Hola a todos, mi nombre es Alexander, trabajo como ingeniero en CIAN y me dedico a la administración de sistemas y la automatización de procesos de infraestructura. En los comentarios a uno de los artículos anteriores, se nos pidió que dijéramos dónde obtenemos 4 TB de registros por día y qué hacemos con ellos. Sí, tenemos muchos registros y se ha creado un clúster de infraestructura separado para procesarlos, lo que nos permite resolver problemas rápidamente. En este artículo, hablaré sobre cómo lo adaptamos durante el año para trabajar con un flujo de datos cada vez mayor.
Por donde empezamos
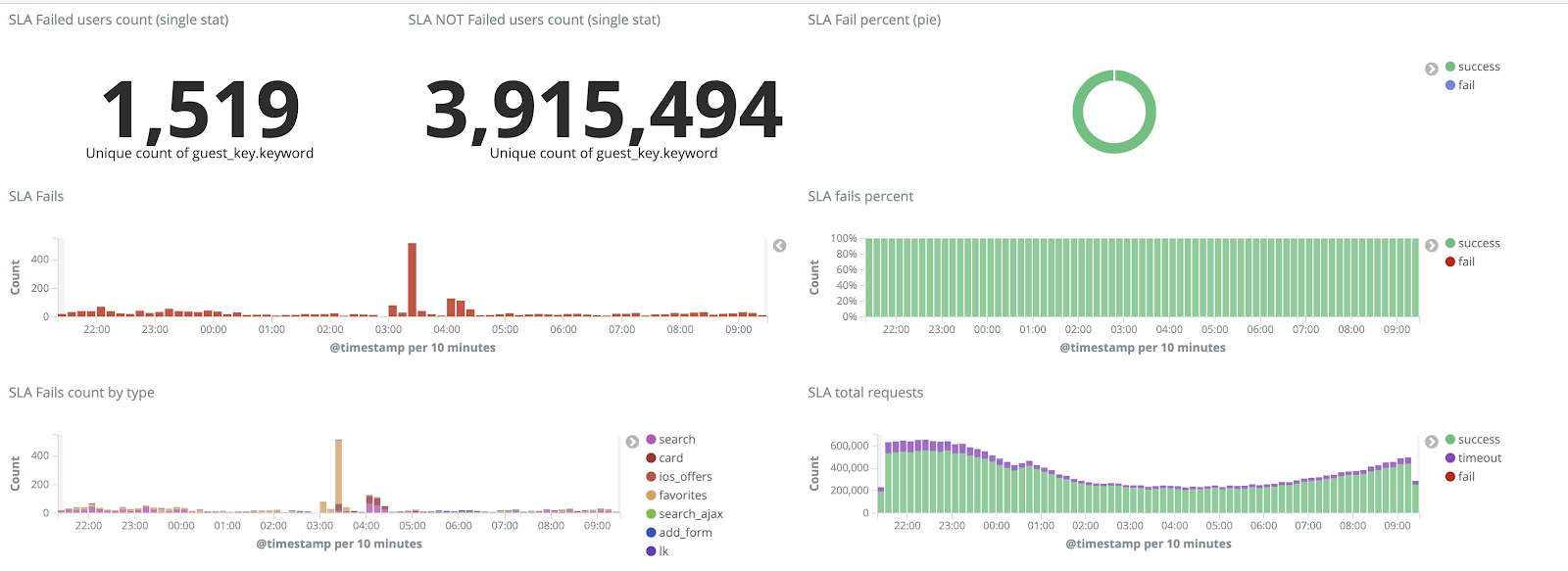
En los últimos años, la carga en cian.ru ha crecido muy rápidamente, y para el tercer trimestre de 2018, el tráfico de recursos alcanzó los 11,2 millones de usuarios únicos por mes. En ese momento, en momentos críticos, perdimos hasta el 40% de los registros, por lo que no pudimos lidiar rápidamente con los incidentes y dedicamos mucho tiempo y esfuerzo a resolverlos. A menudo no pudimos encontrar la causa del problema, y se repitió después de un tiempo. Fue un infierno con el que tenías que hacer algo.
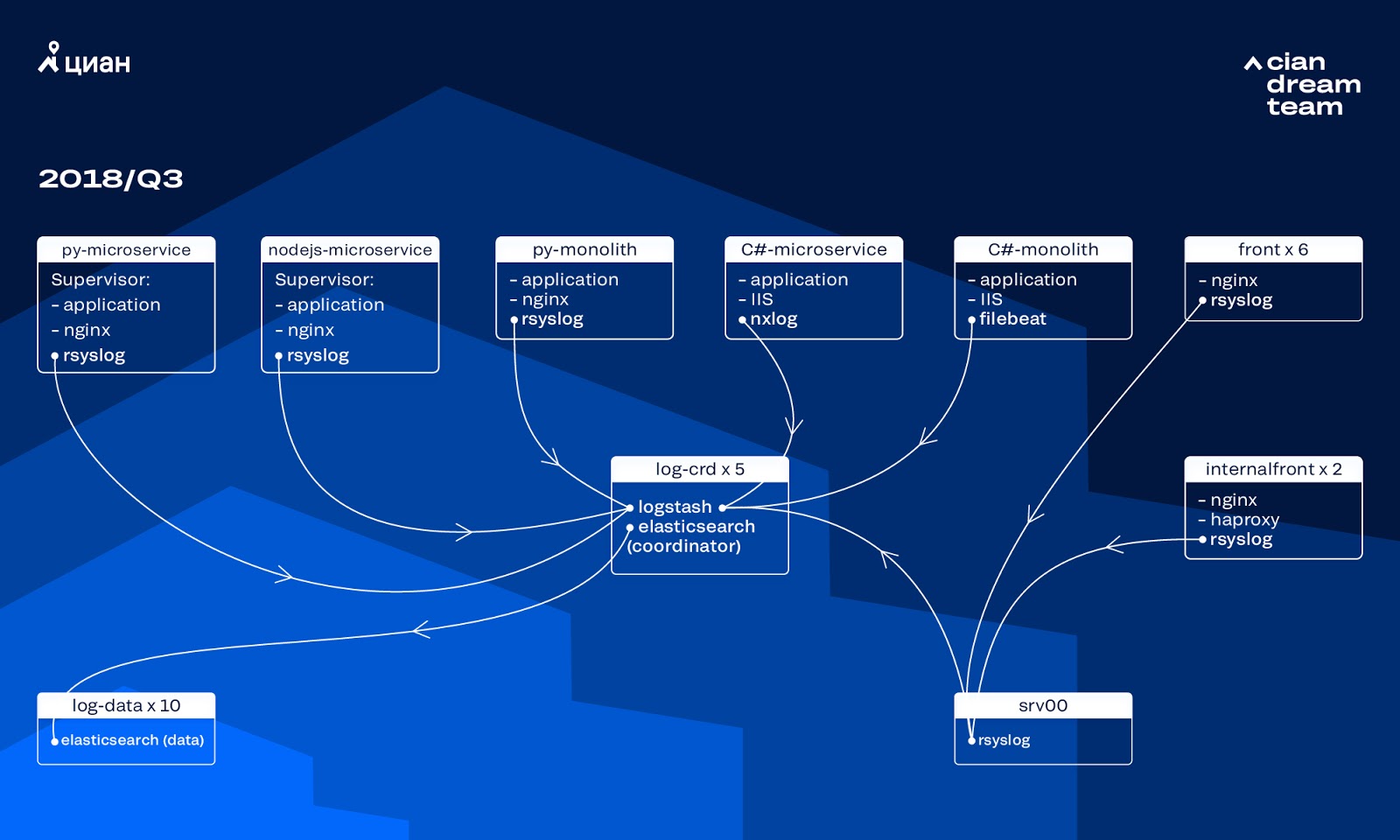
En ese momento, utilizamos un clúster de 10 nodos de datos con ElasticSearch versión 5.5.2 con configuraciones de índice típicas para almacenar registros. Se introdujo hace más de un año como una solución popular y asequible: la secuencia de registro no era tan grande, no tenía sentido crear configuraciones no estándar.
Logstash en diferentes puertos proporcionó el procesamiento de registros entrantes en cinco coordinadores de ElasticSearch. Un índice, independientemente del tamaño, constaba de cinco fragmentos. Se organizó la rotación horaria y diaria, como resultado, aparecieron alrededor de 100 fragmentos nuevos en el grupo cada hora. Si bien no había muchos registros, el clúster se las arregló y nadie llamó la atención sobre su configuración.
Problemas de crecimiento
El volumen de los registros generados creció muy rápidamente, ya que dos procesos se superponían entre sí. Por un lado, había cada vez más usuarios del servicio. Por otro lado, comenzamos a cambiar activamente a la arquitectura de microservicios, aserrando nuestros viejos monolitos en C # y Python. Varias docenas de microservicios nuevos que reemplazaron partes del monolito generaron significativamente más registros para el cluster de infraestructura.
Fue la escala lo que nos llevó al hecho de que el clúster se volvió prácticamente incontrolable. Cuando los registros comenzaron a llegar a una velocidad de 20 mil mensajes por segundo, la rotación inútil frecuente aumentó el número de fragmentos a 6 mil, y un nodo representó más de 600 fragmentos.
Esto condujo a problemas con la asignación de RAM, y cuando un nodo cayó, comenzó un movimiento simultáneo de todos los fragmentos, multiplicando el tráfico y cargando los nodos restantes, lo que hizo casi imposible escribir datos en el clúster. Y durante este período nos quedamos sin registros. Y con un problema de servidor, perdimos 1/10 del clúster en principio. Una gran cantidad de pequeños índices añadieron complejidad.
Sin registros, no entendíamos las causas del incidente y tarde o temprano podríamos volver a pisar el mismo rastrillo, pero en la ideología de nuestro equipo esto era inaceptable, ya que todos los mecanismos de trabajo que teníamos se agudizaron exactamente al contrario, nunca repitan los mismos problemas. Para hacer esto, necesitábamos un volumen completo de registros y su entrega casi en tiempo real, ya que un equipo de ingenieros de servicio monitoreó las alertas no solo de las métricas, sino también de los registros. Para comprender el alcance del problema, en ese momento el volumen total de registros era de aproximadamente 2 TB por día.
Fijamos un objetivo: eliminar por completo la pérdida de registros y reducir el tiempo de entrega al clúster ELK a un máximo de 15 minutos durante la fuerza mayor (confiamos en esta cifra en el futuro como un KPI interno).
Nuevo mecanismo de rotación y nodos calientes-calientes
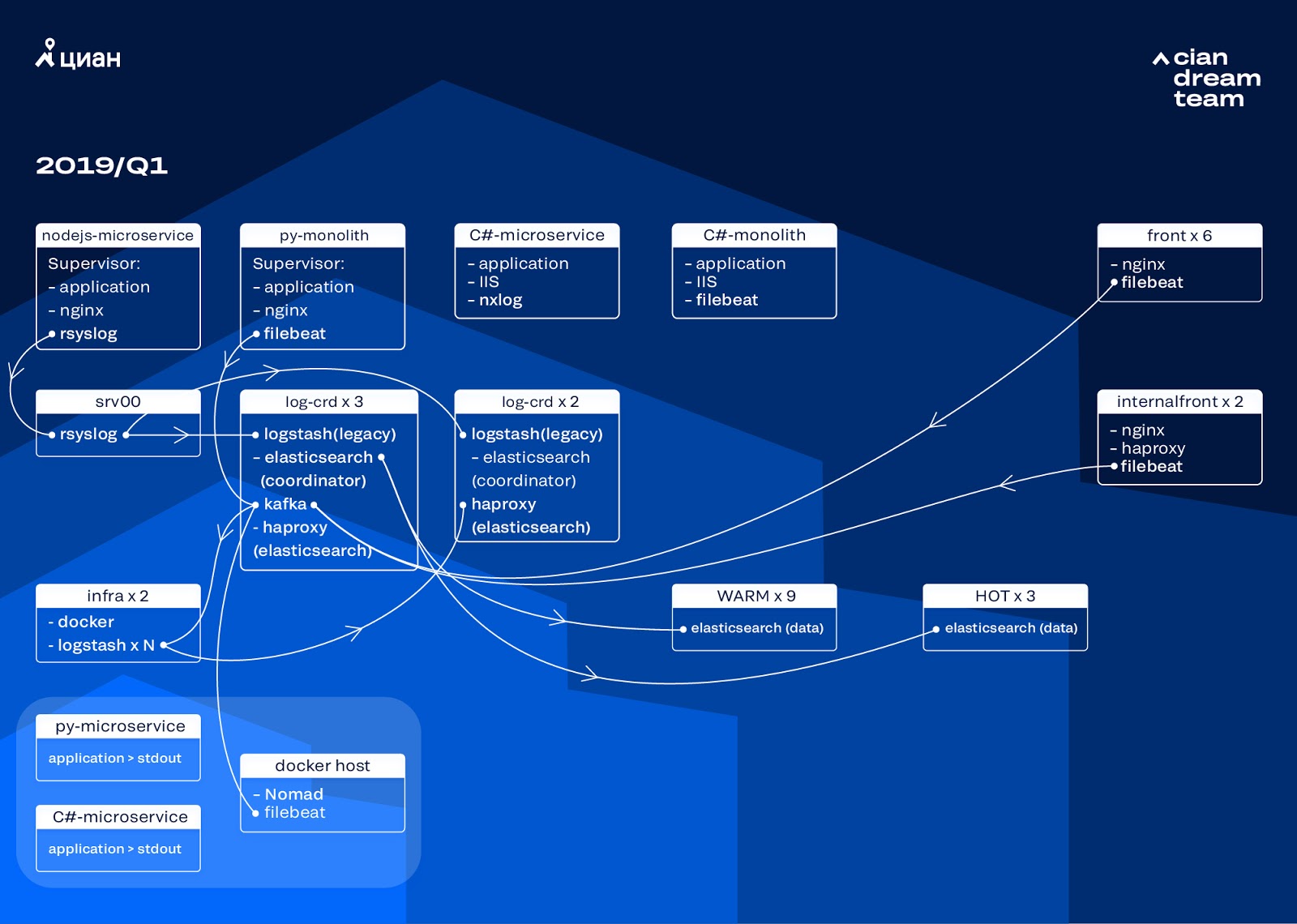
Comenzamos la transformación del clúster actualizando la versión de ElasticSearch de 5.5.2 a 6.4.3. Una vez más, nos llegó un clúster de la versión 5, y decidimos pagarlo y actualizarlo por completo, todavía no hay registros. Así que hicimos esta transición en solo un par de horas.
La transformación más ambiciosa en esta etapa fue la introducción de tres nodos con el coordinador como un buffer intermedio Apache Kafka. El intermediario de mensajes nos salvó de perder registros durante problemas con ElasticSearch. Al mismo tiempo, agregamos 2 nodos al clúster y cambiamos a una arquitectura caliente-caliente con tres nodos "calientes" dispuestos en diferentes bastidores en el centro de datos. Redirigimos los registros a ellos que no deberían perderse en ningún caso, nginx, así como los registros de errores de la aplicación. Registros menores: depuración, advertencia, etc., fueron a otros nodos y también, después de 24 horas, los registros "importantes" se trasladaron desde los nodos "activos".
Para no aumentar el número de índices pequeños, cambiamos de rotación de tiempo al mecanismo de reinversión. Hubo mucha información en los foros de que la rotación por tamaño de índice no es muy confiable, por lo que decidimos usar la rotación por la cantidad de documentos en el índice. Analizamos cada índice y registramos el número de documentos después de los cuales la rotación debería funcionar. Por lo tanto, hemos alcanzado el tamaño óptimo del fragmento: no más de 50 GB.
Optimización de clúster
Sin embargo, no eliminamos por completo los problemas. Desafortunadamente, los índices pequeños aparecieron de todos modos: no alcanzaron el volumen establecido, no giraron y se eliminaron mediante la limpieza global de los índices anteriores a tres días, ya que eliminamos la rotación por fecha. Esto condujo a la pérdida de datos debido al hecho de que el índice del clúster desapareció por completo, y un intento de escribir en un índice inexistente rompió la lógica del curador que utilizamos para el control. El alias para la grabación se transformó en un índice y rompió la lógica del rollover, causando un crecimiento incontrolado de algunos índices a 600 GB.
Por ejemplo, para configurar la rotación:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
En ausencia de alias de rollover, se produjo un error:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Dejamos la solución a este problema para la próxima iteración y tomamos otra pregunta: cambiamos para extraer la lógica de Logstash, que maneja los registros entrantes (eliminando información innecesaria y enriqueciéndola). Lo colocamos en docker, que ejecutamos a través de docker-compose, y colocamos logstash-exporter en el mismo lugar, lo que proporciona las métricas a Prometheus para el monitoreo operativo de la secuencia de registro. Entonces nos dimos la oportunidad de cambiar sin problemas la cantidad de instancias de logstash responsables del procesamiento de cada tipo de registro.
Mientras estábamos mejorando el clúster, el tráfico de cian.ru creció a 12.8 millones de usuarios únicos por mes. Como resultado, resultó que nuestras conversiones no se mantuvieron un poco al día con los cambios en la producción, y nos enfrentamos con el hecho de que los nodos "calientes" no podían hacer frente a la carga y ralentizaron la entrega completa de registros. Recibimos los datos "en caliente" sin fallas, pero tuvimos que intervenir en la entrega del resto y hacer una renovación manual para distribuir uniformemente los índices.
Al mismo tiempo, escalar y cambiar la configuración de las instancias de logstash en el clúster se complicó por el hecho de que se trataba de un docker-compose local, y todas las acciones se realizaron a mano (para agregar nuevos extremos, tenía que pasar por todos los servidores con las manos y hacer docker-compose up -d en todas partes).
Redistribución de registros
En septiembre de este año, seguimos viendo el monolito, la carga en el clúster aumentó y el flujo de registro se acercaba a 30 mil mensajes por segundo.
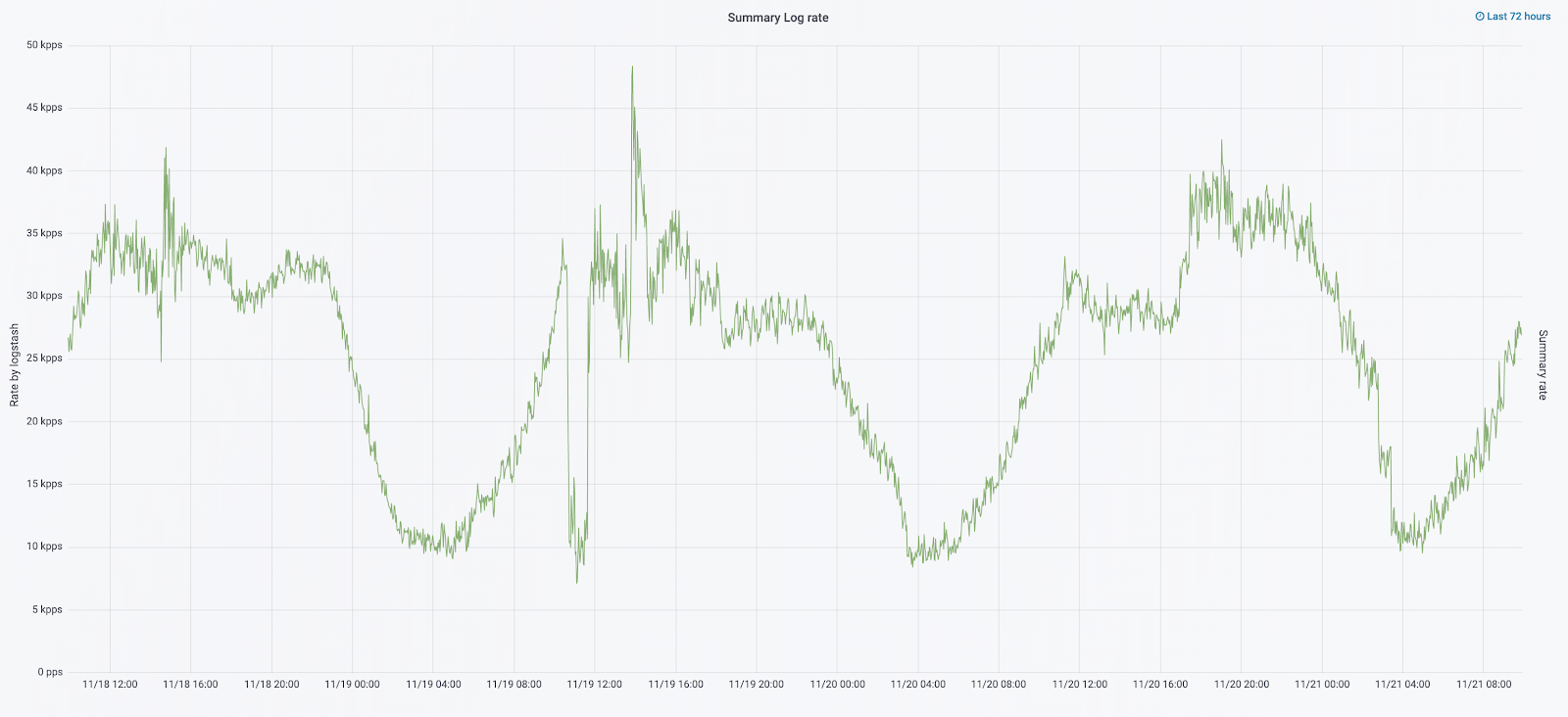
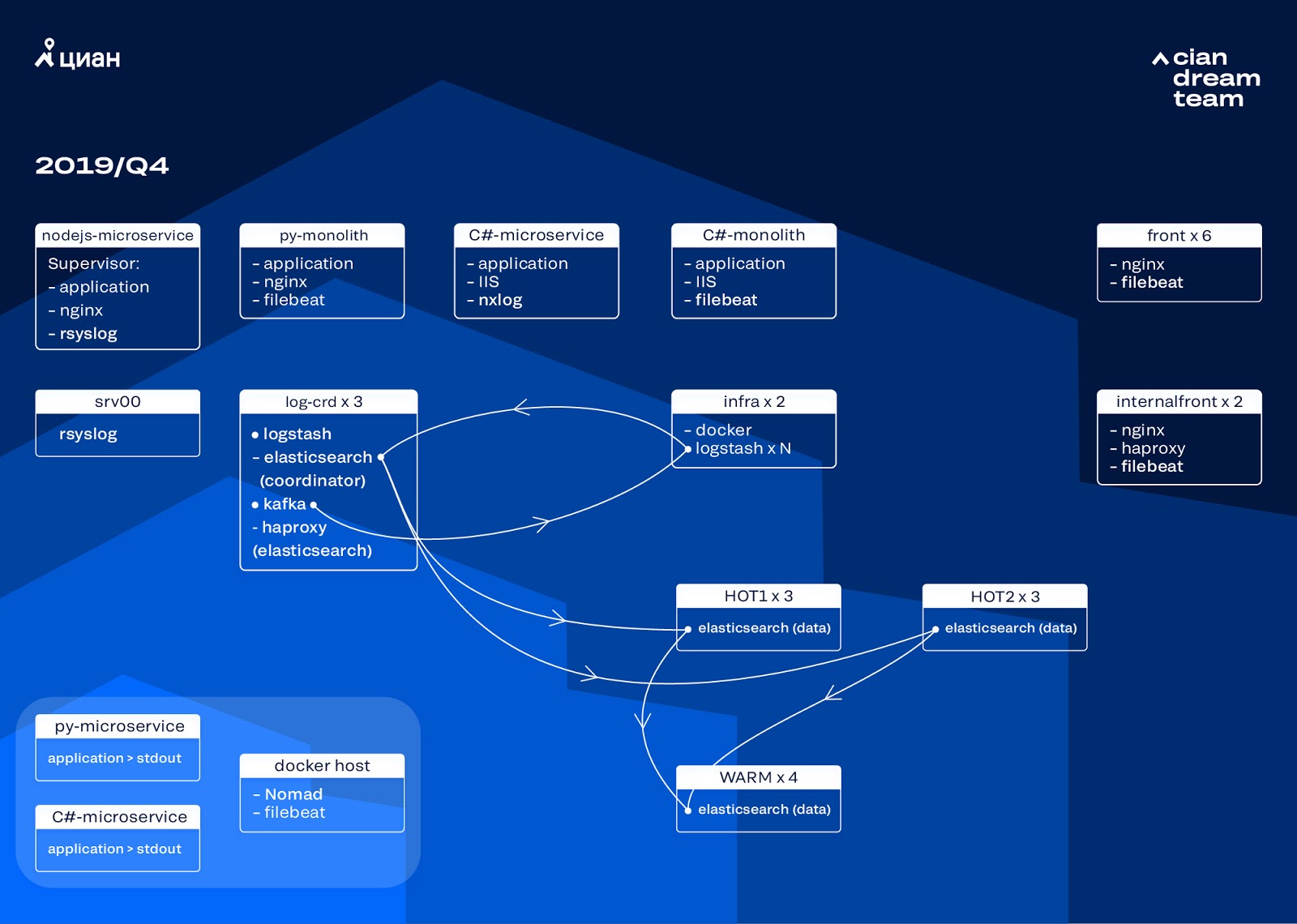
Comenzamos la siguiente iteración con la actualización de la plancha. Cambiamos de cinco coordinadores a tres, reemplazamos nodos de datos y ganamos en términos de dinero y volumen de almacenamiento. Para los nodos, utilizamos dos configuraciones:
- Para nodos activos: E3-1270 v6 / 960 Gb SSD / 32 Gb x 3 x 2 (3 para Hot1 y 3 para Hot2).
- Para nodos calientes: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
En esta iteración, sacamos el índice con registros de acceso de microservicios, que ocupan tanto espacio como los registros de nginx de front-end, en el segundo grupo de tres nodos activos. Ahora almacenamos datos en nodos activos durante 20 horas y luego los transferimos para calentarlos a otros registros.
Resolvimos el problema de la desaparición de pequeños índices reconfigurando su rotación. Los índices ahora se rotan de todos modos cada 23 horas, incluso si hay pocos datos. Esto aumentó ligeramente el número de fragmentos (se convirtieron en unos 800), pero desde el punto de vista del rendimiento del clúster esto es tolerable.
Como resultado, seis nodos "calientes" y solo cuatro "cálidos" resultaron en el clúster. Esto provoca un ligero retraso en las solicitudes durante largos intervalos de tiempo, pero aumentar el número de nodos en el futuro resolverá este problema.
En esta iteración, también se solucionó el problema de la falta de escalado semiautomático. Para hacer esto, implementamos un clúster de infraestructura Nomad, similar a lo que ya hemos implementado para la producción. Si bien el número de Logstash no cambia automáticamente según la carga, llegaremos a esto.
Planes futuros
La configuración implementada escala bien, y ahora almacenamos 13.3 TB de datos, todos registros en 4 días, lo cual es necesario para el análisis de emergencia de alertas. Convertimos parte de los registros a métricas, que agregamos a Graphite. Para facilitar el trabajo de los ingenieros, tenemos métricas para el clúster de infraestructura y scripts para solucionar problemas típicos semiautomáticos. Después de aumentar el número de nodos de datos, que está previsto para el próximo año, cambiaremos al almacenamiento de datos de 4 a 7 días. Esto será suficiente para el trabajo operativo, ya que siempre tratamos de investigar los incidentes lo antes posible, y los datos de telemetría están disponibles para investigaciones a largo plazo.
En octubre de 2019, el tráfico de cian.ru aumentó a 15,3 millones de usuarios únicos por mes. Esta fue una prueba seria de la solución arquitectónica para la entrega de registros.
Ahora nos estamos preparando para actualizar ElasticSearch a la versión 7. Sin embargo, para esto tendremos que actualizar la asignación de muchos índices en ElasticSearch, porque se trasladaron de la versión 5.5 y se declararon obsoletos en la versión 6 (simplemente no existen en la versión 7). Y esto significa que, en el proceso de actualización, habrá alguna fuerza mayor que nos dejará sin registros por el momento. De las 7 versiones, estamos ansiosos por Kibana con una interfaz mejorada y nuevos filtros.
Logramos el objetivo principal: dejamos de perder registros y redujimos el tiempo de inactividad del clúster de infraestructura de 2-3 caídas por semana a un par de horas de trabajo de servicio por mes. Todo este trabajo en producción es casi invisible. Sin embargo, ahora podemos determinar con precisión lo que está sucediendo con nuestro servicio, podemos hacerlo rápidamente en un modo silencioso y no preocuparnos de que se pierdan los registros. En general, estamos satisfechos, felices y nos estamos preparando para nuevos exploits, de los que hablaremos más adelante.