
Mi trabajo principal es, en su mayor parte, el despliegue de sistemas de software, es decir, paso mucho tiempo tratando de responder estas preguntas:
- Este software funciona para el desarrollador, pero no para mí. Por qué
- Ayer este software funcionó para mí, pero no hoy. Por qué
Este es un tipo de depuración que es ligeramente diferente de la depuración de software normal. La depuración normal se trata de la lógica del código, pero la depuración de la implementación se trata de la interacción del código y el entorno. Incluso si la raíz del problema es un error lógico, el hecho de que todo funcione en una máquina y no en otra significa que el problema está de alguna manera en el medio ambiente.
Entonces, en lugar de las herramientas de depuración habituales como gdb , tengo un conjunto diferente de herramientas para depurar la implementación. Y mi herramienta favorita para tratar un problema como "¿Por qué no funciona este software?" llamado strace .
¿Qué es strace?
strace es una herramienta para rastrear una llamada al sistema. Inicialmente creado bajo Linux, pero los mismos chips de depuración pueden rotarse con herramientas para otros sistemas ( DTrace o ktrace ).
La aplicación principal es muy simple. Solo necesita ejecutar strace con cualquier comando y enviará todas las llamadas del sistema al volcado (aunque, primero, probablemente tenga que instalar strace ):
$ strace echo Hello ...Snip lots of stuff... write(1, "Hello\n", 6) = 6 close(1) = 0 close(2) = 0 exit_group(0) = ? +++ exited with 0 +++
¿Qué son estas llamadas al sistema? Es un tipo de API para el núcleo del sistema operativo. Érase una vez, el software tenía acceso directo al hardware en el que funcionaba. Si, por ejemplo, necesita mostrar algo en la pantalla, se reproduce con puertos y / o registros de memoria para dispositivos de video. Cuando los sistemas informáticos multitarea se hicieron populares, el caos reinó porque varias aplicaciones lucharon por el hardware. Los errores en una aplicación podrían afectar el trabajo de otros, si no todo el sistema. Luego aparecieron modos de privilegio (o "protección de anillo") en la CPU. El núcleo se convirtió en el más privilegiado: obtuvo acceso completo al hardware, creando aplicaciones menos privilegiadas que ya tenían que solicitar el acceso del núcleo para interactuar con el hardware a través de llamadas al sistema.
A nivel binario, una llamada al sistema es ligeramente diferente de una simple llamada a función, sin embargo, la mayoría de los programas usan un contenedor en la biblioteca estándar. Es decir la biblioteca estándar POSIX C contiene una llamada a la función write () , que contiene todo el código específico de la arquitectura para la llamada al sistema de escritura .
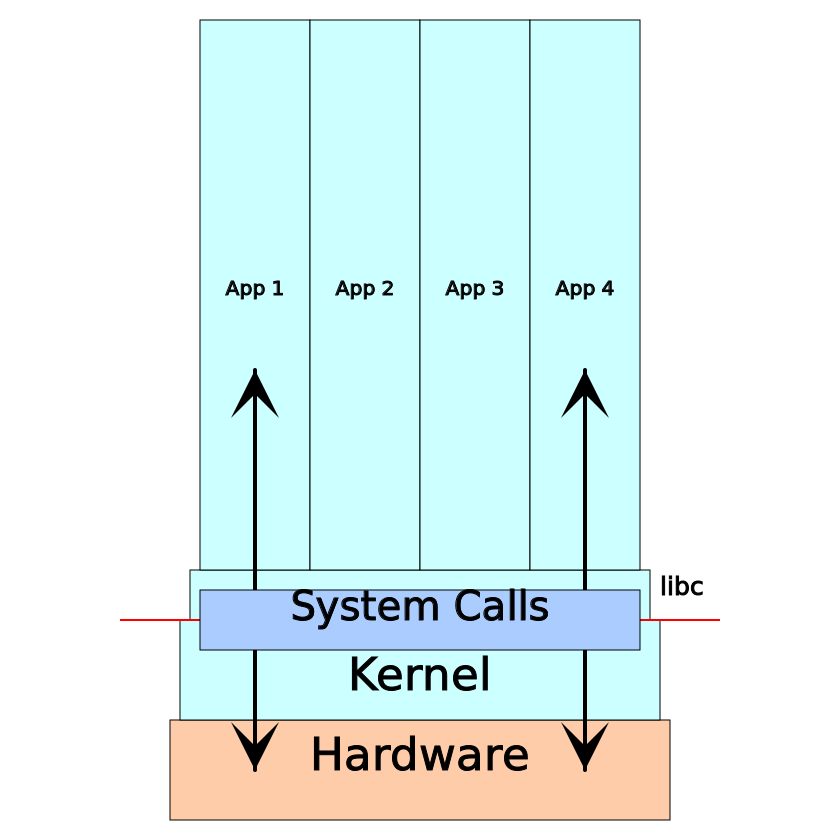
En resumen, cualquier interacción entre la aplicación y su entorno (sistemas informáticos) se lleva a cabo mediante llamadas al sistema. Por lo tanto, cuando el software funciona en una máquina y no en otra, sería bueno ver los resultados de las llamadas del sistema de rastreo. Para ser más específicos, aquí hay una lista de puntos típicos que se pueden analizar mediante el seguimiento de llamadas del sistema:
- Consola de E / S
- Entrada / salida de red
- Acceso al sistema de archivos y E / S de archivos
- Gestión de vida útil de procesos / subprocesos
- Gestión de memoria de bajo nivel
- Acceso a controladores de dispositivos específicos.
¿Cuándo usar strace?
En teoría, strace se usa con cualquier programa en el espacio del usuario, porque cualquier programa en el espacio del usuario debe hacer llamadas al sistema. Funciona de manera más eficiente con programas compilados de bajo nivel, pero también funciona con lenguajes de nivel superior como Python si puede superar el ruido adicional del tiempo de ejecución y el intérprete.
En todo su esplendor, strace se manifiesta durante la depuración de software que funciona bien en una máquina, pero de repente deja de funcionar en otra, dando mensajes confusos sobre archivos, permisos o intentos fallidos de ejecutar algunos comandos o algo ... Es una pena, pero no tan bueno. se combina con problemas de alto nivel, como errores de verificación de certificados. Esto generalmente requiere una combinación de herramientas strace , a veces ltrace, y de nivel superior (como la herramienta de línea de comandos openssl para depurar un certificado).
Por ejemplo, trabajamos en un servidor independiente, pero las llamadas del sistema de rastreo a menudo se pueden realizar en plataformas de implementación más complejas. Solo necesita elegir el kit de herramientas adecuado.
Ejemplo de depuración simple
Digamos que desea ejecutar la increíble aplicación de servidor foo, pero resulta esto:
$ foo Error opening configuration file: No such file or directory
Obviamente, no pudo encontrar el archivo de configuración que escribió. Esto sucede porque a veces, cuando los administradores de paquetes compilan una aplicación, anulan la ubicación esperada de los archivos. Y si sigue la guía de instalación para una distribución, en otra encontrará los archivos completamente, no donde esperaba. Sería posible resolver el problema en un par de segundos si el mensaje de error decía dónde buscar el archivo de configuración, pero no dice. Entonces, ¿dónde mirar?
Si tiene acceso al código fuente, puede leerlo y averiguarlo. Un buen plan de respaldo, pero no la solución más rápida. Puede recurrir a un depurador paso a paso como gdb y ver qué hace el programa, pero es mucho más eficiente usar una herramienta especialmente diseñada para mostrar la interacción con el entorno: strace .
La conclusión de strace puede parecer redundante, pero la buena noticia es que la mayor parte se puede ignorar con seguridad. A menudo es útil usar el operador -o para guardar los resultados de seguimiento en un archivo separado:
$ strace -o /tmp/trace foo Error opening configuration file: No such file or directory $ cat /tmp/trace execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0 brk(NULL) = 0x56363b3fb000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0 mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000 close(3) = 0 openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\260A\2\0\0\0\0\0"..., 832) = 832 fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000 mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000 mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0 mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000 mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000 mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000 mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000 close(3) = 0 arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0 mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0 mprotect(0x56363b08b000, 4096, PROT_READ) = 0 mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0 munmap(0x7f2f12cf1000, 25186) = 0 openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory) dup(2) = 3 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR) brk(NULL) = 0x56363b3fb000 brk(0x56363b41c000) = 0x56363b41c000 fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0 write(3, "Error opening configuration file"..., 60) = 60 close(3) = 0 exit_group(1) = ? +++ exited with 1 +++
Casi toda la primera página de salida de strace suele ser una preparación de bajo nivel para el lanzamiento. (Hay muchas llamadas mmap , mprotect , brk para cosas como detectar memoria de bajo nivel y mostrar bibliotecas dinámicas). De hecho, durante la depuración, las salidas de strace se leen mejor desde el final. En la parte inferior hay una llamada para escribir , que muestra un mensaje de error. Miramos arriba y vemos la primera llamada de sistema errónea: una llamada de openat que arroja un error ENOENT ("archivo o directorio no encontrado"), intentando abrir /etc/foo/config.json . Aquí, aquí debe estar el archivo de configuración.
Fue solo un ejemplo, pero diría que el 90% del tiempo que uso strace , nada es mucho más difícil de hacer y no tiene que hacerlo. A continuación se muestra una guía completa de depuración paso a paso:
- Frustrado por un mensaje de error de sistema-slurred de un programa
- Reinicia el programa con strace
- Encuentra el mensaje de error en los resultados de seguimiento
- Ve más alto hasta que te topes con la primera llamada fallida del sistema
Es muy probable que la llamada al sistema en el paso 4 muestre lo que salió mal.
Consejos
Antes de mostrar un ejemplo de depuración más compleja, te contaré algunos trucos para usar strace de manera efectiva:
el hombre es tu amigo
En muchos sistemas * nix, se puede obtener una lista completa de las llamadas al sistema kernel ejecutando man syscalls . Verá cosas como brk (2) , lo que significa que puede obtener más información ejecutando man 2 brk .
Un pequeño rake: man 2 fork me muestra una página para el shell fork () en GNU libc , que resulta ser implementado usando la llamada clone () . La semántica de la llamada fork sigue siendo la misma si escribe un programa que usa fork () y comienza a rastrear: no encontraré llamadas fork , en lugar de ellas habrá clone () . Tal rastrillo solo se confunde si comienzas a comparar la fuente con la salida de strace .
Use -o para guardar la salida en un archivo
strace puede generar una salida extensa, por lo que a menudo es útil almacenar resultados de rastreo en archivos separados (como en el ejemplo anterior). Y ayuda a no confundir la salida del programa con la salida de la consola.
Use -s para ver más datos de argumentos
Probablemente haya notado que la segunda mitad del mensaje de error no se muestra en el ejemplo de seguimiento anterior. Esto se debe a que strace solo muestra los primeros 32 bytes del argumento de cadena de forma predeterminada. Si desea ver más, agregue algo como -s 128 a la llamada de strace .
-y facilita el seguimiento de archivos \ sockets \ y así sucesivamente.
"Todo es un archivo" significa que los sistemas * nix realizan todas las E / S utilizando descriptores de archivo, ya sea que se aplique a un archivo o red, o a canales de interproceso. Esto es conveniente para la programación, pero hace que sea difícil hacer un seguimiento de lo que realmente sucede cuando ve la lectura y escritura generales en los resultados de seguimiento de una llamada al sistema.
Al agregar el operador -u, fuerza a strace a anotar cada descriptor de archivo en la salida con una nota de lo que apunta.
Adjuntar a un proceso que ya se está ejecutando con -p **
Como se verá en el siguiente ejemplo, a veces necesita rastrear un programa que ya se está ejecutando. Si sabe que se está ejecutando como el proceso 1337 (por ejemplo, de las conclusiones de ps ), puede rastrearlo así:
$ strace -p 1337 ...system call trace output...
Quizás necesite privilegios de root.
Use -f para monitorear procesos secundarios
strace de forma predeterminada solo rastrea un proceso. Si este proceso genera procesos secundarios, puede ver la llamada del sistema para generar el proceso secundario, pero las llamadas del sistema del proceso secundario no se mostrarán.
Si cree que el error está en el proceso secundario, use el operador -f , esto habilitará su rastreo. La desventaja de esto es que la conclusión te confundirá aún más. Cuando strace rastrea un proceso o un hilo, muestra una secuencia única de eventos de llamada. Cuando rastrea varios procesos a la vez, probablemente verá el comienzo de la llamada interrumpida por el mensaje <inacabado ...> , luego un montón de llamadas para otras ramas de ejecución, y solo entonces el final de la primera con <... foocall resume> . O separe todos los resultados de rastreo en diferentes archivos, utilizando también el operador -ff ( consulte el manual de strace para más detalles).
Filtre la traza con -e
Como puede ver, el resultado del rastreo es un grupo real de todas las llamadas posibles del sistema. Con la bandera -e , puede filtrar la traza (consulte el manual de strace ). La principal ventaja es que ejecutar una traza con filtrado es más rápido que hacer una traza completa, y luego grep . Para ser honesto, casi siempre no me importa.
No todos los errores son malos.
Un ejemplo simple y común es un programa que busca un archivo en varios lugares a la vez, como un shell que busca, en el que el directorio basket / contiene un archivo ejecutable:
$ strace sh -c uname ... stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory) stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0 ...
Una heurística de "última solicitud fallida antes del mensaje de error" es buena para encontrar errores relevantes. Sea como fuere, es lógico comenzar desde el final.
Las guías de programación de C ayudan a comprender las llamadas al sistema
Las llamadas estándar a las bibliotecas C no son llamadas del sistema, sino solo una capa superficial delgada. Entonces, si comprende al menos un poco cómo y qué hacer en C, será más fácil para usted comprender los resultados de rastrear una llamada al sistema. Por ejemplo, si tiene problemas para depurar llamadas a sistemas en red, consulte la misma "Guía de programación de red" de Bija .
Ejemplo de depuración más complicado
Ya he dicho que un ejemplo de depuración simple es un ejemplo de algo con lo que, en su mayor parte, tengo que lidiar con strace . Sin embargo, a veces se requiere una investigación real, así que aquí hay un ejemplo real de depuración más complicada.
bcron es un programador de procesamiento de tareas, otra implementación del demonio * nix cron . Está instalado en el servidor, pero cuando alguien intenta editar la programación, esto es lo que sucede:
# crontab -e -u logs bcrontab: Fatal: Could not create temporary file
Bien, entonces Bcron trató de escribir cierto archivo, pero no funcionó y no admite por qué. Descubrir strace :
# strace -o /tmp/trace crontab -e -u logs bcrontab: Fatal: Could not create temporary file # cat /tmp/trace ... openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 read(3, "#Ansible: logsagg\n20 14 * * * lo"..., 8192) = 150 read(3, "", 8192) = 0 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 socket(AF_UNIX, SOCK_STREAM, 0) = 3 connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0 mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000 write(3, "156:Slogs\0#Ansible: logsagg\n20 1"..., 161) = 161 read(3, "32:ZCould not create temporary f"..., 8192) = 36 munmap(0x7f82049b4000, 8192) = 0 close(3) = 0 write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49 unlink("bcrontab.14779.1573691864.847933") = 0 exit_group(111) = ? +++ exited with 111 +++
Al final, hay un mensaje de error de escritura , pero esta vez algo es diferente. En primer lugar, no hay un error de llamada al sistema relevante que generalmente ocurra antes de esto. En segundo lugar, está claro que en algún lugar alguien ya ha leído el mensaje de error. Parece que el verdadero problema está en otro lugar, y bcrontab solo reproduce el mensaje.
Si observa la lectura de man 2 , puede ver que el primer argumento (3) es el descriptor de archivo que * nix usa para todo el procesamiento de E / S. ¿Cómo saber qué representa el descriptor de archivo 3? En este caso particular, puede ejecutar strace con el operador -u (ver arriba), y automáticamente le dirá, sin embargo, para calcular tales cosas, es útil saber cómo leer y analizar los resultados de la traza.
La fuente del descriptor de archivo puede ser una de las muchas llamadas al sistema (todo depende de cuál sea el descriptor para la consola, el socket de red, el archivo en sí mismo u otra cosa), pero sea como sea, estamos buscando llamadas que devuelvan 3 (t .e. busque "= 3" en los resultados del seguimiento). Como resultado, hay 2 de ellos: openat en la parte superior y socket en el medio. openat abre el archivo, pero cerrar (3) después de eso mostrará que se cierra nuevamente. (Rastrillo: los descriptores de archivo se pueden reutilizar cuando se abren y cierran). La llamada socket () es adecuada, ya que es la última antes de read () , y resulta que bcrontab funciona con algo a través del socket. La siguiente línea muestra que el descriptor de archivo está asociado con el socket del dominio Unix a lo largo de la ruta / var / run / bcron-spool .
Por lo tanto, debe encontrar el proceso conectado al zócalo Unix por otro lado. Hay un par de trucos ingeniosos para este propósito, y ambos son útiles para depurar implementaciones de servidores. El primero es usar netstat o ss más reciente (estado del socket). Ambos comandos muestran las conexiones de red activas del sistema y toman el operador -l para describir los zócalos de escucha, y el operador -p para mostrar los programas conectados al zócalo como cliente. (Hay muchas más opciones útiles, pero estas dos son suficientes para esta tarea).
# ss -pl | grep /var/run/bcron-spool u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))
Esto sugiere que el oyente es un comando inixserver que funciona con el ID de proceso 20629. (Y, por coincidencia, utiliza el descriptor de archivo 3 como socket).
La segunda herramienta realmente útil para encontrar la misma información se llama lsof . Enumera todos los archivos abiertos (o descriptores de archivos) en el sistema. O puede obtener información sobre un archivo específico:
# lsof /var/run/bcron-spool COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAM
El proceso 20629 es un servidor de larga duración, por lo que puede adjuntar strace utilizando algo como strace -o / tmp / trace -p 20629 . Si editamos la tarea cron en otro terminal, obtenemos la salida de los resultados de seguimiento con un error. Y aquí está el resultado:
accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL) = 4 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200 close(4) = 0 accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} --- wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200 wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes) rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0 rt_sigreturn({mask=[]}) = 43 accept(3, NULL, NULL
(La última aceptación () no se completará al rastrear). Y nuevamente, lamentablemente, este resultado no contiene el error que estamos buscando. No vemos ningún mensaje que bcrontag envíe o reciba de un socket. En su lugar, complete el control del proceso ( clone , wait4 , SIGCHLD , etc.) Este proceso genera un proceso hijo, que, como puede suponer, hace el trabajo real. Y si necesita atrapar su rastro, agregue strace -f a la llamada. Esto es lo que encontramos al buscar el mensaje de error en el nuevo resultado con strace -f -o / tmp / trace -p 20629 :
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
Ahora, esto es algo. El proceso 21470 recibe un error de "acceso denegado" cuando intenta crear un archivo en la ruta tmp / spool.21470.1573692319.854640 (en referencia al directorio de trabajo actual). Si simplemente supiéramos el directorio de trabajo actual, habríamos conocido la ruta completa y podríamos descubrir por qué el proceso no puede crear su propio archivo temporal. Desafortunadamente, el proceso ya se ha cerrado, por lo que no puede usar lsof -p 21470 para encontrar el directorio actual, sino que puede trabajar en la dirección opuesta: busque las llamadas al sistema PID 21470 que cambian el directorio. (Si no hay ninguno, el PID 21470 debe haberlos heredado del padre, y esto no se puede resolver a través de lsof -p .) Esta llamada al sistema es chdir (que es fácil de encontrar con la ayuda de los motores de búsqueda de red modernos). Y aquí está el resultado de búsquedas inversas basadas en los resultados de seguimiento, hasta el servidor PID 20629:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470 ... 21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0 ... 21470 chdir("/var/spool/cron") = 0 ... 21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied) 21470 write(1, "32:ZCould not create temporary f"..., 36) = 36 21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84 21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory) 21470 exit_group(111) = ? 21470 +++ exited with 111 +++
(Si se pierde, es posible que deba leer mi publicación anterior sobre el control de procesos y los shells * nix ). Entonces, el servidor PID 20629 no obtuvo permiso para crear un archivo a lo largo de la ruta /var/spool/cron/tmp/spool.21470.1573692319.854640 . , — . :
# ls -ld /var/spool/cron/tmp/ drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/ # ps u -p 20629 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spool
! cron, root /var/spool/cron/tmp/ . chown cron /var/spool/cron/tmp/ bcron . ( , — SELinux AppArmor, dmesg .)
Total
, , , , — . , bcron , .
, , , strace , , . , strace . , .