
Saludos habr.
Si alguien ejecuta un sistema web de grafito y se enfrenta a un problema de rendimiento de almacenamiento (IO, consumo de espacio en disco), entonces la posibilidad de que ClickHouse se haya lanzado como reemplazo debería apuntar a uno. Esta declaración implica que una implementación de terceros, como carbonwriter o go-carbon, ya se usa como la métrica receptora del demonio.
ClickHouse resuelve bien los problemas descritos. Por ejemplo, después de transferir datos de 2TiB de whisper, caben en 300GiB. No me detendré en la comparación en detalle; hay suficientes artículos sobre este tema. Además, hasta hace poco, todo era perfecto con nuestro almacenamiento ClickHouse.
Problemas de consumo
A primera vista, todo debería funcionar bien. Siguiendo la documentación , creamos una configuración para el esquema de almacenamiento de métricas (en adelante retention ), luego creamos una tabla de acuerdo con la recomendación del backend seleccionado para grafito-web: carbon-clickhouse + graphite-clickhouse o graphouse , dependiendo de qué pila se use. Y ... la bomba de tiempo se enciende.
Para entender cuál, necesita saber cómo los insertos y la vida útil de los datos en las tablas de la familia de motores * MergeTree ClickHouse (diagramas tomados de la presentación de Alexei Zatelepin):
- Se inserta un

- Cada uno de estos bloques antes de escribir en el disco se ordena de acuerdo con la tecla
ORDER BY especificada al crear la tabla. - Después de ordenar, una
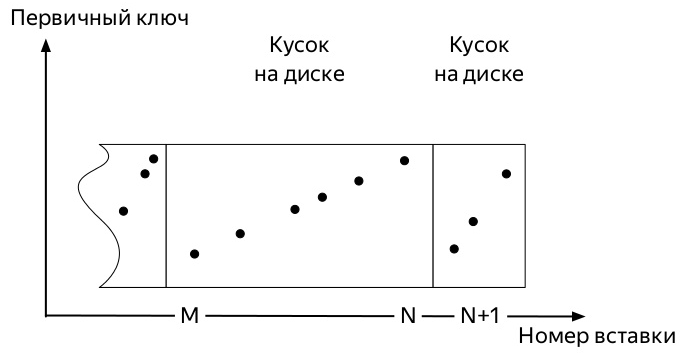
- El servidor monitorea en segundo plano que no hay muchas piezas de este tipo e inicia las
merge , en adelante fusionar).
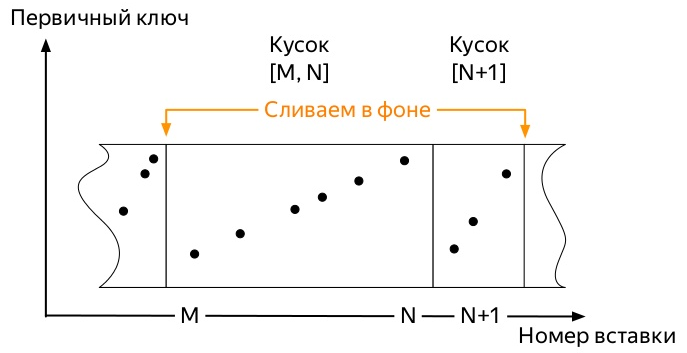

- El servidor deja de ejecutar fusiones por sí solo tan pronto como los datos ya no ingresen activamente a
partition , pero puede iniciar el proceso manualmente con el comando OPTIMIZE . - Si solo queda una pieza en la partición, entonces no puede iniciar la fusión con el comando habitual, debe usar
OPTIMIZE ... FINAL
Entonces, llegan las primeras métricas. Y ocupan un cierto espacio. Los eventos posteriores pueden variar ligeramente dependiendo de muchos factores:
- La clave de partición puede ser muy pequeña (día) o muy grande (varios meses).
- La configuración de retención puede acomodar varios umbrales significativos de agregación de datos dentro de la partición activa (donde va el registro de métricas), o puede que no.
- Si hay muchos datos, las primeras piezas, que debido a las fusiones de fondo ya pueden ser enormes (al elegir una clave de partición subóptima), no podrán manipularse con pequeñas piezas nuevas.
Y todo siempre termina igual. El lugar ocupado por las métricas en ClickHouse solo crece si:
- no aplique
OPTIMIZE ... FINAL manualmente o - no inserte datos en todas las particiones de forma continua para comenzar una fusión en segundo plano tarde o temprano
El segundo método parece el más fácil de implementar. y, por lo tanto, está equivocado y fue probado primero.
Escribí un script de Python bastante simple que enviaba métricas ficticias para cada día en los últimos 4 años y corría cada hora por la corona.
Dado que todo el trabajo de ClickHouse DBMS se basa en el hecho de que este sistema hará todo el trabajo de fondo tarde o temprano, pero no se sabe cuándo, no podía esperar hasta que las grandes piezas viejas se dignen para comenzar a fusionarse con otras pequeñas. Quedó claro que teníamos que buscar una forma de automatizar las optimizaciones forzadas.

Eche un vistazo a la estructura de la tabla system.parts . Esta es información completa sobre cada pieza de todas las tablas en el servidor ClickHouse. Contiene, entre otras cosas, las siguientes columnas:
- Nombre de DB (
database ); - nombre de la tabla (
table ); - Nombre de partición e ID (
partition y partition_id ); - cuando se creó la pieza (
modification_time ); - fecha mínima y máxima en una pieza (la partición se realiza por día) (
min_date y max_date );
También hay una tabla system.graphite_retentions , con los siguientes campos interesantes:
- Nombre de la base de datos (
Tables.database ); - nombre de la tabla (
Tables.table ); - la edad de la métrica cuando se debe aplicar la siguiente agregación (
age );
Entonces
- Tenemos una tabla de piezas y una tabla de reglas de agregación.
- Combine su intersección y obtenga todas las tablas * GraphiteMergeTree.
- Estamos buscando todas las particiones en las que:
- más de una pieza
- o ha llegado el momento de aplicar la siguiente regla de agregación,
modification_time anterior a ese momento.
Implementación
Esta solicitud SELECT concat(p.database, '.', p.table) AS table, p.partition_id AS partition_id, p.partition AS partition,
devuelve cada una de las particiones de las tablas * GraphiteMergeTree cuya fusión debería liberar espacio en disco. Todo lo que queda es la pequeña cosa: revíselos todos con la solicitud OPTIMIZE ... FINAL . La implementación final también tuvo en cuenta el momento en que no hay necesidad de tocar particiones con un registro activo.
Esto es exactamente lo que hace el proyecto de grafito-ch-optimizador . Ex colegas de Yandex.Market lo probaron en el producto, el resultado del trabajo se puede ver a continuación.

Si ejecuta el programa en el servidor con ClickHouse, comenzará a funcionar en modo demonio. Una vez por hora, se ejecutará una solicitud, verificando si hay nuevas particiones de más de tres días que puedan optimizarse.
En un futuro cercano, para proporcionar al menos paquetes deb, y si es posible, también rpm.
UPD: los paquetes están disponibles en las versiones de github , y las imágenes de trabajo se pueden encontrar en docker-hub en el repositorio de innogames / graphite-ch-optimizer.
En lugar de una conclusión
En los últimos más de 9 meses, pasé mucho tiempo dentro de mi empresa InnoGames en la unión de ClickHouse y Graphite-web. Fue una buena experiencia, que hizo posible cambiar rápidamente de whisper a ClickHouse como depósito de métricas. Espero que este artículo sea algo así como el comienzo de un ciclo sobre las mejoras que hemos realizado en varias partes de esta pila y lo que se hará en el futuro.
Se gastaron varios litros de cerveza y días administrativos en el desarrollo de solicitudes junto con v0devil , por lo que quiero expresarle mi agradecimiento. Y también por revisar este artículo.
Página del proyecto en github