Hola habr
Home Credit es un sistema grande y muy dinámico, que a veces es difícil de seguir. Para ayudar a los empleados a mantenerse al tanto de todas las noticias y cambios y mantener el ritmo en todas partes, estamos introduciendo activamente algoritmos de aprendizaje automático. En nuestro Banco, los bots de chat ya toman parte del trabajo de los operadores, las opiniones de los clientes son analizadas no solo por expertos, sino también por algoritmos inteligentes para procesar el lenguaje natural.
Hoy les contaré cómo ayudamos a los especialistas en la operación de servicios bancarios a deshacerse de la necesidad de mirar constantemente los paneles de control de los sistemas de monitoreo, es decir, pidieron ayuda para el aprendizaje automático. Eso es lo que tenemos.

¿Cómo funciona el monitoreo manual?
El lugar de trabajo típico de un especialista en operaciones se ve como en la imagen de arriba, y él pasa la mayor parte de su tiempo mirando los tableros. Cualquier actividad sospechosa en el sistema, por ejemplo, cuando la red se ha caído o ha llovido una NullPointerException, atraerá inmediatamente la atención; una investigación comenzará de inmediato.
El hombre no es una máquina. Puede distraerse, ir a cenar, contestar el teléfono. Y cuando el número de gráficos excede de cien, se hace difícil unirlos y llegar al fondo de la esencia.
Otro problema es que hay una familia de errores que ocurren constantemente, pero que no afectan seriamente el comportamiento del sistema. Por ejemplo, un microservicio de terceros se cayó y los paneles se sacudieron notablemente, pero de hecho el sistema está fuera de peligro. A primera vista, no siempre está claro cómo el comportamiento anormal es crítico y qué hay detrás. Para establecer los motivos en detalle, debe ir al servidor y profundizar en los registros. Tal operación tiene que hacerse docenas de veces al día. Encomendamos al menos parcialmente al auto.
Aprendizaje automático como asistente inteligente
Existen tres fuentes principales de datos: Zabbix, ElasticSearch y un sistema interno de monitoreo de métricas comerciales. Utilizamos Zabbix para monitorear el hardware, la red y la disponibilidad de varios puntos de entrada a los sistemas. Con ElasticSearch, analiza y extrae el registro de mensajes. Varios errores, ejecuciones y consultas se utilizan como métricas. Los analistas de negocios, sin embargo, monitorean el desempeño de los usuarios: la cantidad de transferencias, ventas y otras actividades comerciales. Los datos se recopilan con una frecuencia de una vez por minuto y se agregan a la base de datos. Bueno, los datos se recopilan, es hora de escribir un montón de si para poner el aprendizaje automático en la batalla.
Formulamos el problema de la siguiente manera: teniendo las métricas del sistema en la entrada, clasificaremos el estado final del sistema: regular o anormal. En este contexto, el problema encaja perfectamente en el paradigma de aprender con un maestro. Esto significa que todo nuestro conjunto de datos de entrenamiento debe estar etiquetado. En otras palabras, cada minuto de la operación del sistema debe tener una etiqueta de 0 (comportamiento normal) o -1 (comportamiento anómalo).
En la vida, resulta que no todo es tan color de rosa como nos gustaría. Como regla general, no todos los incidentes se registran en JIRA, queda mucho en el correo y no va más allá, y a veces los límites de tiempo de la anomalía son borrosos o inexactos. Resulta que construir un conjunto de datos de alta calidad en el campo de datos históricos no es una tarea trivial.
Si bien los nuevos datos recién comienzan a presentarse, intentemos exprimir el beneficio de lo que ya tenemos. Para los casos en que los datos no tienen un marcado, se utilizan algoritmos de aprendizaje sin un maestro. Procederemos por el hecho de que la mayoría de las veces el sistema funciona correctamente, pero ocasionalmente ocurren eventos imprevistos: errores (sin ellos), la base se cayó o, por ejemplo, la excavadora Petr golpeó el cable del centro de datos. Por lo tanto, reducimos nuestra tarea a la búsqueda de anomalías, a saber, la búsqueda de un nuevo comportamiento del sistema (Detección de novedades).
Para hacer esto, use el algoritmo Bosque aislado. Ya está implementado en la biblioteca sklearn. Utilizaremos métricas de los sistemas de monitoreo como características.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
Capacitaremos a los bosques aislados sobre datos históricos y utilizaremos los nuevos datos que ya hemos logrado marcar para evaluar la calidad. Por lo tanto, queda por elegir los hiperparámetros del modelo y el tamaño del conjunto de datos para el entrenamiento.
Ahora los datos de estado, que se recopilan cada minuto, se ingresan al modelo entrenado y obtienen la etiqueta 0 o -1.
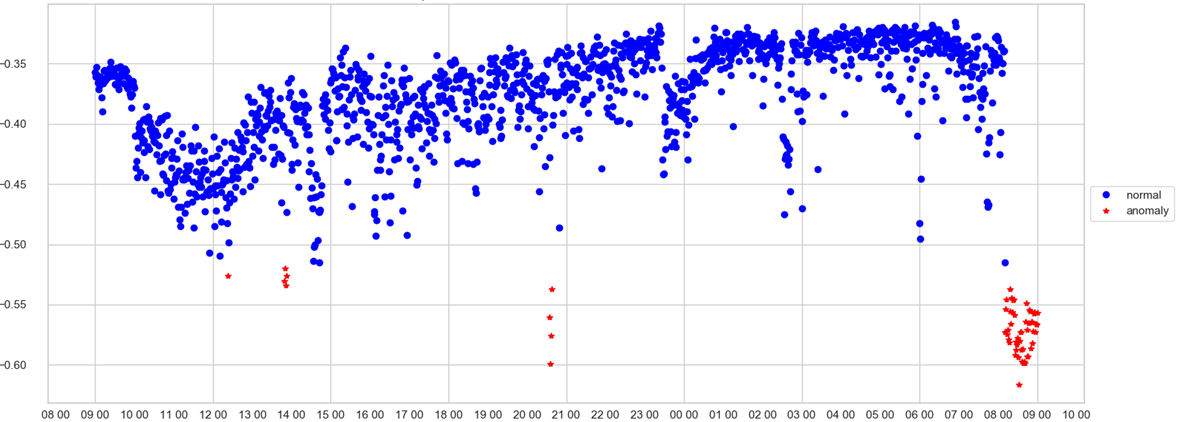
Un operador puede rastrear solo un horario. En el eje X - tiempo, en Y - puntaje de anomalía, es decir, qué tan fuerte el modelo consideraba anormal el estado del sistema en este momento. Si el valor de la velocidad ha pasado por la papelera (que el modelo selecciona por sí mismo), el punto se tiñe de rojo y se registra una anomalía.
Ahora sabemos que el sistema funciona en un modo inusual o que una situación de emergencia ocurrió en tiempo casi real. Esto es muy bueno, pero ¿qué pasa con el operador al momento de recibir la señal sobre la anomalía? ¿Qué tablero mirar? Intentemos abrir el "recuadro negro" de nuestro modelo y comprender cómo toma decisiones.
Interpretando un modelo usando LIME
Existen diferentes enfoques sobre cómo abrir la caja negra de un modelo entrenado y comprender lo que está en la mente de la máquina. Con una regresión logística o un árbol de decisión, todo está claro, no es difícil de entender sobre la base de la cual se tomó la decisión. Con el bosque aislado, las cosas son más complicadas. En primer lugar, hay un accidente dentro del algoritmo, y en segundo lugar, es un algoritmo de aprendizaje sin un maestro.
El primer candidato fue la biblioteca LIME, que utiliza el enfoque agnóstico del modelo, que ayuda a interpretar cualquier modelo, lo principal es que la salida del modelo tiene una distribución probabilística entre las clases. De acuerdo, por supuesto, el resultado no es la probabilidad, pero pronto, pero intentemos normalizarlos en el rango de 0 a 1 y tratarlo como probabilidad. Por lo tanto, pudimos proporcionar un formato de entrada compatible con LIME.
La forma en que LIME interpretó los resultados fue decepcionante. En primer lugar, como interpretación, hubo varios signos más importantes en la salida y, en la mayoría de los casos, solo uno de ellos realmente reflejó adecuadamente la esencia de la decisión, el resto agregó ruido. El segundo inconveniente fue que la interpretación era inestable y a menudo producía diferentes listas de signos de una carrera a otra. Para obtener resultados más estables, tuvo que ejecutar la interpretación varias veces y de alguna manera promediar los resultados. Realmente no quería hacer esto.
SHAP - puente de persona a carro
Después de eso, nuestros ojos se posaron en otra biblioteca para la interpretación de modelos: SHAP. La idea detrás de la biblioteca surgió de la teoría de juegos. La biblioteca también tiene una hermosa visualización. Después de mirar los ejemplos, nos dimos cuenta con frustración de que SHAP no podía interpretar el Bosque Aislado, ¡y realmente queríamos hacerlo! Pero, por otro lado, SHAP puede diseccionar con seguridad XGBoost. Pensamos, ¿y si nos enseñan a hacer XGBoost lo mismo que puede hacer el Bosque Aislado? Para hacer esto, tomamos todo nuestro conjunto de datos y lo marcamos con Bosque aislado. Además, como objetivo, no tomaron una clase, sino un scor, que se asignó al Bosque Aislado. ¡Pronosticaremos según todas las métricas la velocidad que proporcionaría el Bosque Aislado, pero solo con XGBoot! Apenas dicho que hecho. Ejecutaremos nuestro conjunto de datos etiquetados a través de XGBoost. Y ahora, ahora sabe cómo predecir la velocidad de la misma manera que el Bosque Aislado. ¡Hurra, ahora podemos usar SHAP!
El primer paso es crear un objeto TreeExplainer, pasando el modelo como parámetro. A continuación, se calculan los valores de shap, que nos permiten dar una explicación de cómo el modelo tomó esta o aquella decisión.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
SHAP le permite interpretar tanto el modelo como un todo y los resultados para ejemplos específicos. Por ejemplo, puede obtener una explicación para un ejemplo específico utilizando el método force_plot (), que recibe los valores de entrada y los valores del ejemplo en sí.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
Resulta el siguiente gráfico, que muestra qué características del modelo y cuánto influyeron en la decisión.

Ayudamos a los negocios
Ahora, sabiendo qué métricas hicieron una contribución significativa a la tasa general de anormalidad, es posible establecer a qué nivel surgió el problema y, lo más importante, si tuvo un impacto en los usuarios finales del sistema.

Cada vez que se detecta una anomalía, se obtiene una lista de métricas que tienen el mayor impacto en la decisión. Si la lista incluye métricas que rastrean directamente los indicadores relacionados con el negocio, esto se menciona en la alerta de una manera especial, lo que aumenta automáticamente la prioridad de la anomalía.
Este es solo el primer pero importante paso para fortalecer y automatizar el sistema de monitoreo mediante el aprendizaje automático, que puede aumentar significativamente la velocidad de identificación de las causas y la influencia del comportamiento anormal del sistema.
Referenciasscikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap