 Fuente
FuenteHola Habr! Mi nombre es Maxim Pchelin, y lidero el desarrollo de BI-DWH en MyGames (división de juegos de Mail.ru Group). En este artículo hablaré sobre cómo y por qué creamos un almacenamiento DataLake orientado al cliente.
El artículo consta de tres partes. Primero, explicaré por qué decidimos implementar DataLake. En la segunda parte, describiré qué tecnologías y soluciones utilizamos para que el almacenamiento pueda funcionar y llenarse de datos. Y en la tercera parte, describiré lo que hacemos para mejorar la calidad de nuestros servicios.
Lo que nos trajo a DataLake
En
MyGames, trabajamos en el departamento de BI-DWH y
brindamos servicios de dos categorías: un repositorio para analistas de datos y servicios de informes regulares para usuarios comerciales (gerentes, especialistas en marketing, desarrolladores de juegos y otros).
¿Por qué tal almacenamiento no estándar?
Por lo general, BI-DWH no implica la implementación del almacenamiento de DataLake; esto no se puede llamar una solución típica. ¿Y cómo se construyen entonces estos servicios?
Por lo general, una empresa tiene un proyecto; en nuestro caso, este es un juego. El proyecto tiene un sistema de registro que con mayor frecuencia escribe datos en la base de datos. Además de esta base, se crean escaparates para agregados, métricas y otras entidades para análisis futuros. Los informes regulares se crean sobre la base de escaparates que utilizan cualquier herramienta de BI adecuada, así como sistemas de análisis ad-hoc, comenzando con consultas SQL simples y tablas de Excel, y terminando con Jupyter Notebook para DS y ML. Todo el sistema es compatible con un equipo de desarrollo.
Supongamos que otra empresa nace en una empresa. Tener otro equipo de desarrollo e infraestructura debajo es atractivo, pero costoso. Por lo tanto, el proyecto debe estar "conectado". Esto se puede hacer de diferentes maneras: en el nivel de la base de datos, en el nivel de la tienda, o al menos en el nivel de visualización: el problema está resuelto.
¿Y si la empresa tiene un tercer proyecto? "Compartir" ya puede terminar mal: puede haber problemas con la asignación de recursos o derechos de acceso. Por ejemplo, uno de los proyectos lo realiza un equipo externo que no necesita saber nada sobre los dos primeros proyectos. La situación se está volviendo más arriesgada.
Ahora imagine que no hay tres proyectos, sino mucho más. Y sucedió que este es exactamente nuestro caso.
MyGames es una de las divisiones más grandes del Grupo Mail.ru, tenemos 150 proyectos en nuestra cartera. Además, todos son muy diferentes: su propio desarrollo y la compra para operaciones en Rusia. Funcionan en varias plataformas: PC, Xbox, Playstation, iOS y Android. Estos proyectos se desarrollan en diez oficinas en todo el mundo con cientos de tomadores de decisiones.

Para los negocios, esto es excelente, pero complica la tarea para el equipo de BI-DWH.
En nuestros juegos, se registran muchas acciones de los jugadores: cuándo ingresó al juego, dónde y cómo alcanzó los niveles, con quién y con qué éxito luchó, qué y para qué moneda compró. Necesitamos recopilar todos estos datos para cada uno de los juegos.
Necesitamos esto para que la empresa pueda recibir respuestas a sus preguntas sobre los proyectos. ¿Qué pasó la semana pasada después del lanzamiento de la acción? ¿Cuáles son nuestras previsiones de ingresos o uso de las capacidades del servidor de juegos para el próximo mes? ¿Qué se puede hacer para influir en estos pronósticos?
Es importante que MyGames no imponga un paradigma de desarrollo en los proyectos. Cada estudio de juegos registra datos ya que los considera más eficientes. Algunos proyectos generan registros en el lado del cliente, algunos en el lado del servidor. Algunos proyectos usan RDBMS para recopilarlos, mientras que otros usan herramientas completamente diferentes: Kafka, Elasticsearch, Hadoop, Tarantool o Redis. Y recurrimos a estas fuentes de datos para cargarlos en el repositorio.
¿Qué quieres de nuestro BI-DWH?
En primer lugar, desde el departamento de BI-DWH quieren recibir datos de todos nuestros juegos para resolver tanto las tareas operativas diarias como las estratégicas. Comenzando por cuántas vidas dar un monstruo terrible al final del nivel, y terminando con cómo distribuir adecuadamente los recursos dentro de la empresa: qué proyectos deberían dar más desarrolladores o quién debería asignar un presupuesto de marketing.
La fiabilidad también se espera de nosotros. Trabajamos en una gran empresa y no podemos vivir según el principio de "Ayer trabajamos, pero hoy el sistema está en su lugar, y solo aumentará en una semana si se nos ocurre algo".
Quieren ahorros de nosotros. Nos complacería resolver todos los problemas comprando hierro o contratando personas. Pero somos una organización comercial y no podemos pagarla. Tratamos de hacer que la empresa se beneficie.
Es importante destacar que quieren que nos centremos en el cliente. Los clientes en este caso son nuestros consumidores, clientes: gerentes, analistas, etc. Debemos adaptarnos a nuestros juegos y trabajar de tal manera que sea conveniente que los clientes cooperen con nosotros. Por ejemplo, en algunos casos, cuando compramos proyectos en el mercado asiático para operaciones, junto con el juego podemos obtener bases con nombres en chino. Y la documentación de estas bases en chino. Podríamos buscar un desarrollador de ETL con conocimientos de chino o negarnos a descargar datos en el juego, pero en cambio, el equipo y yo nos encerramos en la sala de reuniones, tomamos el reloj y comenzamos a jugar. Entra y sal del juego, compra, dispara, muere. Y miramos qué y cuándo aparece en esta o aquella tabla. Luego, escribimos la documentación y, sobre esta base, construimos ETL.
En este caso, es importante sentir la ventaja. Profundizar en el registro único de un juego con una DAU de 50 personas, cuando necesitas ayudar a un proyecto con una DAU de 500,000 cerca, es un lujo inadmisible. Por lo tanto, por supuesto, podemos dedicar mucho esfuerzo a crear una solución personalizada, pero solo si las empresas realmente lo necesitan.
Sin embargo, tan pronto como los desarrolladores, especialmente los principiantes, escuchan que tendrán que adaptarse de esta manera, desean no hacerlo nunca. Cualquier desarrollador quiere hacer una arquitectura ideal, nunca cambiarla y escribir artículos sobre ella en Habr.
¿Pero qué pasa si dejamos de adaptarnos a nuestros juegos? ¿Supongamos que comenzamos a exigirles que envíen datos a una única API de entrada? El resultado será uno: todos comenzarán a dispersarse.
- Algunos proyectos comenzarán a reducir sus soluciones de BI-DWH, con preferencia y poetas. Esto conducirá a la duplicación de recursos y dificultades en el intercambio de datos entre sistemas.
- Otros proyectos no lograrán la creación de su BI-DWH, pero tampoco querrán adaptarse al nuestro. Y aún otros dejarán de usar datos, lo que es aún peor.
- Bueno y lo más importante, la administración no tendrá información sistemática actualizada sobre lo que está sucediendo en los proyectos.
¿Podríamos implementar el almacenamiento de una manera simple?
150 proyectos es mucho. Implementar la solución de inmediato para todos es demasiado largo. Las empresas no esperarán un año para que aparezcan los primeros resultados. Por lo tanto, tomamos 3 proyectos que generan los máximos ingresos e implementamos el primer prototipo para ellos. Queríamos recopilar datos clave y crear paneles básicos con las métricas más populares: DAU, MAU, Ingresos, registros, retención, así como un poco de economía y pronósticos.
No pudimos usar las bases del juego de los proyectos para esto. En primer lugar, esto dificultaría el análisis de diseño cruzado debido a la necesidad de agregar datos de varias bases de datos. En segundo lugar, los juegos en sí funcionan sobre estas bases de datos, lo cual es importante para que los maestros y las réplicas no se sobrecarguen. Finalmente, todos los juegos en algún momento eliminan todo el historial de datos que no necesitan en sus bases de datos, lo cual es inaceptable para el análisis.
Por lo tanto, la única opción es recopilar todo lo que necesita para el análisis en un solo lugar. En este punto, cualquier base de datos relacional o repositorio de texto sin formato nos conviene. Atornillaríamos BI y construiríamos tableros. Hay muchas opciones para combinaciones de tales soluciones:

Pero entendimos que más tarde tendríamos que cubrir los otros 150 juegos. Quizás alguna base de datos relacional de clúster pueda manejar la cantidad de datos generados. Pero las fuentes no solo se encuentran en sistemas completamente diferentes, sino que también tienen estructuras de datos muy diferentes. Nos encontramos con estructuras relacionales, Data Vault y otros. No funcionará poner todo esto en una base de datos sin trucos complejos y laboriosos.
Todo esto nos llevó a comprender que necesitamos construir un DataLake.
Implementación de DataLake
En primer lugar, el almacenamiento de DataLake es adecuado para nuestras condiciones, ya que nos permite almacenar datos no estructurados. DataLake puede convertirse en un único punto de entrada para todas las fuentes diversas, desde tablas desde RDBMS hasta JSON, que enviamos desde Kafka o Mongo. Como resultado, DataLake puede convertirse en la base para el análisis de diseño cruzado implementado en base a interfaces para varios consumidores: SQL, Python, R, Spark, etc.
Cambiar a Hadoop
Para DataLake, elegimos la solución obvia: Hadoop. Específicamente, su montaje desde Cloudera. Hadoop le permite trabajar con datos no estructurados y es fácilmente escalable al agregar nodos de datos. Además, este producto ha sido bien estudiado, por lo que la respuesta a cualquier pregunta se puede encontrar en Stackoverflow y no gastar recursos en I + D.
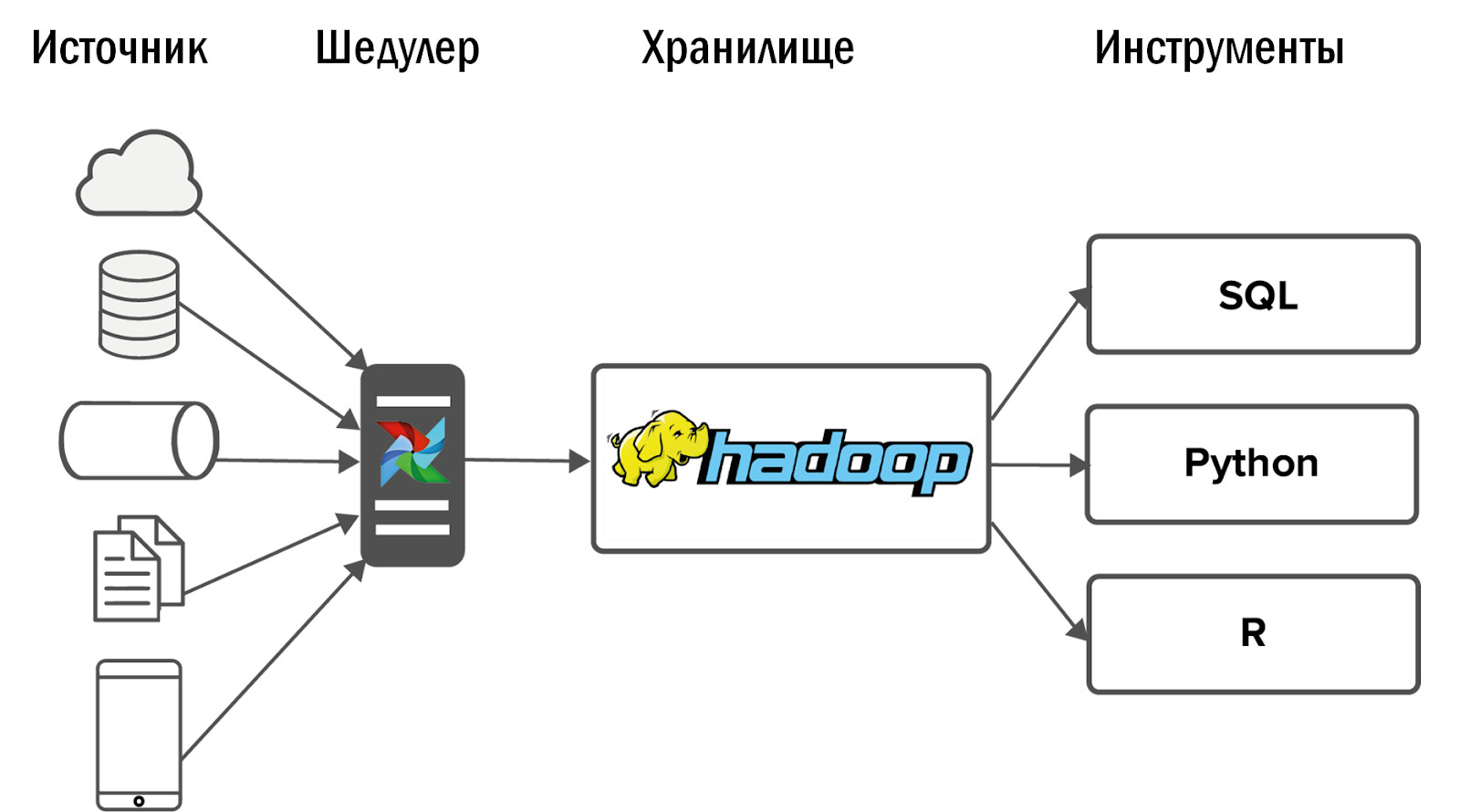
Después de implementar Hadoop, obtuvimos el siguiente diagrama de nuestro primer almacenamiento unificado:

Los datos se recopilaron en Hadoop de un pequeño número de fuentes, y luego se enfrentó a varias interfaces: herramientas y servicios de BI para análisis ad-hoc.
Otros eventos se desarrollaron inesperadamente: nuestro Hadoop comenzó a la perfección, y los consumidores para quienes los datos fluyeron a la tienda abandonaron los viejos sistemas analíticos y comenzaron a usar el nuevo producto a diario para su trabajo.
Pero surgió un problema: cuanto más haces, más quieren de ti. Muy rápidamente, los proyectos que ya estaban integrados en Hadoop comenzaron a solicitar más datos. Y aquellos proyectos que aún no se han agregado, comenzaron a solicitarlo. Los requisitos de estabilidad comenzaron a crecer bruscamente.
Al mismo tiempo, no es razonable simplemente aumentar el equipo linealmente. Si dos desarrolladores de DWH hacen frente a dos proyectos, entonces para cuatro proyectos no podemos contratar a dos desarrolladores más. Por lo tanto, primero fuimos por el otro lado.
Establecimiento de procesos
Con recursos limitados, la solución más barata es ajustar los procesos. Además, en una gran empresa es imposible crear una arquitectura de almacenamiento e implementarla. Tiene que negociar con una gran cantidad de personas.
- En primer lugar, con representantes comerciales que asignan recursos para análisis. Deberá demostrar que necesita implementar solo aquellas tareas de sus clientes que beneficiarán al negocio.
- También debe negociar con los analistas para que le den algo a cambio de los servicios que les brinda: análisis de sistemas, análisis de negocios, pruebas. Por ejemplo, entregamos el análisis del sistema de nuestras fuentes de datos a analistas. Por supuesto, no están contentos, pero de lo contrario simplemente no habrá nadie para hacerlo.
- Por último, pero no menos importante, debe negociar con los desarrolladores de juegos: instalar SLA y acordar una estructura de datos. Si los campos desaparecen, aparecen y cambian de nombre constantemente, no importa el tamaño del equipo, siempre perderá sus manos.
- También debe negociar con su propio equipo: busque un compromiso entre las soluciones ideales que todos los desarrolladores desean crear y las soluciones estándar que no son tan interesantes, pero que pueden ser remachadas de manera económica y rápida.
- Será necesario acordar con los administradores el monitoreo de la infraestructura. Aunque, tan pronto como tenga recursos adicionales, es mejor contratar a su propio especialista DevOps en el equipo de almacenamiento.
En este punto, podría terminar el artículo si tal variante del repositorio cumpliría todos los objetivos establecidos para él. Pero esto no es así. Por qué
Antes de Hadoop, podíamos proporcionar datos y estadísticas para cinco proyectos. Con la implementación de Hadoop y sin un aumento en el equipo, pudimos cubrir 10 proyectos. Después de establecer los procesos, nuestro equipo ya ha atendido 15 proyectos. Esto es genial, pero tenemos 150 proyectos. Necesitábamos algo nuevo.
Implementación de flujo de aire
Inicialmente, recopilamos datos de fuentes usando Cron. Dos proyectos es normal. 10 - duele, pero está bien. Sin embargo, ahora se cargan diariamente alrededor de 12 mil procesos para cargar desde 150 proyectos en DataLake. Cron ya no es adecuado. Para hacer esto, necesitamos una herramienta poderosa para administrar flujos de descarga de datos.
Elegimos el Administrador de tareas de flujo de aire de código abierto. Nació en las entrañas de Airbnb, luego de lo cual fue transferido a Apache. Esta es una herramienta para ETL basado en código. Es decir, usted escribe un script en Python, y se convierte en un DAG (gráfico acíclico dirigido). Los DAG son excelentes para mantener las dependencias entre tareas: no puede crear un escaparate utilizando datos que aún no se han cargado.
Airflow tiene un excelente controlador de errores. Si un proceso falla o hay un problema con la red, el despachador reinicia el proceso la cantidad de veces que especifique. Si hay muchas fallas, por ejemplo, la tabla en la fuente ha cambiado, entonces llega un mensaje de notificación.
Airflow tiene una excelente interfaz de usuario: muestra convenientemente qué procesos se están ejecutando, cuáles se han completado con éxito o con un error. Si las tareas cayeron con errores, puede reiniciarlas desde la interfaz y controlar el proceso a través de la supervisión sin entrar en el código.
Airflow es personalizable, está construido sobre operadores, estos son complementos para trabajar con fuentes específicas. Algunos operadores salen de la caja, muchos han escrito la comunidad Airflow. Si lo desea, puede crear su propio operador, la interfaz para esto es muy simple.
¿Cómo usamos el flujo de aire?
Por ejemplo, necesitamos cargar una tabla de PostgreSQL en Hadoop. La tarea
sql_sensor_battle_log verifica si la fuente tiene los datos que necesitamos para ayer. Si es así, la tarea
load_stg_data_from_battle_log datos de la PG y los agrega a Hadoop. Finalmente,
load_oda_data_from_battle_log realiza el procesamiento inicial: digamos, convirtiendo de Unix Time a tiempo legible para humanos.
En dicha cadena de tareas, los datos se toman de una entidad en una fuente:

Y así, de todas las entidades que necesitamos de una fuente:
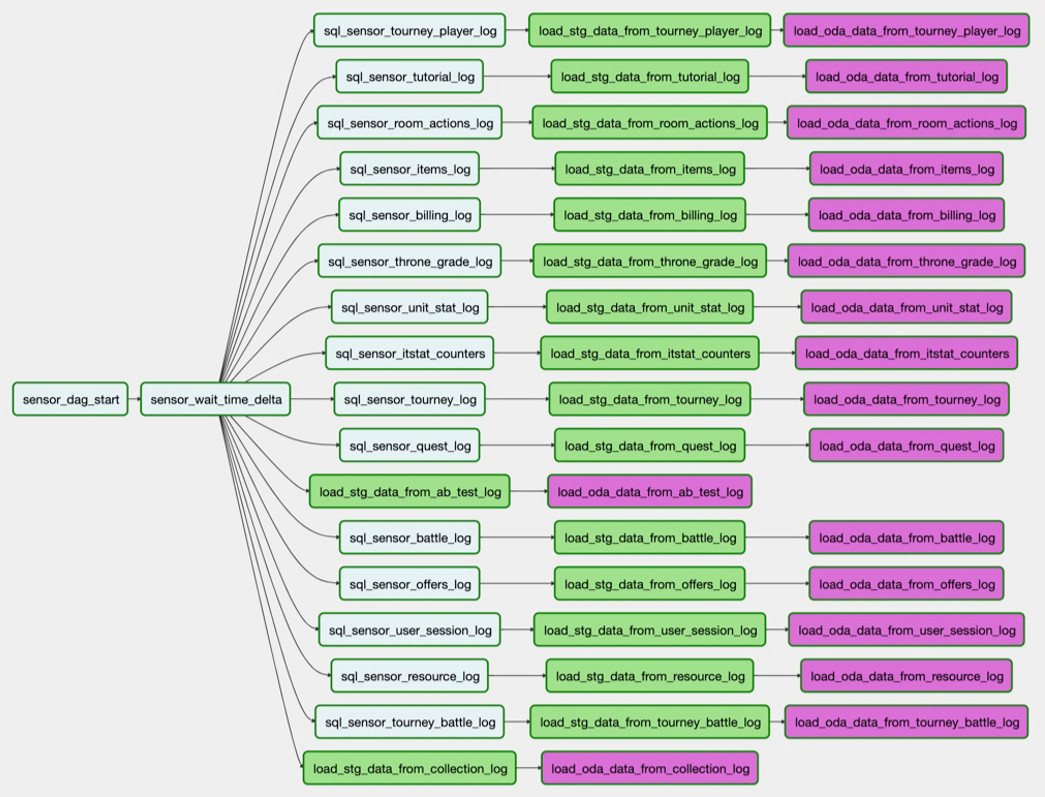
Este conjunto de descargas es el DAG. Y en este momento tenemos 250 DAG para cargar datos sin procesar, procesar, transformar y crear escaparates en él.
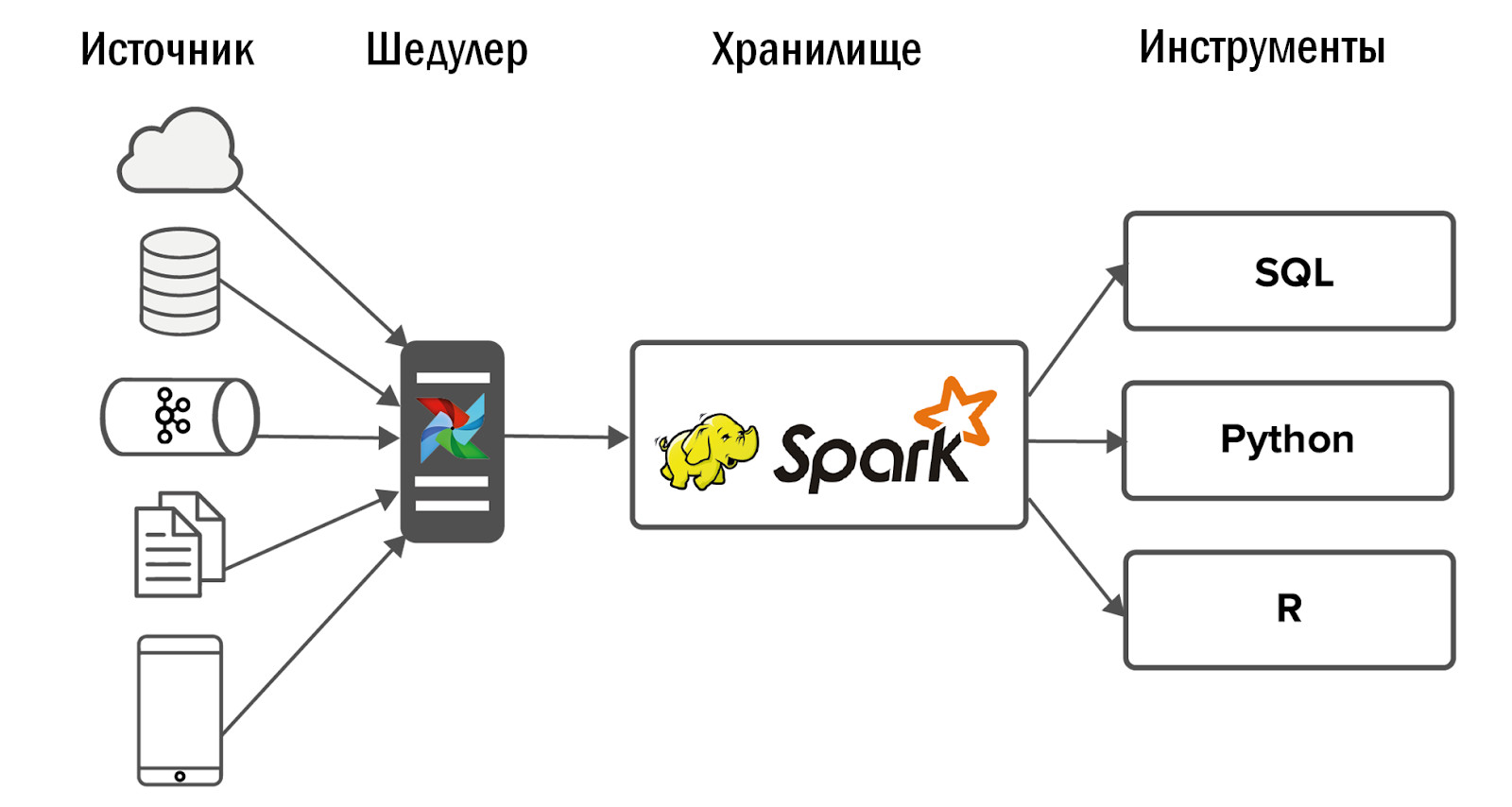
El esquema de almacenamiento unificado actualizado es el siguiente:
- Después de la introducción de Airflow, pudimos permitirnos un fuerte aumento en el número de fuentes, hasta 400 piezas. Las fuentes de datos son tanto internas (de nuestros juegos) como externas: sistemas de estadísticas comprados, API heterogéneas. Es Airflow que nos permite ejecutar y controlar diariamente 12 mil procesos que procesan datos de nuestros 150 juegos.
- En más detalle sobre nuestro flujo de aire, Dean Safina escribió en su artículo ( https://habr.com/ru/company/mailru/blog/344398/ ). Y también únete a la comunidad Airflow en Telegram ( https://t.me/ruairflow ). Muchas preguntas sobre Airflow pueden resolverse con la ayuda de la documentación, pero a veces aparecen más solicitudes personalizadas: ¿cómo puedo empaquetar Airflow en la ventana acoplable, por qué no funciona el tercer día y todo eso? Esto se puede responder en esta comunidad.
Qué mejorar en DataLake
En este punto, los desarrolladores de DWH confían en que todo está listo y ahora puedes calmarte. Desafortunadamente o afortunadamente, todavía hay algo que ajustar en DataLake.
Calidad de los datos
Con una gran cantidad de tablas en DataLake, la calidad de los datos es la primera en sufrir. Por ejemplo, tome una mesa con pagos. Contiene user_id, cantidad, fecha y hora de pago:
Alrededor de 10 mil pagos ocurren cada día:

Una vez en la tabla del día llegaron solo 28 entradas. Sí, y user_id está todo vacío:
Si algo se rompe repentinamente en nuestra fuente, entonces, gracias a Airflow, lo sabremos de inmediato. Pero si formalmente hay datos, e incluso en el formato correcto, entonces no aprendemos de inmediato sobre el desglose y de los consumidores de datos. No es realista comprobar nuestras 5000 mesas con nuestras propias manos.
Para evitar esto, hemos desarrollado nuestro propio sistema de control de calidad de datos (DQ). Todos los días monitorea las descargas clave a nuestro repositorio: rastrea cambios repentinos en el número de filas, busca campos vacíos y verifica la duplicación de datos. El sistema también aplica controles personalizados de analistas. En base a esto, ella envía notificaciones por correo sobre lo que salió mal y dónde. Los analistas van a los proyectos y descubren por qué, por ejemplo, hay muy pocos datos, eliminan los motivos y volvemos a cargar los datos.
Priorizar descargas
Con el creciente número de tareas para cargar datos en DataLake, rápidamente surge un conflicto de prioridad. La situación habitual: algún proyecto no tan importante tomó todos los recursos con sus descargas por la noche, y las tablas que se necesitan para calcular las métricas para la alta gerencia no tienen tiempo para cargar al comienzo del día laboral. Nos ocupamos de esto de varias maneras.
- Monitoreo de descargas clave. Airflow tiene su propio sistema SLA, que le permite determinar si todas las claves llegaron a tiempo. Si no se cargan algunos datos, lo descubriremos unas horas antes que los usuarios y tendremos tiempo para solucionarlo.
- Establecimiento de prioridades. Para hacer esto, utilizamos la cola Airflow y el sistema de prioridad. Nos permite determinar el orden de carga de los DAG y la cantidad de procesos paralelos en ellos. No tiene sentido cargar registros que se analizan una vez por trimestre, antes de descargar datos para las métricas de alta gerencia.
Monitoreo de la duración del lote nocturno
Tenemos un almacenamiento por lotes. Por la noche, estamos en el proceso de construirlo, y es importante para nosotros asegurarnos de que haya suficiente noche para procesar el lote diario. De lo contrario, durante las horas de trabajo, los analistas no tendrán suficientes recursos de almacenamiento para trabajar. Regularmente resolvemos este problema de varias maneras:
- Escala inversa. No enviamos todos los datos, sino solo lo que necesitan los analistas. Monitoreamos todas las tablas cargadas, y si una de ellas no se usa durante seis meses, entonces apagamos su carga.
- Desarrollo de capacidades. Si entendemos que estamos limitados por las capacidades de la red, la cantidad de núcleos o la capacidad del disco, entonces agregamos nodos de datos a Hadoop.
- Optimización del flujo de aire de los trabajadores. Estamos haciendo todo lo posible para que cada parte de nuestro sistema se utilice al máximo en cada momento del tiempo de construcción del almacenamiento.
- Refactorización de procesos no óptimos. Por ejemplo, consideramos la economía de un juego nuevo y nos lleva 5 minutos. Pero después de un año, los datos crecen y la misma solicitud se procesa durante 2 horas. En algún momento, debemos reajustarnos al recálculo incremental, aunque al principio esto puede parecer una complicación innecesaria.
Control de recursos
Es importante no solo tener tiempo para terminar de preparar el repositorio para el comienzo de la jornada laboral, sino también monitorear la disponibilidad de sus recursos después de eso. Con esto, pueden surgir dificultades con el tiempo. En primer lugar, la razón es que los analistas escriben consultas subóptimas. Una vez más, los propios analistas se están volviendo cada vez más. Lo más simple en este caso: aumentar la capacidad del hardware. Sin embargo, una solicitud no óptima aún ocupará todos los recursos disponibles. Es decir, tarde o temprano comenzará a gastar dinero en hierro sin un beneficio significativo. Por lo tanto, usamos varios otros enfoques.
- Cita: dejamos a los usuarios al menos un poco de recursos. Sí, las solicitudes se ejecutarán lentamente, pero al menos lo harán.
- Monitoreo de los recursos consumidos: cuántos núcleos utilizan las solicitudes de los usuarios, quienes olvidaron usar particiones en Hadoop y tomaron toda la RAM, etc. Además, estos monitoreos son visibles para los propios analistas, y cuando algo no funciona para ellos, ellos mismos encuentran al culpable y tratan con ellos. el. Si tuviéramos pocos proyectos, rastrearíamos el consumo de recursos nosotros mismos. Pero con tantos, tendríamos que contratar un equipo de monitoreo separado y en constante expansión. Y a la larga, esto no es razonable.
- Formación voluntaria obligatoria del usuario. El trabajo de los analistas no es escribir consultas de calidad en su repositorio. Su trabajo es responder preguntas comerciales. Y además de nosotros, el equipo del repositorio, a nadie le importa la calidad de las solicitudes de los analistas. Por lo tanto, creamos preguntas frecuentes y presentaciones, realizamos conferencias para nuestros analistas, explicamos cómo podemos trabajar con nuestro DataLake y cómo no.
De hecho, dedicar tiempo a hacer que los datos estén disponibles es mucho más importante que completarlos. Si hay datos en el almacenamiento, pero no están disponibles, entonces, desde el punto de vista empresarial, todavía están allí, y sus esfuerzos para descargar ya se han gastado.
Flexibilidad de la arquitectura
Es importante no olvidarse de la flexibilidad del DataLake construido y no tener miedo de cambiar la arquitectura al cambiar los factores de entrada: qué datos deben cargarse en el almacenamiento, quién los usa y cómo. No creemos que nuestra arquitectura siempre permanecerá sin cambios.
Por ejemplo, lanzamos un nuevo juego móvil. Ella escribe JSON a Nginx desde los clientes, Nginx arroja datos a Kafka, los analizamos usando Spark y los ponemos en Hadoop. Todo funciona, la tarea está cerrada.
Pasaron un par de meses y, en el almacenamiento, todos los procesos del lote nocturno comenzaron a durar más. Estamos empezando a descubrir cuál es el problema: resulta que el juego "disparó", se generaron 50 veces más datos y Spark no pudo hacer frente al análisis JSON, arrastrando la mitad de los recursos de almacenamiento. Inicialmente, todos los datos se enviaron a un tema de Kafka, y Spark los clasificó en diferentes entidades. Pedimos a los desarrolladores de juegos que compartan datos sobre clientes con diferentes entidades y los viertan en temas separados de Kafka. Se hizo más fácil, pero no por mucho tiempo. Luego decidimos cambiar del análisis JSON diario a cada hora. Sin embargo, la instalación de almacenamiento comenzó a construirse no solo por la noche, sino durante todo el día, lo que no era deseable para nosotros. Después de tales intentos, para resolver este problema, abandonamos Spark e implementamos ClickHouse.

Tiene un gran motor de análisis JSON que descompone instantáneamente los datos en tablas. Primero enviamos información de Kafka a ClickHouse, y desde allí la recogemos en Hadoop. Esto resolvió completamente nuestro problema.
Por supuesto, tratamos de no reproducir sistemas de zoológicos en nuestro almacenamiento DataLake, pero intentamos seleccionar las tecnologías más adecuadas para tareas específicas.
¿Valió la pena?
¿Valió la pena implementar Hadoop, un sistema de control de calidad, lidiar con Airflow y establecer procesos comerciales? Por supuesto que valió la pena:
- La empresa tiene información actualizada sobre todos los proyectos, que está disponible en servicios individuales.
- Los usuarios de nuestro sistema, desde diseñadores de juegos hasta gerentes, dejaron de tomar decisiones solo sobre la base de la intuición y cambiaron a enfoques basados en datos.
- Les dimos a los analistas las herramientas para hacer su propia ciencia de cohetes. Ahora responden consultas comerciales complejas, crean modelos de pronóstico, sistemas de recomendación, mejoran los juegos. En realidad, para esto trabajamos en BI-DWH.