By type of activity, one has to deal with situations when a developer writes a request and thinks "the
base is smart, it can handle everything! "
In some cases (partly from ignorance of the database capabilities, partly from premature optimizations), this approach leads to the appearance of “Frankenstein”.
First I’ll give an example of such a query:
In order to objectively evaluate the quality of the request, let's create some arbitrary data set:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
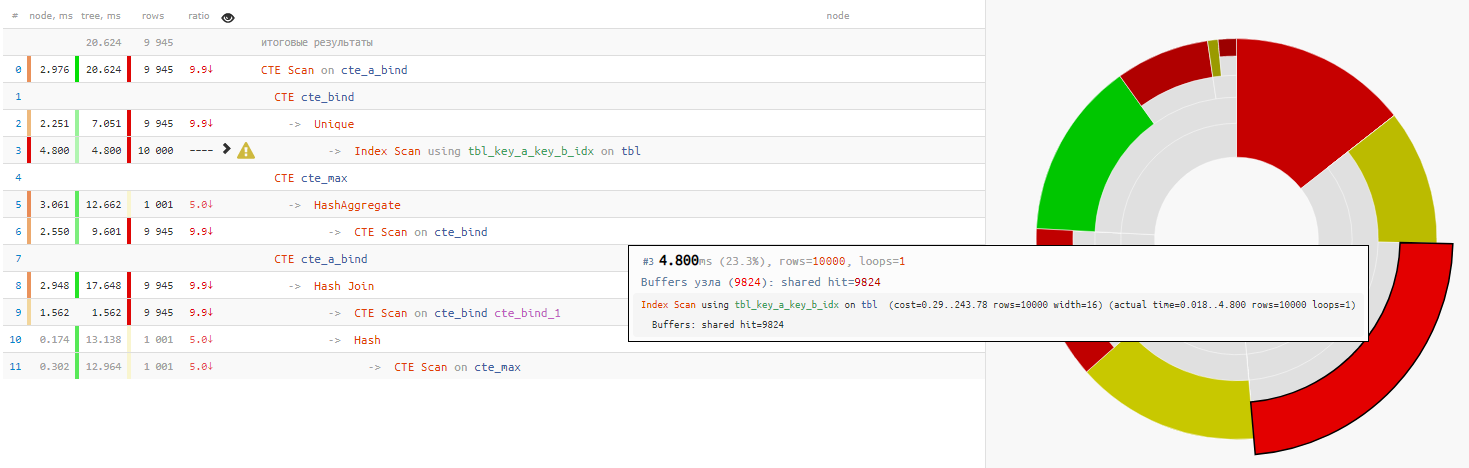
It turns out that
reading the data itself
took less than a quarter of the total query execution
time :
 [look at explain.tensor.ru]
[look at explain.tensor.ru]Disassemble by bones
We will look closely at the request, and we will be puzzled:
- Why is WITH RECURSIVE here, if there are no recursive CTEs?
- Why group min / max values in a separate CTE if then they are still attached to the original sample anyway?
+ 25% of the time - Why at the end use re-readings from the previous CTE through the unconditional 'SELECT * FROM'?
+ 14% of the time
In this case, we were very lucky that Hash Join was chosen for the connection, and not Nested Loop, because then we would not get a single CTE Scan pass, but 10K!
a bit about CTE ScanHere we must recall that CTE Scan is an analogue of Seq Scan - that is, no indexing, but only exhaustive search, which would require 10K x 0.3ms = 3000ms for cte_max cycles or 1K x 1.5ms = 1500ms for cte_bind cycles !
Actually, what did you want to get as a result?
Yeah, it’s usually this kind of question that he visits somewhere in the 5th minute of the analysis of “three-story” requests.We wanted for each unique key pair to remove
min / max from the group by key_a .
So we will use the
window functions for this:
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [look at explain.tensor.ru]
[look at explain.tensor.ru]Since reading data in both versions takes about 4-5ms equally, our entire time gain of
-32% is pure
load removed from the base CPU , if such a request is performed quite often.
In general, you should not force the base to "round - wear, square - roll."