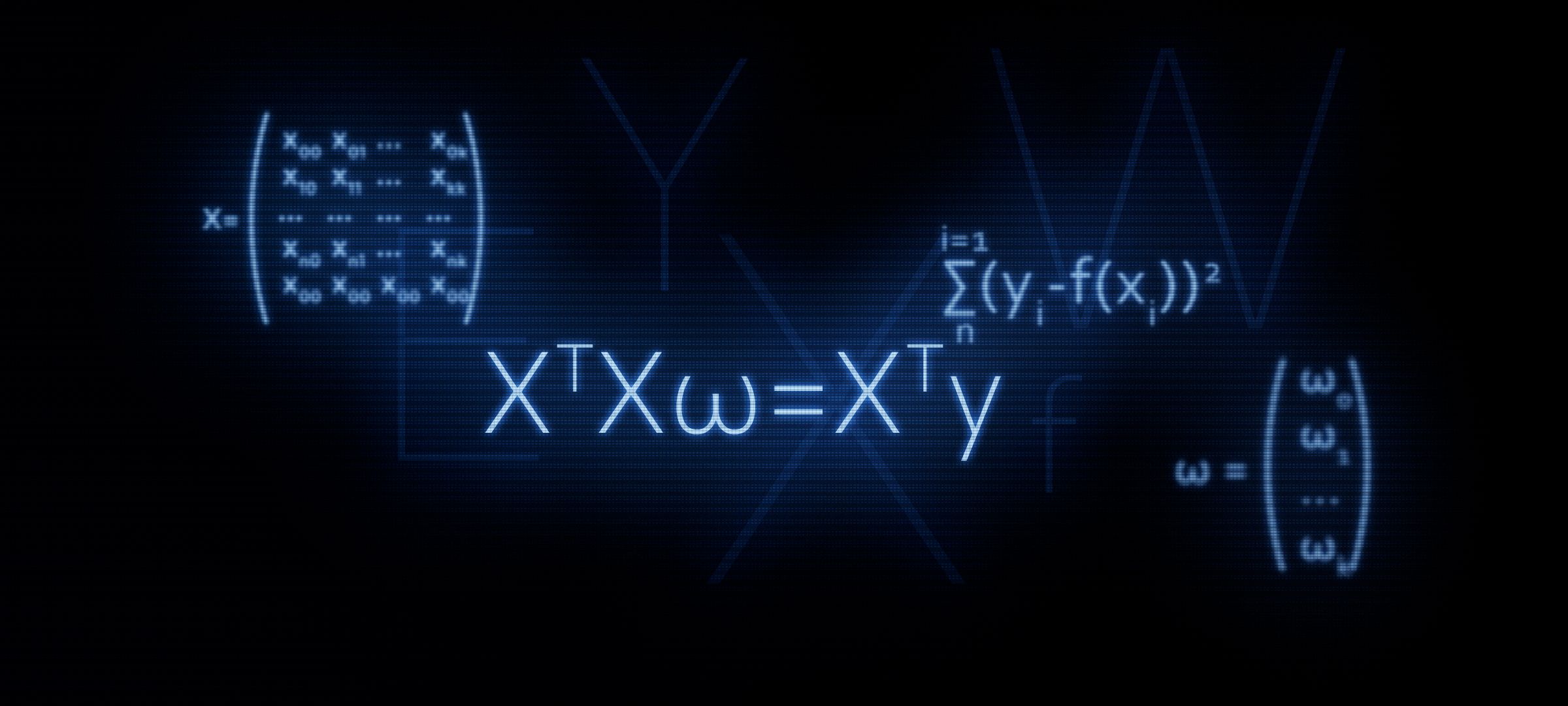
The purpose of the article is to provide support to novice datasaintists. In the
previous article, we examined on the fingers three methods for solving the linear regression equation: analytical solution, gradient descent, stochastic gradient descent. Then for the analytical solution we applied the formula
XTX vecw=XT vecy . In this article, as follows from the title, we will justify the use of this formula, or in other words, we will independently derive it.
Why it makes sense to pay increased attention to the formula
XTX vecw=XT vecy ?
It is with the matrix equation that in most cases, acquaintance with linear regression begins. At the same time, detailed calculations of how the formula was derived are rare.
For example, at Yandex machine learning courses, when students are introduced to regularization, they suggest using the functions from the
sklearn library, while not a word is mentioned about the matrix representation of the algorithm. It is at this moment that some listeners may want to understand this issue in more detail - write code without using ready-made functions. And for this, we must first present the equation with the regularizer in matrix form. This article will allow those who wish to master such skills. Let's get started.
Baseline
Targets
We have a number of target values. For example, the target may be the price of an asset: oil, gold, wheat, dollar, etc. At the same time, by a number of values of the target indicator we mean the number of observations. Such observations may be, for example, monthly oil prices for the year, that is, we will have 12 target values. We begin to introduce the notation. We designate each target value as
yi . Total we have
n observations, which means we can imagine our observations as
y1,y2,y3...yn .
Regressors
We assume that there are factors that to some extent explain the values of the target indicator. For example, the exchange rate of the dollar / ruble pair is strongly influenced by the price of oil, the Fed rate, etc. Such factors are called regressors. At the same time, each value of the target indicator must correspond to the value of the regressor, that is, if we have 12 targets for each month in 2018, then we must also have 12 regressors for the same period. Denote the values of each regressor by
xi:x1,x2,x3...xn . Let in our case there is
k regressors (i.e.
k factors that influence the value of the target). So our regressors can be represented as follows: for the 1st regressor (for example, the price of oil):
x11,x12,x13...x1n , for the 2nd regressor (for example, the Fed rate):
x21,x22,x23...x2n for
k th "regressor:
xk1,xk2,xk3...xknDependence of targets on regressors
Assume Target Dependence
yi from regressors "
i -th "observation can be expressed through the linear regression equation of the form:
f(w,xi)=w0+w1x1i+...+wkxki
where
xi - "
i th "regressor value from 1 to
n ,
k - the number of regressors from 1 to
kw - angular coefficients that represent the amount by which the calculated target indicator will change on average when the regressor changes.
In other words, we are for everyone (except
w0 ) of the regressor we determine “our” coefficient
w , then multiply the coefficients by the values of the regressors "
i -th "observation, as a result we get a certain approximation"
i th "target.
Therefore, we need to select such coefficients
w for which the values of our approximating function
f(w,xi) will be located as close as possible to the values of the targets.
Estimation of the quality of the approximating function
We will determine the quality estimate of the approximating function by the least squares method. The quality assessment function in this case will take the following form:
Err= sum limitsni=1(yi−f(xi))2 rightarrowmin
We need to choose such values of the coefficients $ w $ for which the value
Err will be the smallest.
We translate the equation into matrix form
Vector view
First, to make your life easier, you should pay attention to the linear regression equation and note that the first coefficient
w0 not multiplied by any regressor. Moreover, when we translate the data into matrix form, the above circumstance will seriously complicate the calculations. In this regard, it is proposed to introduce another regressor for the first coefficient
w0 and equate to one. Or rather, each "
i the "value" of this regressor to equate to unity - because when multiplied by unity, nothing will change in terms of the result of calculations, and from the point of view of the rules for the product of matrices, our torment will be significantly reduced.
Now, for a while, to simplify the material, suppose we have only one "
i th "observation. Then, imagine the values of the regressors"
i th observation as a vector
vecxi . Vector
vecxi has dimension
(k times1) , i.e
k rows and 1 column:
vecxi= beginpmatrixx0ix1i...xki endpmatrix qquad
The desired coefficients can be represented as a vector
vecw having dimension
(k times1) :
vecw= beginpmatrixw0w1...wk endpmatrix qquad
The linear regression equation for "
i -th "observation will take the form:
f(w,xi)= vecxiT vecw
The quality assessment function of the linear model will take the form:
Err= sum limitsni=1(yi− vecxiT vecw)2 rightarrowmin
Note that in accordance with the rules of matrix multiplication, we needed to transpose the vector
vecxi .
Matrix representation
As a result of the multiplication of vectors, we get the number:
(1 timesk) centerdot(k times1)=1 times1 as expected. This number is the approximation "
i -th "target. But we need to approximate not one value of the target, but all. To do this, we write everything"
i matrix regressors
X . The resulting matrix has the dimension
(n timesk) :
$$ display $$ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $$ display $$
Now the linear regression equation will take the form:
f(w,X)=X vecw
Denote the values of the target indicators (all
yi ) per vector
vecy dimension
(n times1) :
vecy= beginpmatrixy0y1...yn endpmatrix qquad
Now we can write in the matrix format the equation for assessing the quality of a linear model:
Err=(X vecw− vecy)2 rightarrowmin
Actually, from this formula we further obtain the formula known to us
XTXw=XTyHow it's done? The brackets are opened, differentiation is carried out, the resulting expressions are transformed, etc., and that is what we are going to do now.
Matrix transformations
Expand the brackets
(X vecw− vecy)2=(X vecw− vecy)T(X vecw− vecy)=(X vecw)TX vecw− vecyTX vecw−(X vecw)T vecy+ vecyT vecyPrepare an equation for differentiation
To do this, we carry out some transformations. In subsequent calculations, it will be more convenient for us if the vector
vecwT will be presented at the beginning of each work in the equation.
Conversion 1
vecyTX vecw=(X vecw)T vecy= vecwTXT vecyHow did it happen? To answer this question, just look at the sizes of the multiplied matrices and see that at the output we get a number or otherwise
const .
We write the dimensions of the matrix expressions.
vecyTX vecw:(1 timesn) centerdot(n timesk) centerdot(k times1)=(1 times1)=const(X vecw)T vecy:((n timesk) centerdot(k times1))T centerdot(n times1)=(1 timesn) centerdot(n times1)=(1 times1)=const vecwTXT vecy:(1 timesk) centerdot(k timesn) centerdot(n times1)=(1 times1)=constConversion 2
(X vecw)TX vecw= vecwTXTX vecwWe write similarly to transformation 1
(X vecw)TX vecw:((n timesk) centerdot(k times1))T centerdot(n timesk) centerdot(k times1)=(1 times1)=const vecwTXTX vecw:(1 timesk) centerdot(k timesn) centerdot(n timesk) centerdot(k times1)=(1 times1)=constAt the output, we get an equation that we have to differentiate:
Err= vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyWe differentiate the function of assessing the quality of the model
Differentiate by vector
vecw :
fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw
( vecwTXTX vecw)′−(2 vecwTXT vecy)′+( vecyT vecy)′=02XTX vecw−2XT vecy+0=0XTX vecw=XT vecyQuestions why
( vecyT vecy)′=0 should not be, but the operations to determine the derivatives in the other two expressions, we will analyze in more detail.
Differentiation 1
We reveal the differentiation:
fracd( vecwTXTX vecw)d vecw=2XTX vecwIn order to determine the derivative of a matrix or vector, you need to see what they have inside. We look:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
vecw= beginpmatrixw0w1...wk endpmatrix qquad$ inline $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
$ inline $ X = \ begin {pmatrix} x_ {00} & x_ {01} & ... & x_ {0k} \\ x_ {10} & x_ {11} & ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
Denote the product of matrices
XTX through the matrix
A . Matrix
A square and moreover, it is symmetrical. These properties will be useful to us further, remember them. Matrix
A has dimension
(k timesk) :
$ inline $ A = \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad $ inline $
Now our task is to correctly multiply the vectors by the matrix and not get “twice two five”, so we will focus and be extremely careful.
$ inline $ \ vec {w} ^ TA \ vec {w} = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad \ times \ begin {pmatrix} a_ {00} & a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \ \ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
$ inline $ = \ begin {pmatrix} w_0a_ {00} + w_1a_ {10} + ... + w_ka_ {k0} & ... & w_0a_ {0k} + w_1a_ {1k} + ... + w_ka_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
= beginpmatrix(w0a00+w1a10+...+wkak0)w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10mu(w0a0k+w1a1k+...+wkakk)wk endpmatrix==w20a00+w1a10w0+wkak0w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10muw0a0kwk+w1a1kwk+...+w2kakkHowever, we got an intricate expression! In fact, we got a number - a scalar. And now, already truly, we pass to differentiation. It is necessary to find the derivative of the obtained expression for each coefficient
w0w1...wk and get the dimension vector at the output
(k times1) . Just in case, I will describe the procedures for the actions:
1) differentiate by
wo we get:
2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwk2) differentiate by
w1 we get:
w0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk3) differentiate by
wk we get:
w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakkAt the output, the promised vector of size
(k times1) :
beginpmatrix2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwkw0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk.........w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakk endpmatrix
If you take a closer look at the vector, you will notice that the left and corresponding right elements of the vector can be grouped in such a way that, as a result, the vector can be distinguished from the presented vector
vecw the size
(k times1) . For instance,
w1a10 (left element of the top line of the vector)
+a01w1 (the right element of the top line of the vector) can be represented as
w1(a10+a01) , a
w2a20+a02w2 - as
w2(a20+a02) etc. on each line. Group:
beginpmatrix2w0a00+w1(a10+a01)+w2(a20+a02)+...+wk(ak0+a0k)w0(a01+a10)+2w1a11+w2(a21+a12)+...+wk(ak1+a1k).........w0(a0k+ak0)+w1(a1k+ak1)+w2(a2k+ak2)+...+2wkakk endpmatrix
Take out the vector
vecw and at the output we get:
$$ display $$ \ begin {pmatrix} 2a_ {00} & a_ {10} + a_ {01} & a_ {20} + a_ {02} & ... & a_ {k0} + a_ {0k} \\ a_ {01} + a_ {10} & 2a_ {11} & a_ {21} + a_ {12} & ... & a_ {k1} + a_ {1k} \\ ... & ... & .. . & ... & ... \\ ... & ... & ... & ... & ... \\ ... & ... & ... & ... & .. . \\ a_ {0k} + a_ {k0} & a_ {1k} + a_ {k1} & a_ {2k} + a_ {k2} & ... & 2a_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ ... \\ ... \\ w_k \ end {pmatrix} \ qquad $$ display $$
Now, let's take a look at the resulting matrix. A matrix is the sum of two matrices
A+AT :
$$ display $$ \ begin {pmatrix} a_ {00} & a_ {01} & a_ {02} & ... & a_ {0k} \\ a_ {10} & a_ {11} & a_ {12} & ... & a_ {1k} \\ ... & ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & a_ {k2} & ... & a_ {kk} \ end {pmatrix} + \ begin {pmatrix} a_ {00} & a_ {10} & a_ {20} & ... & a_ {k0} \\ a_ {01} & a_ {11} & a_ {21} & ... & a_ {k1} \\ ... & ... & ... & ... & ... \\ a_ {0k} & a_ {1k} & a_ {2k} & ... & a_ {kk} \ end {pmatrix} \ qquad $$ display $$
Recall that a little earlier, we noted one important property of the matrix
A - it is symmetrical. Based on this property, we can confidently state that the expression
A+AT equals
2A . This is easy to verify by revealing the matrix-by-element product
XTX . We will not do this here, those who wish can conduct a check on their own.
Let's get back to our expression. After our transformations, it turned out as we wanted to see it:
(A+AT) times beginpmatrixw0w1...wk endpmatrix qquad=2A vecw=2XTX vecw
So, we coped with the first differentiation. We pass to the second expression.
Differentiation 2
fracd(2 vecwTXT vecy)d vecw=2XT vecyLet's go along the beaten path. It will be much shorter than the previous one, so do not go far from the screen.
We reveal the element-wise vectors and matrix:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
$ inline $ X ^ T = \ begin {pmatrix} x_ {00} & x_ {10} & ... & x_ {n0} \\ x_ {01} & x_ {11} & ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} & x_ {1k} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
vecy= beginpmatrixy0y1...yn endpmatrix qquadFor a while, we remove the deuce from the calculations - it does not play a big role, then we will return it to its place. Multiply the vectors by the matrix. First of all, we multiply the matrix
XT on vector
vecy , here we have no restrictions. Get the size vector
(k times1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Perform the following action - multiply the vector
vecw to the resulting vector. At the output, a number will wait for us:
beginpmatrixw0(x00y0+x10y1+...+xn0yn)+w1(x01y0+x11y1+...+xn1yn) mkern10mu+ mkern10mu... mkern10mu+ mkern10muwk(x0ky0+x1ky1+...+xnkyn) endpmatrix qquad
We then differentiate it. At the output we get a dimension vector
(k times1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Does it resemble something? All right! This is the product of the matrix.
XT on vector
vecy .
Thus, the second differentiation was successfully completed.
Instead of a conclusion
Now we know how equality came about.
XTX vecw=XT vecy .
Finally, we describe a quick way to transform the main formulas.
Estimate the quality of the model in accordance with the least squares method: sum limitsni=1(yi−f(xi))2 mkern20mu= mkern20mu sum limitsni=1(yi− vecxiT vecw)2==(X vecw− vecy)2 mkern20mu= mkern20mu(X vecw− vecy)T(X vecw− vecy) mkern20mu= mkern20mu vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyWe differentiate the resulting expression: fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw=2XTX vecw−2XT vecy=0XTX vecw=XT vecy leftarrow Previous work of the author - “We solve the equation of simple linear regression” rightarrow The next work of the author - "Chewing Logistic Regression"Literature
Internet sources:1)
habr.com/en/post/2785132)
habr.com/ru/company/ods/blog/3220763)
habr.com/en/post/3070044)
nabatchikov.com/blog/view/matrix_derTextbooks, task collections:1) Lecture notes on higher mathematics: full course / D.T. Written - 4th ed. - M.: Iris Press, 2006
2) Applied Regression Analysis / N. Draper, G. Smith - 2nd ed. - M.: Finance and Statistics, 1986 (translated from English)
3) Tasks for solving matrix equations:
function-x.ru/matrix_equations.html
mathprofi.ru/deistviya_s_matricami.html