Infa será útil para los desarrolladores de JS que desean comprender profundamente la esencia de trabajar con Node.js y Event Loop. Puede controlar de manera más consciente y flexible el flujo del programa (servidor web).
Compilé este artículo basado en mi reciente informe a colegas.
Al final del artículo hay materiales útiles para estudio independiente.
¿Cómo es Node.js. Características asincrónicas
Veamos este código: demuestra perfectamente la sincronización de la ejecución del código en Node.js. Se realiza una solicitud en algún lugar de GitHub, luego se lee un archivo y el resultado se muestra en la consola. ¿Qué queda claro de este código síncrono?
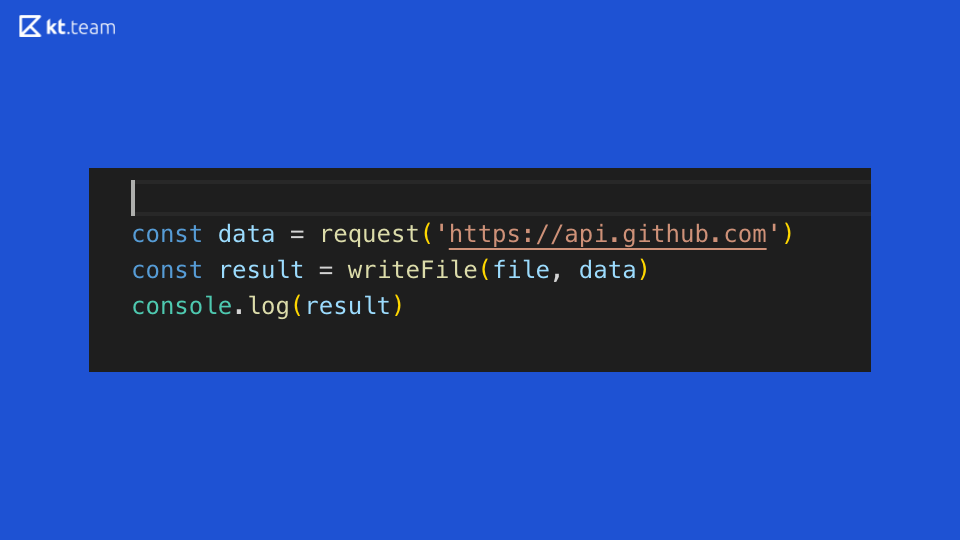
Supongamos que este es un servidor web abstracto que realiza operaciones en un enrutador. Si llega una solicitud entrante en este enrutador, hacemos una solicitud adicional, leemos el archivo e lo imprimimos en la consola. En consecuencia, el tiempo que se dedica a solicitar y leer un archivo, el servidor se bloqueará, no podrá procesar ninguna otra solicitud entrante, ni realizará otras operaciones.
¿Cuáles son las opciones para resolver este problema?
- Multithreading
- E / S sin bloqueo
Para la primera opción (multiproceso) hay un buen ejemplo con el servidor web Apache vs Nginx.
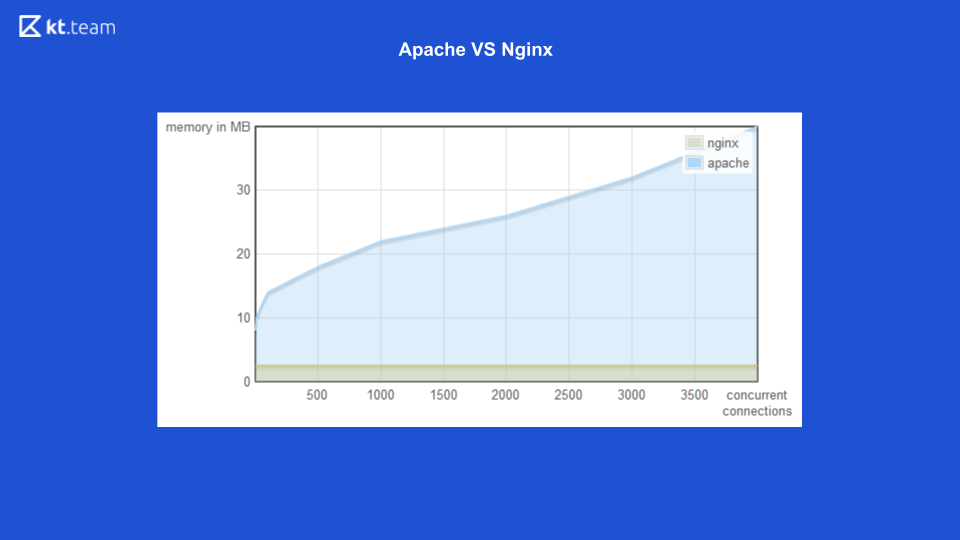
Anteriormente, Apache generaba una secuencia para cada solicitud entrante: cuántas solicitudes había, la misma cantidad de subprocesos. En este momento, Nginx tenía la ventaja de usar E / S sin bloqueo. Aquí puede ver que con un aumento en el número de solicitudes entrantes, la cantidad de memoria consumida por Apache aumenta, y en la siguiente diapositiva, el número de solicitudes procesadas por segundo con el número de conexiones para Nginx es mayor.
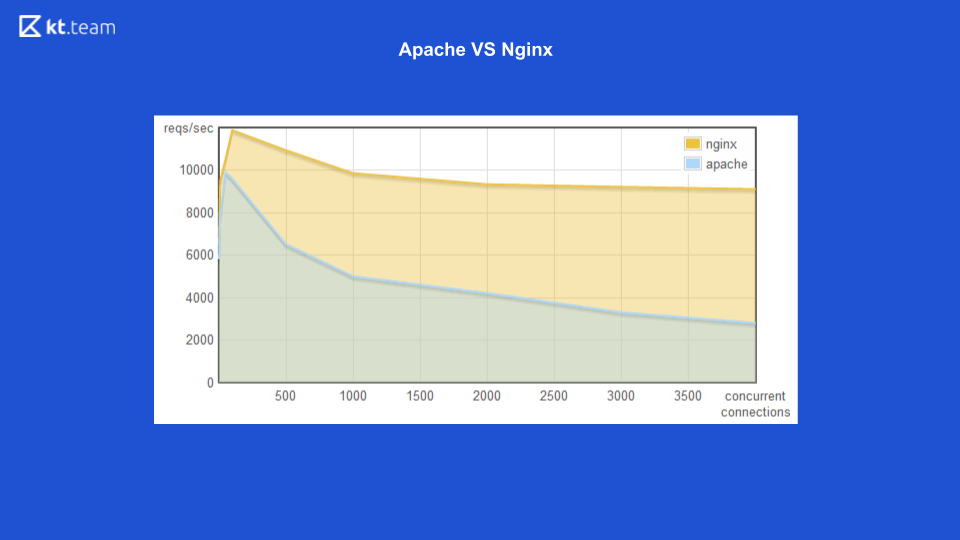
Se muestra claramente que la entrada / salida sin bloqueo es más eficiente.
La entrada / salida sin bloqueo es posible gracias a los modernos sistemas operativos que proporcionan este mecanismo: un demultiplexor de eventos.
Un demultiplexor es un mecanismo que recibe una solicitud de una aplicación, la registra y la ejecuta.
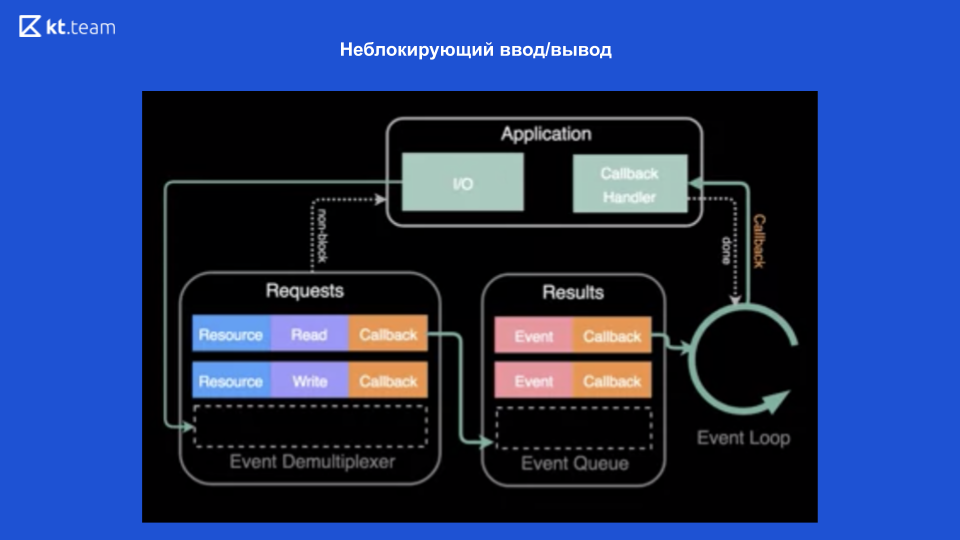
En la parte superior del diagrama, se ve que tenemos una aplicación y se realizan operaciones en ella (deje que se lea un archivo). Para hacer esto, se realiza una solicitud al demultiplexor de eventos, se envía un recurso aquí (enlace al archivo), la operación deseada y la devolución de llamada. El evento demultiplexor registra esta solicitud y devuelve el control directamente a la aplicación, por lo tanto, no está bloqueado. Luego realiza operaciones en el archivo, y después de eso, cuando se lee el archivo, la devolución de llamada se registra en la cola de ejecución. Luego, el bucle de eventos procesa de forma gradual y sincrónica cada devolución de llamada desde esta cola. Y, en consecuencia, devuelve el resultado a la aplicación. Además (si es necesario) todo se vuelve a hacer.
Por lo tanto, gracias a esta E / S sin bloqueo, Node.js puede ser asíncrono.
Aclararé que en este caso, es el sistema operativo el que nos proporciona entrada / salida sin bloqueo. Para entrada / salida sin bloqueo (generalmente, en principio, para operaciones de entrada / salida) incluimos solicitudes de red y trabajamos con archivos.
Este es el concepto general de E / S sin bloqueo. Cuando surgió la oportunidad, Ryan Dahl, desarrollador de Node.js, se inspiró en la experiencia Nginx, que utilizaba E / S sin bloqueo, y decidió crear una plataforma específicamente para desarrolladores. Lo primero que tenía que hacer era "hacer amigos" en su plataforma con un demultiplexor de eventos. El problema fue que el demultiplexor se implementó de manera diferente en cada sistema operativo, y tuvo que escribir un contenedor, que más tarde se conoció como libuv. Esta es una biblioteca escrita en C. Proporciona una interfaz única para trabajar con estos demultiplexores de eventos.
Características de la biblioteca Libuv
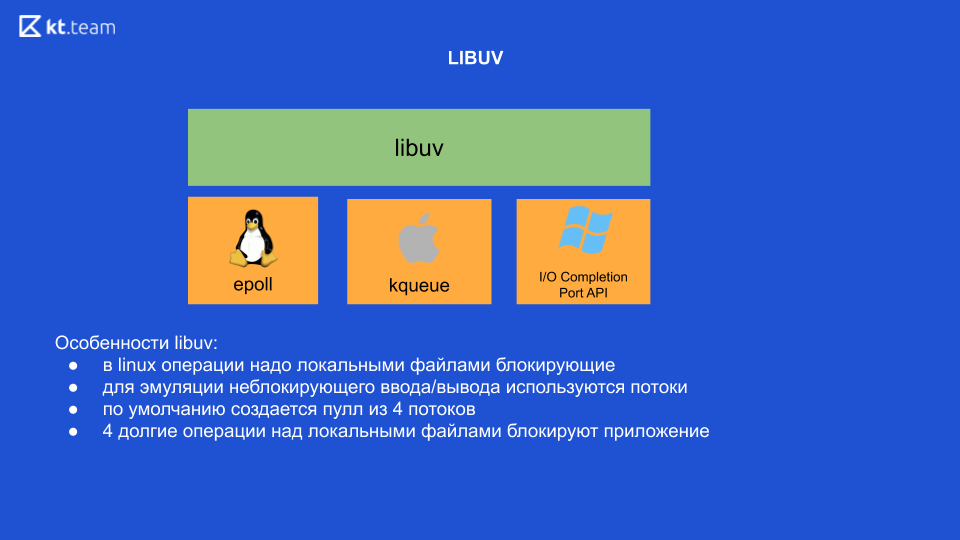
En Linux, en principio, en este momento, todas las operaciones con archivos locales están bloqueadas. Es decir, parece que hay entrada / salida sin bloqueo, pero es precisamente cuando se trabaja con archivos locales que la operación sigue bloqueando. Es por eso que libuv usa hilos internamente para emular E / S sin bloqueo. 4 subprocesos salen de la caja, y aquí debemos llegar a la conclusión más importante: si realizamos unas 4 operaciones pesadas en archivos locales, en consecuencia, bloquearemos toda nuestra aplicación (está en Linux, otros sistemas operativos no).
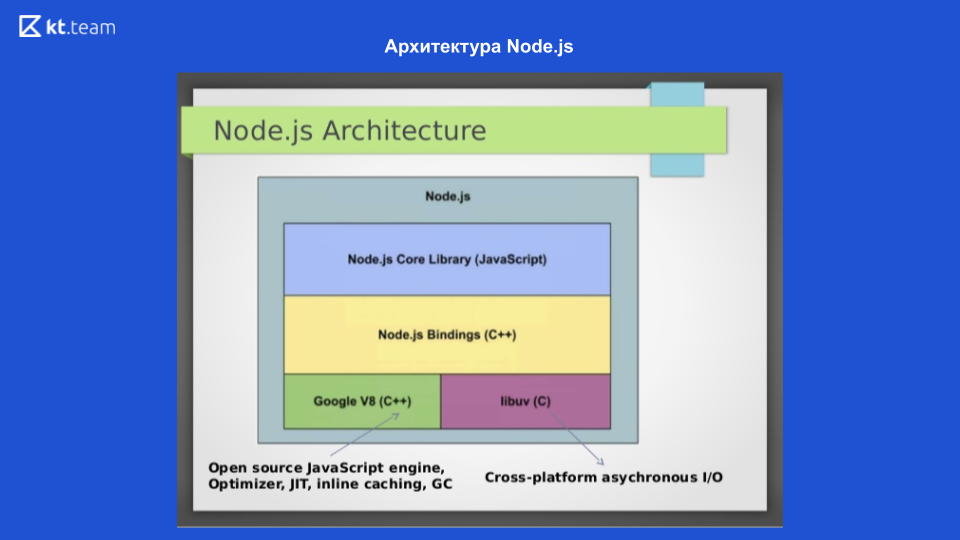
En esta diapositiva, vemos la arquitectura de Node.js. Para interactuar con el sistema operativo, se utiliza la biblioteca libuv escrita en C; Para compilar el código JavaScript en el código de la máquina, se utiliza el motor Google V8, también hay una biblioteca Node.js Core, que contiene módulos para trabajar con solicitudes de red, un sistema de archivos y un módulo para el registro. Que todo esto interactuó entre sí, se escriben enlaces Node.js. Estos 4 componentes conforman la estructura de Node.js. El mecanismo de Event Loop está en libuv.
Bucle de eventos
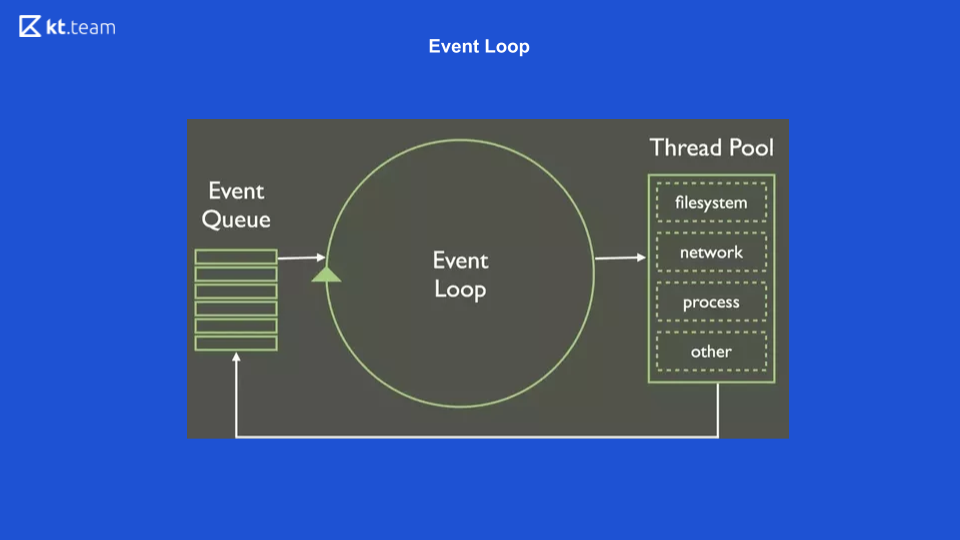
Esta es la representación más simple de cómo se ve Event Loop. Hay una cierta cola de eventos, hay un ciclo interminable de eventos que realiza operaciones sincrónicamente desde la cola y los distribuye más.
Esta diapositiva muestra cómo se ve Event Loop directamente en Node.js.
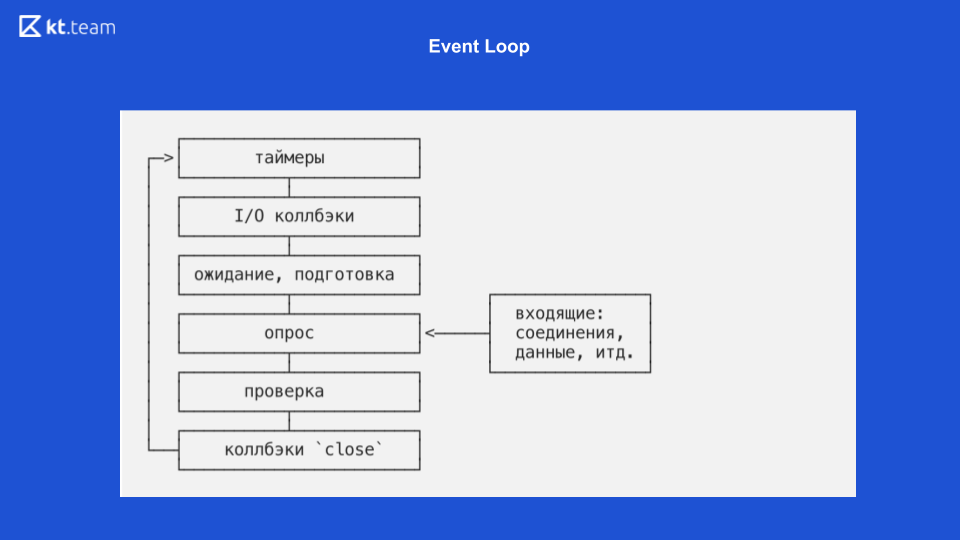
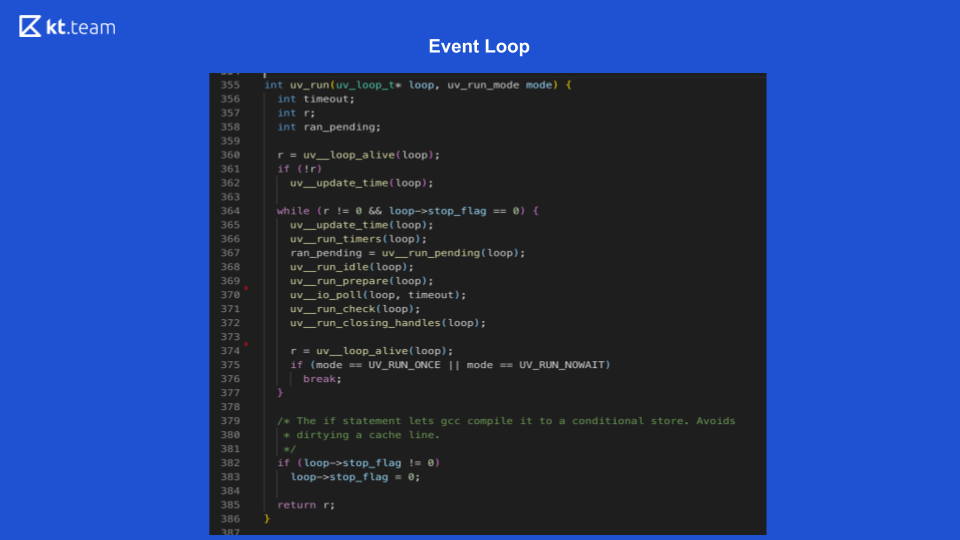
Allí, la implementación es más interesante y más complicada. Esencialmente, un bucle de eventos es un bucle de eventos, y es infinito siempre que haya algo que hacer. Event Loop en Node.js se divide en varias fases. (Las fases de la diapositiva 8 deben compararse con el código fuente de la diapositiva 9.)
Fase 1 - Temporizadores
Esta fase se realiza directamente por Event Loop. (Fragmento de código con uv_update_time): aquí se actualiza simplemente el momento en que Event Loop comenzó a funcionar.
uv_run_timers: en este método, se realiza la siguiente acción del temporizador. Hay una cierta pila, más precisamente, un montón de temporizadores, esto es esencialmente lo mismo que la cola donde se encuentran los temporizadores. Se toma el temporizador con el menor tiempo, en comparación con el tiempo actual del bucle de eventos, y si es hora de ejecutar este temporizador, se ejecuta su devolución de llamada. Vale la pena señalar aquí que Node.js tiene una implementación de setTimeout y hay setInterval. Para libuv, esto es esencialmente lo mismo, solo setInterval todavía tiene un indicador de repetición.
En consecuencia, si este temporizador tiene un indicador de repetición, se vuelve a colocar en la cola de eventos y luego se procesa de la misma manera.
Fase 2: devoluciones de llamadas de E / S
Aquí necesitamos volver al diagrama sobre la entrada / salida sin bloqueo.
Cuando el demultiplexor de eventos lee un archivo y pone en cola la devolución de llamada, solo corresponde a la etapa de devolución de llamada de E / S. Aquí las devoluciones de llamada se realizan para entrada / salida sin bloqueo, es decir, estas son exactamente las funciones que se utilizan después de una solicitud a una base de datos u otro recurso o para leer / escribir un archivo. Se llevan a cabo precisamente en esta fase.
En la diapositiva 9, la ejecución de la función de devolución de llamada de E / S comienza la línea 367: ran_pending = uv_run_pending (loop).
3 fases - espera, preparación
Estas son operaciones internas para devoluciones de llamada, de hecho, no podemos influir en la fase, solo indirectamente. Hay un process.nextTick, su devolución de llamada puede ejecutarse inadvertidamente en la fase de espera y preparación. process.nextTick se ejecuta en la fase actual, es decir, process.nextTick puede funcionar en cualquier fase. No hay una herramienta preparada para ejecutar el código en la fase de "espera, preparación" en Node.js.
En la diapositiva 9, las líneas 368, 369 corresponden a esta fase:
uv_run_idle (loop) - espera;
uv_run_prepare (loop): preparación.
4 fases - encuesta
Aquí es donde se ejecuta todo nuestro código que escribimos en JS. Inicialmente, todas las solicitudes que hacemos llegan aquí, y aquí es donde se puede bloquear Node.js. Si llega alguna operación de cálculo pesado, entonces en esta etapa nuestra aplicación puede congelarse y esperar hasta que se complete esta operación.
En la diapositiva 9, la función de sondeo está en la línea 370: uv_io_poll (bucle, tiempo de espera).
5 fases - verificar
Hay un temporizador setImmediate en Node.js, sus devoluciones de llamada se ejecutan en esta fase.
En el código fuente, esta es la línea 371: uv_run_check (loop).
6 fases (última): cierre de eventos de devolución de llamada
Por ejemplo, un socket web necesita cerrar la conexión, en esta fase se llamará a una devolución de llamada de este evento.
En el código fuente, esta es la línea 372: uv_run_closing_handless (loop).
Y al final, Event Loop Node.js es el siguiente
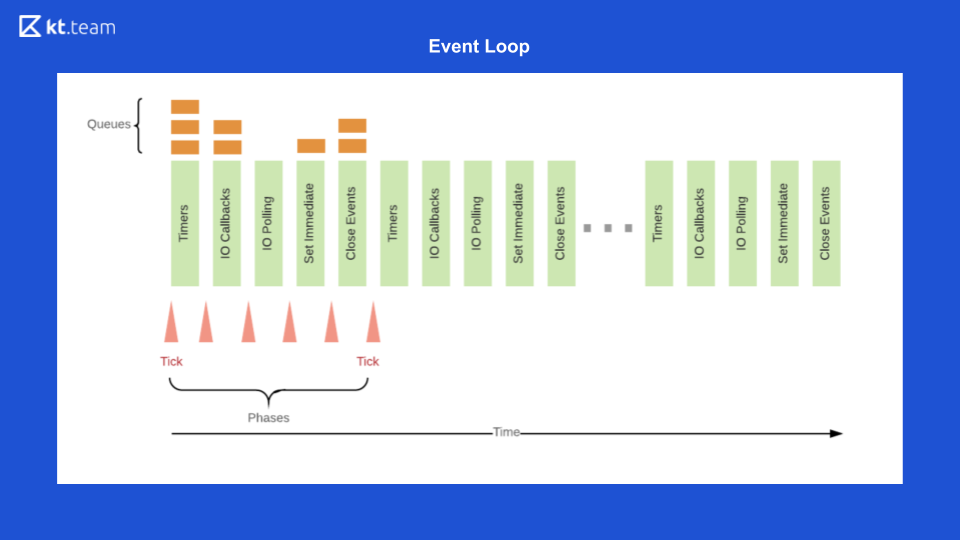
Primero, en la cola del temporizador, se ejecuta el temporizador, cuyo período se ha acercado.
Luego se ejecutan las devoluciones de llamadas de E / S.
Entonces el código es la base, luego setImmediate y los eventos cercanos.
Después de eso, todo se repite en un círculo. Para demostrar esto, abriré el código. ¿Cómo se realizará?
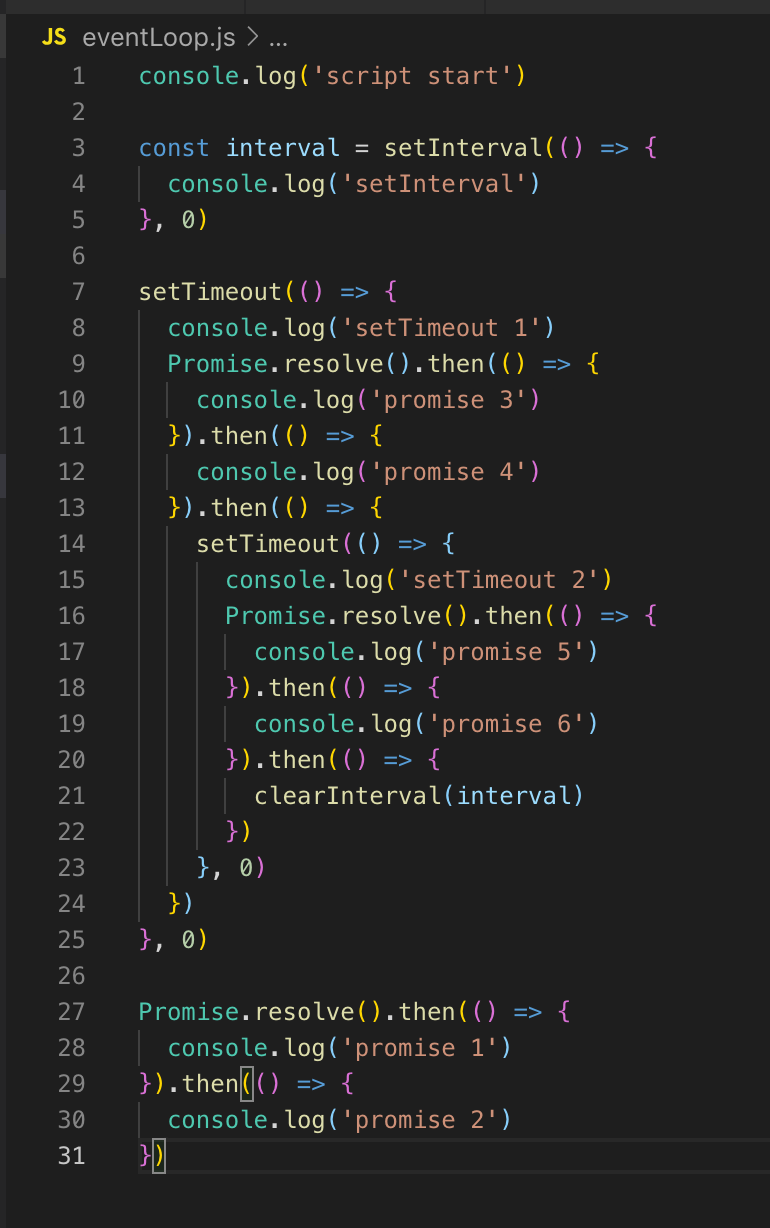
No tenemos temporizadores en línea, por lo que el bucle de eventos continúa. Tampoco hay devoluciones de llamadas de E / S, por lo que pasamos inmediatamente a la fase de sondeo. Todo el código que está aquí se ejecuta inicialmente en la fase de sondeo. Por lo tanto, primero imprimimos script_start, setInterval se coloca en la cola del temporizador (no se ejecuta, solo se coloca). setTimeout también se coloca en la cola del temporizador, y luego se ejecutan las promesas: primero la promesa 1 y luego la promesa 2.
En el siguiente tick (bucle de eventos), volvemos a la etapa del temporizador, aquí en la cola ya hay 2 temporizadores: setInterval y setTimeout. Ambos están retrasados 0, respectivamente, están listos para ejecutarse.
SetInterval se ejecuta (salida a la consola), luego setTimeout 1. No hay devoluciones de llamadas de E / S sin bloqueo, luego habrá una fase de sondeo, la promesa 3 y la promesa 4 se muestran en la consola.
A continuación, se registra el temporizador setTimeout. Esto termina la marca, vaya a la siguiente marca. Hay temporizadores nuevamente, la salida a la consola es setInterval y setTimeout 2, luego se muestran la promesa 5 y la promesa 6.
Revisamos Event Loop y ahora podemos hablar con más detalle sobre multihilo.
Subprocesos - módulo de trabajo_procesos
Threading ha aparecido en Node.js gracias al módulo worker_threads en la versión 10.5. Y en la décima versión, se lanzó exclusivamente con la clave - experimental-worker, y desde la undécima versión fue posible comenzar sin ella.
Node.js también tiene un módulo de clúster, pero no genera subprocesos: genera varios procesos más. La escalabilidad de la aplicación es su objetivo principal.
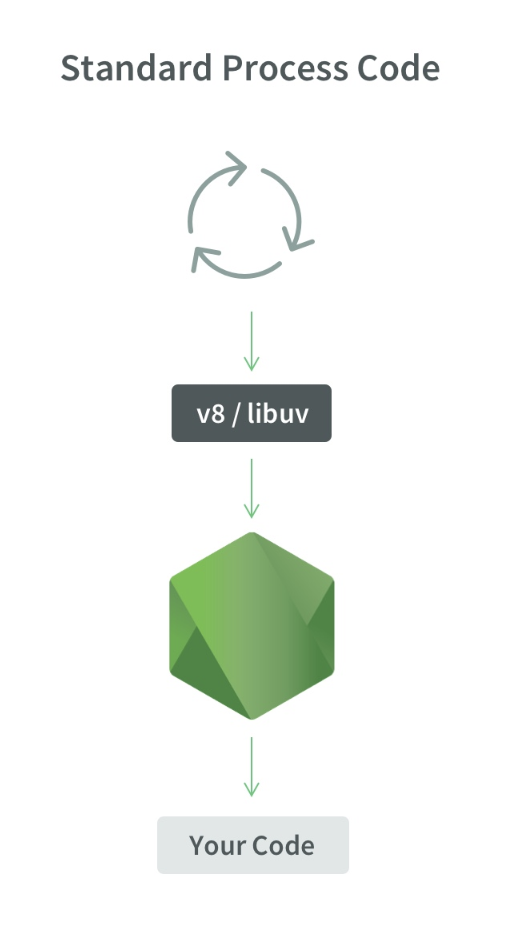
¿Qué aspecto tiene 1 proceso?
1 proceso Node.js, 1 hilo, 1 Event Loop, 1 motor V8 y libuv.
Si comenzamos hilos X, entonces se ve así:
1 proceso Node.js, X subprocesos, X Event Loops, X V8 motores y X libuv.
Esquemáticamente, se ve de la siguiente manera
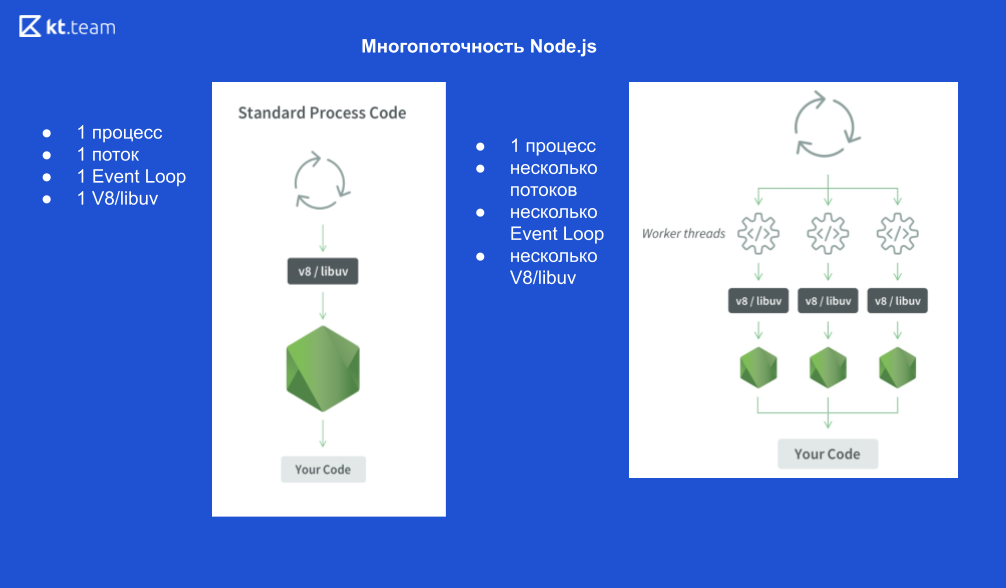
Tomemos un ejemplo.
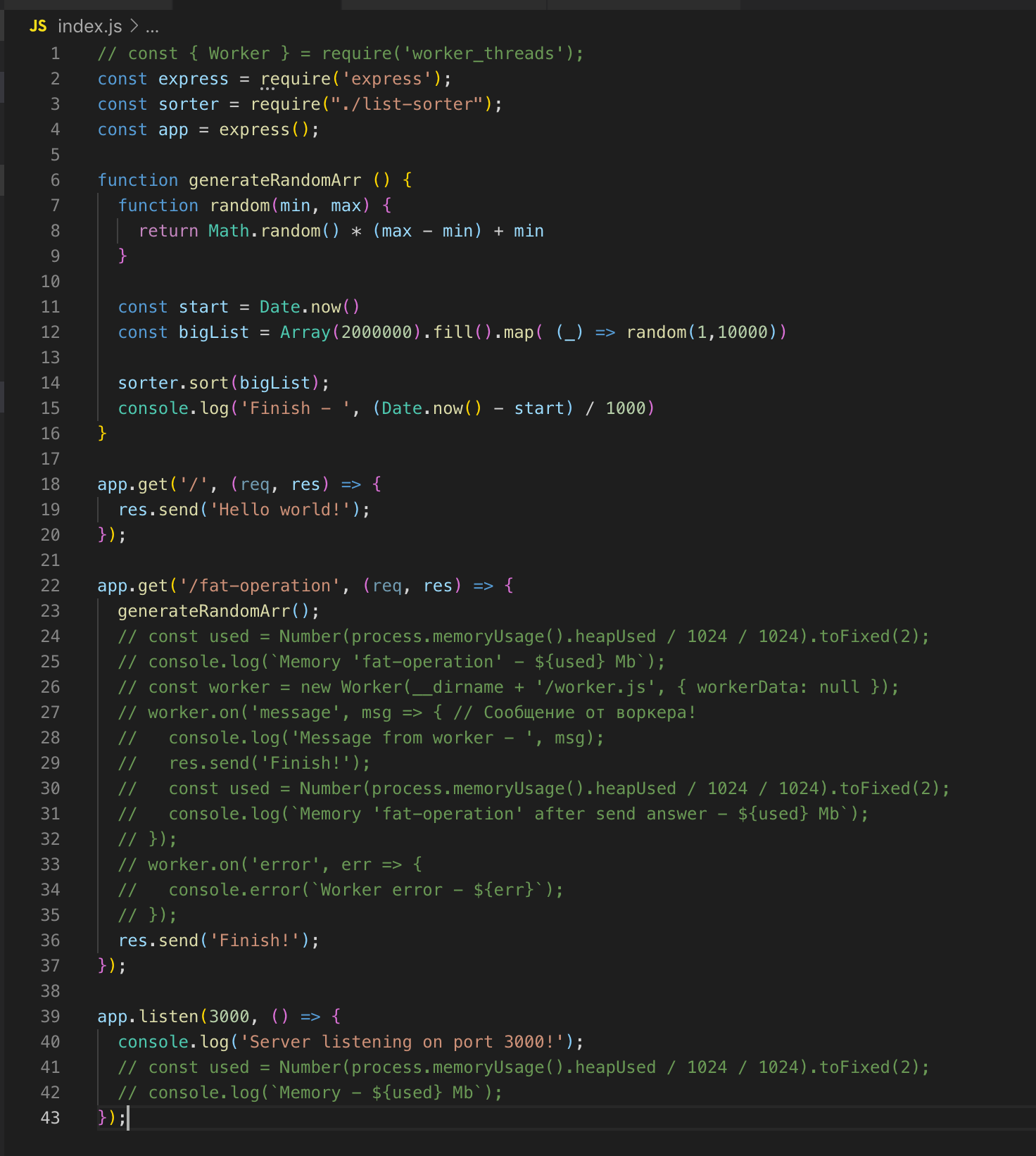
El servidor web más simple en Express. Hay 2 rutas'a - / y / fat-operation.
También hay una función generateRandomArr (). Ella llena el conjunto con dos millones de registros y los ordena. Comencemos el servidor.
Hacemos una solicitud de / fat-operation. Y en ese momento, cuando se realiza la operación de ordenar la matriz, enviamos otra solicitud a route /, pero para obtener la respuesta tenemos que esperar hasta que la matriz esté ordenada. Esta es una implementación clásica de un solo hilo. Ahora conectamos el módulo worker_threads.
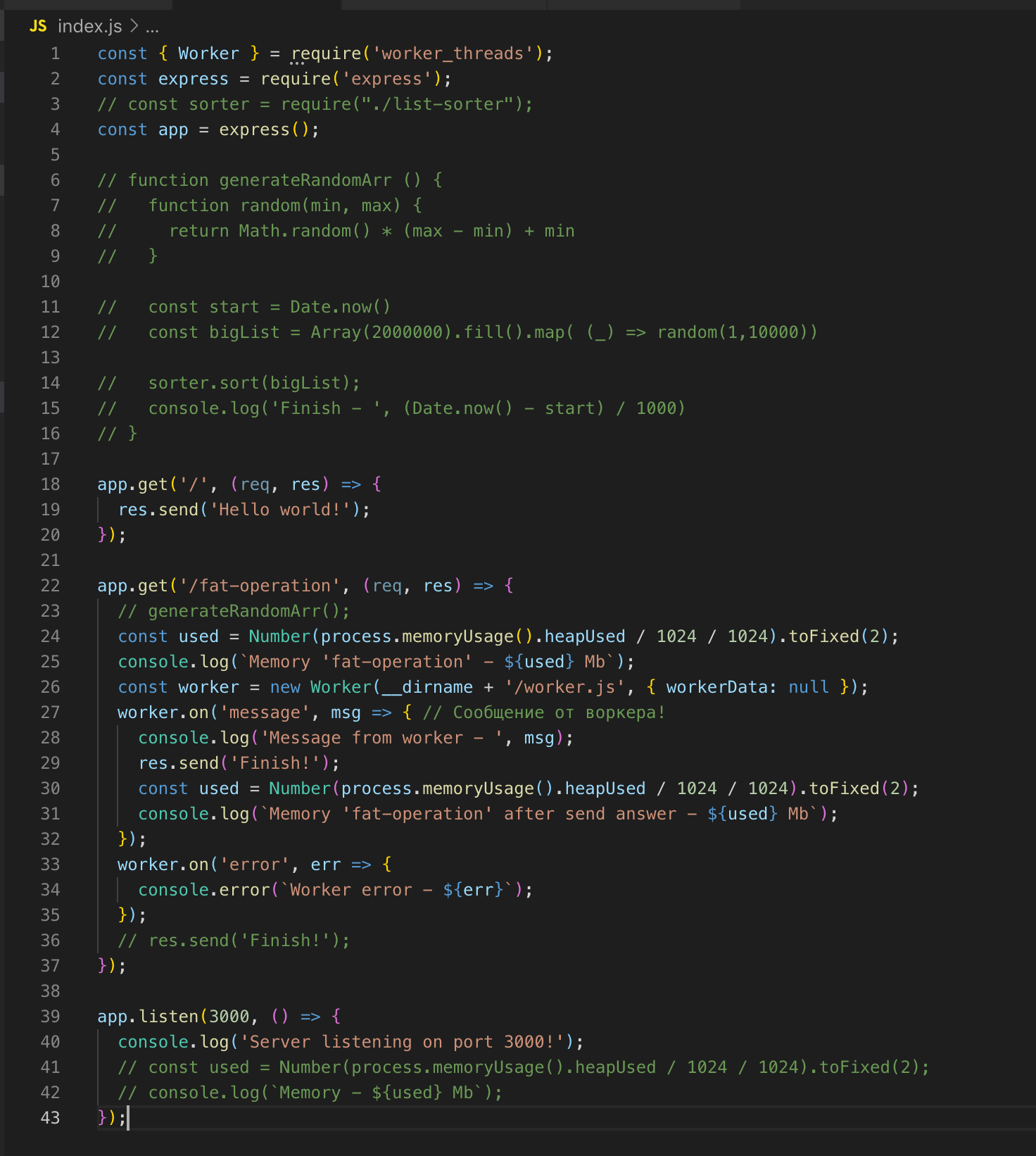
Hacemos una solicitud a / fat-operation y luego - a /, de donde obtenemos la respuesta de inmediato - ¡Hola mundo!
Para la operación de ordenar la matriz, generamos un hilo separado que tiene su propia instancia de Event Loop, y no afecta la ejecución del código en el hilo principal.
Un hilo será "destruido" cuando no tenga operaciones que realizar.
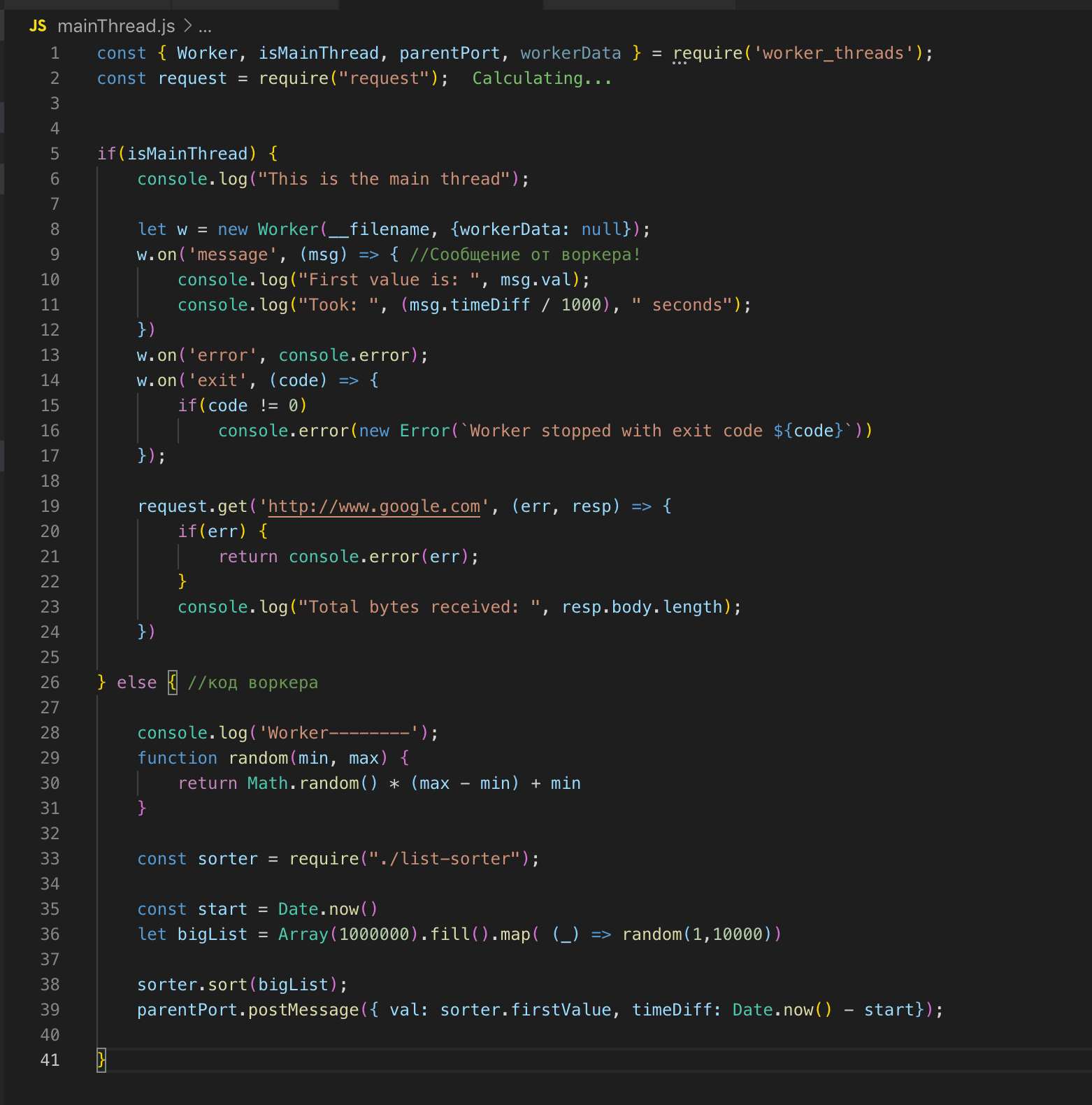
Nos fijamos en el código fuente. Registramos al trabajador en la línea 26 y, si es necesario, le pasamos los datos. En este caso, no estoy transmitiendo nada. Y luego nos suscribimos a eventos: un error y un mensaje. En el trabajador, se llama a la función, se ordena una matriz de dos millones de registros. Tan pronto como se ordena, enviamos el resultado a la transmisión principal de acuerdo con post_message.
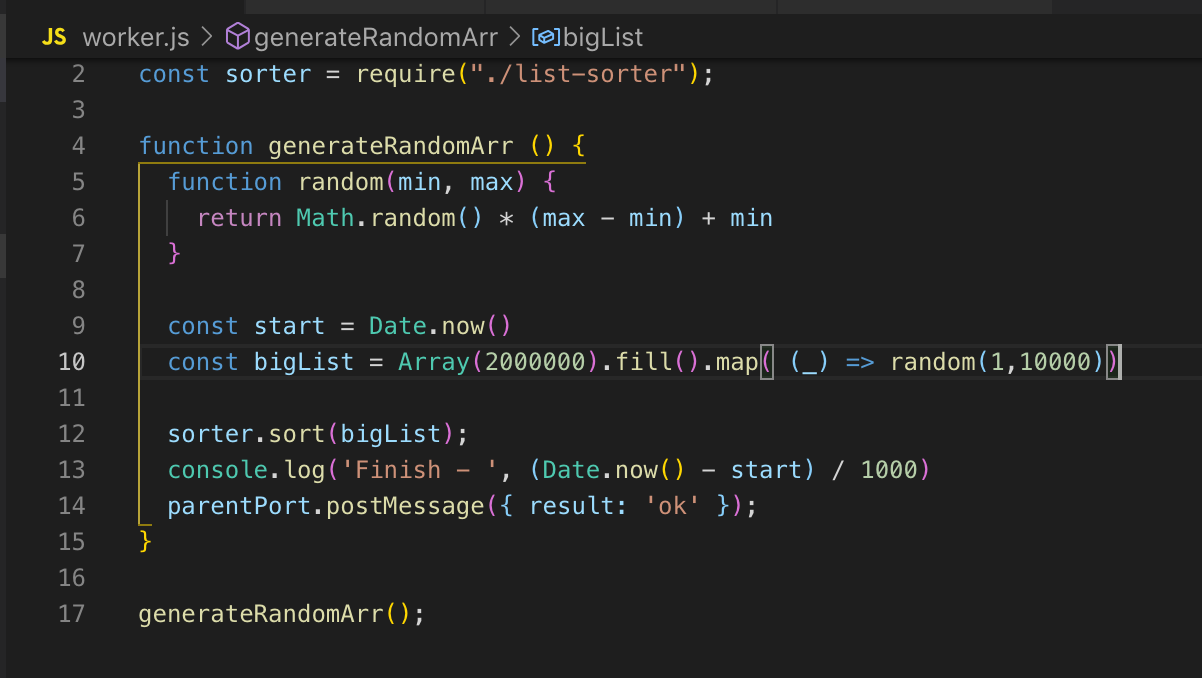
En el hilo principal, captamos este mensaje y enviamos el resultado para finalizar. El trabajador y el hilo principal tienen memoria común, por lo que tenemos acceso a las variables globales de todo el proceso. Cuando transferimos datos de la transmisión principal al trabajador, el trabajador solo obtiene una copia.
Podemos describir la secuencia principal y la secuencia de trabajo en un archivo. El módulo worker_threads proporciona una API a través de la cual podemos determinar en qué hilo se está ejecutando actualmente el código.
Comparto enlaces a recursos útiles y un enlace a la presentación de Ryan Dahl cuando presentó el Event Loop (interesante de ver).
Bucle de eventos
- Traducción de un artículo de la documentación de Node.js
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/en/post/336498/
Hilos_Trabajadores
- https://nodejs.org/api/worker_threads.html#worker_threads_worker_workerdata - API
- https://habr.com/ru/company/ruvds/blog/415659/
- https://nodesource.com/blog/worker-threads-nodejs/
- Diapositivas originales de la presentación de Ryan Dahl (a través de VPN)