Hola a todos! Mi nombre es Alexey Skorobogaty, soy arquitecto de sistemas en Lamoda. En febrero de 2019, hablé en Go Meetup mientras aún estaba en la posición de líder del equipo Core. Hoy quiero presentar una transcripción de mi informe, que también pueden ver.
Nuestro equipo se llama Core por una razón: el área de responsabilidad incluye todo lo relacionado con los pedidos en la plataforma de comercio electrónico. El equipo estaba formado por desarrolladores de PHP y especialistas en nuestro procesamiento de pedidos, que en ese momento era un solo monolito. Estábamos comprometidos y continuamos lidiando con su descomposición en microservicios.

Un pedido en nuestro sistema consta de componentes relacionados: hay una unidad de entrega y una cesta, unidades de descuento y pago, y al final hay un botón que envía el pedido a recoger en el almacén. Es en este momento que comienza el trabajo del sistema de procesamiento de pedidos, donde se validarán todos los datos del pedido y se agregará la información.
Dentro de todo esto hay una compleja lógica multicriterio. Los bloques interactúan entre sí e influyen entre sí. Los cambios continuos y constantes del negocio se suman a la complejidad de los criterios. Además, tenemos diferentes plataformas a través de las cuales los clientes pueden crear pedidos: sitio web, aplicaciones, call center, plataforma B2B. Además de los estrictos criterios SLA / MTTI / MTTR (métricas de registro y resolución de incidentes). Todo esto requiere una gran flexibilidad y estabilidad del servicio.
Patrimonio arquitectonico
Como ya dije, en el momento de la formación de nuestro equipo, el sistema de procesamiento de pedidos era un monolito: casi 100 mil líneas de código que describían directamente la lógica empresarial. La parte principal fue escrita en 2011 usando la arquitectura clásica de MVC multicapa. Se basó en PHP (el marco ZF1), que fue gradualmente cubierto de adaptadores y componentes de Symfony para interactuar con varios servicios. Durante su existencia, el sistema tenía más de 50 contribuyentes, y aunque logramos mantener un estilo unificado de escritura de código, esto también impuso sus limitaciones. Además, surgió una gran cantidad de contextos mixtos; por diversas razones, se implementaron algunos mecanismos en el sistema que no estaban directamente relacionados con el procesamiento de pedidos. Todo esto llevó al hecho de que en este momento tenemos una base de datos MySQL mayor de 1 terabyte.
Esquemáticamente, la arquitectura inicial se puede representar de la siguiente manera:
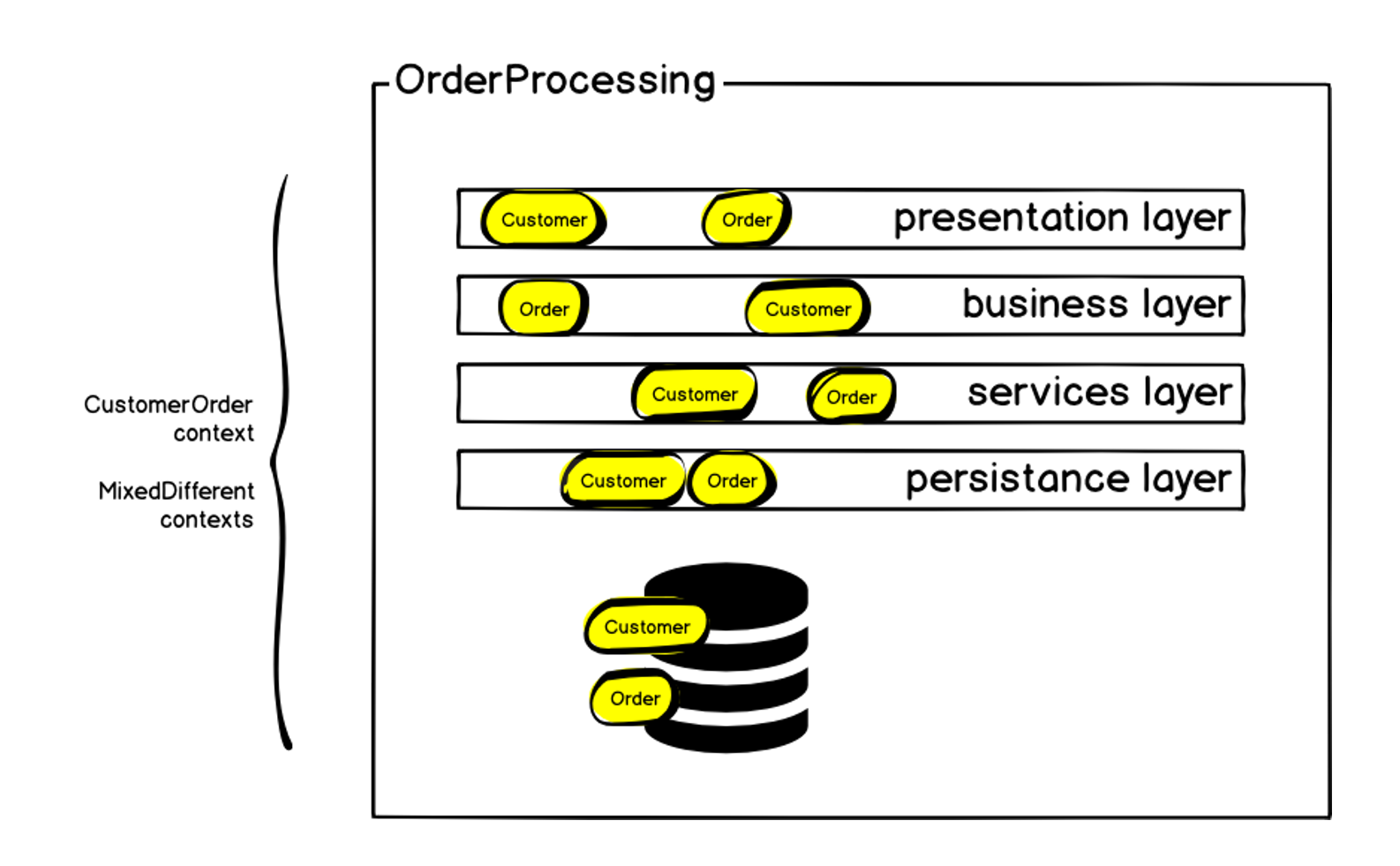
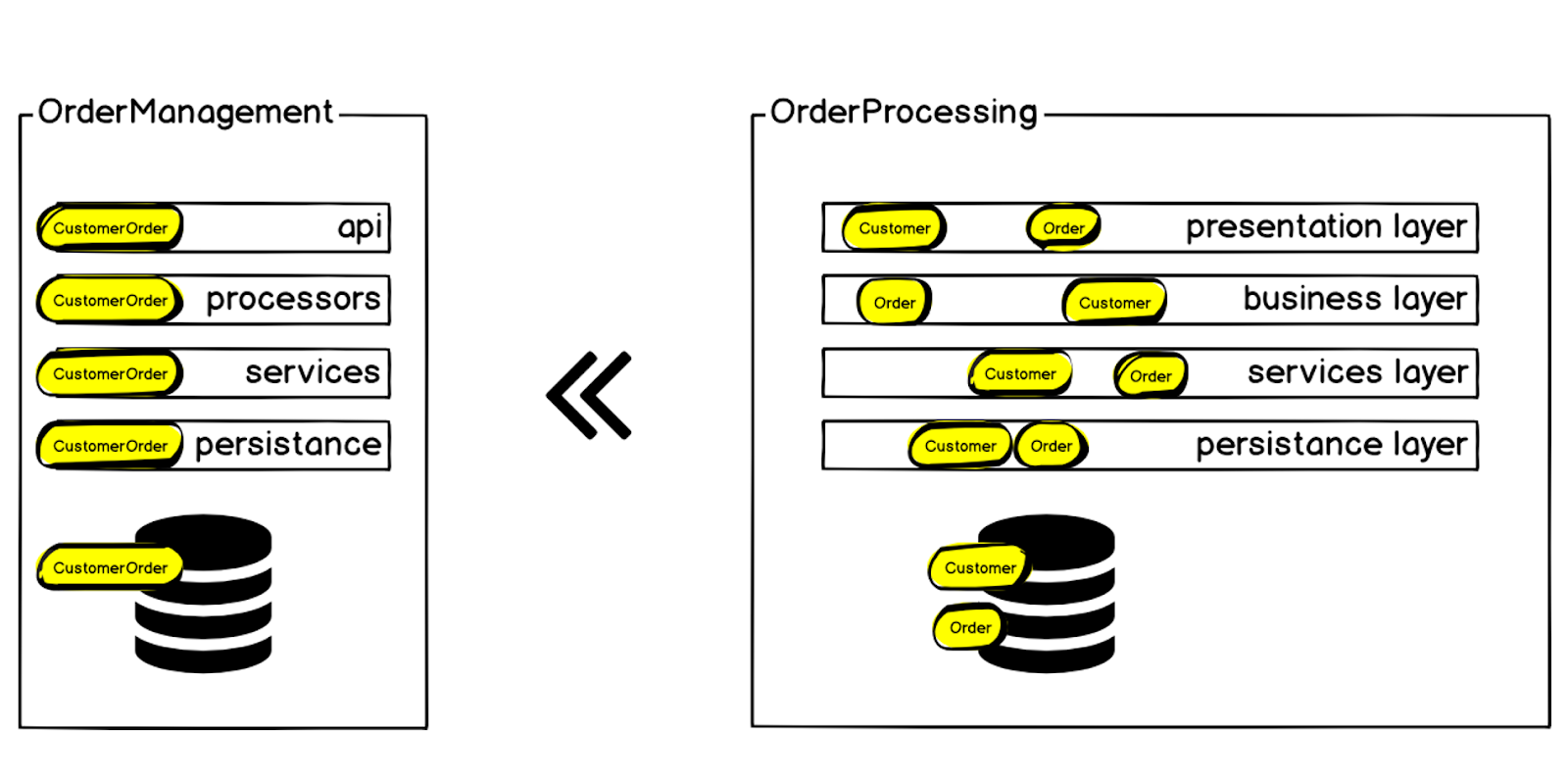
El orden, por supuesto, estaba en cada una de las capas, pero además del orden, había otros contextos. Comenzamos definiendo el contexto acotado del pedido y llamándolo el pedido del cliente, ya que además del pedido en sí, existen los mismos bloques que mencioné al principio: entrega, pago, etc. Dentro del monolito, todo esto fue difícil de manejar: cualquier cambio condujo a un aumento de las dependencias, el código se entregó al producto durante mucho tiempo y la probabilidad de errores y fallas del sistema aumentó todo el tiempo. Pero estamos hablando de crear un pedido, la métrica principal de una tienda en línea: si los pedidos no se crean, el resto no es tan importante. La falla del sistema causa una caída inmediata en las ventas.
Por lo tanto, decidimos transferir el contexto del Pedido del cliente desde el sistema de Procesamiento de pedidos a un microservicio separado, que se llamó Gestión de pedidos.
Requerimientos y herramientas
Después de determinar el contexto que decidimos eliminar del monolito en primer lugar, formamos los requisitos para nuestro servicio futuro:
- Rendimiento
- Consistencia de datos
- Sostenibilidad
- Previsibilidad
- Transparencia
- Incremento de cambio
Queríamos que el código fuera lo más claro y fácil de editar posible, para que la próxima generación de desarrolladores pudiera hacer rápidamente los cambios necesarios para el negocio.
Como resultado, llegamos a una cierta estructura que usamos en todos los microservicios nuevos:
Contexto acotado . Cada nuevo microservicio, comenzando con la Gestión de pedidos, creamos en función de los requisitos comerciales. Debe haber explicaciones específicas de qué parte del sistema y por qué se requiere colocarlo en un microservicio separado.
Infraestructura y herramientas existentes. No somos el primer equipo en Lamoda en comenzar a implementar Go; antes de nosotros había pioneros, el equipo Go en sí, que preparó la infraestructura y las herramientas:
- Gogi (swagger) es un generador de especificaciones de swagger.
- Gonkey (prueba): para pruebas funcionales.
- Usamos Json-rpc y generamos un enlace cliente / servidor mediante swagger. También implementamos todo esto en Kubernetes, recopilamos métricas en Prometheus, utilizamos ELK / Jaeger para el seguimiento; todo esto está incluido en el paquete que Gogi crea para cada nuevo microservicio por especificación.
Así es como se ve nuestro nuevo microservicio de gestión de pedidos:
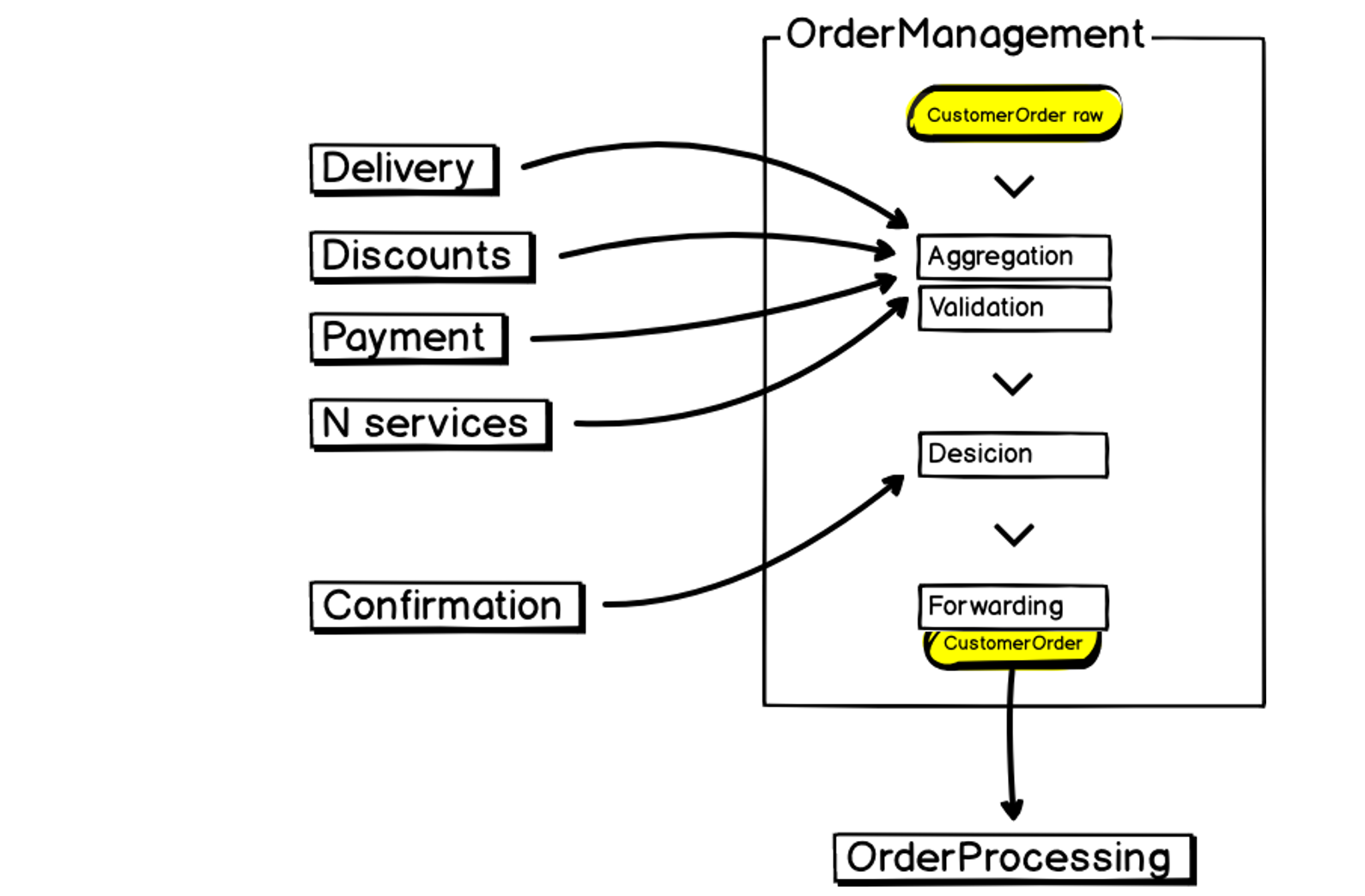
En la entrada, tenemos datos, los agregamos, los validamos, interactuamos con servicios de terceros, tomamos decisiones y transferimos los resultados al procesamiento de pedidos, el mismo monolito que es grande, inestable y requiere recursos. Esto también debe tenerse en cuenta al construir un microservicio.
Cambio de paradigma
Al elegir Ir, inmediatamente obtuvimos varias ventajas:
- La escritura fuerte y estática corta inmediatamente un cierto rango de posibles errores.
- El modelo de concurrencia se adapta bien a nuestras tareas, ya que necesitamos caminar y sondear simultáneamente varios servicios.
- La composición y las interfaces también nos ayudan en las pruebas.
- La "simplicidad" del estudio : aquí se descubrieron no solo ventajas obvias, sino también problemas.
Go language limita la imaginación del desarrollador. Esto se convirtió en un obstáculo para nuestro equipo, acostumbrado a PHP cuando cambiamos al desarrollo en Go. Nos enfrentamos a un cambio de paradigma real. Tuvimos que pasar por varias etapas y entender algunas cosas:
- Ir es difícil de construir abstracciones.
- Se puede decir que Go está basado en objetos, pero no es un lenguaje orientado a objetos, ya que no hay herencia directa y algunas otras cosas.
- Ir ayuda a escribir explícitamente, en lugar de esconder objetos detrás de abstracciones.
- Ir tiene tubería. Esto nos inspiró a construir cadenas de procesadores de datos.
Como resultado, llegamos a comprender que Go es un lenguaje de programación procesal.

Datos primero
Estaba pensando cómo visualizar el problema que estábamos enfrentando y encontré esta imagen:
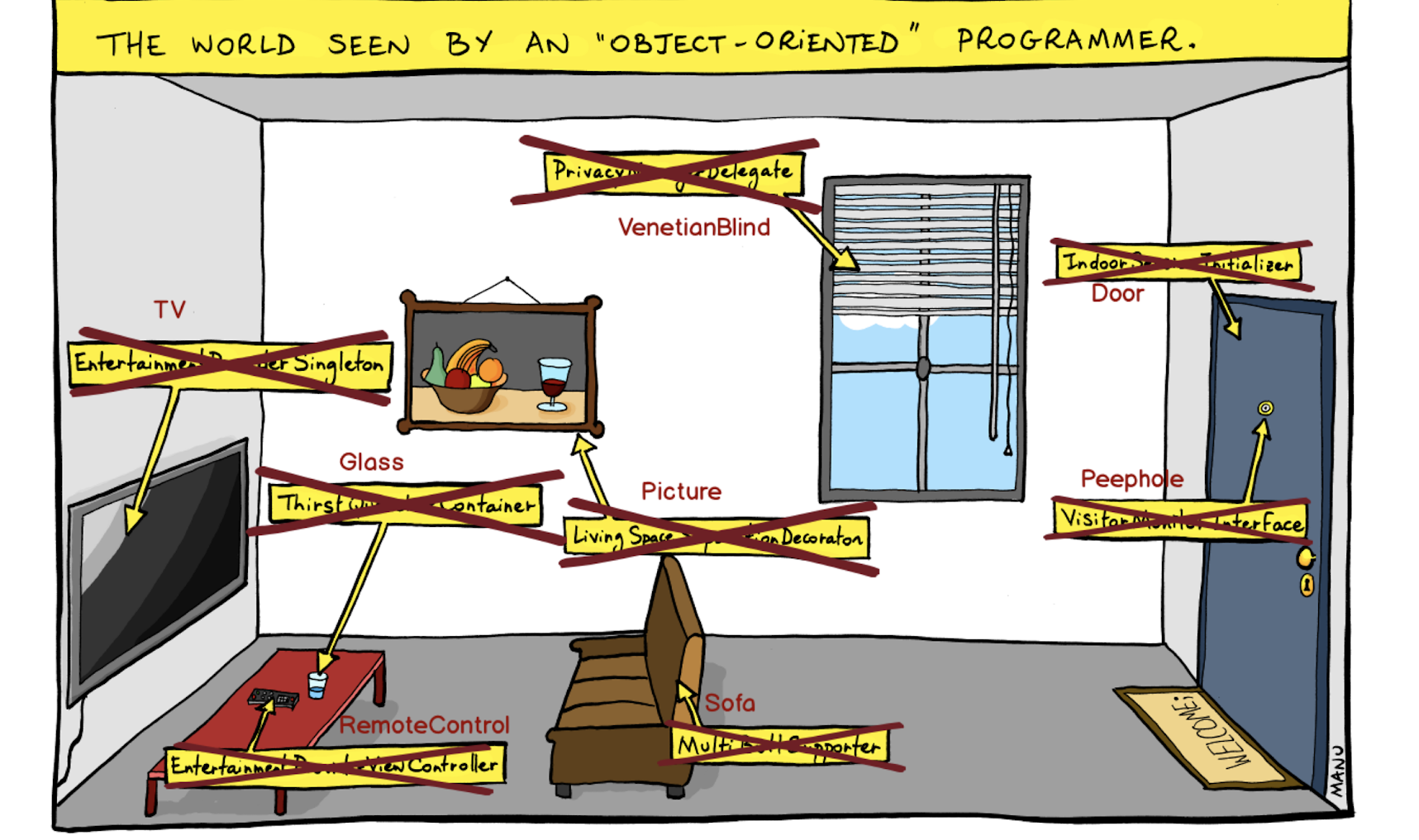
Esta es una visión del mundo "orientada a objetos" donde construimos abstracciones y cerramos objetos detrás de ellas. Por ejemplo, aquí no es solo una puerta, sino un iniciador de sesión interior. No el alumno, sino la interfaz de monitor de visitante, y así sucesivamente.
Abandonamos este enfoque y colocamos entidades en primer lugar, sin obscurecernos por las abstracciones.
Razonando de esta manera, ponemos datos en primer lugar, y obtuvimos dicha canalización en el servicio:

Inicialmente, definimos un modelo de datos que ingresa a la tubería del controlador. Los datos son mutables y los cambios pueden ocurrir tanto de forma secuencial como simultánea. Con esto, ganamos en velocidad.
Regreso al futuro
De repente, al desarrollar microservicios, llegamos al modelo de programación de los años 70. Después de los años 70, surgieron grandes monolitos empresariales, donde apareció la programación orientada a objetos, y la programación funcional, grandes abstracciones que hicieron posible mantener el código en estos monolitos. En microservicios, no necesitamos todo esto, y podemos usar el excelente modelo de CSP ( comunicación de procesos secuenciales ), cuya idea fue presentada solo en los años 70 por Charles Hor.
También utilizamos Secuencia / Selección / Interación, un paradigma de programación estructural según el cual todo el código del programa puede estar compuesto por las estructuras de control correspondientes.
Bueno, la programación de procedimientos, que era la corriente principal en los años 70 :)
Estructura del proyecto

Como dije, en primer lugar colocamos los datos. Además, reemplazamos la construcción del proyecto "desde la infraestructura" por una orientada a los negocios. Para que el desarrollador, al ingresar el código del proyecto, vea de inmediato lo que está haciendo el servicio: esta es la transparencia que hemos identificado como uno de los requisitos básicos para la estructura de nuestros microservicios.
Como resultado, tenemos una arquitectura plana: una pequeña capa API más modelos de datos. Y toda la lógica (que está limitada en nuestro contexto por los requisitos comerciales de un microservicio) se almacena en procesadores (controladores).
Intentamos no crear nuevos microservicios separados sin una solicitud clara de la empresa: así es como controlamos la granularidad de todo el sistema. Si existe una lógica que está estrechamente relacionada con el microservicio existente, pero esencialmente se refiere a un contexto diferente, primero lo concluimos en los llamados servicios. Y solo cuando surge una necesidad comercial constante, la llevamos a un microservicio separado, que luego pasamos a usar una llamada rpc.
Para controlar la granularidad y no producir microservicios sin pensar, concluimos una lógica que no está directamente relacionada con este contexto, sino que está estrechamente relacionada con este microservicio, en la capa de servicios. Y luego, si hay una necesidad comercial, lo llevamos a un microservicio separado, y luego lo usamos con la llamada rpc para acceder a él.
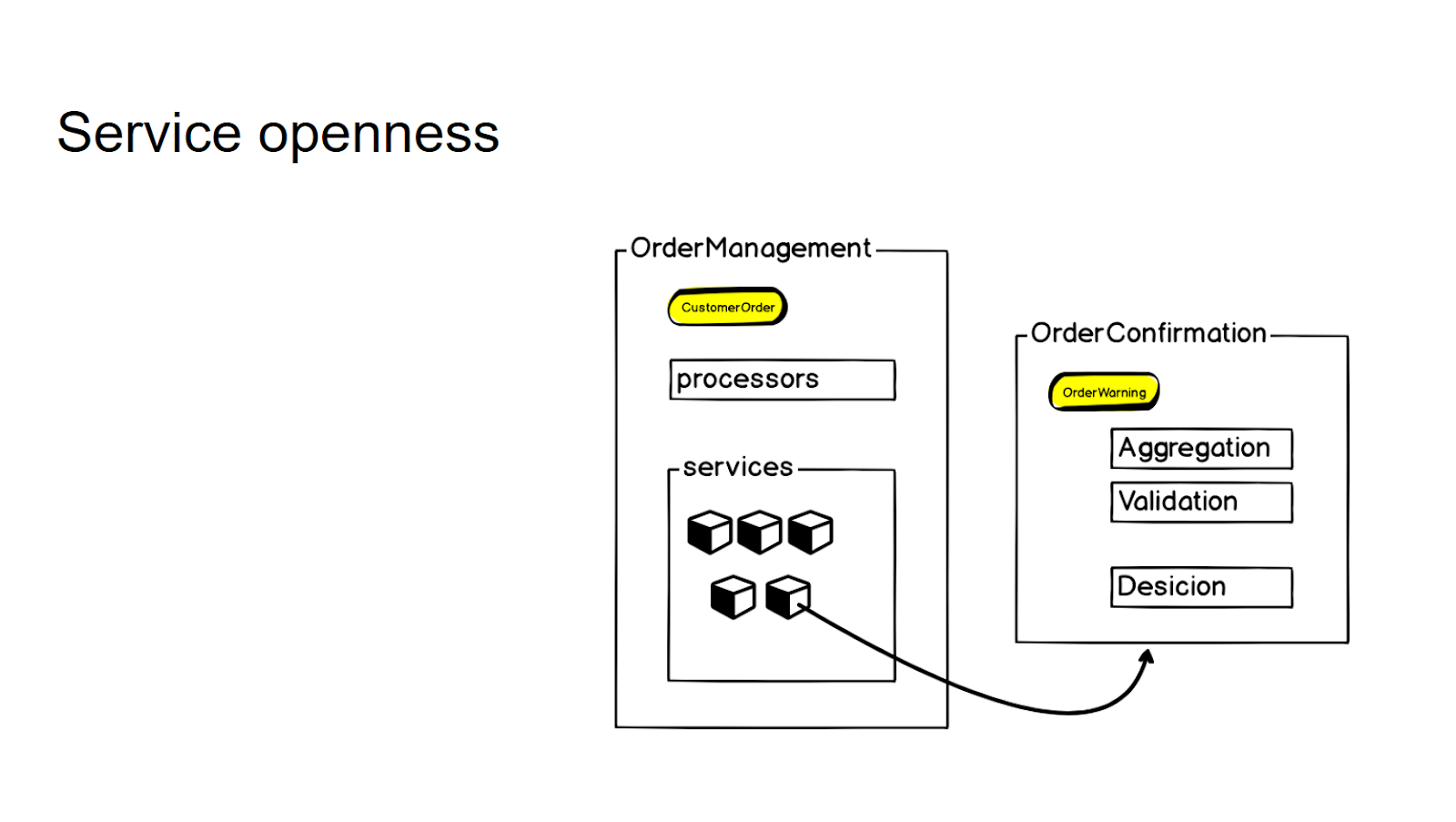
Por lo tanto, para la API interna en los procesadores del servicio, la interacción no cambia de ninguna manera.
Sostenibilidad
Decidimos no tomar bibliotecas de terceros por adelantado, ya que los datos con los que trabajamos son bastante confidenciales. Así que hicimos un ciclo un poco :) Por ejemplo, nosotros mismos implementamos algunos mecanismos clásicos, para Idempotency, Queue-worker, Fault Tolerance, Compensating transacciones. Nuestro siguiente paso es intentar reutilizarlo. Envuelva en bibliotecas, tal vez contenedores laterales en vainas Kubernetes. Pero ahora podemos aplicar estos patrones.
Implementamos en nuestros sistemas un patrón llamado degradación elegante: el servicio debe continuar funcionando, independientemente de las llamadas externas en las que agreguemos información. En el ejemplo de creación de un pedido: si la solicitud entró en el servicio, crearemos un pedido en cualquier caso. Incluso si el servicio vecino cae, que es responsable de alguna parte de la información que debemos agregar o validar. Además, no perderemos el pedido, incluso si no podemos rechazar a corto plazo el procesamiento del pedido, donde debemos transferirlo. Este es también uno de los criterios por los cuales decidimos si poner la lógica en un servicio separado. Si un servicio no puede proporcionar su trabajo cuando los siguientes servicios no están disponibles en la red, entonces debe rediseñarlo o pensar si debe eliminarse del monolito.
Ir a ir!
Cuando viene a escribir microservicios de productos orientados a los negocios desde una arquitectura clásica orientada a servicios, en particular PHP, se encuentra con un cambio de paradigma. Y debe ser aprobado, de lo contrario puede pisar el rastrillo sin cesar. La estructura del proyecto orientada a los negocios nos permite no complicar el código una vez más y controlar la granularidad del servicio.
Una de nuestras tareas principales era aumentar la estabilidad del servicio. Por supuesto, Go no proporciona una mayor estabilidad recién sacada de la caja. Pero, en mi opinión, en el ecosistema Go, resultó ser más fácil crear todo el kit de confiabilidad necesario, incluso con sus propias manos, sin recurrir a bibliotecas de terceros.
Otra tarea importante era aumentar la flexibilidad del sistema. Y aquí definitivamente puedo decir que la tasa de introducción de cambios requeridos por el negocio ha crecido significativamente. Gracias a la arquitectura de los nuevos microservicios, el desarrollador se queda solo con las características del negocio; no necesita pensar en crear clientes, enviar monitoreo, enviar seguimiento y configurar el registro. Dejamos para el desarrollador exactamente la capa de escritura de lógica empresarial, lo que le permite no pensar en todo el paquete de infraestructura.
¿Vamos a reescribir completamente todo en Go y abandonar PHP?
No, dado que nos estamos alejando de las necesidades comerciales, y hay algunos contextos en los que PHP encaja muy bien: no necesita tanta velocidad y todo el kit de herramientas Go-go. Toda la automatización de las operaciones para la entrega de pedidos y la gestión del estudio fotográfico se realiza en PHP. Pero, por ejemplo, en la plataforma de comercio electrónico en el lado del cliente, casi reescribimos todo en Go, ya que está justificado.