Probablemente, en todas las ciudades de Bielorrusia donde hay trolebuses, hay grupos VK o chats en Telegram en los que las personas rastrean la ubicación de los controladores. Esto se hace principalmente para no pagar los viajes y viajar gratis, aunque la descripción de los grupos casi siempre contiene la posdata "Pagar por viajar".
En VC, generalmente se ve así:
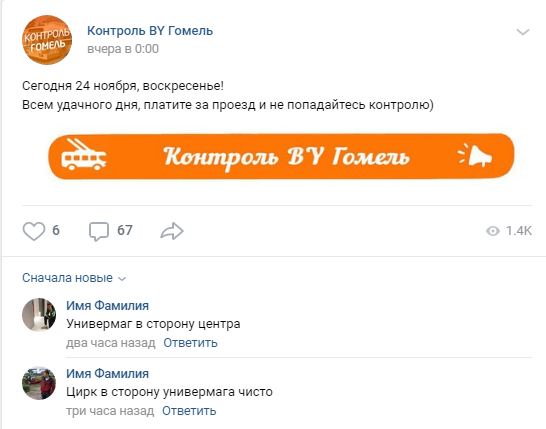
Un comentario típico se ve así:
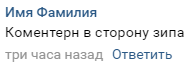
La estructura es extremadamente simple. En el comentario hay nombres de la parada donde se notó actualmente a los controladores, también está la dirección en la que se encuentran:
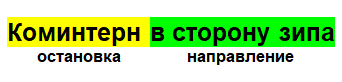
El comentario, como resultado, es un objeto con una parada, hora y fecha, así como una identificación única por la cual podemos identificarlo. Con esto, puede calcular la ubicación más probable de dónde están los controladores ahora.
Preparación
Primero debe determinar el público objetivo, desde el cual analizaremos los datos. El grupo debe tener mucha actividad en los comentarios, de lo contrario corremos el riesgo de obtener muy poca información
En mi caso, este es el grupo "Control Gomel".
Analizaremos los comentarios utilizando la API oficial de VKontakte para Python
Nos autenticamos con la clave de acceso del usuario, ya que algunos grupos pueden estar cerrados, y el acceso a sus comentarios solo se puede obtener si usted fue aceptado en el grupo.
Después de eso, puede comenzar a extraer comentarios:
Recibir comentarios
Para comenzar, obtenemos la última publicación disponible en el grupo para extraer comentarios a través de vk.wall.getComments e inicializar el DataFrame, en el que guardaremos los datos.
Cada publicación de comentarios tiene la inscripción "Que tengas un buen día, paga la tarifa y no caigas bajo control", así que descarga los comentarios, verifica el contenido de la publicación y obtén una variedad de comentarios de los que puedes tomar datos.
Tomé comentarios de publicaciones en los últimos 3 meses, dado que 1 publicación se publica todos los días (ahora a fines de noviembre, el año escolar comienza en septiembre, y los supervisores probablemente tengan esto en cuenta y cambien sus lugares normales). En principio, se pueden tener en cuenta otros signos, como, por ejemplo, la época del año.
Algunos de los comentarios están obstruidos con mensajes como "¿Hay alguien en Barykin?" Si observa tales comentarios (innecesarios), puede resaltar algunos signos:
- El texto contiene las palabras "limpio", "izquierda", "nadie" y similares
- Las palabras "dime", "quién", "qué", "cómo"
- Símbolos, como emoticones, por ejemplo
Después de eso, revisamos una serie de comentarios y extraemos una identificación única, texto, hora, fecha y día de la semana, que colocamos en el DataFrame ya creado.
Recibir comentariosimport re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
Por lo tanto, recibimos un DataFrame con el texto de los comentarios, su identificación, día de la semana, hora y minuto en que se escribió el comentario. Solo necesitamos el día de la semana, la hora de escritura y el texto. Se parece a esto:
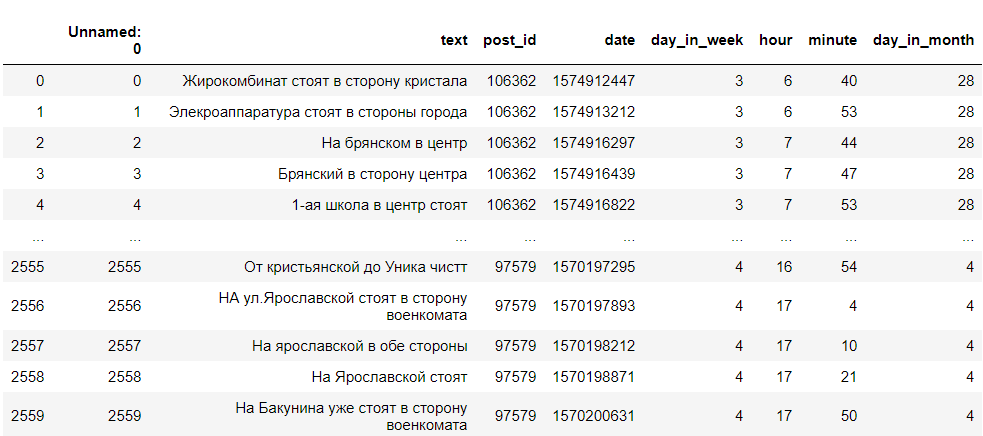
Limpieza de datos
Ahora necesitamos borrar los datos. Es necesario eliminar la dirección del comentario para cometer menos errores al buscar la distancia de Levenshtein. Encontramos las expresiones "a un lado", "ir", "cómo", "cerca", ya que generalmente van seguidas del nombre de la segunda parada, y las eliminamos junto con lo que viene después de ellas, así como reemplazamos algunos nombres de jerga de las paradas con las habituales. .
Borrar datos from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
Convertir usando la distancia de Levenshtein
Procedemos directamente a la distancia de Levenshane. Un poco de ayuda: la distancia de Levenshtein: el número mínimo de operaciones para insertar un carácter, eliminar un carácter y reemplazar un carácter con otro, necesario para convertir una línea en otra.
Lo encontraremos usando la biblioteca
fuzzywuzzy . Le ayuda a calcular rápida y fácilmente la distancia de Levenshtein. Para acelerar el trabajo, los autores de la biblioteca también recomiendan instalar la biblioteca python-Levenshtein.
Para obtener paradas de los comentarios, necesitamos una lista de paradas. Me lo brindó amablemente el desarrollador de la aplicación GoTrans, Alexander Kozlov.
La lista tuvo que ampliarse, agregando algunas paradas que no estaban allí, y cambiando parte de los nombres para que estuvieran mejor ubicados.
Paradasparadas = ['supermercado', 'prado', 'remybtekhnika', 'Leningrado', 'Yaroslavl', 'Polesskaya',
'Yaroslavl', 'timofeenko', '8 de marzo',
«Casa comercial Rechitsky», «Avenida Rechitsky», «circo», «grandes almacenes», «Chongarskaya»,
'chongarka', 'ggu', 'skorina', 'university', 'appliance', '1000 little things', 'maya', 'station',
'parque de posgrado', 'comercio y economía', 'aniversario', 'microdistrito 18', 'aeropuerto', 'próximo',
'gomelgeodezcentr', 'crystal', 'lake lyubenskoye', 'mercado davydovsky', 'davydovka',
'river sozh', 'gomeldrev',
'Sevruki', 'gmu No. 1', 'etc. Rechitsky', 'disfraz', 'hospital de enfermedades infecciosas', 'campamento de gaviotas',
Volotova, Coral, Gomeltorgmash, Gomelproekt, Vneshgomelstroy, Periódico,
'Kalenikova', 'Eremino', 'destilería', 'automatización industrial especial', '2nd School', 'Barykina',
'unidades de máquina', 'juventud', 'cuerpo de casting', 'químicos', 'golovatsky', 'budenny',
'spu67', '35th', 'gagarin', '50 años para la planta de Gomselmash ',' hill ',' fábrica de radio ',
'abuela', 'cristalería', 'castaño', 'motores de arranque', 'astronautas',
'rtsrm initial', 'bykhovskaya', 'instituto del ministerio de situaciones de emergencia', 'dk gomselmash', 'store', 'rechitsky',
'Sevruks', 'Osovtsy', 'turista', 'fábrica de carne', 'Santísima Trinidad', 'ciudad médica', 'octubre',
'depósito de petróleo', 'gomelloblavtotrans', 'milkavita', 'bakunin', 'zip', 'oma', 'resina',
'construction market ksk', 'road builder', 'field', 'kamenetskaya', 'bolshevik', 'jakubovka',
'Borodina', 'hipermercado hipopótamo', 'héroes subterráneos', '9 de mayo', 'castaño', 'protésico',
'estación iput', 'internacional comunista', 'universidad pedagógica musical', 'empresa agrícola', 'desvío', 'victoria',
'western', 'pearl', 'Vladimir', 'dry', 'dispensary', 'Ivanova',
'construcción de máquinas', 'abedules', '60 años', 'ingeniero de potencia', 'centrolita',
'clínica oncológica', 'campo de tiro', 'golovintsy', 'coral', 'sur', 'primavera',
Efremova, Border, Belgut, Gomelstroy, Borisenko, Athletics Palace,
'Michurinsky', 'solar', 'gastello', 'militar', 'centro de automóviles', 'fontanería', 'uza',
'facultad de medicina', 'jardín de infantes 11', 'bolchevique', 'cachorros', 'Davydovsky', 'océano', 'progreso',
'Dobrushskaya', 'blanco', 'GSK', 'davydovka', 'equipo eléctrico', 'amistad',
'70 años ',' reparación de automóviles ',' colina sueca ',' circuito ',' canal de agua ',' máquina gomel ',
Volotova, Pioneer, RCM, Khimtorg, 2nd Meadow Lane, Bochkina, Baños,
'clínica oncológica', 'plaza', 'Lenin', 'primera escuela', 'tienda sur',
'gomelagrotrans', 'millers', 'lyubensky', 'oficina de alistamiento militar', 'hospital', 'uza', 'rtsrm',
'lysyukovyh', 'shop iput', 'raton', 'gasolinera', 'randovsky', 'farmhouse', 'castaño', 'ropovsky',
'Romanovichi', 'Ilyich', 'remo', 'empresa de construcción', 'infeccioso',
'fábrica gorda', 'servicio de automóviles', 'servicio agrícola', 'adhesivo', 'Nikolskaya',
'cosechadoras autopropulsadas', 'albañiles', 'materiales de construcción', 'maquinaria de reparación', 'administración',
'Octubre', 'cuento de hadas del bosque', 'Tatiana', 'Boris Tsarikov', 'Zharkovsky', 'Zaitseva',
«reubicación», «Karpovich», «planta de construcción de viviendas», «transporte eléctrico urbano», «zlin»,
«estadio gomselmash», «ap 6», «accionamiento hidráulico», «depósito de locomotoras», «mercado de automóviles osovtsy»,
'nueva vida', 'Zhukova', 'unidad militar', 'tercera escuela', 'bosque', 'faro rojo',
'regional', 'Davydovskaya', 'Karbysheva', 'satélite del mundo', 'juventud', 'locomotora de estadio',
'solar', 'Ladaservice', 'μR 21', 'Aresa', 'internacionalistas', 'Kosareva',
'Bogdanova', 'Hormigón de hierro Gomel', 'μr 20a', 'μr Rechitsky', 'equipamiento médico', 'Juraeva',
'college of art crafts', 'ice', 'dk festival', 'shopping center',
'Kuibyshevsky', 'festival', 'garage koop 27', 'ingeniería sísmica', 'milcha', 'hospital de tubos',
'ptu179', 'productos químicos', 'departamento de bomberos', 'hospital', 'estación de autobuses',
'complejo de periódicos', 'victoria', 'klenkovsky', 'diamante', 'reparación del motor', 'mkr 19']
Usando .map y fuzzywuzzy.process.extractOne, encontramos la parada con la distancia mínima de Levenshtein en la lista, después de lo cual reemplazamos el texto del comentario con el nombre de la parada, lo que nos permite obtener un conjunto de datos con los nombres de las paradas.
El conjunto de datos resultante se parece a esto:
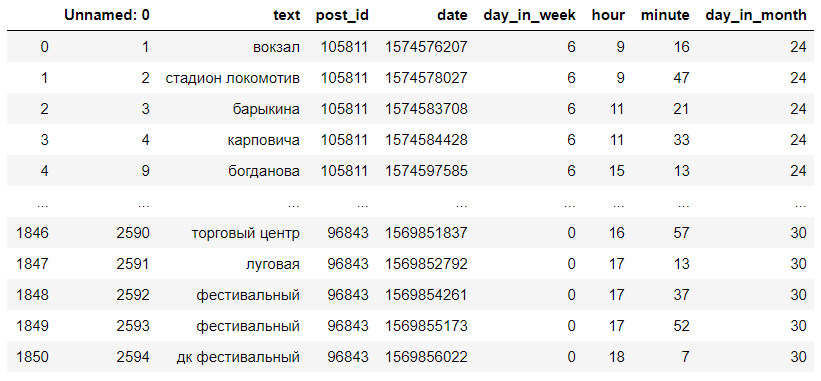
Los comentarios se transforman en paradas def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
Salida de datos
Ahora podemos suponer dónde estarán los controladores en la hora dada.
Estamos buscando en los registros de datos resultantes para una hora y un día específicos de la semana. Por ejemplo, el martes a las 9 am:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
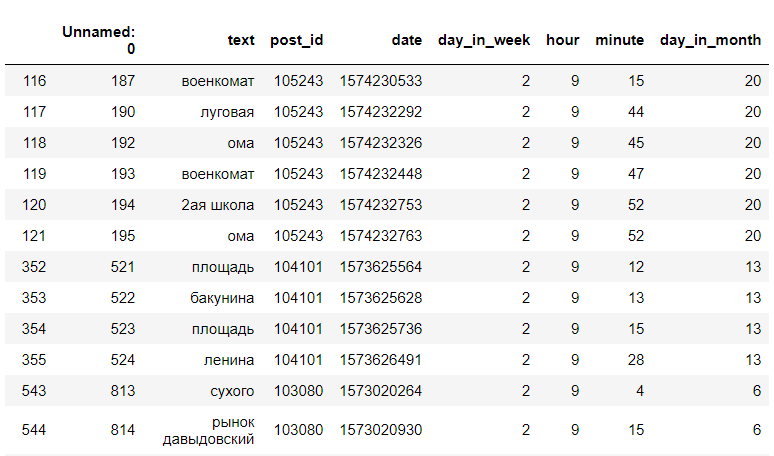 (esto no es toda la información)
(esto no es toda la información)Después de eso, encontramos el número de paradas únicas, y mostramos solo las paradas, y su número:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

Ahora podemos decir que a las 9 en punto de la mañana, los martes, los controladores probablemente serán notados en las paradas de la Planta de Procesamiento de Carne, ul. Lugovaya, BelGUT, TD "Oma".
El principal defecto de este método es la falta de datos. No para todos los días y horas hay entradas en los comentarios dados durante la hora pico, cuando las personas usan el transporte público más que los datos en horas menos populares, pero si agrega datos, por ejemplo, no solo de los comentarios de un grupo, sino también de grupos alternativos, o chats de telegramas, con el número de entradas, todo será más fácil.
Bot con VK LongPoll API
Para dar la oportunidad de recibir datos sobre la ubicación de los controladores, dependiendo de la hora, y sin estar atado a una computadora, hice un bot para un grupo en VKontakte que responde a cualquier mensaje enviando el número de paradas en los registros, dada la hora y el día actual de la semana.
Código bot from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
Conclusión
La calidad de tales hipótesis ha sido probada por mí más de una vez en la práctica, y todo funciona bien. Resultó que los controladores, básicamente, están en las mismas paradas, aunque no se pueden dar pronósticos absolutamente correctos, y la probabilidad de éxito no es del 100%. La distancia de Levenshtein tiene docenas de aplicaciones diferentes, desde corregir errores en una palabra, hasta comparar genes, cromosomas y proteínas, pero también tiene potencial en tales problemas aplicados.
Que tenga un buen día y pague la tarifa.
Todos los códigos de bot y manipulaciones de datos se publican
aquí .