
La historia del aprendizaje automático comenzó a mediados del siglo pasado. En ese momento, esta tecnología era más un área de investigación científica y experimentos, y las computadoras poderosas dieron un impulso a la aplicación práctica de ML.
Hoy, el aprendizaje automático es una tendencia innegable en el mercado de TI. Cada vez más empresas de diferentes industrias están creando divisiones de ciencia de datos para utilizar el aprendizaje automático para encontrar nuevas oportunidades en los datos acumulados para el crecimiento y la mejora de la eficiencia empresarial. Sin embargo, si bien estas iniciativas no dan el debido rendimiento. Según las estadísticas, 8 de cada 10 casos confirmados no entran en operación comercial.
Lo más probable es que la mayoría de ustedes hayan escuchado la broma "la forma más efectiva de hacer que el aprendizaje automático sea más productivo son las diapositivas de PowerPoint". Lamentablemente, esto no es una broma. A menudo, todo el proceso tiene este aspecto: una empresa transmite datos y un caso empresarial se descarga de los sistemas empresariales. Los científicos de datos están desarrollando un modelo de aprendizaje automático en el Jupiter Notebook, se coloca una captura de pantalla de los gráficos en una diapositiva de PowerPoint y se envía al cliente comercial. ¿Es posible utilizar la diapositiva resultante para tomar decisiones de gestión? Lo más probable es que no, ya que los datos de pronóstico se vuelven obsoletos rápidamente, y la situación en el negocio durante este tiempo puede cambiar seriamente.
Intentando superar todos los obstáculos y poner el aprendizaje automático en marcha, la mayoría de las empresas invierten en la infraestructura de recopilación, almacenamiento y procesamiento de grandes cantidades de datos: Data Lake. Por supuesto, este es un paso necesario. Pero, ¿qué cambia esto desde una perspectiva empresarial? ¿Es posible tomar decisiones basadas en el aprendizaje automático? No, porque hay una brecha entre Data Lake y las empresas. Obviamente, por qué el 86% de las empresas encuestadas cree que las aplicaciones comerciales de próxima generación deberían estar equipadas con aprendizaje automático.
En SAP decidimos escribir una serie de artículos sobre cómo superar las dificultades existentes con la nueva plataforma SAP Data Intelligence y poner una herramienta tan poderosa como el aprendizaje automático al servicio de las empresas. Y, si estás interesado en este tema, sigue leyendo :)
Para comenzar, le contaré sobre la primera y muy importante etapa en el desarrollo de cualquier caso de negocio "Búsqueda y preparación de datos". En artículos posteriores, consideraremos en detalle las etapas "Desarrollo y capacitación de modelos", "Integración con fuentes de datos in situ y en la nube de SAP y no SAP", "Creación de servicios para usar modelos", "Transferencia de casos de negocio a productivos", "Monitoreo y la operación de casos de negocios ”y mucho más.
Desarrollo de un caso de negocio basado en el aprendizaje automático. Búsqueda y preparación de datos.Veamos el proceso de creación de un caso de negocio (Figura 1).
Inicialmente, una idea generalmente es formulada por una empresa. A menudo, lo hace de buena gana, ya que tiene el objetivo definitivo de digitalizar funciones dentro de la transformación digital de toda la empresa. Para recopilar, evaluar y priorizar ideas, puede utilizar, por ejemplo, SAP Innovation Management.
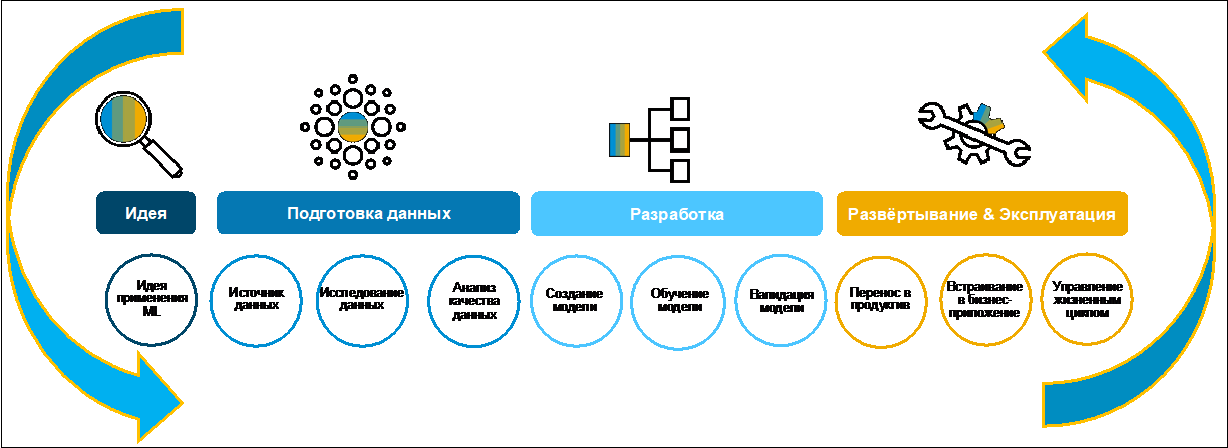 Figura 1
Figura 1En la primera etapa de la búsqueda y preparación de datos, es necesario comprender si existen para el desarrollo de un caso de negocios, dónde se almacenan, en qué formatos y de qué calidad son. El paisaje típico moderno incluye muchos sistemas heterogéneos. Los datos se pueden duplicar en diferentes aplicaciones. Encontrar la información correcta puede llevar mucho tiempo. Para este propósito, en SAP Data Intelligence, esta tarea se ha simplificado enormemente utilizando el Catálogo de Metadatos. Veamos qué es y cómo usarlo.
Catálogo de metadatosPara usar el catálogo de metadatos, debe conectar el sistema de origen a Data Intelligence. Las fuentes de datos para Data Intelligence pueden ser sistemas locales SAP ERP, BW, Marketing ... y no SAP MES, Oracle, MS SQL, DB2, Hadoop y muchos otros, así como servicios en la nube Amazon, Azzure, Google SCP. Para conectarse a las fuentes de datos, necesita información sobre la ubicación de los sistemas y usuarios técnicos creados en estos sistemas específicamente para la integración con SAP Data Intelligence. La Figura 2 muestra un ejemplo de un panorama de datos personalizado en SAP Data Intelligence.
 Figura 2
Figura 2
Una vez configurado en el Catálogo de Metadatos de SAP Data Intelligence, es posible ver la información almacenada en los sistemas conectados. La Figura 3 muestra la lista de archivos que se encuentran en la carpeta DAT263 en Hadoop conectado a SAP Data Intelligence.
 Figura 3
Figura 3Si encuentra los datos necesarios para implementar un caso de negocio, agreguemos objetos de datos al Catálogo mediante la función de publicación. Usaré el archivo autos_history.csv, que contiene estadísticas de ventas de autos usados. En la Figura 4, verá cómo puede publicar un objeto de datos y sus metadatos en el Catálogo para un acceso rápido en el futuro.
 Figura 4
Figura 4Puede personalizar la estructura del directorio, los niveles de jerarquía de acuerdo con los requisitos de su caso de negocio. Por ejemplo, en mi carpeta Habr_demo, se recopilarán todos los metadatos sobre los objetos que necesito para este artículo.
El catálogo de metadatos generado es un acceso rápido a los datos de casos de negocios. Realizaré perfiles y análisis de su calidad en los objetos de mi carpeta en el Catálogo de Metadatos de SAP Data Intelligence. La pantalla inicial del catálogo de metadatos se muestra en la Fig. 5)
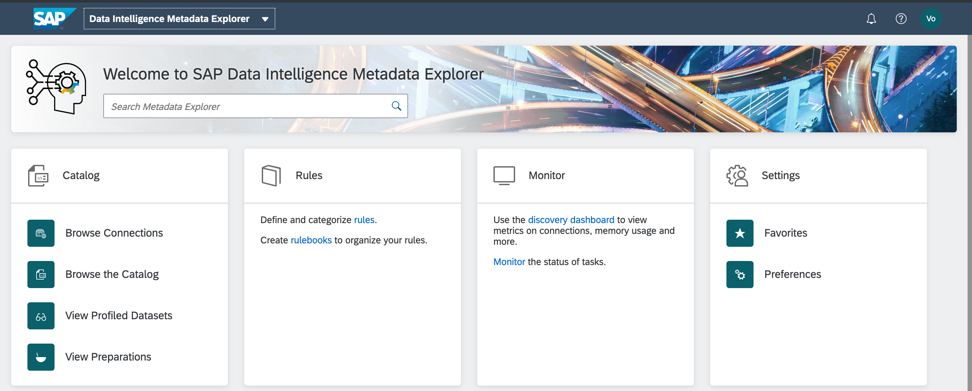 Figura 5
Figura 5Y aquí está el objeto de datos que publiqué en la carpeta Habr_demo (Fig. 6)
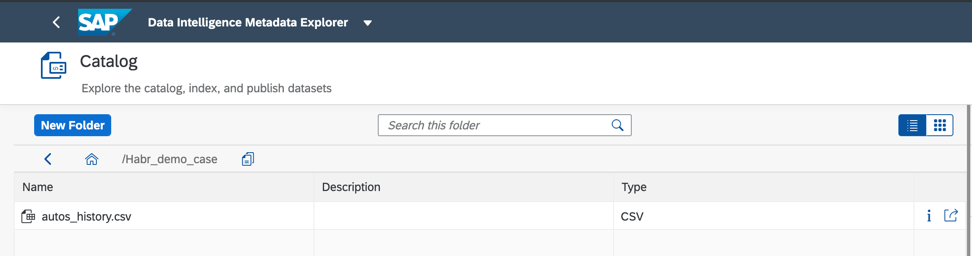 Figura 6
Figura 6Además, para mejorar y acelerar la búsqueda, podemos asignar etiquetas o etiquetas en el catálogo de objetos de datos, como se muestra en la Fig. 7)
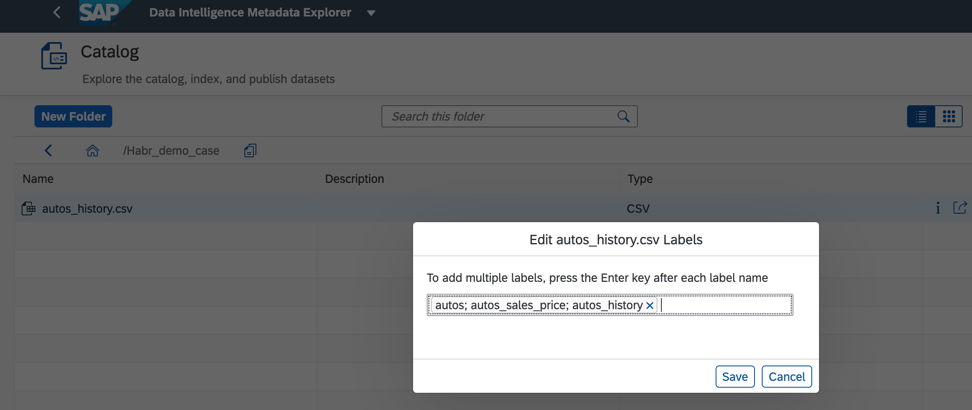 Figura 7
Figura 7El catálogo de metadatos le permite buscar objetos por sus nombres, campos y etiquetas. Un solo objeto de datos puede tener múltiples etiquetas. Esto es conveniente si varios desarrolladores trabajan con él, todos pueden asignar una etiqueta a su caso de negocio y encontrar rápidamente todo lo que necesita de él. Además, las etiquetas pueden resaltar datos personales y confidenciales, cuyo acceso debe estar estrictamente limitado.
En el conjunto de datos considerado, una búsqueda por etiqueta y por nombre de campo da un resultado rápido (Fig. 8). De acuerdo, es muy conveniente!
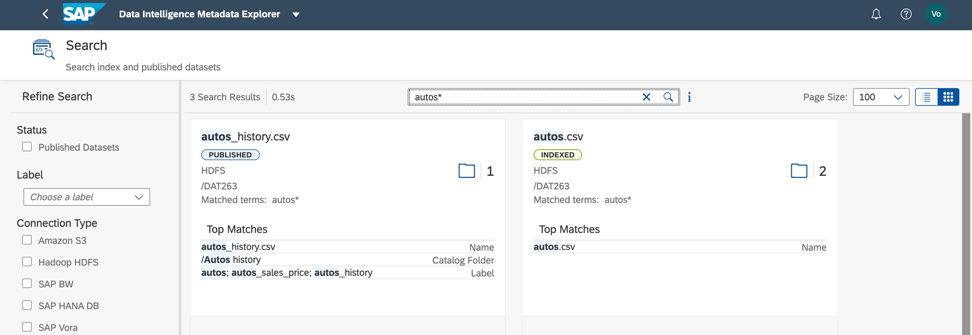 Figura 8
Figura 8A continuación, debemos entender cómo se llena nuestro archivo. Para hacer esto, podemos perfilar los datos. También comenzamos el proceso desde el catálogo de metadatos y el menú contextual para objetos de datos (Fig. 9).
 Figura 9
Figura 9Durante la creación de perfiles, el catálogo de metadatos leerá el contenido del archivo, analizará su estructura y relleno. El resultado se puede encontrar en la hoja informativa (Fig. 10).
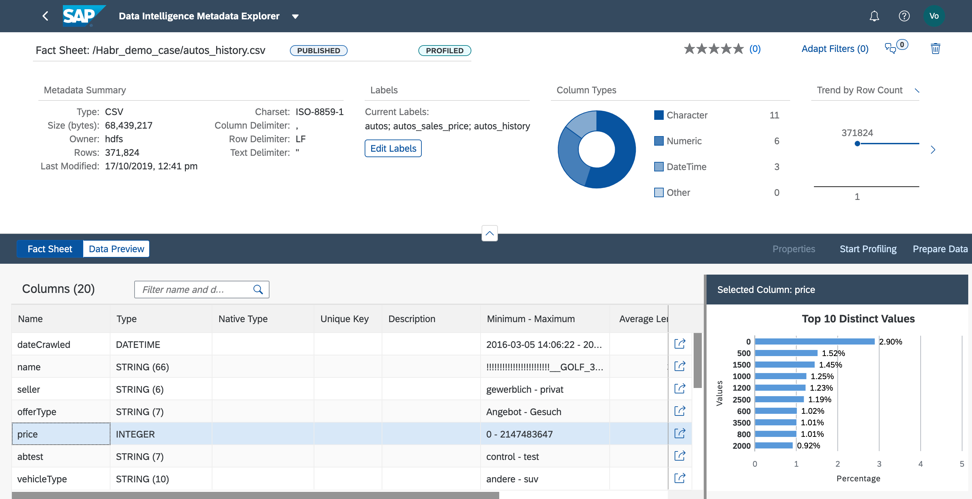 Figura 10
Figura 10
En la hoja informativa, vemos la estructura del archivo y la información sobre cómo completar los campos.
1. En el archivo seleccionado, como resultado de la creación de perfiles, revelamos: el campo del vendedor tiene un valor I en todas las líneas. Esto significa que podemos eliminar este campo del conjunto de datos para no utilizar el aprendizaje automático al construir el modelo, ya que no afectará el resultado del pronóstico (Fig. 11).
 Figura 112.
Figura 112. Analizando la columna de precios, entendemos que casi el 3% de los datos que tenemos contiene precio cero. Para utilizar este archivo en nuestro caso de negocios, debemos completar el precio con los valores reales o el promedio de este producto, o debemos eliminar las líneas con precio cero del archivo (Fig. 12).
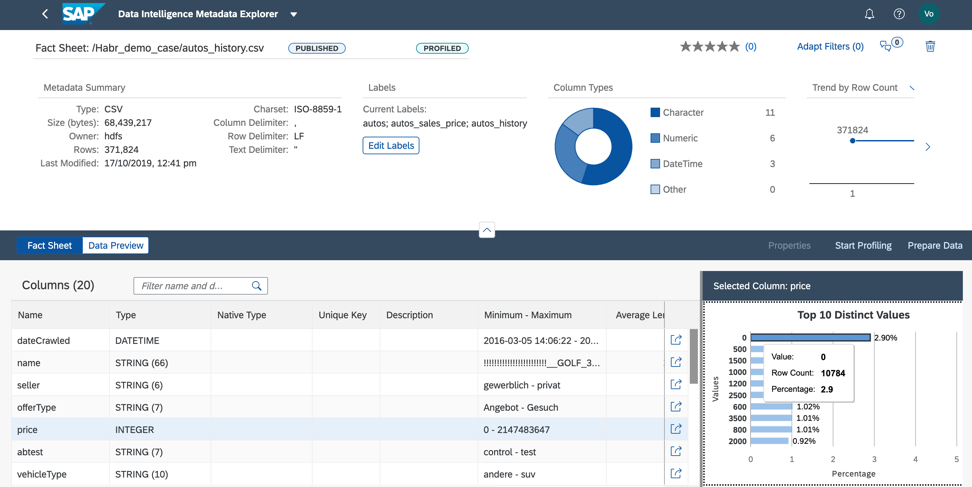 Figura 12
Figura 12Podemos hacer el preprocesamiento de datos de dos maneras: en el Catálogo de metadatos o directamente en el Jupiter Notebook. La elección de la herramienta depende de quién es responsable del preprocesamiento de los datos para el caso de negocio. Si es analista, le recomiendo usar la interfaz de preparación de datos visuales, que está disponible en el Catálogo de metadatos. Si un científico de datos está involucrado en la preparación de los datos, entonces la elección definitivamente debería estar a favor del cuaderno de Júpiter, que también está integrado en Data Intelligence.
3. El valor del campo modelo está bien distribuido, lo que nos permitirá capacitar cualitativamente el modelo, como en la Figura 13.
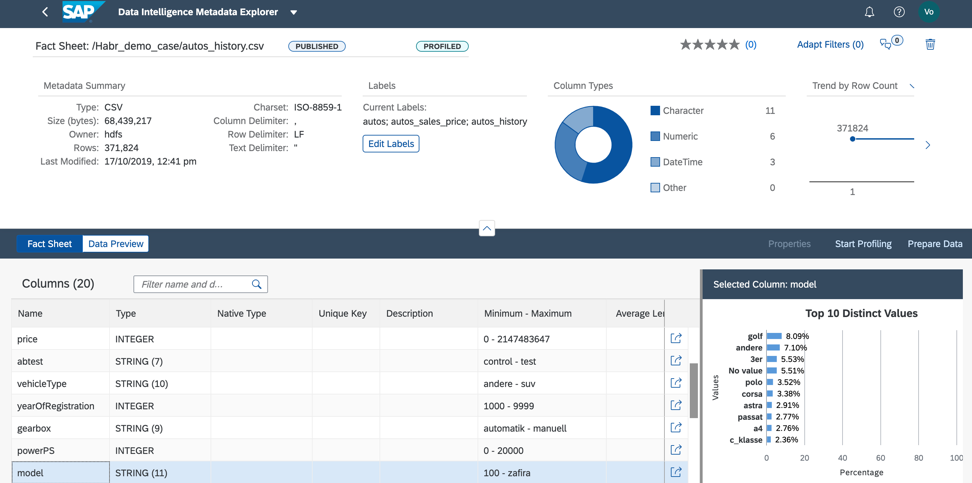 Figura 13
Figura 13
Ahora entendemos qué objetos de datos se requieren para implementar un caso de negocios, qué objetos de datos se completan, qué preprocesamiento debemos hacer para usar estos datos para implementar, capacitar y probar el modelo. Pero antes de comenzar el preprocesamiento, debe verificar la calidad de los datos. Para hacer esto, las reglas de negocio están disponibles en el Catálogo de Metadatos. Noto de inmediato que, en este momento, la funcionalidad de las reglas comerciales tiene una serie de limitaciones serias. Por lo tanto, recomiendo un preprocesamiento de datos más o menos complicado en el Jupiter Notebook, que está integrado en SAP Data Intelligence.
Entonces, volvamos a nuestro conjunto de datos y verifiquemos el cumplimiento de los umbrales mínimo y máximo en el campo de precios, para que podamos estimar aproximadamente si los datos tienen anomalías o valores incorrectos. Como ya entendió, las reglas de negocio también se configuran en el Catálogo de Metadatos, como en la Fig. 14a, c. La relación de reglas y datos se configura en el libro de reglas (Rulebook). Esto le permite usar las mismas reglas para verificar datos diferentes.
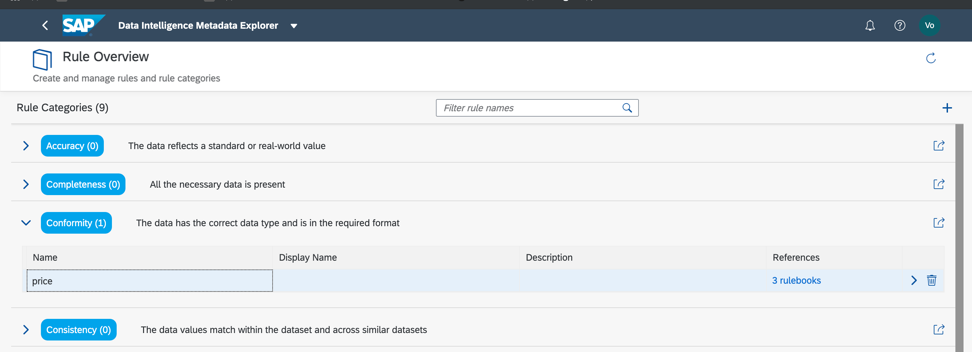 Figura 14 a.
Figura 14 a.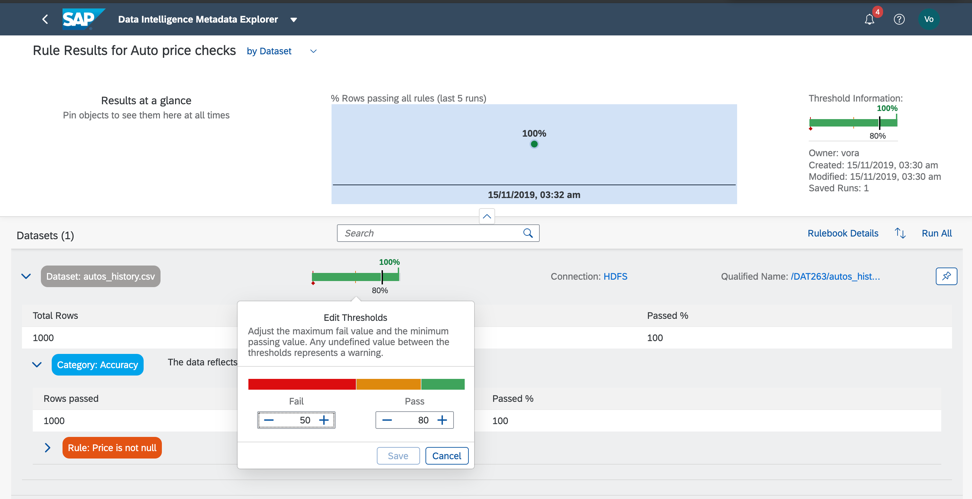 Figura 14 c.
Figura 14 c.Entonces, como vemos, nuestros datos son 100% correctos.
Pero esto no siempre sucede. Los datos pueden considerarse correctos si el 75% de los registros cumplen con las condiciones especificadas en las reglas.
Es posible mejorar la calidad de los datos y, sobre todo, esto se hace en los sistemas de contabilidad. Para hacer esto, las empresas organizan el proceso de gestión de datos. Otra posible razón son los criterios de calidad de datos definidos incorrectamente.
En resumen, quiero decir sobre las ventajas y desventajas del Catálogo de Metadatos.
En mi opinión, tiene 3 ventajas principales:
- Simplifica el acceso a los datos.
- Acelerando la recuperación de datos.
- Interfaz conveniente e intuitiva, que está diseñada no solo para profesionales avanzados en TI o Data Science, sino también para el negocio involucrado en la implementación y el soporte adicional del caso de negocios.
Y, por supuesto, sobre los defectos. Son obvios. Actualmente, la funcionalidad del Catálogo de metadatos en SAP Data Intelligence está en un nivel básico. Puede ser suficiente comenzar a usar, pero la funcionalidad no cubre exactamente todos los requisitos para una solución de gestión de datos.
Y esto es una consecuencia de la novedad y complejidad de SAP Data Intelligence. SAP invierte muchos recursos para mejorar esta solución. Y esto inspira confianza en que en el futuro cercano el Catálogo de Metadatos se convertirá en una herramienta poderosa para la gestión de datos. Habrá una oportunidad para crear reglas comerciales complejas sin programación. También será posible integrar el administrador de información de SAP y el centro de datos de SAP con el fin de una cobertura totalmente funcional del tema de la gestión de datos.
En el próximo artículo, hablaremos sobre la fase "Desarrollo y capacitación de un modelo en SAP Data Intelligence". Todo lo más interesante por delante!
Publicado por Elena Ganchenko, experta en SAP CIS