
El diseño de análisis de transmisión y sistemas de procesamiento de datos de transmisión tiene sus propios matices, sus propios problemas y su propia pila tecnológica. Hablamos de esto en la próxima
lección abierta , realizada en la víspera del lanzamiento del curso de
Ingeniero de Datos .
En el seminario web discutido:
- cuando se necesita procesamiento de transmisión;
- qué elementos están en SPOD, qué herramientas podemos usar para implementar estos elementos;
- cómo construir su propio sistema de análisis de clickstream.
Profesor:
Yegor Mateshuk , ingeniero de datos sénior en MaximaTelecom.
¿Cuándo se necesita la transmisión? Stream vs Batch
En primer lugar, debemos determinar cuándo necesitamos la transmisión y el procesamiento por lotes. Expliquemos las fortalezas y debilidades de estos enfoques.
Entonces, las desventajas del procesamiento por lotes:- los datos se entregan con retraso. Dado que tenemos un cierto período de cálculos, para este período siempre nos quedamos atrás en tiempo real. Y cuanto más iteración, más nos quedamos atrás. Por lo tanto, tenemos un retraso de tiempo, que en algunos casos es crítico;
- Se crea la carga máxima sobre el hierro. Si calculamos un lote en modo por lotes, al final del período (día, semana, mes) tenemos una carga máxima, porque necesita calcular muchas cosas. ¿A qué conduce esto? Primero, comenzamos a descansar contra límites que, como saben, no son infinitos. Como resultado, el sistema se ejecuta periódicamente hasta el límite, lo que a menudo resulta en fallas. En segundo lugar, dado que todos estos trabajos comienzan al mismo tiempo, compiten y se calculan bastante lentamente, es decir, no puede contar con un resultado rápido.
Pero el procesamiento por lotes tiene sus ventajas:- Alta eficiencia. No profundizaremos, ya que la eficiencia está asociada con la compresión, con los marcos y con el uso de formatos de columna, etc. El hecho es que el procesamiento por lotes, si toma la cantidad de registros procesados por unidad de tiempo, será más eficiente;
- facilidad de desarrollo y soporte. Puede procesar cualquier parte de los datos mediante pruebas y recuentos según sea necesario.
Ventajas del procesamiento de transmisión de datos (transmisión):- resultado en tiempo real. No esperamos el final de ningún período: tan pronto como nos lleguen los datos (incluso una cantidad muy pequeña), podemos procesarlos de inmediato y transmitirlos. Es decir, el resultado, por definición, es luchar por el tiempo real;
- Carga uniforme sobre hierro. Está claro que hay ciclos diarios, etc., sin embargo, la carga todavía se distribuye durante todo el día y resulta más uniforme y predecible.
La principal desventaja del procesamiento de transmisión:- complejidad de desarrollo y soporte. Primero, probar, administrar y recuperar datos es un poco más difícil en comparación con el lote. La segunda dificultad (de hecho, este es el problema más básico) está asociada con las reversiones. Si los trabajos no funcionaron y hubo un fracaso, es muy difícil capturar exactamente el momento en que todo se rompió. Y resolver el problema requerirá más esfuerzo y recursos que el procesamiento por lotes.
Entonces, si está pensando
si necesita transmisiones , responda las siguientes preguntas por sí mismo:
- ¿Realmente necesitas en tiempo real?
- ¿Hay muchas fuentes de transmisión?
- ¿Perder un récord es crítico?
Veamos
dos ejemplos :
Ejemplo 1. Análisis de existencias para el comercio minorista:- la exhibición de bienes no cambia en tiempo real;
- los datos se entregan con mayor frecuencia en modo por lotes;
- La pérdida de información es crítica.
En este ejemplo, es mejor usar lote.
Ejemplo 2. Análisis para un portal web:- la velocidad analítica determina el tiempo de respuesta a un problema;
- los datos llegan en tiempo real;
- Las pérdidas de una pequeña cantidad de información de actividad del usuario son aceptables.
Imagine que el análisis refleja cómo se sienten los visitantes de un portal web al usar su producto. Por ejemplo, lanzó una nueva versión y necesita comprender dentro de 10-30 minutos si todo está en orden, si alguna característica personalizada se ha roto. Supongamos que el texto del botón "Pedido" ha desaparecido: los análisis le permitirán responder rápidamente a una fuerte caída en el número de pedidos, e inmediatamente comprenderá que necesita retroceder.
Por lo tanto, en el segundo ejemplo, es mejor usar flujos.
Elementos SPOD
Los ingenieros de procesamiento de datos capturan, mueven, entregan, convierten y almacenan estos mismos datos (sí, ¡el almacenamiento de datos también es un proceso activo!).
Por lo tanto, para construir un sistema de procesamiento de datos de transmisión (SPOD), necesitaremos los siguientes elementos:
- cargador de datos (medios de entrega de datos al almacenamiento);
- bus de intercambio de datos (no siempre es necesario, pero no hay forma de transmitirlo porque necesita un sistema a través del cual intercambiará datos en tiempo real);
- almacenamiento de datos (como sin él);
- Motor ETL (necesario para realizar varias operaciones de filtrado, clasificación y otras operaciones);
- BI (para mostrar resultados);
- orquestador (vincula todo el proceso, organizando el procesamiento de datos en varias etapas).
En nuestro caso, consideraremos la situación más simple y nos centraremos solo en los primeros tres elementos.
Herramientas de procesamiento de flujo de datos
Tenemos varios "candidatos" para el rol de
cargador de
datos :
- Canal de apache
- Apache nifi
- Streamset
Canal de apache
El primero del que hablaremos es
Apache Flume , una herramienta para transportar datos entre diferentes fuentes y repositorios.

Pros:
- hay casi en todas partes
- usado durante mucho tiempo
- lo suficientemente flexible y extensible
Contras:
- configuración inconveniente
- difícil de monitorear
En cuanto a su configuración, se parece a esto:

Arriba, creamos un canal simple que se encuentra en el puerto, toma datos de allí y simplemente lo registra. En principio, para describir un proceso, esto sigue siendo normal, pero cuando tiene docenas de dichos procesos, el archivo de configuración se convierte en un infierno. Alguien agrega algunos configuradores visuales, pero ¿por qué molestarse si hay herramientas que lo hacen fuera de la caja? Por ejemplo, el mismo NiFi y StreamSets.
Apache nifi
De hecho, desempeña el mismo papel que Flume, pero con una interfaz visual, que es una gran ventaja, especialmente cuando hay muchos procesos.
Un par de hechos sobre NiFi
- desarrollado originalmente en la NSA;
- Hortonworks ahora es compatible y desarrollado;
- parte de HDF de Hortonworks;
- tiene una versión especial de MiNiFi para recopilar datos de dispositivos.
El sistema se parece a esto:
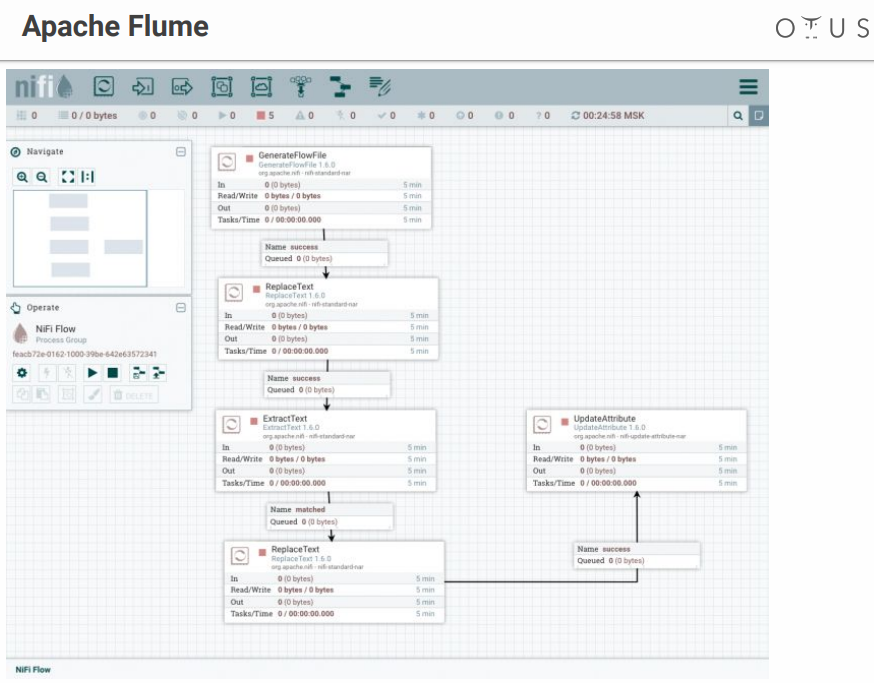
Tenemos un campo de creatividad y etapas de procesamiento de datos que arrojamos allí. Hay muchos conectores para todos los sistemas posibles, etc.
Streamset
También es un sistema de control de flujo de datos con una interfaz visual. Fue desarrollado por personas de Cloudera, se instala fácilmente como Parcel en CDH, tiene una versión especial de SDC Edge para recopilar datos de dispositivos.
Consta de dos componentes:
- SDC: un sistema que realiza el procesamiento directo de datos (gratis);
- StreamSets Control Hub: un centro de control para varios SDC con características adicionales para el desarrollo de líneas de pago (de pago).
Se parece a esto:

Momento desagradable: los StreamSets tienen partes gratuitas y de pago.
Bus de datos
Ahora veamos dónde cargaremos estos datos. Solicitantes:
Apache Kafka es la mejor opción, pero si tiene RabbitMQ o NATS en su empresa, y necesita agregar un poco de análisis, entonces implementar Kafka desde cero no será muy rentable.
En todos los demás casos, Kafka es una gran opción. De hecho, es un agente de mensajes con escala horizontal y gran ancho de banda. Está perfectamente integrado en todo el ecosistema de herramientas para trabajar con datos y puede soportar cargas pesadas. Tiene una interfaz universal y es el sistema circulatorio de nuestro procesamiento de datos.
En el interior, Kafka se divide en Tema: una cierta secuencia de datos separada de los mensajes con el mismo esquema o, al menos, con el mismo propósito.
Para analizar el siguiente matiz, debe recordar que las fuentes de datos pueden variar ligeramente. El formato de datos es muy importante:

El formato de serialización de datos Apache Avro merece una mención especial. El sistema usa JSON para determinar la estructura de datos (esquema) que se serializa en un
formato binario compacto . Por lo tanto, ahorramos una gran cantidad de datos y la serialización / deserialización es más barata.
Todo parece estar bien, pero la presencia de archivos separados con circuitos plantea un problema, ya que necesitamos intercambiar archivos entre diferentes sistemas. Parece que es simple, pero cuando trabajas en diferentes departamentos, los chicos del otro lado pueden cambiar algo y calmarse, y todo se romperá por ti.
Para no transferir todos estos archivos a unidades flash, disquetes y pinturas rupestres, hay un servicio especial: registro de esquemas. Este es un servicio para sincronizar avro-esquemas entre servicios que escriben y leen desde Kafka.

En términos de Kafka, el productor es quien escribe, el consumidor es el que consume (lee) los datos.
Almacén de datos
Retadores (de hecho, hay muchas más opciones, pero solo unas pocas):
- HDFS + Colmena
- Kudu + Impala
- Clickhouse
Antes de elegir un repositorio, recuerde qué
es la idempotencia . Wikipedia dice que la idempotencia (idem en latín - los mismos + potentes - capaces) - la propiedad de un objeto u operación cuando se aplica la operación al objeto nuevamente, da el mismo resultado que el primero. En nuestro caso, el proceso de procesamiento de transmisión debe construirse de modo que al rellenar los datos de origen, el resultado permanezca correcto.
Cómo lograr esto en los sistemas de transmisión:
- Identificar una identificación única (puede ser compuesta)
- use esta identificación para deduplicar datos
El almacenamiento HDFS + Hive
no proporciona idempotencia para la transmisión de grabaciones "fuera de la caja", por lo que tenemos:
Kudu es un repositorio adecuado para consultas analíticas, pero con una clave primaria, para deduplicación.
Impala es la interfaz SQL para este repositorio (y muchos otros).
En cuanto a ClickHouse, esta es una base de datos analítica de Yandex. Su objetivo principal es el análisis en una tabla llena de una gran corriente de datos sin procesar. De las ventajas: hay un motor ReplacingMergeTree para la deduplicación clave (la deduplicación está diseñada para ahorrar espacio y puede dejar duplicados en algunos casos, debe tener en cuenta los
matices ).
Queda por añadir algunas palabras sobre
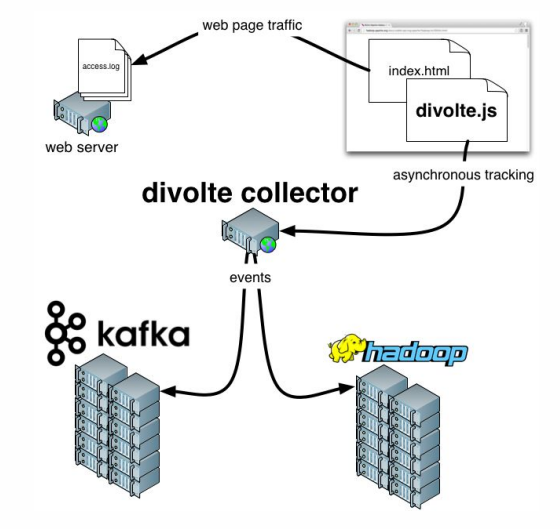
Divolte . Si recuerdas, hablamos sobre el hecho de que algunos datos deben ser capturados. Si necesita organizar de forma rápida y sencilla los análisis para un portal, Divolte es un excelente servicio para capturar eventos de usuarios en una página web a través de JavaScript.
Ejemplo práctico
¿Qué estamos tratando de hacer?
Intentemos crear una tubería para recopilar datos de Clickstream en tiempo real.
Clickstream es una huella virtual que deja un usuario mientras está en su sitio. Capturaremos datos usando Divolte y los escribiremos en Kafka.

Necesita Docker para trabajar, además necesita clonar el
siguiente repositorio . Todo lo que ocurra será lanzado en contenedores. Para ejecutar varios contenedores a la vez, se
usará docker-compose.yml . Además, hay un
Dockerfile que compila nuestros StreamSets con ciertas dependencias.
También hay tres carpetas:
- los datos de clickhouse se escribirán en datos de clickhouse
- exactamente el mismo papá ( datos sdc ) que tendremos para StreamSets, donde el sistema puede almacenar configuraciones
- la tercera carpeta ( ejemplos ) incluye un archivo de solicitud y un archivo de configuración de tubería para StreamSets

Para comenzar, ingrese el siguiente comando:
docker-compose up
Y disfrutamos de lo lento pero seguro que comienzan los contenedores. Después de comenzar, podemos ir a la dirección
http: // localhost: 18630 / e inmediatamente tocar Divolte:

Entonces, tenemos Divolte, que ya recibió algunos eventos y los grabó en Kafka. Intentemos calcularlos usando StreamSets:
http: // localhost: 18630 / (contraseña / inicio de sesión - admin / admin).

Para no sufrir, es mejor
importar Pipeline , nombrándolo, por ejemplo,
clickstream_pipeline . Y de la carpeta de ejemplos importamos
clickstream.json . Si todo está bien,
veremos la siguiente imagen :

Entonces, creamos una conexión con Kafka, registramos qué Kafka necesitamos, registramos qué tema nos interesa, luego seleccionamos los campos que nos interesan, luego pusimos un drenaje en Kafka, registrando qué Kafka y qué tema. Las diferencias son que en un caso, el formato de datos es Avro, y en el segundo es solo JSON.
Sigamos adelante. Podemos, por ejemplo,
hacer una vista previa que capture ciertos registros en tiempo real de Kafka. Luego escribimos todo.
Después del lanzamiento, veremos que una secuencia de eventos vuela a Kafka, y esto sucede en tiempo real:

Ahora puede hacer un repositorio para estos datos en ClickHouse. Para trabajar con ClickHouse, puede usar un cliente nativo simple ejecutando el siguiente comando:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Tenga en cuenta que esta línea indica la red a la que desea conectarse. Y dependiendo de cómo nombre la carpeta con el repositorio, el nombre de su red puede diferir. En general, el comando será el siguiente:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
La lista de redes se puede ver con el comando:
docker network ls
Bueno, no queda nada:
1.
Primero, "firme" nuestro ClickHouse a Kafka , "
explíquele " qué formato tenemos los datos que necesitamos allí:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
Ahora crearemos una tabla real donde pondremos los datos finales:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
Y luego proporcionaremos una relación entre estas dos tablas :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
Y ahora seleccionaremos los campos necesarios :
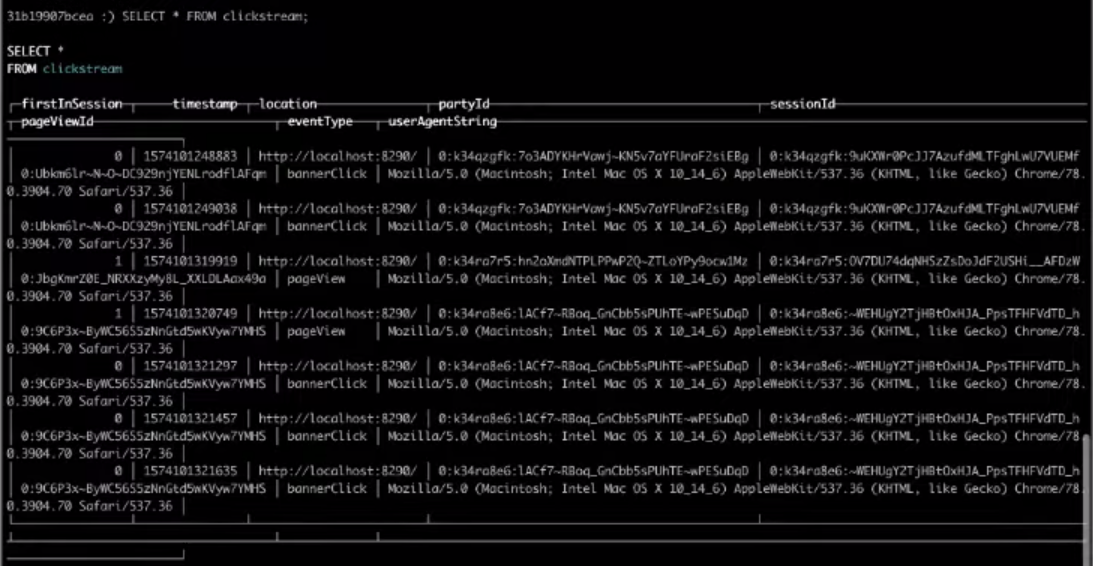
SELECT * FROM clickstream;
Como resultado, la elección de la tabla de destino nos dará el resultado que necesitamos.
Eso es todo, fue el Clickstream más simple que puedes construir. Si desea completar los pasos anteriores usted mismo,
vea el video completo.