Spring es un potente marco de Java de código abierto. Decidí decirle para qué tareas es útil el backend de Spring y cuáles son sus ventajas y desventajas en comparación con otras bibliotecas: Guice y Dagger 2. Considere la inyección de dependencia y la inversión de control: aprenderá cómo comenzar a estudiar estos principios.
- Hola a todos, mi nombre es Cyril. Hoy hablaré sobre la inyección de dependencia.
Comenzaremos con lo que se llama mi informe. "En cierto reino, no en un" estado "de primavera". Hablaremos, por supuesto, sobre Spring, pero también quiero ver todo lo que está además de él. ¿De qué hablaremos específicamente?

Haré una pequeña digresión: te diré en qué estoy trabajando, cuál es mi proyecto, por qué usamos la inyección de dependencia. Luego le diré de qué se trata, compare Inversion of Control y Dependency Injection, y hable sobre su implementación en las tres bibliotecas más famosas.
Trabajo en el equipo de Yandex.Tracker. Hacemos un análogo de supermercado de Jira o Trello. [...] Decidimos hacer nuestro propio producto, que primero fue interno. Ahora lo estamos vendiendo. Cada uno de ustedes puede ingresar, crear su propio Rastreador y realizar tareas, por ejemplo, educativas o comerciales.
Veamos la interfaz. En los ejemplos, usaré algunos términos de mi área. Intentaremos crear un ticket y mirar los comentarios que otros colegas me dejarán en él.
Para empezar, ¿qué es la inyección de dependencia en general? Este es un patrón de programación que cumple con el viejo dicho estadounidense, el principio de Hollywood: "No nos llame, lo llamaremos nosotros mismos". Las dependencias mismas vienen a nosotros. Esto es principalmente un patrón, no una biblioteca. Por lo tanto, en principio, este patrón es común en casi todas partes. Incluso podría decir que todas las aplicaciones usan la inyección de dependencia de una forma u otra.

Veamos cómo puede crear usted mismo la inyección de dependencia si comenzamos desde cero. Supongamos que decidí desarrollar una clase tan pequeña en la que crearé un ticket a través de nuestra API. Por ejemplo, cree una instancia de la clase TrackerApi. Tiene un método createTicket en el que le enviaremos mi correo electrónico. Crearemos un ticket desde mi cuenta con el nombre: "Preparar un informe para Java Meetup".

Veamos la implementación de TrackerApi. Aquí, por ejemplo, podemos hacer esto: crear una instancia de httpClient. En términos simples, crearemos un objeto a través del cual iremos a la API. A través de este objeto llamaremos al método execute en él.

Por ejemplo, uno personalizado. Escribí código externo de estas clases, y lo usará de forma similar a esto. Creo un nuevo TicketCreator y llamo al método createTicket en él.

Aquí hay un problema: cada vez que creamos un ticket, recrearemos y volveremos a crear httpClient, aunque, en términos generales, no es necesario. Los httpClients son muy serios de crear.

Intentemos hacerlo. Aquí puede ver el primer ejemplo de inyección de dependencia en nuestro código. Presta atención a lo que hemos hecho. Sacamos nuestra variable en el campo y la llenamos en el constructor. El hecho de que lo completemos en el constructor significa que las dependencias nos llegan. Esta es la primera inyección de dependencia.

Cambiamos la responsabilidad a los usuarios del código, por lo que ahora debemos crear un httpClient, pasándolo, por ejemplo, a TicketCreator.
Esto tampoco es muy bueno aquí, porque ahora, al llamar a este método, crearemos nuevamente httpClient cada vez.

Por lo tanto, nuevamente lo sacamos al campo. Y aquí, por cierto, hay un ejemplo no obvio de inyección de dependencia. Podemos decir que siempre creamos tickets debajo de mí (o debajo de otra persona). Crearemos cada objeto TicketCreator separado de diferentes usuarios.
Por ejemplo, este creará debajo de mí cuando lo creamos. Y la línea que pasamos al constructor también es Inyección de dependencias.

¿Cómo lo haremos ahora? Cree una nueva instancia de TrackerTicketCreator y llame al método. Ahora incluso podemos crear algún tipo de método personalizado que creará un ticket con texto personalizado para nosotros. Por ejemplo, cree un boleto "Contratar a un nuevo aprendiz".

Ahora intentemos ver cómo se vería nuestro código si quisiéramos leer los comentarios en este ticket de la misma manera, debajo de mí. Esto es sobre el mismo código. Llamaríamos al método getComments en este ticket.
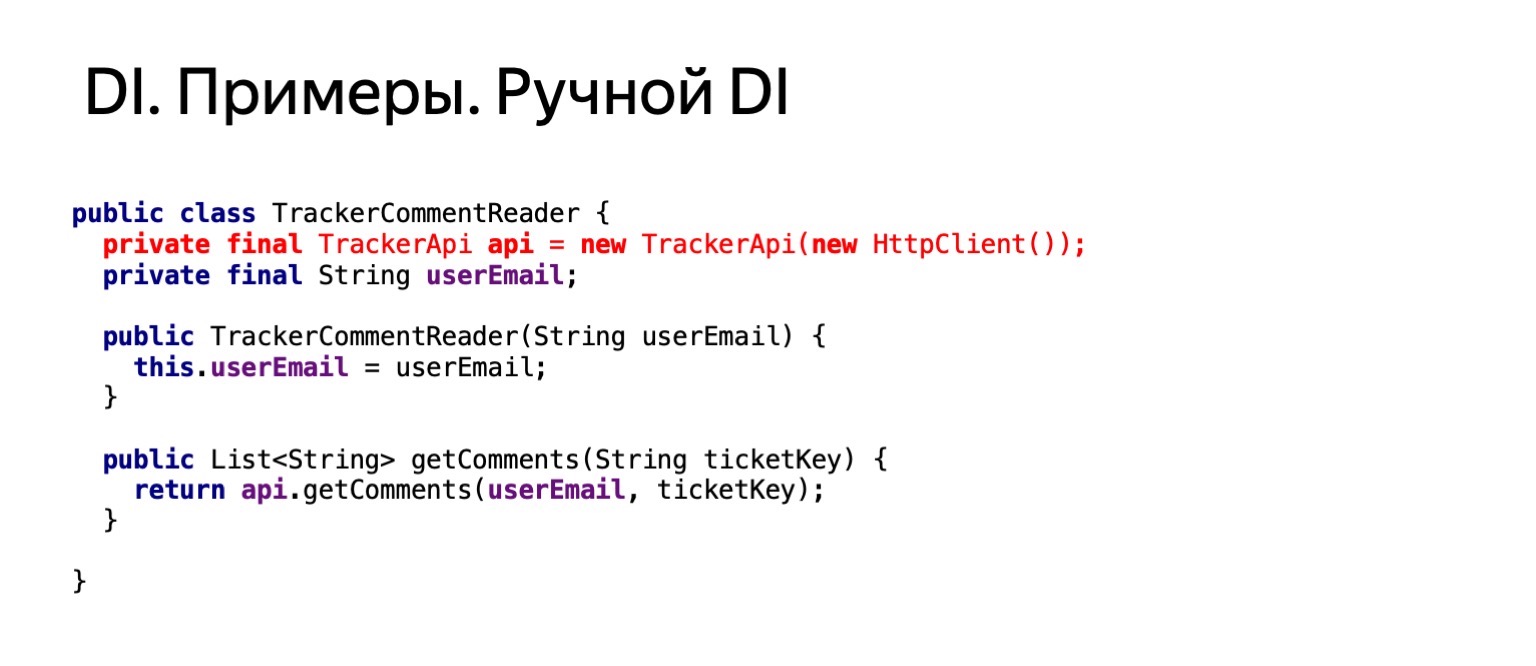
¿Cómo se vería él? Si tomamos y duplicamos esta funcionalidad en un lector de comentarios, duplicamos la creación de httpClient. Esto no nos conviene. Queremos deshacernos de eso.

Bueno Ahora reenviemos todos estos parámetros como Inyección de dependencias, como parámetros de constructor.

¿Cuál es el problema aquí? Nos saltamos todo, pero en el código de usuario ahora escribimos "repetitivo". Este es un tipo de código innecesario que un usuario generalmente necesita escribir para realizar una acción relativamente pequeña en términos de lógica. Aquí tendremos que crear constantemente httpClient, una API para ello y seleccionar el correo electrónico del usuario. Cada usuario de TicketCreator tendrá que hacer esto por sí mismo. Esto no esta bien. Ahora intentaremos ver cómo se verá en las bibliotecas cuando intentemos evitarlo.
Ahora, vamos a desviarnos un poco y veamos qué es la Inversión de control, porque muchos asocian la Inyección de dependencia con ella.

La inversión del control es un principio de programación en el que los objetos que utilizamos no son creados por nosotros. No afectamos su ciclo de vida en absoluto. Típicamente, la entidad que crea estos objetos se llama contenedor IoC. Muchos de ustedes han oído hablar de la primavera aquí. La documentación de Spring dice que las IoC también se conocen como inyección de dependencia. Ellos creen que esto es lo mismo.

¿Cuáles son los principios básicos? Los objetos no se crean por código de aplicación, sino por algún contenedor de IoC. Nosotros, como usuarios de la biblioteca, no hacemos nada, todo nos llega solo. Por supuesto, IoC es relativo. El contenedor IoC en sí crea estos objetos, y esto ya no es aplicable a él. Puede pensar que IoC implementa no solo bibliotecas DI. Las conocidas bibliotecas Java Servlets y Akka Actors, que ahora se utilizan en Scala y en el código Java.

Hablemos de bibliotecas. En términos generales, ya se han escrito muchas bibliotecas para Java y Kotlin. Voy a enumerar los principales:
- Primavera, un gran marco. Su parte principal es la inyección de dependencia o, como dicen, la inversión de control.
- Guice es una biblioteca que se escribió aproximadamente entre el segundo y el tercer Spring cuando Spring se mudó de XML a la descripción del código. Es decir, cuando la primavera todavía no era tan hermosa.
- Dagger es lo que suelen usar las personas en Android.
Intentemos reescribir nuestro ejemplo en primavera.

Teníamos nuestro TrackerApi. No incluí al usuario aquí para abreviar. Supongamos que intentamos en Dependency Injection para hacer httpClient. Para hacer esto, debemos declararlo con una anotación.
El componente , toda la clase, y específicamente el constructor, se declaran con la anotación
Autowired . ¿Qué significa esto para la primavera?

Tenemos dicha configuración en el código, se indica mediante la anotación de Escaneo de
componentes . Significa que intentaremos recorrer todo el árbol de nuestras clases en el paquete en el que está contenido. Y más hacia el interior, trataremos de encontrar todas las clases que están marcadas en la anotación
Componente .
Estos componentes caerán en el contenedor de IoC. Es importante para nosotros que todo se enamore de nosotros. Solo marcamos lo que queremos anunciar. Para que algo nos llegue, debemos declararlo usando la anotación
Autowired en el constructor.

TicketCreator lo marcamos exactamente de la misma manera.

Y CommentReader también.
Ahora echemos un vistazo a la configuración. Como dijimos, Component Scan colocará todo en un contenedor IoC. Pero hay un punto, el llamado método de fábrica. Tenemos el método httpClient, que no creamos como clase, porque httpClient nos llega desde la biblioteca. No comprende qué es Spring, etc., lo crearemos directamente en la configuración. Para hacer esto, escribimos un método que generalmente lo construye una vez y lo marcamos con la anotación Bean.

¿Cuáles son los pros y los contras? La ventaja principal: la primavera es muy común en el mundo. El siguiente más y menos es el escaneo automático. No deberíamos declarar explícitamente en ningún lugar que deseamos agregar un contenedor a IoC además de las anotaciones sobre las clases mismas. Suficientes anotaciones. Y el signo negativo es exactamente el mismo: si, por el contrario, queremos controlar esto, entonces Spring no nos proporciona esto. A menos que podamos decir en nuestro equipo: “No, no haremos eso. Debemos prescribir claramente algo en alguna parte. Solo en la configuración, como hicimos con los beans.
Además, debido a esto, se produce un inicio lento. Cuando se inicia la aplicación, Spring tiene que pasar por todas estas clases y descubrir qué poner en el contenedor de IoC. Lo ralentiza. El mayor inconveniente de Spring, me parece, es el árbol de dependencias. No se verifica en la etapa de compilación. Cuando Spring comienza en algún momento, necesita entender si tengo esa dependencia interna. Si más tarde resulta que no está en el árbol de dependencias, obtendrá un error en tiempo de ejecución. Y nosotros en Java no queremos un error de tiempo de ejecución. Queremos que el código se compile para nosotros. Esto significa que funciona.

Echemos un vistazo a Guice. Esta es una biblioteca que, como dije, se hizo entre la segunda y la tercera primavera. La belleza que vimos no era. Había XML. Para solucionar este problema, y fue escrito por Guice. Y aquí puede ver que, a diferencia de la configuración, estamos escribiendo un módulo. En él, declaramos explícitamente qué clases queremos poner en este módulo: TrackerAPI, TrackerTicketCreator y todos los demás contenedores. Un análogo a la anotación de Bean aquí es
Provides , que crea httpClient de la misma manera.

Necesitamos declarar cada uno de estos frijoles. Vamos a nombrar un ejemplo de
Singleton . Pero específicamente,
Singleton dirá que tal bean se creará exactamente una vez. No lo vamos a recrear constantemente. E
Inject , respectivamente, es un análogo de
Autowired .

Una pequeña tableta con lo que pertenece.

¿Cuáles son los pros y los contras? Pros: es más simple, me parece, y comprensible que la versión XML de Spring. Inicio más rápido Y aquí vienen las desventajas: requiere una declaración explícita de los granos usados. Deberíamos haber escrito Bean. Pero, por otro lado, esto es una ventaja, como ya hemos dicho. Esta es una imagen especular de lo que tiene Spring. Por supuesto, es menos común que la primavera. Este es su menos natural. Y existe exactamente el mismo problema: el árbol de dependencias no se verifica en la etapa de compilación.
Cuando los chicos comenzaron a usar Guice para Android, se dieron cuenta de que aún les faltaba velocidad de lanzamiento. Por lo tanto, decidieron escribir un marco de inyección de dependencia más simple y primitivo que les permita iniciar rápidamente la aplicación, porque para Android es muy importante.

Aquí la terminología es la misma. Dagger tiene exactamente los mismos módulos que Guice. Pero ya están marcados con anotaciones, no como en el caso de la herencia de la clase. Por lo tanto, se mantiene el principio.
El único inconveniente es que siempre debemos indicar explícitamente en el módulo cómo se crean los beans. En Guice, podríamos crear frijoles dentro del propio frijol. No tuvimos que decir qué tipo de dependencias necesitábamos reenviar. Y aquí tenemos que decir esto explícitamente.

En Dagger, debido a que no desea hacer una entrada demasiado manual, existe el concepto de un componente. Un componente es algo que une módulos cuando queremos declarar un bin de un módulo para que pueda tomarse en otro módulo. Este es un concepto diferente. Un bean de un módulo puede "inyectar" un bean de otro módulo utilizando un componente.

Aquí se trata de la misma placa de resumen: lo que ha cambiado o no ha cambiado en el caso de Inject o módulos.

Cuales son las ventajas? Es incluso más simple que Guice. El lanzamiento es incluso más rápido que Guice. Y probablemente ya no será más rápido, porque Dagger abandonó por completo la reflexión. Esta es exactamente la parte de la biblioteca en Java que se encarga de observar el estado de un objeto, su clase y sus métodos. Es decir, obtener el estado en tiempo de ejecución. Por lo tanto, no utiliza la reflexión. Él no va y no analiza qué dependencias tiene alguien. Pero debido a esto, comienza muy rápido.
¿Cómo lo hace él? Usando la generación de código.
Si miramos hacia atrás, veremos el componente de interfaz. No implementamos ninguna implementación de esta interfaz, Dagger lo hace por nosotros. Y será posible seguir utilizando la interfaz en la aplicación.
Naturalmente, es muy común en el mundo de Android debido a esta velocidad. El árbol de dependencias se verifica inmediatamente en la compilación, porque no hay nada que verifiquemos diferidamente en tiempo de ejecución.
¿Cuáles son las desventajas? Él tiene menos oportunidades. Es más detallado que Guice y Spring.

Dentro de estas bibliotecas, surgió una iniciativa en Java: el llamado JSR-330. JSR es una solicitud para realizar un cambio en la especificación del idioma o complementarlo con algunas bibliotecas adicionales. Dicho estándar se propuso en base a Guice, y se agregaron anotaciones de
inyección a esta biblioteca. En consecuencia, Spring y Guice lo respaldan.
¿Qué conclusiones se pueden sacar? Java tiene muchas bibliotecas diferentes para DI. Y debe comprender por qué tomamos uno específico de ellos. Si tomamos Android, entonces ya no hay otra opción, usamos Dagger. Si vamos al mundo del backend, entonces ya estamos viendo lo que más nos conviene. Y para el primer estudio de Inyección de dependencia, me parece que Guice es mejor que Spring. No hay nada superfluo en ello. Puedes ver cómo funciona, sentir.
Para seguir estudiando, le sugiero que se familiarice con la documentación de todas estas bibliotecas y la composición de JSR:
-
primavera-
Guice-
Daga 2-
JSR-330Gracias