
Just do not be surprised, but the second heading to this post generated a neural network, or rather, the algorithm of sammarization. And what is sammarization?
This is one of the key and classic
challenges of Natural Language Processing (NLP) . It consists in creating an algorithm that takes text as input and outputs an abridged version of it. Moreover, the correct structure (corresponding to the norms of the language) is preserved in it and the main idea of the text is correctly transmitted.
Such algorithms are widely used in the industry. For example, they are useful for search engines: using text reduction, you can easily understand whether the main idea of a site or document correlates with a search query. They are used to search for relevant information in a large stream of media data and to filter out information garbage. Text reduction helps in financial research, in the analysis of legal contracts, annotation of scientific papers and much more. By the way, the sammarization algorithm generated all the subheadings for this post.
To my surprise, on Habré there were very few articles about sammarization, so I decided to share my research and results in this direction. This year I participated in the racetrack at the
Dialogue conference and experimented with headline generators for news items and for poems using neural networks. In this post, I will first briefly go over the theoretical part of sammarization, and then I will give examples with the generation of headings, I will tell you what difficulties models have when reducing the text and how these models can be improved to achieve better headings.
Below is an example of a news item and its original reference headline. The models I will talk about will train to generate headers with this example:

Secrets to cutting text seq2seq architecture
There are two types of text reduction methods:
- Extractive . It consists in finding the most informative parts of the text and constructing from them the annotation correct for the given language. This group of methods uses only those words that are in the source text.
- Abstract It consists in extracting semantic links from the text, while taking into account language dependencies. With abstract sammarization, annotation words are not selected from the abbreviated text, but from the dictionary (the list of words for a given language) - thereby rephrasing the main idea.
The second approach implies that the algorithm should take into account language dependencies, rephrase and generalize. He also wants to have some knowledge of the real world in order to prevent factual errors. For a long time, this was considered a difficult task, and researchers could not get a high-quality solution - a grammatically correct text while preserving the main idea. That is why in the past, most algorithms were based on an extracting approach, since the selection of whole pieces of text and transferring them to the result allows you to maintain the same level of literacy as the source.
But this was before the boom of neural networks and its imminent penetration into the NLP. In 2014, the
seq2seq architecture was
introduced with an attention mechanism that can read some text sequences and generate others (which depends on what the model learned to output) (
article by Sutskever et al.). In 2016, such an architecture was applied directly to the solution of the problem of sammarization, thereby realizing an abstract approach and obtaining a result comparable to what a competent person could write (
article from Nallapati et al., 2016;
article from Rush et al., 2015; ) How does this architecture work?
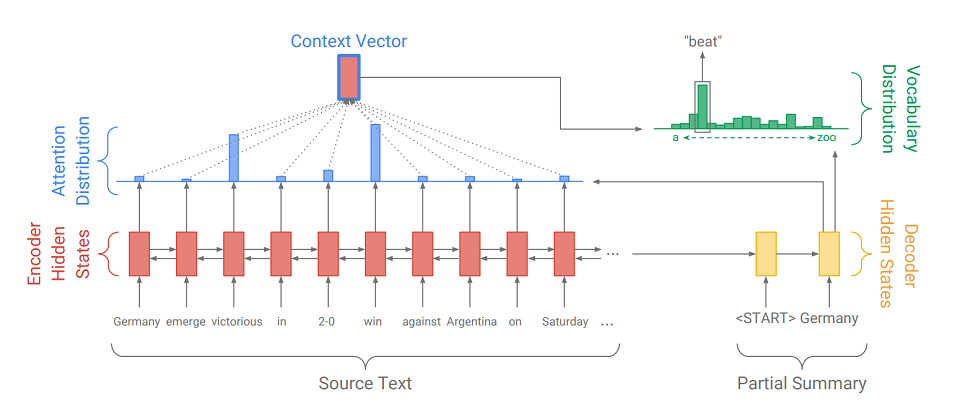
Seq2Seq consists of two parts:
- Encoder (Encoder) - a two-way RNN, which is used to read the input sequence, that is, sequentially processes the input elements simultaneously from left to right and from right to left to better take into account the context.
- decoder (Decoder) - one-way RNN, which sequentially and element-wise produces an output sequence.
First, the input sequence is translated into an embedding sequence (in short, embedding is a concise representation of a word as a vector). Embeddings then go through the recursive network of the encoder. So, for each word, we get the encoder's hidden states (
indicated by red rectangles on the diagram ), and they contain information about the token itself and its context, allowing us to take into account the language connections between the words.
Having processed the input, the encoder transfers its last hidden state (which contains compressed information about the entire text) to the decoder, which receives a special token

and creates the first word of the output sequence (
in the picture it is “Germany” ). Then he cyclically takes his previous output, feeds it to himself and again displays the next output element (
so after “Germany” comes “beat”, and after “beat” comes the next word, etc. ). This is repeated until a special token is issued
. This means the end of generation.
To display the next element, the decoder, just like the encoder, converts the input token into embedding, takes a step of the recursive network and receives the next hidden state of the decoder (
yellow rectangles in the diagram ). Then, using a fully connected layer, a probability distribution is obtained for all words from a pre-compiled model dictionary. The most likely words will be deduced by the model.
Adding
an attention mechanism helps the decoder make better use of input information. The mechanism at each step of the generation determines the so-called
attention distribution (the
blue rectangles in the figure are the set of weights corresponding to the elements of the original sequence, the sum of the weights is 1, all weights> = 0 ), and from it it receives the weighted sum of all the hidden states of the encoder, thereby forming context vector (
the diagram shows a red rectangle with a blue stroke ). This vector concatenates with embedding the decoder input word at the stage of calculating the latent state and with the latent state itself at the stage of determining the next word. So at each step of the output, the model can determine which encoder states are most important to it at the moment. In other words, it decides the context of which input words should be taken into account the most (for example, in the picture, displaying the word “beat”, the attention mechanism gives large weights to the “victorious” and “win” tokens, and the rest are close to zero).
Since the generation of headers is also one of the tasks of sammarization, only with the minimum possible output (1-12 words), I decided to apply
seq2seq with the attention mechanism for our case. We train such a system on texts with headings, for example, on the news. Moreover, it is advisable at the training stage to submit to the decoder not his own output, but the words of the real heading (teacher forcing), making life easier for himself and the model. As an error function, we use the standard cross-entropy loss function, showing how close the probability distributions of the output word and the word from the real header are:
When using the trained model, we use ray search to find a more likely sequence of words than using the greedy algorithm. To do this, at each step of generation, we derive not the most probable word, but at the same time look at beam_size of the most probable sequences of words. When they end (each one ends on
), we derive the most probable sequence.
Model evolution
One of the problems of the model on seq2seq is the inability to cite words that are not in the dictionary. For example, the model has no chance to deduce "obamacare" from the article above. The same goes for:
- rare surnames and names
- new terms
- words in other languages,
- different pairs of words connected by a hyphen (as a "Republican Senator")
- and other designs.
Of course, you can expand the dictionary, but this greatly increases the number of trained parameters. In addition, it is necessary to provide a large number of documents in which these rare words are found, so that the generator learns to use them in a qualitative manner.
Another and more elegant solution to this problem was presented in a 2017 article - “
Get To The Point: Summarization with Pointer-Generator Networks ” (Abigail See et al.). She adds a new mechanism to our model -
a pointer
mechanism , which can select words from the source text and directly insert into the generated sequence. If the text contains OOV (
out of vocabulary - a word that is not in the dictionary ), then the model, if it considers it necessary, can isolate OOV and insert it at the output. Such a system is called a
“ pointer-generator” (pointer-generator or pg) and is a synthesis of two approaches to sammarization. She herself can decide at what step she should be abstract, and at what step - extracting. How she does it, we’ll figure it out now.
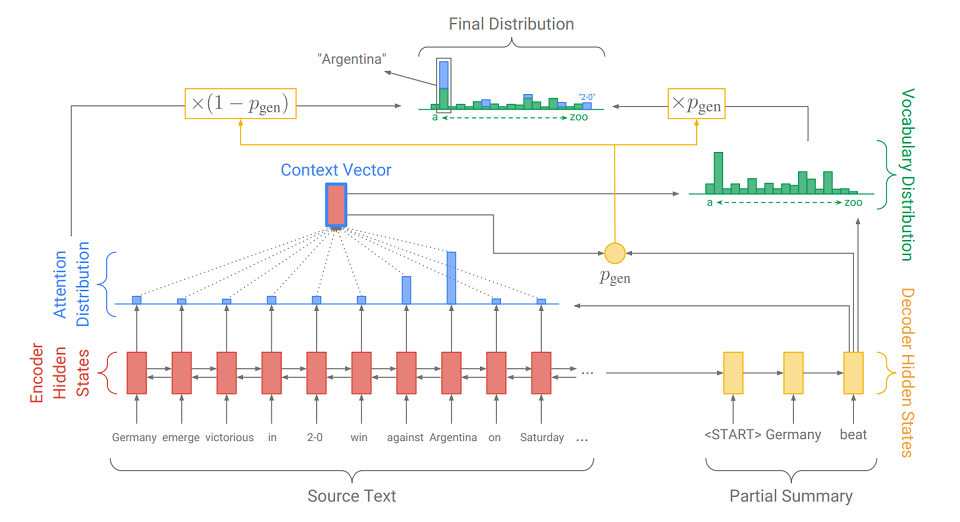
The main difference from the usual seq2seq model is the additional action on which p
gen is calculated - the generation probability. This is done using the hidden state of the decoder and the context vector. The meaning of the additional action is simple. The closer p
gen is to 1, the more likely it is that the model will issue a word from its dictionary using abstract generation. The closer p
gen is to 0, the more likely it is that the generator will extract the word from the text, guided by the distribution of attention obtained earlier. The final probability distribution of the word results is the sum of the generated probability distribution of the words (in which there is no OOV) multiplied by p
gen and the distribution of attention (in which OOV is, for example, “2-0” in the picture) multiplied by (1 - p
gen ).

In addition to the pointing mechanism, the article introduces
a coverage mechanism , which helps to avoid repeating words. I also experimented with it, but did not notice significant improvements in the quality of headings - it is not really needed. Most likely, this is due to the specifics of the task: since it is necessary to output a small number of words, the generator simply does not have time to repeat itself. But for other tasks of sammarization, for example, annotation, it can come in handy. If interested, you can read about it in the original
article .

Great variety of Russian words
Another way to improve the quality of the output headers is to properly preprocess the input sequence. In addition to the obvious disposal of uppercase characters, I also tried to convert words from the source text into pairs of styles and inflections (i.e. foundations and endings). For splitting, use the Porter Stemmer.
We mark all inflections with the “+” symbol at the beginning to distinguish them from other tokens. We consider each topic and inflection as a separate word and learn from them in the same way as in words. That is, we get embeddings from them and derive a sequence (also broken down into foundations and endings) that can be easily turned into words.
Such a conversion is very useful when working with morphologically rich languages like Russian. Instead of compiling huge dictionaries with a great variety of Russian word forms, you can limit yourself to a large number of stems of these words (they are several times smaller than the number of word forms) and a very small set of endings (I got a lot of 450 inflections). Thus, we make it easier for the model to work with this “wealth” and at the same time we do not increase the complexity of the architecture and the number of parameters.

I also tried using the lemma + gramme transformation. That is, from each word before processing, you can get its initial form and grammatical meaning using the pymorphy package (for example, “was”
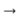
“To be” and “VERB | impf | past | sing | femn”). Thus, I got a pair of parallel sequences (in one - the initial forms, in the other - grammatical values). For each type of sequence, I compiled my embeddings, which I then concatenated and submitted to the pipeline described earlier. In it, the decoder did not learn to give out a word, but a lemma and grammes. But such a system did not bring visible improvements compared to pg on the topic. Perhaps it was an overly simple architecture for working with grammatical values, and it was worth creating a separate classifier for each grammatical category in the output. But I did not experiment with such or more complex models.
I experimented with another addition to the original architecture of the pointer-generator, which, however, does not apply to preprocessing. This is an increase in the number of layers (up to 3) of the recursive networks of the encoder and decoder. Increasing the depth of the recurrent network can improve the quality of the output, since the hidden state of the last layers can contain information about a much longer input subsequence than the hidden state of a single-layer RNN. This helps to take into account complex extended semantic connections between elements of the input sequence. True, this costs a significant increase in the number of model parameters and complicates learning.

Header Generator Experiments
All my experiments on headline generators can be divided into two types: experiments with news articles and verses. I will tell you about them in order.
News Experiments
When working with news, I used models such as seq2seq, pg, pg with stems and inflections - single-layer and three-layer. I also considered models that work with grams, but everything that I wanted to tell about them, I have already described above. I must say right away that all pg described in this section used the coating mechanism, although its influence on the result is doubtful (since without it it was not much worse).
I trained on the RIA Novosti dataset, which was provided by the Rossiya Segodnya news agency to conduct a headline generation track at the Dialog conference. The dataset contains 1,003,869 news articles published from January 2010 to December 2014.
All studied models used the same embeddings (128), vocabulary (100k), and latent states (256) and trained for the same number of eras. Therefore, only qualitative changes in architecture or in preprocessing could affect the result.
Models adapted to work with pre-processed text give better results than models that work with words. A three-layer pg that uses information about topics and inflections works best. When using any pg, the expected improvement in the quality of the headers as compared to seq2seq also appears, which hints at the preferred use of the pointer when generating headers. Here is an example of the operation of all models:
Looking at the generated headers, we can distinguish the following problems from the models under study:
- Models often use irregular forms of words. Models with stems (as in the example above) are more relieved of this drawback;
- All models, except those that work with themes, can produce headers that seem incomplete, or strange designs that are not in the language (as in the example above);
- All studied models often confuse the described persons, substitute incorrect dates or use not quite suitable words.


Experiments with verses
Since the three-layer pg with the themes has the least inaccuracies in the generated headers, this is the model I chose for experiments with verses. I taught her on the case, composed of 6 million Russian poems from the site "stihi.ru". They include love (about half of the verses are devoted to this topic), civic (about a quarter), urban and landscape poetry. Writing period: January 2014 - May 2019. I will give examples of generated headings for verses:
The model turned out to be mostly extracting: almost all headers are a single line, often extracted from the first or last stanza. In exceptional cases, the model can generate words that are not in the poem. This is due to the fact that a very large number of texts in the case really have one of the lines as a name.
In conclusion, I will say that the index generator, working on the stems and using a single-layer decoder and encoder, took second place on the
competition track for generating headlines for news articles at the scientific dialogue conference on computer linguistics "Dialogue". The main organizer of this conference is ABBYY, the company is engaged in research in almost all modern areas of Natural Language Processing.
Finally, I suggest you a little interactive: send news in the comments, and see what headers the neural network will generate for them.
Matvey, developer at NLP Group at ABBYY