Desde la última publicación en el mundo del lenguaje Julia, sucedieron muchas cosas interesantes:
Al mismo tiempo, hay un notable aumento en el interés de los desarrolladores, que se expresa mediante abundantes evaluaciones comparativas:
Simplemente nos regocijamos con las herramientas nuevas y convenientes y continuamos estudiándolas. Esta noche se dedicará al análisis de texto, la búsqueda de un significado oculto en los discursos de los presidentes y la generación de texto en el espíritu del programador de Shakespeare y Julia, y para el postre, alimentamos una red recurrente de 40,000 pasteles.
Recientemente aquí en Habré se realizó la revisión de paquetes para Julia, lo que permitió llevar a cabo investigaciones en el campo de la PNL - Julia PNL. Procesamos textos . Entonces, comencemos con los negocios de inmediato y comencemos con el paquete TextAnalysis .
TextAnalisys
Deje que se proporcione texto, que representamos como un documento de cadena:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
Para un trabajo conveniente con una gran cantidad de documentos, es posible cambiar los campos, por ejemplo, los títulos, y también, para simplificar el procesamiento, podemos eliminar la puntuación y las letras mayúsculas:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
que le permite construir n-gramas despejados para palabras:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
Está claro que los signos de puntuación y las palabras con letras mayúsculas serán unidades separadas en el diccionario, lo que interferirá con una evaluación cualitativa de las ocurrencias de frecuencia de los términos específicos de nuestro texto, por lo tanto, los eliminamos. Para n-gramas, es fácil encontrar muchas aplicaciones interesantes, por ejemplo, se pueden usar para realizar búsquedas difusas en el texto , pero como solo somos turistas, nos las arreglaremos con ejemplos de juguetes, es decir, la generación de texto usando cadenas de Markov
Procházení modelového grafu
Una cadena de Markov es un modelo discreto de un proceso de Markov que consiste en un cambio en un sistema que solo tiene en cuenta su estado anterior (modelo). Hablando en sentido figurado, uno puede percibir esta construcción como un autómata celular probabilístico. N-gramos coexisten bastante con este concepto: cualquier palabra del léxico está asociada con cualquier otra conexión de diferentes grosores, que está determinada por la frecuencia de aparición de pares específicos de palabras (gramos) en el texto.

Cadena Markov para cuerda "ABABD"
La implementación del algoritmo en sí ya es una gran actividad para la noche, pero Julia ya tiene un maravilloso paquete Markovify , que fue creado solo para estos fines. Desplazándonos cuidadosamente por el manual en checo , procedemos a nuestras ejecuciones lingüísticas.
Romper texto en tokens (por ejemplo, palabras)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
Componemos un modelo de primer orden (solo se tienen en cuenta los vecinos más cercanos):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Luego procedemos a implementar la función de la frase generadora basada en el modelo provisto. De hecho, se necesita un modelo, una solución alternativa y la cantidad de frases que desea obtener:
Código function gensentences(model, fun, n) sentences = []
El desarrollador del paquete proporcionó dos funciones de derivación: walk y walk2 (la segunda funciona más tiempo, pero ofrece diseños más únicos), y siempre puede determinar su opción. Probémoslo:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Por supuesto, la tentación es genial para probar textos rusos, especialmente en versos blancos. Para el idioma ruso, debido a su complejidad, la mayoría de las frases son ilegibles. Además, como ya se mencionó , los caracteres especiales requieren un cuidado especial, por lo tanto, guardamos los documentos de los que se recopila el texto codificado en UTF-8 o utilizamos herramientas adicionales .
Siguiendo el consejo de su hermana, después de limpiar un par de libros de Oster de caracteres especiales y cualquier separador y establecer un segundo orden para n-gramos, obtuve el siguiente conjunto de unidades fraseológicas:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
Ella aseguró que fue por tal técnica que los pensamientos se construyeron en el cerebro femenino ... ejem, y quién soy yo para discutir ...
Analízalo
En el directorio del paquete TextAnalysis puede encontrar ejemplos de datos textuales, uno de los cuales es una colección de discursos de presidentes estadounidenses antes del congreso.

Código using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
Después de leer estos archivos y formar un cuerpo a partir de ellos, así como limpiarlo de la puntuación, revisaremos el vocabulario general de todos los discursos:
Código crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
Puede ser interesante ver qué documentos contienen palabras específicas, por ejemplo, eche un vistazo a cómo manejamos las promesas:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
o con frecuencias de pronombre:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
Así que probablemente científicos y periodistas de violación y hay una actitud perversa hacia los datos que se estudian.
Matrices
La semántica verdaderamente distributiva comienza cuando los textos, gramos y fichas se convierten en vectores y matrices .
Un término matriz de documentos ( DTM ) es una matriz que tiene un tamaño donde - el número de documentos en el caso, y - tamaño del diccionario de corpus, es decir El número de palabras (únicas) que se encuentran en nuestro corpus. En la fila i- ésima, la columna j- ésima de la matriz es un número: cuántas veces en el texto i -ésimo se encontró la palabra j- ésima.
Código dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Aquí las unidades originales son términos
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Espera un momento ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
Será necesario leer con más detalle ...
También puede extraer todo tipo de datos interesantes del término matrices. Decir la frecuencia de aparición de palabras específicas en documentos
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
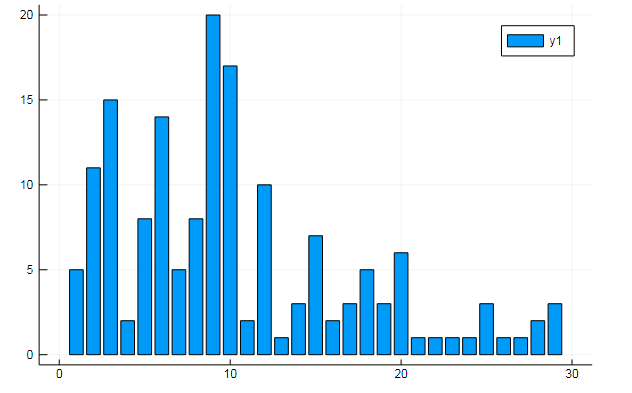
D[:, w1] |> bar
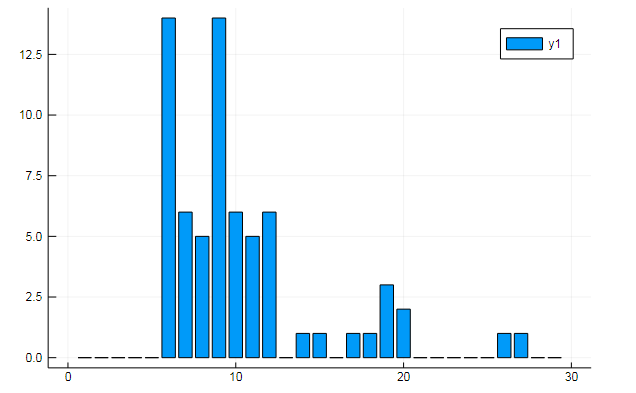
o similitud de documentos sobre algunos temas ocultos:
k = 3

Los gráficos muestran cómo se revela cada uno de los tres temas en los discursos.
o agrupar palabras por tema, o, por ejemplo, la similitud de vocabulario y la preferencia de ciertos temas en diferentes documentos
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
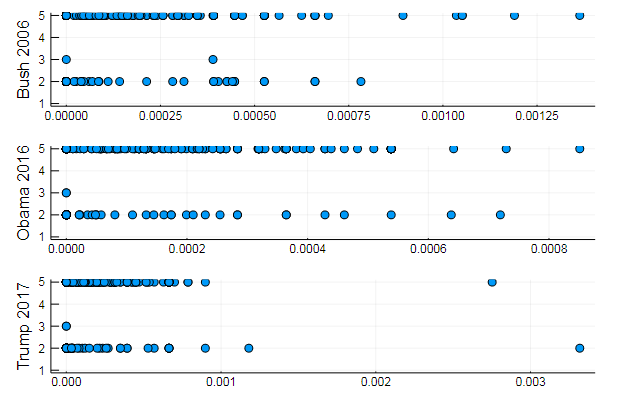
Resultados bastante naturales, actuaciones del mismo tipo. De hecho, la PNL es una ciencia bastante interesante, y puede extraer mucha información útil de datos correctamente preparados: puede encontrar muchos ejemplos en este recurso ( Reconocimiento del autor en los comentarios , el uso de LDA , etc.)
Bueno, para no ir muy lejos, generaremos frases para el presidente ideal:
Código function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Memoria a corto y largo plazo
Bueno, ¿cómo puede ser sin redes neuronales! Recolectan laureles en este campo con mayor velocidad, y el entorno del lenguaje Julia contribuye a esto en todos los sentidos. Para los curiosos, puede recomendar el paquete Knet , que, a diferencia del Flux que examinamos anteriormente , no funciona con arquitecturas de redes neuronales como constructor de módulos, sino que en su mayor parte funciona con iteradores y flujos. Esto puede ser de interés académico y contribuir a una comprensión más profunda del proceso de aprendizaje, y también proporciona computación de alto rendimiento. Al hacer clic en el enlace proporcionado anteriormente, encontrará orientación, ejemplos y material para el autoaprendizaje (por ejemplo, muestra cómo crear un generador de texto de Shakespeare o un código juliac en redes recurrentes). Sin embargo, algunas funciones del paquete Knet se implementan solo para la GPU, por lo tanto, por ahora, continuemos ejecutando Flux.
Uno de los ejemplos típicos del funcionamiento de las redes de recurrencia es a menudo el modelo de alimentación simbólica de los sonetos de Shakespeare:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
Si entrecierra los ojos y no sabe inglés, entonces la obra parece bastante real .

Es más fácil de entender en ruso.
Pero es mucho más interesante probar lo grandioso y poderoso, y aunque es muy difícil desde el punto de vista léxico, puede usar literatura más primitiva como datos, es decir, más recientemente conocida como la corriente de vanguardia de la poesía moderna: las rimas.
Recogida de datos
Empanadas y polvos: cuartetas rítmicas, a menudo sin rima, escritas en minúsculas y sin signos de puntuación.
La elección recayó en el sitio poetory.ru en el que el camarada administrador hior . La larga falta de respuesta a la solicitud de datos fue la razón para comenzar a estudiar el análisis del sitio. Un rápido vistazo al tutorial HTML le brinda una comprensión rudimentaria del diseño de páginas web. A continuación, encontramos los medios del lenguaje Julia para trabajar en tales áreas:
- HTTP.jl : funcionalidad de cliente y servidor HTTP para Julia
- Gumbo.jl : análisis de diseños html y no solo
- Cascadia.jl - Paquete auxiliar para Gumbo

Luego implementamos un guión que pasa las páginas de la poesía y guarda los pasteles en un documento de texto:
Código using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
Con más detalle, se desmonta en un cuaderno de Júpiter . Recojamos los pasteles y la pólvora en una sola línea:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
Y mira el alfabeto usado:
prod(sort([unique(str)..., '_']) )

Verifique los datos descargados antes de comenzar el proceso.
¡Ay, ah, qué desgracia! Algunos usuarios rompen las reglas (a veces las personas simplemente se expresan haciendo ruido en estos datos). Entonces limpiaremos nuestra caja de símbolos de la basura
str = lowercase(str)
Como lo aconseja rssdev10, el código se modifica usando expresiones regulares
Tengo un conjunto de caracteres más aceptable. La mayor revelación de hoy es que, desde el punto de vista del código de máquina, hay al menos tres espacios diferentes: es difícil para los cazadores de datos vivir.

Ahora puede conectar Flux con la presentación posterior de los datos en forma de vectores onehot:
Flux entra en juego using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
Configuramos el modelo a partir de un par de capas LSTM, un perceptrón y softmax totalmente conectados, así como pequeñas cosas cotidianas, y para la función de pérdida y el optimizador:
Código m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
El modelo está listo para la capacitación, por lo que al ejecutar la línea a continuación, puede ocuparse de su propio negocio, cuyo costo se selecciona de acuerdo con la potencia de su computadora. En mi caso, estas son dos conferencias sobre filosofía que, por alguna maldita cosa, nos fueron entregadas tarde en la noche ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Una vez ensamblado un generador de muestras, puede comenzar a cosechar los beneficios de sus trabajos.
generador de barmaglot function sample(m, alphabet, len)
Ligera decepción debido a las expectativas un poco altas. Aunque la red solo tiene una secuencia de caracteres en la entrada y solo puede operar con las frecuencias de su reunión, una tras otra, captó completamente la estructura del conjunto de datos, destacó algunas palabras y, en algunos casos, incluso mostró la capacidad de mantener el ritmo. Posiblemente, la identificación de la afinidad semántica ayudará a mejorar.

Los pesos de una red capacitada pueden guardarse en el disco y luego leerse fácilmente
weights = Tracker.data.(params(model)); using BSON: @save
Con la prosa, también, solo sale la psicodelia cibernética abstracta. Hubo intentos de mejorar la calidad del ancho y la profundidad de la red, así como la diversidad y abundancia de datos. Para el cuerpo de texto dado, gracias especiales al mayor divulgador del idioma ruso

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
Pero si entrenas una red neuronal en el código fuente del lenguaje Julia, entonces resulta bastante bueno:
Además de la posibilidad de metaprogramación , obtenemos un programa que escribe y ejecuta, ¡tal vez incluso nuestro propio código! Bueno, o será un regalo del cielo para los diseñadores de películas sobre hackers .
En general, el comienzo se ha hecho, y luego ya como lo indica la fantasía. En primer lugar, debe obtener equipos de alta calidad para que los cálculos largos no repriman el deseo de experimentar. En segundo lugar, necesitamos estudiar los métodos y la heurística más profundamente, lo que nos permitirá diseñar modelos mejores y más optimizados. En este recurso, es suficiente encontrar todo lo relacionado con el procesamiento del lenguaje natural, después de lo cual es bastante posible enseñar a su red neuronal cómo generar poesía o ir a un hackathon para el análisis de texto .
En esto, déjame despedirme. ¡Datos para entrenar en la nube , listados en el github , fuego en los ojos, un huevo en un pato y buenas noches a todos!