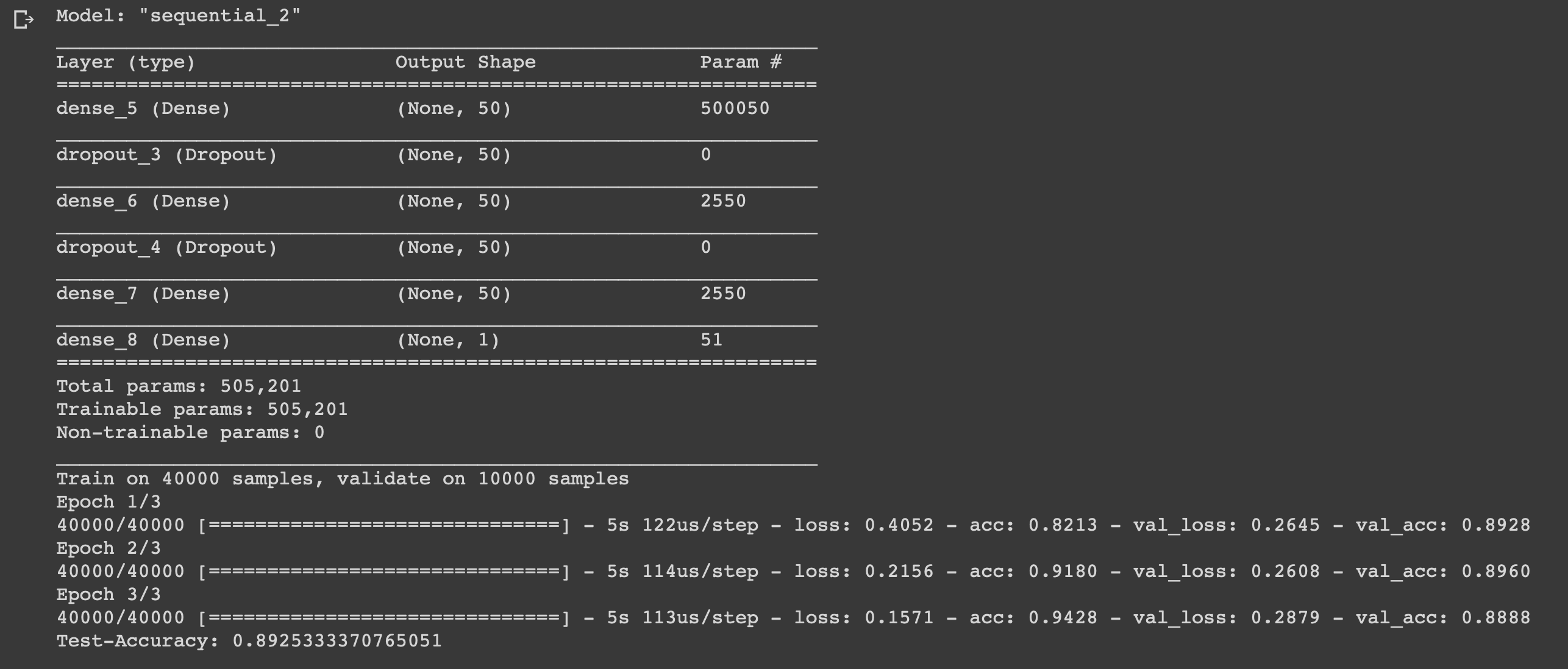
Ahora puedes entrenar a nuestro modelo. Haremos esto con un tamaño de lote de 500 y solo tres eras, ya que se reveló que el modelo comienza a reentrenar si se entrena más tiempo.
model = models.Sequential()
Conclusión
Hemos creado una red neuronal simple de seis capas que puede calcular el estado de ánimo de los cineastas con una precisión de 0,89. Por supuesto, para ver películas geniales no es necesario escribir una red neuronal, pero este fue solo otro ejemplo de cómo puede usar los datos, beneficiarse de ellos, porque los necesita para eso. La red neuronal es universal debido a la simplicidad de su estructura, al cambiar algunos parámetros, puede adaptarla para tareas completamente diferentes.
Siéntase libre de escribir sus ideas en los comentarios.