Hola Habr! Mi nombre es Roman, y quiero hablar hoy sobre cómo nosotros, en la Universidad de Innopolis, desarrollamos un banco de pruebas y un servicio para el sistema Acronis Active Restore, que pronto debería formar parte de la línea de productos de la compañía. Todos los que estén interesados en cómo la universidad está construyendo relaciones con socios industriales, los invito a continuar con Cat.

El desarrollo de Active Restore comenzó dentro de Acronis, pero nosotros, como estudiantes de la Universidad de Innopolis, participamos en este proceso como parte de un proyecto de capacitación industrial. Mi curador (y ahora colega) Daulet Tumbaev ya escribió sobre la idea, así como la arquitectura,
en su publicación . Hoy hablaré sobre cómo preparamos el servicio desde Innopolis.
Todo comenzó en el verano, cuando se nos informó que en el primer semestre, las empresas de TI vendrían a nosotros y nos ofrecerían sus ideas para el trabajo práctico. Y así, en diciembre de 2018, se nos presentaron 15 proyectos diferentes, y al final del mes establecimos prioridades, descubrimos a quién le gusta más.
Todos los estudiantes de pregrado completaron un formulario en el que era necesario elegir cuatro proyectos en los que queríamos participar. Era necesario motivar por qué yo, y por qué precisamente estos proyectos. Por ejemplo, señalé que ya tengo experiencia en programación y desarrollo de sistemas en C / C ++. Pero lo más importante, el proyecto me permitió desarrollar mis habilidades y seguir creciendo.
Dos semanas después, nos asignaron, y desde el comienzo del segundo semestre, comenzó el trabajo en los proyectos. El equipo se formó, en la primera reunión evaluamos las fortalezas y debilidades de cada uno y los roles asignados.
- Roman Rybkin es un desarrollador de Python / C ++.
- Eugene Ishutin - Desarrollador de Python / C ++, responsable de interactuar con la empresa.
- Anastasia Rodionova es una desarrolladora de Python / C ++ responsable de escribir documentación.
- Brandon Acosta: configuración del entorno, preparación del stand para experimentos y pruebas.
Las primeras dos semanas tuvimos que comenzar el proceso. Establecimos contactos con el cliente, formalizamos los requisitos para el proyecto, lanzamos un proceso iterativo y configuramos el entorno para el trabajo.
Por cierto, nuestro trabajo con el cliente realmente comenzó a hervir cuando comenzamos las asignaturas optativas. El hecho es que Acronis lidera en la Universidad de Innopolis (y no solo) temas de elección. Y Alexey Kostyushko, desarrollador líder del equipo Kernel, imparte dos cursos de manera continua: Ingeniería inversa y Arquitectura y controladores de kernel de Windows. Hasta donde yo sé, un curso sobre programación de sistemas y computación multiproceso también está planeado en el futuro. Pero lo principal es que todos estos cursos están diseñados para ayudar a los estudiantes a hacer frente a proyectos industriales. Impulsan seriamente la comprensión del área temática y por lo tanto simplifican el trabajo en el proyecto.
Debido a esto, comenzamos más vigorosamente que otros equipos, y la interacción con Acronis se volvió más densa. Alexey Kostyushko actuó para nosotros en el papel de propietario del producto, de él recibimos los conocimientos necesarios en el área temática. Gracias a sus cursos electivos, nuestras habilidades y competencias duras se impulsaron con mucha fuerza, nos preparamos realmente para cumplir con la tarea que nos enfrentaba.
Del pensamiento al proyecto
El primer mes para todos los equipos fue lo más difícil posible. Todos estaban perdidos, no sabían por dónde empezar, tal vez con documentos o, por el contrario, sumergiéndose en el código. Al principio, comentarios contradictorios vinieron de curadores y mentores de la universidad y representantes de la compañía.
Cuando todo encajó (al menos en mi cabeza), quedó claro que los mentores de la universidad nos ayudaron a construir relaciones internas en el equipo y preparar documentos. Pero el verdadero avance fue la llegada de Daulet en marzo. Nos sentamos y trabajamos en el proyecto todo el fin de semana. Luego repensamos la esencia del proyecto, reiniciamos, redistribuimos las prioridades de las tareas y volamos rápidamente. Entendimos lo que se debe hacer para comenzar el experimento (un poco más adelante) y desarrollar el servicio. A partir de ese momento, la idea general se convirtió en un plan claro. Comenzó el desarrollo real del código, y en 2 semanas desarrollamos la primera versión del banco de pruebas, incluidas las máquinas virtuales, los servicios necesarios y el código para automatizar el experimento y recopilar datos.
Vale la pena señalar que, paralelamente al proyecto industrial, hubo cursos de capacitación que nos ayudaron a construir una arquitectura competente para nuestros proyectos y organizar la Gestión de Calidad. Al principio, estas tareas llevaban entre el 70 y el 90% del tiempo por semana, pero resultó que era necesario tiempo para evitar problemas en el proceso de desarrollo. El objetivo de la universidad era que aprendiéramos a construir de manera competente el proceso de desarrollo, y las empresas, como clientes, estaban más interesadas en el resultado. Esto, por supuesto, trajo mucha confusión, pero ayudó a combinar habilidades teóricas y prácticas. Suficiente complejidad y carga aseguraron la presencia de motivación, lo que resultó en un proyecto exitoso.
Inicialmente, dos personas de nuestro equipo se dedicaron al desarrollo puro, una persona se hizo cargo de los documentos y otra se sumó a la creación del entorno. Sin embargo, más tarde se nos unieron tres solteros más, con quienes nos convertimos en un solo equipo. La universidad decidió lanzar un proyecto industrial de prueba para estudiantes del tercer año de estudio. Ampliar el equipo de 4 a 7 personas aceleró enormemente el proceso, porque nuestros solteros podían realizar fácilmente tareas relacionadas con el desarrollo. Ekaterina Levchenko ayudó a escribir código python y scripts por lotes para el banco de pruebas. Ansat Abirov y Ruslan Kim actuaron como desarrolladores, se dedicaron a la selección y optimización de algoritmos.
Trabajamos en este formato hasta finales de mayo, cuando se lanzó el experimento. En este momento, el proyecto industrial para solteros terminó. Dos de ellos comenzaron una pasantía en Acronis y continuaron trabajando con nosotros. Por lo tanto, después de mayo, ya trabajamos como un equipo de 6 personas.
Antes de nosotros estaba el tercer semestre, que en Innopolis está libre de actividades académicas. Teníamos solo 2 asignaturas optativas, y el resto del tiempo lo dedicamos a un proyecto industrial. Fue en el tercer semestre que el trabajo en el servicio fue intensivo. El proceso de desarrollo cayó completamente en los rieles, demostraciones e informes se hicieron regulares. En este formato, trabajamos durante 1,5 meses y, a fines de julio, casi terminamos la parte de desarrollo del trabajo.
Detalles técnicos
Primero, se formularon los requisitos para un servicio, que debería interactuar adecuadamente con el controlador del minifiltro del sistema de archivos (que es lo que puede leer
aquí ) y se pensó su arquitectura. Con la vista puesta en la simplicidad del soporte de código adicional, de inmediato proporcionamos un enfoque modular. Nuestro servicio incluye varios gerentes, agentes y manejadores, e incluso antes del inicio de la codificación, se estableció la capacidad de trabajar en modo paralelo.
Sin embargo, después de discutir la arquitectura en una reunión con los chicos de Acronis, se decidió realizar un experimento primero y luego asumir el servicio en sí. Como resultado, el desarrollo tomó solo 2.5 meses. El resto del tiempo, realizamos un experimento para encontrar la lista mínima suficiente de archivos en los que Windows podría ejecutarse. En un sistema real, este conjunto de archivos se genera utilizando el controlador, sin embargo, decidimos encontrar este conjunto de forma heurística, utilizando el método de media división, para verificar el funcionamiento del controlador.
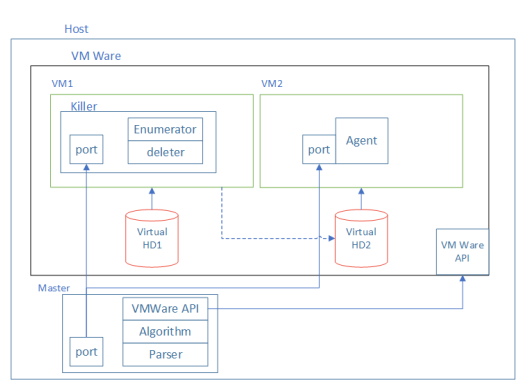 El soporte del experimento.
El soporte del experimento.
Para hacer esto, armamos un stand en Python desde dos máquinas virtuales. Uno de ellos trabajó en Linux, y el segundo cargó Windows. Se configuraron dos discos para ellos: Virtual HD1 y Virtual HD2. Ambas unidades se conectaron a VM1 en el que se instaló Linux. En esta máquina virtual en HD1, se instaló la aplicación Killer, que "dañó" HD2. El daño se refiere a la eliminación de algunos archivos del disco. HD2 era un disco de arranque para VM2 que funcionaba en Windows. Después del "daño" en el disco, intentamos iniciar VM2. Si fue posible hacer esto, los archivos eliminados del disco se consideraron innecesarios de ejecutar.
Para automatizar este proceso, intentamos eliminar archivos no al azar, sino como parte de un enfoque previamente pensado. El algoritmo consistió en 3 pasos:
- Divide la lista de archivos a la mitad.
- Eliminar uno de los medios archivos.
- Intenta iniciar el sistema. Si el sistema se inició, agregue los archivos eliminados a la lista de innecesarios. De lo contrario, volvemos al paso 1.
Primero, decidimos simular el algoritmo. Supongamos que hay 1,000,000 de archivos en el sistema de archivos. En este caso, la búsqueda más efectiva de archivos críticos se produjo en los casos en que los archivos críticos representaban aproximadamente el 15% del total.
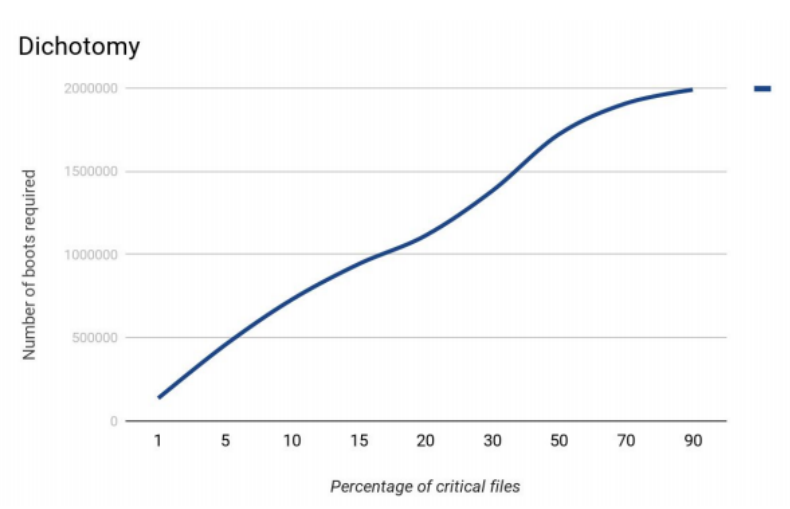 Método de media división.
Método de media división.Al principio, hubo muchos problemas con el experimento. Durante 2-3 semanas estuvo listo un banco de pruebas. Y otros 1-1.5 meses tuve que atrapar errores, agregar el código y aplicar varios trucos para que el soporte funcione.
Lo más difícil fue detectar un error asociado con las operaciones de almacenamiento en caché del disco. El experimento funcionó durante 2 días y produjo resultados muy optimistas que fueron varias veces más rápidos que las simulaciones. Sin embargo, la prueba de archivo crítico falló, el sistema no se inició. Resultó que durante el apagado forzado de la máquina virtual, no se realizaron las operaciones de borrado que el sistema de archivos almacenó en caché y, en consecuencia, el disco no se borró por completo. Como resultado, el algoritmo recibió resultados incorrectos, y durante un par de días forzamos todas nuestras circunvoluciones para resolverlo todo.
En cierto momento, notamos que durante la operación continua el algoritmo estaba enterrado en uno de los segmentos del sistema de archivos y comenzamos a tratar de eliminar los mismos archivos (con la esperanza de un nuevo resultado). Esto sucedió en momentos en que el algoritmo descansaba en regiones donde la mayoría era necesaria, mientras se elegía el intervalo incorrecto para la eliminación. En este punto, decidimos agregar una lista de reorganización de archivos. Es decir, una vez que algunas iteraciones, la lista de archivos fue barajada. Esto ayudó a eliminar el algoritmo de tales palos.
Cuando todo estuvo listo, lanzamos estas dos máquinas virtuales durante 3 días. En total, pasaron alrededor de 600 iteraciones, entre las cuales hubo más de 20 lanzamientos exitosos. Quedó claro que este experimento se puede ejecutar durante mucho tiempo, así como en máquinas más potentes, para encontrar el tamaño de archivo óptimo para ejecutar Windows. Además, el algoritmo se puede distribuir en varias máquinas para acelerar aún más este proceso.
En nuestro caso, además de Windows, solo había Python y nuestro servicio en el disco. En tres días logramos reducir el número de archivos de 70 mil a 50 mil. La lista de archivos se redujo solo en un 28%, pero quedó claro que este enfoque está funcionando y le permite determinar el conjunto mínimo de archivos necesarios para cargar el sistema operativo.
Estructura de servicio
Veamos una pequeña estructura de servicio. El módulo de servicio principal es un gestor de colas. Como obtenemos una lista de archivos del controlador, necesitamos restaurar los archivos de esta lista. Para hacer esto, creamos un giro con prioridades.
Tenemos una lista de archivos que se restauran a su vez. Y si aparecen nuevas solicitudes de acceso, los archivos que se necesitan con urgencia se restauran con prioridad. Gracias a esto, al comienzo de la cola habrá aquellos archivos que el usuario realmente necesita ahora, y al final de la cola habrá aquellos archivos que puedan ser necesarios en el futuro. Pero con el trabajo activo del usuario, se puede formar una "cola de objetos extraordinarios", así como una lista de archivos que se están restaurando en este momento. Además, la operación de búsqueda debería haberse aplicado a todas estas colas a la vez. Por desgracia, no encontramos una implementación de la cola que pudiera establecer varias prioridades de archivo, al tiempo que admitía la búsqueda, así como cambiar las prioridades sobre la marcha. No queríamos adaptarnos a las estructuras de datos existentes y, por lo tanto, tuvimos que escribir las nuestras y configurar la capacidad de trabajar con ellas.
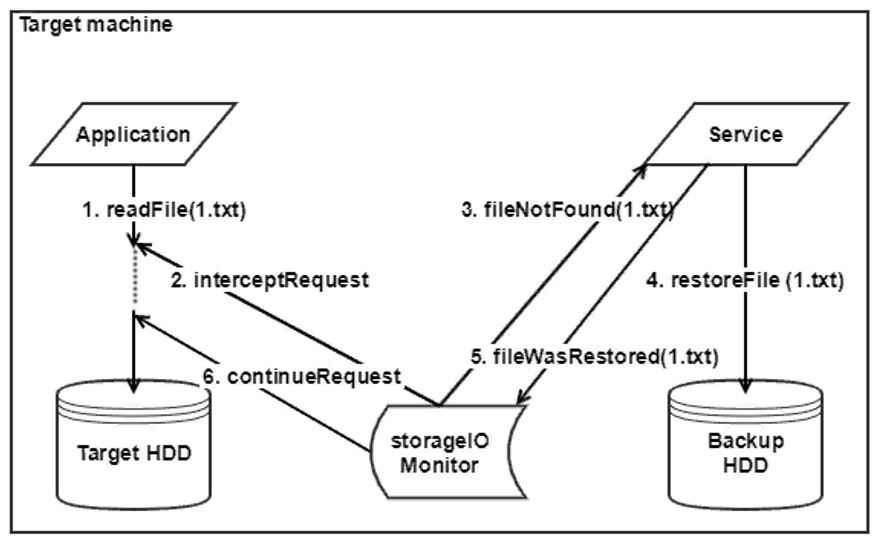
Nuestro servicio deberá comunicarse primero con el controlador en el que Daulet trabajó, y luego con los componentes responsables de restaurar los archivos ... Por lo tanto, para empezar, decidimos crear nuestro propio pequeño emulador del sistema de recuperación, que podría emitir archivos desde una unidad externa para que puedan ser restaurar y probar el servicio.
En total, se proporcionaron dos modos de funcionamiento: el modo normal y el modo de recuperación. En modo normal, el controlador nos envía una lista de archivos afectados por el inicio del sistema operativo. Luego, mientras el sistema se está ejecutando, el controlador monitorea todas las operaciones de archivos y envía notificaciones a nuestro servicio y, a su vez, cambia la lista de archivos. En modo de recuperación, el controlador notifica al servicio que la recuperación del sistema es necesaria. El servicio pone en cola los archivos, ejecuta agentes de software que solicitan archivos de la copia de seguridad y comienza el proceso de recuperación.
Diploma, invitación al trabajo y nuevos proyectos.
Cuando el servicio estuvo listo y probado, tuvimos la última actividad en el proyecto. Era necesario actualizar y estructurar todos los artefactos que habíamos acumulado, así como presentar nuestros resultados al cliente y a la universidad. Para la empresa, este fue otro paso hacia la implementación del proyecto, para la universidad con nuestra tesis de graduación.
Después de la presentación, se hizo una propuesta a los estudiantes. Y después de unas semanas voy a trabajar a Acronis. Los resultados del proyecto llevaron a los desarrolladores a pensar que es posible hacer que el servicio sea más eficiente al reducirlo al nivel de la aplicación nativa de Windows. Pero más sobre eso en el próximo artículo.