En mi
artículo anterior hablé sobre la experiencia de usar el motor
Gemini para desarrollar pruebas visuales, o más bien, pruebas de regresión visual. Dichas pruebas verifican si algo se ha "movido" en la interfaz de usuario después de los siguientes cambios comparando las capturas de pantalla actuales con las de referencia fijadas anteriormente. Desde entonces, mucho ha cambiado en nuestros enfoques para escribir pruebas visuales, incluido el motor utilizado. Ahora usamos a
Hermione , pero en este artículo voy a contar no solo y no tanto sobre Hermione, sino también sobre los problemas que se han acumulado desde entonces y cómo resolverlos, lo que, entre otras cosas, condujo a la transición a un nuevo motor.
En primer lugar, aunque las pruebas funcionaron, y con bastante éxito, no teníamos una comprensión clara de lo que estaba cubierto por las pruebas y lo que no. Había, por supuesto, alguna idea del grado de cobertura, pero no lo medimos cuantitativamente. En segundo lugar, la composición de las pruebas aumentó con el tiempo y diferentes pruebas a menudo probaron lo mismo, porque en diferentes capturas de pantalla, alguna parte coincidió con la misma parte, pero en una captura de pantalla diferente. Como resultado, incluso cambios menores en CSS podrían abrumar muchas pruebas a la vez y requerir la actualización de una gran cantidad de estándares. En tercer lugar, apareció un tema oscuro en nuestro producto, y para cubrirlo de alguna manera con pruebas, algunas pruebas se cambiaron selectivamente para usar un tema oscuro, que tampoco agregó claridad al problema con la determinación del grado de cobertura.
Optimización del rendimiento
Comenzamos, curiosamente, con un rendimiento optimizado. Explicaré por qué. Nuestras pruebas visuales se basan en el
libro de cuentos . Cada historia en el libro de cuentos no es un componente único, sino un "bloque" completo (por ejemplo, una cuadrícula con una lista de entidades, una tarjeta de entidad, diálogo o incluso la aplicación en su conjunto). Para mostrar este bloque, debe "bombear" la historia con datos, no solo los datos que se muestran al usuario, sino también el estado de los componentes utilizados dentro del bloque. Esta información se almacena junto con el código fuente en forma de archivos json que contienen una representación serializada del estado de la aplicación (tienda redux). Sí, esta información es, por decirlo suavemente, redundante, pero simplifica enormemente la creación de pruebas. Para crear una nueva prueba, simplemente abrimos la tarjeta, lista o cuadro de diálogo deseados en la aplicación, tomamos una instantánea del estado actual de la aplicación y la serializamos en un archivo. Luego agregamos una nueva historia y pruebas que toman capturas de pantalla de esta historia (todo en unas pocas líneas de código).
Este enfoque inevitablemente aumenta el tamaño del paquete. El grado de duplicación de datos en él simplemente "se transfiere". Al ejecutar pruebas, el motor gemini ejecuta cada conjunto de pruebas en una sesión de navegador separada. Cada sesión carga el paquete de nuevo y el tamaño del paquete en dicho esquema está lejos del último valor.
Para reducir el tiempo de ejecución de la prueba, redujimos el número de conjuntos de pruebas aumentando el número de pruebas en ellos. Por lo tanto, un conjunto de pruebas podría afectar varias historias a la vez. En este esquema, prácticamente perdimos la capacidad de "filtrar" solo un área determinada de la pantalla debido al hecho de que Gemini le permite configurar el área de captura de pantalla solo para el conjunto de pruebas en su conjunto (aunque la API le permite hacer esto antes de cada captura de pantalla, pero en la práctica no funciona).
La incapacidad de limitar el área de la captura de pantalla en las pruebas condujo a la duplicación de información visual en las imágenes de referencia. Si bien no hubo muchas pruebas, este problema no parecía significativo. Sí, y la IU no cambió muy a menudo. Pero esto no podría continuar para siempre: un rediseño se avecinaba en el horizonte.
Mirando hacia el futuro, diré que en Hermione se puede establecer un área de captura de pantalla para cada disparo y, a primera vista, cambiar a un nuevo motor resolvería todos los problemas. Pero aún tendríamos que "aplastar" grandes conjuntos de pruebas. El hecho es que las pruebas visuales no son inherentemente estables (esto puede deberse a varias razones, por ejemplo, con retrasos en la red, el uso de animaciones o con "clima en Marte") y es muy difícil hacerlo sin reintentos automáticos. Tanto Gemini como Hermione realizan reintentos para el conjunto de pruebas en su conjunto, y cuanto más "grueso" sea el conjunto de pruebas, es menos probable que se complete con éxito durante los reintentos, ya que en la próxima ejecución, las pruebas que se completaron con éxito anteriormente pueden caer. Para las suites de prueba gruesas, tuvimos que implementar un esquema de reintento alternativo integrado en el motor Gemini y realmente no queríamos hacer esto nuevamente al cambiar a un nuevo motor.
Por lo tanto, para acelerar la carga del conjunto de pruebas, dividimos el paquete monolítico en partes, asignando cada instantánea del estado de la aplicación en una "pieza" separada, cargada "a pedido" para cada historia por separado. El código de creación de la historia ahora se ve así:
Para crear una historia, se utiliza el componente StoryProvider (su código se proporcionará a continuación). Las instantáneas se cargan mediante la función de
importación dinámica . Diferentes historias difieren entre sí solo en imágenes de estados. Para un tema oscuro, se genera su propia historia, utilizando la misma instantánea que la historia para un tema claro. En el contexto de un libro de cuentos, se ve así:
Historia del tema predeterminado El componente StoryProvider acepta una devolución de llamada para cargar una instantánea en la que se llama a la función import (). La función import () funciona de forma asíncrona, por lo que no puede tomar una captura de pantalla inmediatamente después de cargar la historia; nos arriesgamos a eliminar el vacío. Para captar el momento del final de la descarga, el proveedor presenta el elemento DOM marcador que indica al motor de prueba durante todo el tiempo de la descarga, que debe retrasarse con la captura de pantalla:
Además, para reducir el tamaño del paquete, deshabilite la adición de mapas de origen al paquete. Pero para no perder la capacidad de depurar la historia (nunca se sabe qué), hacemos esto bajo la condición:
.storybook / webpack.config.js El
script npm run build-storybook compila un libro de cuentos estático sin mapa de origen en la carpeta estática del libro de cuentos. Se utiliza al realizar pruebas. Y el
script npm run storybook se usa para desarrollar y depurar historias de prueba.
Eliminación de la duplicación de información visual.
Como dije anteriormente, Gemini le permite establecer selectores de área de captura de pantalla para el conjunto de pruebas en su conjunto, lo que significa que para resolver completamente el problema de duplicar la información visual en las capturas de pantalla, tendríamos que hacer nuestro propio conjunto de pruebas para cada captura de pantalla. Incluso teniendo en cuenta la optimización de cargar la historia, no parecía demasiado optimista en términos de velocidad y pensamos en cambiar el motor de prueba.
En realidad, ¿por qué Hermione? Actualmente, el repositorio Gemini está marcado como obsoleto y, tarde o temprano, tuvimos que "movernos" a algún lado. La estructura del archivo de configuración de Hermione es idéntica a la estructura del archivo de configuración de Gemini y pudimos reutilizar esta configuración. Los complementos de Géminis y Hermione también son comunes. Además, pudimos reutilizar la infraestructura de prueba: máquinas virtuales y red de selenio implementada.
A diferencia de Gemini, Hermione no se posiciona como una herramienta solo para pruebas de regresión del diseño. Sus capacidades de manipulación del navegador son mucho más amplias y limitadas solo por las capacidades de
Webdriver IO . En combinación con
mocha, este motor es conveniente para usar más para pruebas funcionales (simulación de acciones del usuario) que para pruebas de diseño. Para las pruebas de regresión del diseño, Hermione proporciona solo el método ClaimView (), que compara una captura de pantalla de una página del navegador con una referencia. La captura de pantalla se puede limitar al área especificada mediante los selectores CSS.
Para nuestro caso, la prueba para cada historia individual se vería así:
El método waitForVisible (), a pesar de su nombre, le permite esperar no solo la apariencia, sino también la ocultación del elemento, si establece el segundo parámetro en verdadero. Aquí lo usamos para esperar a que se oculte un elemento marcador, lo que indica que la instantánea de datos aún no está cargada y la historia aún no está lista para una captura de pantalla.
Si intenta encontrar el método waitForVisible () en la documentación de Hermione, no encontrará nada. El hecho es que el
método waitForVisible ()
es el método Webdriver IO API . El método url (), respectivamente, también. En el método url (), pasamos la dirección del marco de una historia en particular, no el libro de cuentos completo. En primer lugar, esto es necesario para que la lista de historias no se muestre en la ventana del navegador; no necesitamos probarla. En segundo lugar, si es necesario, podemos tener acceso a elementos DOM dentro del marco (los métodos webdriverIO le permiten ejecutar código JavaScript en un contexto de navegador).
Para simplificar la escritura de pruebas, creamos nuestro contenedor sobre las pruebas de mocha. El hecho es que no tiene un sentido particular en la elaboración detallada de casos de prueba para pruebas de regresión. Todos los casos de prueba son iguales: "debería ser igual a etalon". Bueno, tampoco quiero duplicar el código para esperar la carga de datos en cada prueba. Por lo tanto, el mismo trabajo para todas las pruebas "mono" se delega a la función de envoltura, y las pruebas mismas se escriben de manera declarativa (bueno, casi). Aquí está el texto de esta función:
create-test-suite.js const themes = [ 'default', 'dark' ]; const rootClassName = '.explorer'; const loadingStubClassName = '.loading-stub'; const timeout = 2000; function createTestSuite(testSuite) { const { name, storyName, browsers, testCases, selector } = testSuite;
Un objeto que describe el conjunto de pruebas se pasa a la entrada de la función. Cada conjunto de pruebas se construye de acuerdo con el siguiente escenario: tome una captura de pantalla del diseño principal (por ejemplo, un área de una tarjeta de entidad o un área de una lista de entidades), luego presione programáticamente los botones que pueden dar lugar a la aparición de otros elementos (por ejemplo, paneles emergentes o menús contextuales) y “tome una captura de pantalla »Cada uno de esos elementos por separado. Por lo tanto, simulamos acciones del usuario en el navegador, pero no con el objetivo de probar un escenario empresarial, sino simplemente para "capturar" el máximo número posible de componentes visuales. Además, la duplicación de información visual en las capturas de pantalla es mínima, porque las capturas de pantalla se toman "puntiagudas" utilizando selectores. Ejemplo de suite de prueba:
Determinación de cobertura
Entonces, descubrimos la velocidad y la redundancia, queda por determinar la efectividad de nuestras pruebas, es decir, determinar el grado de cobertura del código con las pruebas (aquí por código me refiero a las hojas de estilo CSS).
Para las historias de prueba, seleccionamos empíricamente las tarjetas, listas y otros elementos más complicados para llenar para cubrir tantos estilos como sea posible con una captura de pantalla. Por ejemplo, para probar una tarjeta de entidad, se seleccionaron tarjetas con una gran cantidad de diferentes tipos de controles (texto, número, transferencias, fechas, cuadrículas, etc.). Las tarjetas para diferentes tipos de entidades tienen sus propios detalles, por ejemplo, desde una tarjeta de documentos puede mostrar un panel con una lista de versiones de documentos, y la tarjeta de tareas muestra la correspondencia para esta tarea. En consecuencia, para cada tipo de entidad, se creó su propia historia y un conjunto de pruebas específicas para este tipo, etc. Al final, pensamos que todo parecía estar cubierto con pruebas, pero queríamos un poco más de confianza que "me gusta".
Para evaluar la cobertura en Chrome DevTools, hay una herramienta con el nombre Cobertura muy adecuada para este caso:
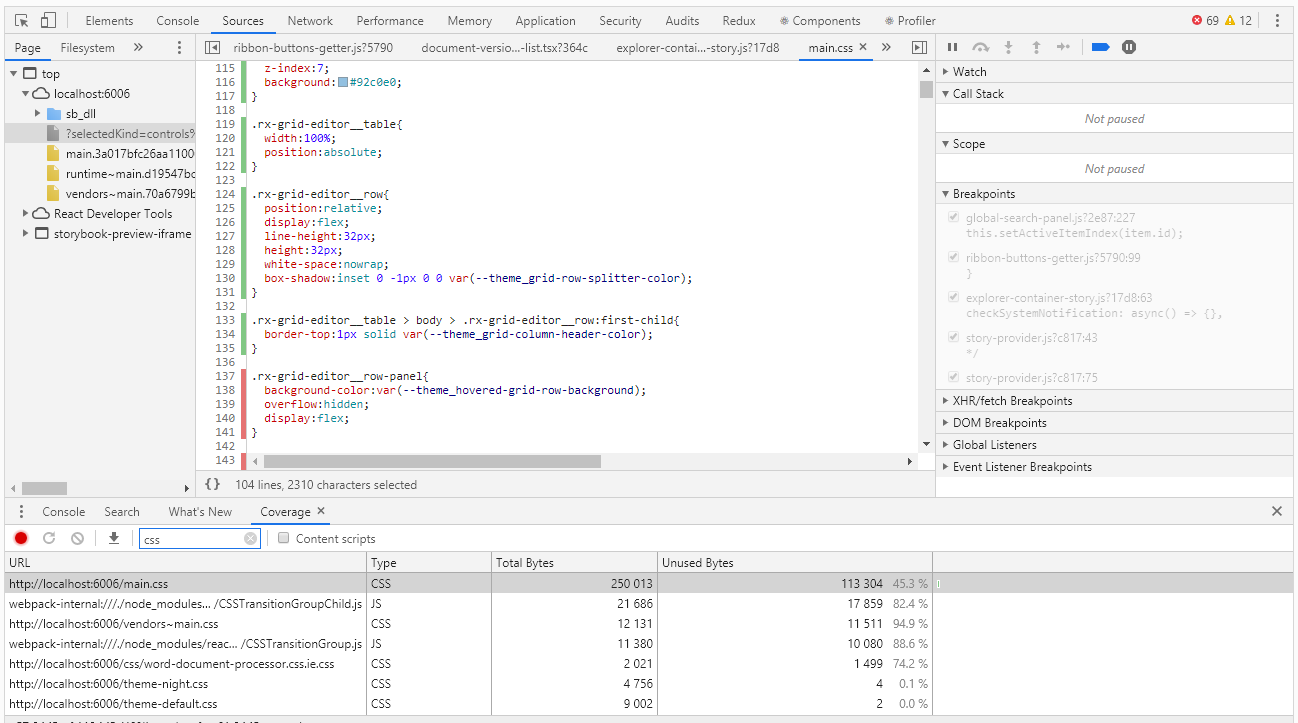
La cobertura le permite determinar qué estilos o qué código js se utilizó al trabajar con la página del navegador. El informe sobre el uso de rayas verdes indica el código utilizado, rojo - no utilizado. Y todo estaría bien si tuviéramos una aplicación del nivel "hola, mundo", pero ¿qué hacer cuando tenemos miles de líneas de código? Los desarrolladores de cobertura lo entendieron bien y proporcionaron la capacidad de exportar el informe a un archivo que ya se puede resolver mediante programación.
Debo decir de inmediato que hasta ahora no hemos encontrado una manera de cobrar el grado de cobertura automáticamente. Teóricamente, esto se puede hacer usando el navegador sin cabeza de Pupeteer, pero Pupeteer no funciona bajo el control de selenio, lo que significa que no podremos reutilizar el código de nuestras pruebas. Entonces, por ahora, omita este tema extremadamente interesante y trabajemos con bolígrafos.
Después de ejecutar las pruebas en modo manual, obtenemos un informe de cobertura, que es un archivo json. En el informe para cada css, js, ts, etc. el archivo indica su texto (en una línea) y los intervalos del código utilizado en este texto (en forma de índices de caracteres de esta línea). A continuación se muestra una parte del informe:
cobertura.json [ { "url": "http://localhost:6006/theme-default.css", "ranges": [ { "start": 0, "end": 8127 } ], "text": "... --theme_primary-accent: #5b9bd5;\r\n --theme_primary-light: #ffffff;\r\n --theme_primary: #f4f4f4;\r\n ..." }, { "url": "http://localhost:6006/main.css", "ranges": [ { "start": 0, "end": 610 }, { "start": 728, "end": 754 } ] "text": "... \r\n line-height:1;\r\n}\r\n\r\nol, ul{\r\n list-style:none;\r\n}\r\n\r\nblockquote, q..." ]
A primera vista, no hay nada difícil en encontrar selectores CSS no utilizados. Pero entonces, ¿qué hacer con esta información? De hecho, en el análisis final, necesitamos encontrar no selectores específicos, sino componentes que olvidamos cubrir con las pruebas. Los estilos de un componente pueden ser configurados por más de una docena de selectores. Como resultado, de acuerdo con los resultados del análisis del informe, obtenemos cientos de selectores no utilizados, y si trata con cada uno de ellos, puede matar mucho tiempo.
Aquí, las expresiones regulares nos ayudan. Por supuesto, solo funcionarán si se cumplen las convenciones de nomenclatura para las clases css (en nuestro código, las clases css se nombran de acuerdo con la metodología BEM - block_name_name_name_modifier). Usando expresiones regulares, calculamos los valores únicos de los nombres de bloque, que ya no son difíciles de asociar con los componentes. Por supuesto, también estamos interesados en elementos y modificadores, pero no en primer lugar, primero debemos tratar con un "pez" más grande. A continuación se muestra una secuencia de comandos para procesar un informe de cobertura
cobertura.js const modules = require('./coverage.json').filter(e => e.url.endsWith('.css')); function processRange(module, rangeStart, rangeEnd, isUsed) { const rules = module.text.slice(rangeStart, rangeEnd); if (rules) { const regex = /^\.([^\d{:,)_ ]+-?)+/gm; const classNames = rules.match(regex); classNames && classNames.forEach(name => selectors[name] = selectors[name] || isUsed); } } let previousEnd, selectors = {}; modules.forEach(module => { previousEnd = 0; for (const range of module.ranges) { processRange(module, previousEnd, range.start, false); processRange(module, range.start, range.end, true); previousEnd = range.end; } processRange(module, previousEnd, module.length, false); }); console.log('className;isUsed'); Object.keys(selectors).sort().forEach(s => { console.log(`${s};${selectors[s]}`); });
Ejecutamos el script colocando primero el archivo coverage.json exportado desde Chrome DevTools y escribiendo el escape en un archivo .csv:
Nodo cobertura.js> cobertura.csvPuede abrir este archivo con Excel y analizar los datos, incluida la determinación del porcentaje de cobertura de código por pruebas.

En lugar de un curriculum vitae
Usar el libro de cuentos como base para las pruebas visuales se ha justificado por completo: tenemos un grado suficiente de cobertura del código CSS con pruebas con un número relativamente pequeño de historias y costos mínimos para crear nuevas.
La transición a un nuevo motor nos permitió eliminar la duplicación de información visual en las capturas de pantalla, lo que simplificó enormemente el soporte de las pruebas existentes.
El grado de cobertura del código CSS se puede medir y, de vez en cuando, se supervisa. Por supuesto, hay una gran pregunta: cómo no olvidar la necesidad de este control y cómo no perder algo en el proceso de recopilación de información sobre la cobertura. Idealmente, me gustaría medir el grado de cobertura automáticamente en cada ejecución de prueba, de modo que cuando se alcanza el umbral especificado, las pruebas caerían con un error. Trabajaremos en esto, si hay noticias, definitivamente te lo diré.