PostgreSQL utiliza estadísticas acumuladas sobre la distribución de valores de datos en las tablas de destino para seleccionar el plan de ejecución de consultas más eficiente.
Se actualiza ejecutando explícitamente los comandos
ANALYZE y
VACUUM ANALYZE o en segundo plano mediante el
proceso autovacuum / autoanalyze . Pero si las estadísticas no tienen tiempo para actualizarse, pueden ocurrir problemas.
¿Cómo detectar y solucionar tal problema?
La opción principal cuando tal situación puede ocurrir es si el conjunto de datos ha cambiado dramáticamente en la tabla. Es decir,
generó una gran cantidad de INSERT / UPDATE / DELETE o simplemente "vertió" los datos en una tabla vacía, por ejemplo,
al restaurar desde una copia de seguridad .
La ayuda para la
utilidad de recuperación estándar
pg_restore incluso dice explícitamente:
Después de la recuperación, tiene sentido ejecutar ANALYZE para cada tabla restaurada para que el optimizador reciba estadísticas actualizadas.
Por lo tanto, si está haciendo algo similar con la base de datos, no sea perezoso, ejecute
ANALYZE inmediatamente para las tablas más "en negrita" o para toda la base de datos.
Determinamos la presencia de un problema.
¿Por qué se ve exactamente la situación de "todo malo"? Por lo general, algo como esto:
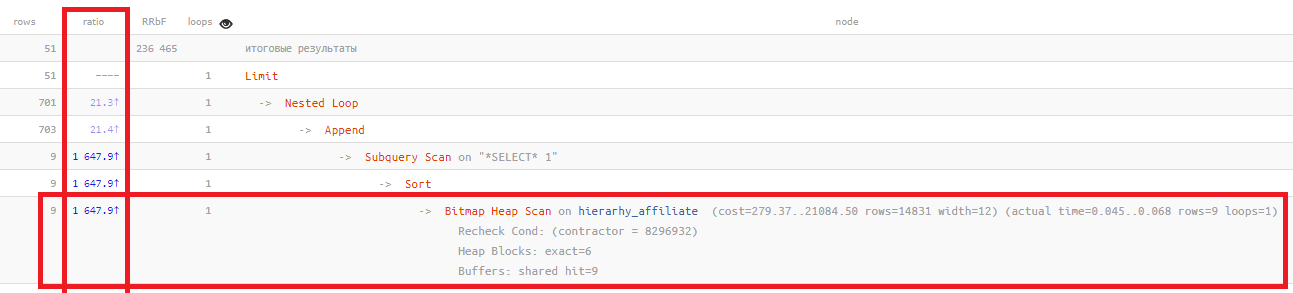
La columna de
proporción solo muestra la relación "a veces" entre el número de registros planeados sobre la base de estadísticas y el número realmente leído:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
Cuanto mayor es este valor, peor son las estadísticas que reflejan la situación real en su tabla. Normalmente, generalmente
no supera los cientos , en este ejemplo,
medio millar de veces .
Esto lleva a la elección de un plan ineficaz y, como resultado, la
carga más salvaje en la base . Para eliminarlo rápidamente, solo necesita escuchar las recomendaciones del manual y pasar por
ANALIZAR en las tablas principales.
Aquí está la carga de la CPU en el servidor de la base de datos antes y después de esta operación para el ejemplo anterior:
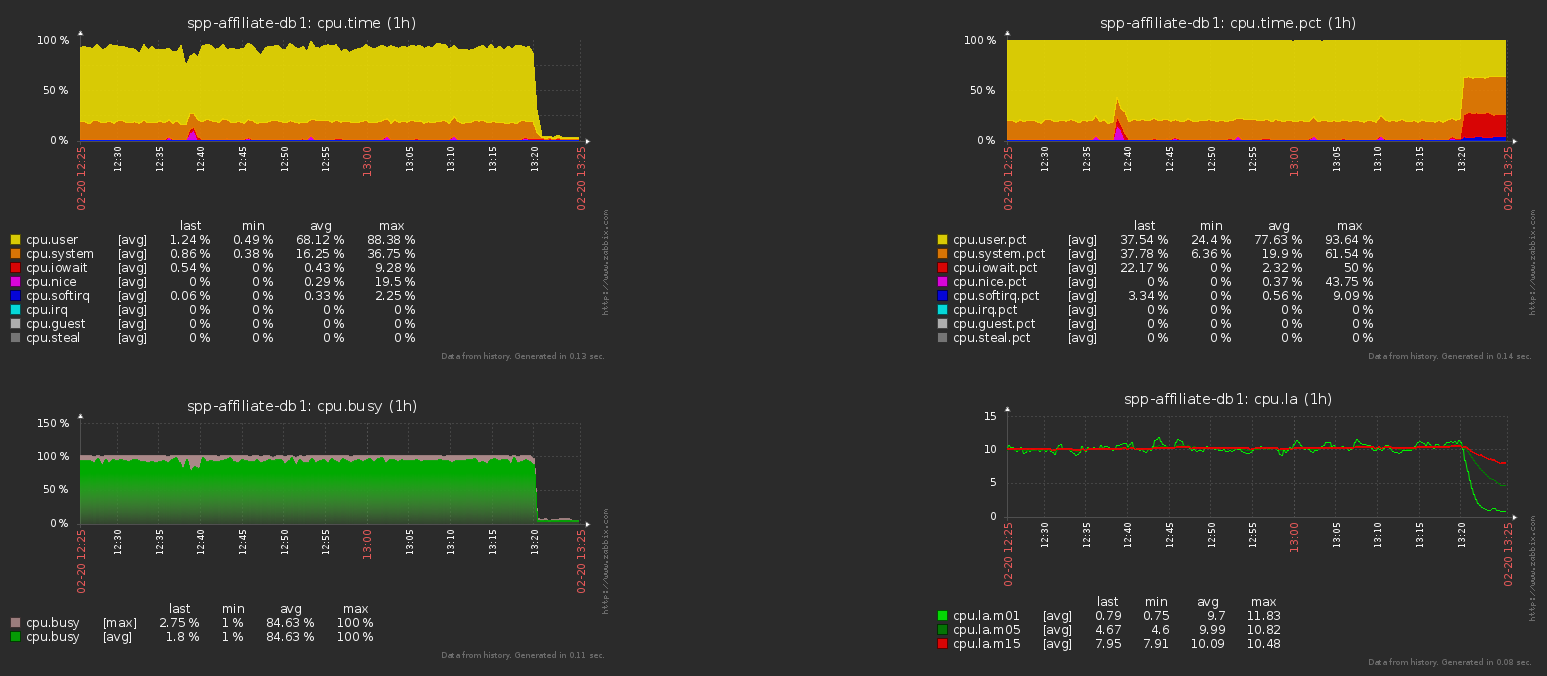
Tabla actualizada con frecuencia
Pero, ¿qué pasa si la tabla realmente cambia una gran cantidad de registros? Por ejemplo, este es algún tipo de búfer o cola de procesamiento donde se agregan constantemente nuevas entradas y se eliminan las antiguas.
En este caso, los siguientes
parámetros de configuración nos ayudarán:
autovacuum_naptime (entero)
Establece el retraso mínimo entre dos ejecuciones de limpieza automática para una sola base de datos. El demonio de limpieza automática escanea la base de datos en el intervalo de tiempo especificado y emite los comandos VACUUM y ANALYZE cuando sea necesario para las tablas en esta base de datos. Si este valor se especifica sin unidades, se considera establecido en segundos. Por defecto, el retraso es de un minuto (1 min). Este parámetro solo se puede establecer en postgresql.conf o en la línea de comando cuando se inicia el servidor.
autovacuum_analyze_threshold (entero)
Establece el número mínimo de tuplas agregadas, modificadas o eliminadas en las que ANALYZE se ejecutará para una sola tabla. El valor predeterminado es 50 tuplas. Este parámetro solo se puede establecer en postgresql.conf o en la línea de comando cuando se inicia el servidor. Sin embargo, este valor se puede anular para las tablas seleccionadas cambiando su configuración de almacenamiento.
autovacuum_analyze_scale_factor (coma flotante)
Especifica el porcentaje del tamaño de la tabla que se agregará a autovacuum_analyze_threshold cuando se seleccione el umbral del comando ANALYZE. El valor predeterminado es 0.1 (10% del tamaño de la tabla). Puede establecer este parámetro solo en postgresql.conf o en la línea de comando cuando se inicia el servidor. Sin embargo, este valor se puede anular para las tablas seleccionadas cambiando su configuración de almacenamiento.
SWSS
A veces, al configurar un servidor,
autovacuum_naptime se "
aplasta " a "una vez al día" (1d) para
que los autoVACUUM recorran menos la base de datos y
consuman menos recursos.
A veces, aunque muy raramente, incluso puede justificarse, por ejemplo, si tiene
miles de tablas / secciones en una base de datos (incluso si se presentan en diferentes patrones).
Debido a que la definición misma de qué tablas específicas de la lista completa deben procesarse, durante la inicialización del proceso de vacío automático,
puede ocupar una parte considerable de los recursos y ralentizar el servidor .
Solo en este caso, tendrá problemas con una tabla modificada con frecuencia.
Aquí: establezca un intervalo de inicio más adecuado o persiga ANALIZAR de acuerdo con dicha tabla en modo "manual" por algunos motivos aplicados (por ejemplo, un temporizador externo o después del final de la siguiente etapa del procesamiento de la cola).
¡Camarada, mantenga las estadísticas actualizadas!