El miedo a las operaciones amortigua ...
Usando una consulta pequeña como ejemplo, considere algunos enfoques universales para optimizar las consultas en PostgreSQL. Depende de ti usarlos o no, pero vale la pena saber sobre ellos.
En algunas versiones futuras de PG, la situación puede cambiar con la "sabiduría" del planificador, pero para 9.4 / 9.6 se ve casi igual, como ejemplos aquí.
Tomaré una solicitud muy real:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
sobre los nombres de tablas y camposLos nombres "rusos" de campos y tablas se pueden tratar de manera diferente, pero esto es cuestión de gustos. Dado
que no tenemos desarrolladores extranjeros
en "Tensor" , y PostgreSQL nos permite dar nombres incluso con jeroglíficos, si están
entre comillas , preferimos nombrar objetos de forma inequívoca, clara, para que no haya malentendidos.
Veamos el plan resultante:
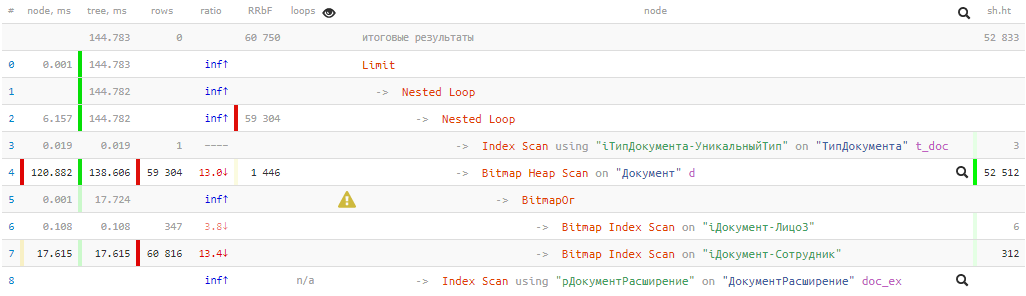 [mira explicar.tensor.ru]144ms y casi 53K buffers
[mira explicar.tensor.ru]144ms y casi 53K buffers , es decir, ¡más de 400MB de datos! Y tenemos suerte si todos ellos están en la memoria caché en el momento de nuestra solicitud, de lo contrario, serán varias veces más largos cuando se resten del disco.
¡El algoritmo es lo más importante!
Para optimizar de alguna manera cualquier solicitud, primero debe comprender lo que debe hacer.
Por ahora, dejamos el desarrollo de la estructura de la base de datos fuera del alcance de este artículo y estamos de acuerdo en que podemos
reescribir la consulta de forma relativamente "económica" y / o incluir en la base de datos los
índices que necesitemos.
Entonces la solicitud es:
- comprueba la existencia de al menos algún documento
- en la condición que necesitamos y de cierto tipo
- donde el autor o albacea es el empleado que necesitamos
UNIRSE + LÍMITE 1
Muy a menudo, es más fácil para un desarrollador escribir una consulta donde, al principio, se unen un gran número de tablas, y luego de todo este conjunto solo hay un registro. Pero más fácil para el desarrollador, no significa más eficiente para la base de datos.
En nuestro caso, solo había 3 mesas, y qué efecto ...
Primero, eliminemos la conexión con la tabla "TypeDocument" y, al mismo tiempo, le digamos a la base de datos que nuestro
registro de tipo es único (lo sabemos, pero el planificador no tiene idea):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
Sí, si la tabla / CTE consta de un solo campo de un solo registro, en PG puede escribir incluso así, en lugar de
d."" = (SELECT "@" FROM T LIMIT 1)
Computación diferida en consultas PostgreSQL
BitmapOr vs UNION
En algunos casos, la exploración de montón de mapa de bits nos costará mucho dinero, por ejemplo, en nuestra situación, cuando suficientes registros caen bajo la condición requerida. Lo obtuvimos debido a la
condición OR, que se convirtió en una operación
BitmapOr en el plan.
Volvamos a la tarea original: necesita encontrar un registro que coincida con
cualquiera de las condiciones, es decir, no es necesario buscar en todos los registros de 59K para ambas condiciones. Hay una manera de resolver una condición y
pasar a la segunda solo cuando no se encontró nada en la primera . Este diseño nos ayudará a:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
El LÍMITE 1 "Externo" garantiza que la búsqueda finalice cuando se encuentre el primer registro. Y si ya está en el primer bloque, el segundo no se
ejecutará (
nunca se ejecutará en el plan).
Condiciones difíciles para "esconderse en CASO"
Hay un momento extremadamente incómodo en la solicitud inicial: verificar el estado utilizando la tabla vinculada "Extensión de documento". Independientemente de la verdad de las condiciones restantes en la expresión (por ejemplo,
d. "Eliminado" NO ES VERDADERO ), esta conexión siempre se realiza y "vale la pena los recursos". Se gastarán más o menos de ellos, depende del tamaño de esta tabla.
Pero puede modificar la solicitud para que la búsqueda del registro relacionado ocurra solo cuando sea realmente necesario:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
Como
no necesitamos ninguno de los campos para el resultado de la tabla vinculada, podemos convertir JOIN en una condición para una subconsulta.
Dejamos los campos indexados "fuera de los corchetes" de CASE, agregamos condiciones simples del registro al bloque WHEN, y ahora la consulta "pesada" se ejecuta solo cuando se cambia a THEN.
Mi apellido es "Total"
Recopilamos la consulta resultante con todas las mecánicas descritas anteriormente:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
Personalizar índices [inferiores]
El ojo entrenado notó que las condiciones indexadas en las subunidades UNION son ligeramente diferentes, esto se debe a que ya tenemos los índices apropiados en la tabla. Y si no estuvieran allí, entonces valdría la pena crear:
Documento (Persona3, Tipo de documento) y
Documento (Tipo de documento, Empleado) .
sobre el orden de los campos en condiciones de ROWDesde el punto de vista del planificador, por supuesto, puede escribir tanto (A, B) = (constA, constB) como (B, A) = (constB, constA) . Pero al escribir en el orden de los campos en el índice , tal solicitud es simplemente más conveniente para depurarla más tarde.
Cual es el plan
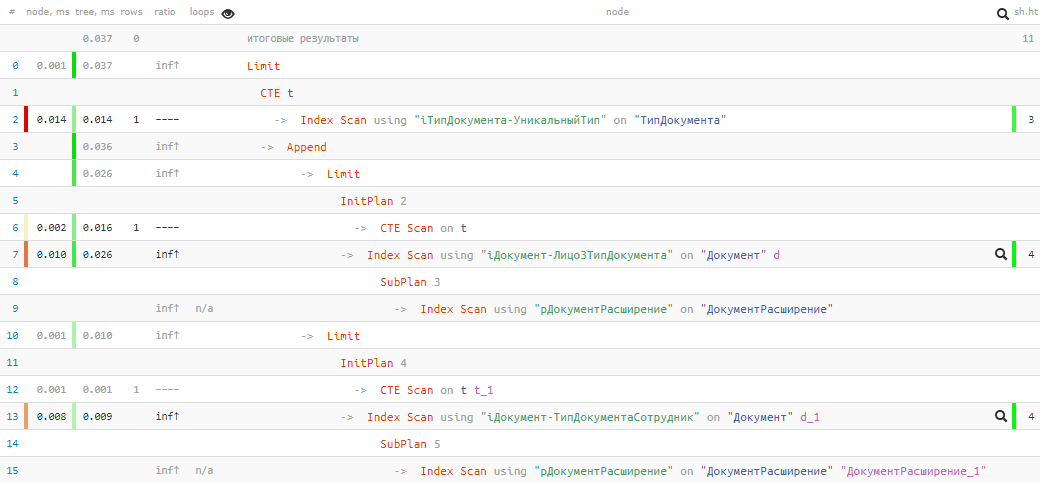 [mira explicar.tensor.ru]
[mira explicar.tensor.ru]Desafortunadamente, no tuvimos suerte, y no se encontró nada en el primer bloque UNION, por lo que el segundo fue ejecutado. Pero aun así, ¡solo
0.037ms y 11 buffers !
Aceleramos la solicitud y redujimos el "bombeo" de datos en la memoria en
varios miles de veces , utilizando métodos bastante simples, un buen resultado con una pequeña copia y pegado. :)