En
People & Screens hemos trabajado con empresas en línea durante muchos años como socios publicitarios. Cuando tuvimos la idea de evaluar la contribución de la publicidad gráfica a las ventas de las tiendas en línea, parecía irrealizable e incluso loco. Tan pronto como nos dimos cuenta de que todos los elementos del mosaico se pueden encontrar y armar, decidimos probarlo. Las primeras hipótesis comenzaron a confirmarse, junto con
Data Insight, profundizamos en esta historia y en unos pocos meses de arduo trabajo creamos dicho estudio, que, de hecho, es una herramienta de trabajo aplicada, un modelo para evaluar la efectividad de la publicidad en 12 categorías de productos de comercio electrónico. En este artículo hablaremos sobre los resultados y los métodos de análisis utilizados.
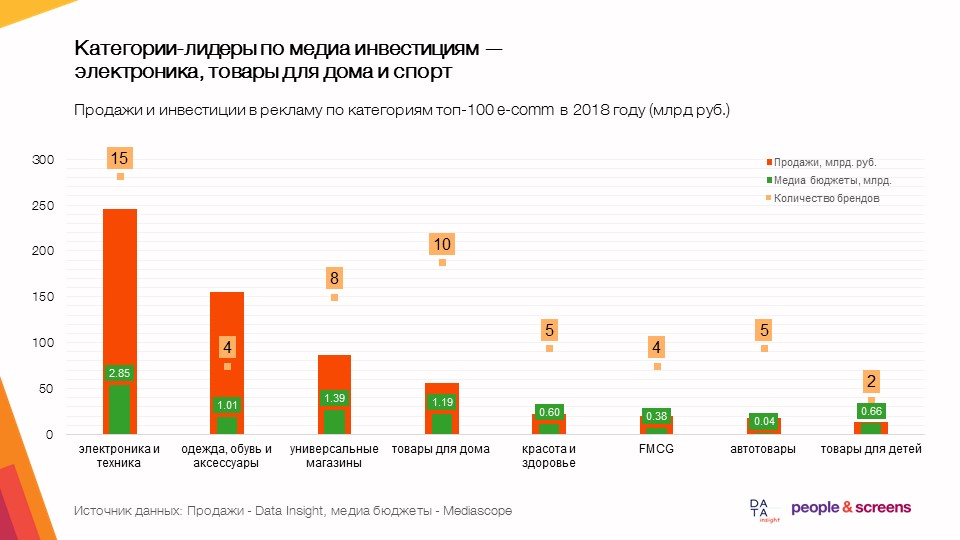
Objetivos de investigación y resultados
La hipótesis clave de nuestro estudio: la publicidad gráfica, el desarrollo de la marca de una tienda en línea, aumenta la conversión en todo el embudo de ventas. En el análisis de datos de ventas, publicidad y datos externos durante los últimos cuatro años, se confirmó la hipótesis. Como resultado, creamos modelos econométricos de ventas para 60 tiendas en línea en 12 categorías de productos.
- Solo la contribución a corto plazo de la publicidad gráfica representó el 39% del crecimiento de las tiendas en línea con una dinámica de mercado promedio del 50-60%.
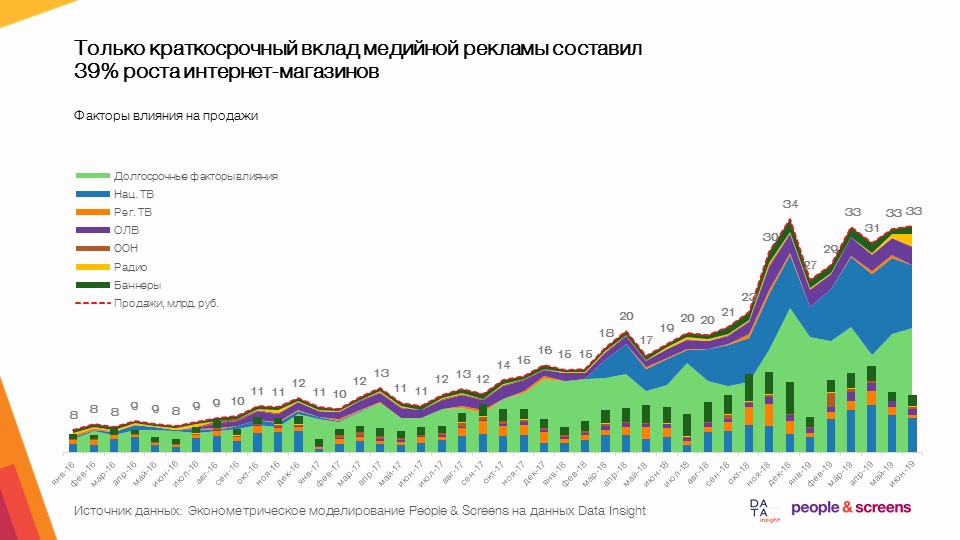
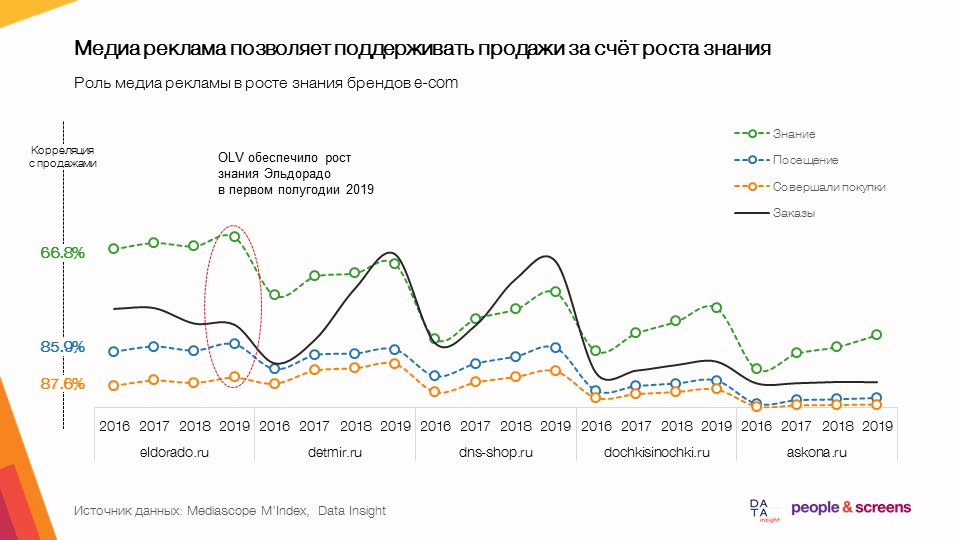
- La publicidad gráfica le permite respaldar las ventas a través de un mayor conocimiento.
- El mayor retorno total en el comercio electrónico proviene de la publicidad en video en línea.
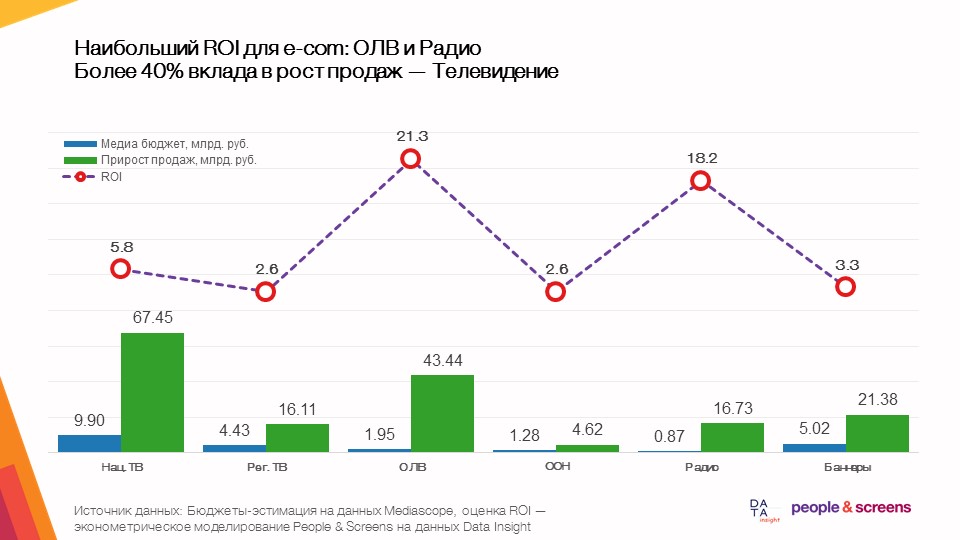
- La eficiencia de los medios depende en gran medida de la categoría: en las categorías de ropa e hipermercados en línea, la televisión mostró una alta eficiencia, en productos electrónicos y de automóviles: publicidad en video en línea.
Lo que analizamos
La recopilación de datos para el estudio fue realizada por ambas compañías que participaron en el estudio. People & Screens recopiló los siguientes datos:
- El anuncio gráfico sale. Utilizamos descargas de las bases de datos de Mediascope a las que tienen acceso todos los grupos de anuncios. Descargamos los costos publicitarios para todos los medios y contactos publicitarios a un público objetivo amplio (Todos mayores de 18 años) en detalles por día (para publicidad en TV, radio, prensa, Internet) y por mes (para publicidad exterior) desde enero de 2016 hasta junio de 2019. Para maximizar la velocidad del trabajo en esta etapa, utilizamos el desarrollo interno de Dentsu Aegis Network Russia para trabajar con datos industriales, en particular la plataforma Atomizer.
- Descargando datos de SimilarWeb diariamente durante los últimos 18 meses. Observamos la dinámica por días de visitas en el escritorio / móvil, la dinámica por días del tráfico de escritorio por fuente (canal) y la dinámica de las instalaciones en Android.
- Dinámica de conocimiento / visitas / compras de la base de datos TGI / Marketing Index para 2016-2019 por trimestres. Esta es una descarga del software industrial Gallileo de Mediascope.
- Consultas de búsqueda de Google Trends para enero de 2016 - julio de 2019 en toda Rusia.
En el lado de Data Insight, se recopilaron y proporcionaron los siguientes datos:
- La dinámica de los pedidos de 72 tiendas en línea de la clasificación TOP-100 por mes para el período de enero de 2016 a agosto de 2019.
- Los datos del contador li.ru para el período comprendido entre enero de 2018 y agosto de 2019 (tráfico al sitio, total por separado, solo en Rusia y solo móvil) para los sitios TOP-11.
- Los datos del contador mail.ru para el período comprendido entre junio de 2017 y septiembre de 2019 para 53 sitios.
- Datos del contador Rambler para el período comprendido entre junio de 2017 y septiembre de 2019 para 38 sitios.
- Datos de consulta de búsqueda de Yandex Wordstat durante 24 meses desde octubre de 2017 hasta septiembre de 2019.
- Evaluación de cheques promedio de las tiendas en línea TOP-100 a partir de 2018.
Algoritmo de datos
La recopilación de datos para el estudio se realizó en varias etapas. Dejaremos fuera del alcance del artículo el trabajo que realizaron nuestros colegas de Data Insight para generar los datos necesarios para el estudio, pero le diremos qué trabajo se realizó al lado de People & Screens:
- Busque todas las tiendas en línea de la clasificación TOP-100 en las bases de datos industriales disponibles y compile diccionarios coincidentes de nombres. Para esto, utilizamos el motor de búsqueda semántico Elasticsearch .
- Formación de plantillas y carga de datos en ellas. En esta etapa, lo más importante era pensar previamente la arquitectura de las tablas de datos.
- Combinando datos de todas las fuentes en un solo conjunto de datos (conjunto de datos).
Para hacer esto, utilizamos el procesamiento de datos cargados en Python usando los paquetes pandas y sqlalchemy . El conjunto de hacks de la vida aquí es bastante estándar:
Al procesar datos sin procesar de tablas csv de más de 1 millón de filas, primero cargamos los nombres de columna de la tabla con una consulta del formulario:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
luego los tipos de datos se agregaron a través del diccionario:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
y los datos en sí cargan función
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
Los resultados de la conversión se cargaron en PostgreSQL. - Validación cruzada de la dinámica de pedidos basada en el análisis de la dinámica del tráfico, consultas de búsqueda y ventas reales en el grupo de clientes de la agencia People & Screens. Aquí construimos matrices de correlación usando df.corr () en diferentes conjuntos de datos dentro de un sitio fijo, luego analizamos en detalle las series "sospechosas" con valores atípicos. Esta es una de las etapas clave del estudio, en la cual verificamos la confiabilidad de la dinámica de los indicadores estudiados.
- Construcción de modelos econométricos sobre datos validados. Aquí usamos las transformadas directas e inversas de Fourier del paquete numpy ( funciones np.fft.fft y np.fft.ifft ) para extraer la estacionalidad, una aproximación suave por partes para estimar la tendencia y el modelo de regresión lineal ( linear_model ) del paquete sklearn para estimar la contribución de la publicidad. Al elegir una clase de modelos para esta tarea, procedimos del hecho de que el resultado de la simulación debe interpretarse fácilmente y utilizarse para evaluar numéricamente la efectividad de la publicidad teniendo en cuenta la calidad de los datos. Investigamos la fiabilidad de los modelos dividiendo los datos en muestras de entrenamiento y prueba de un intervalo de tiempo variable. Es decir comparamos cómo se comporta el modelo entrenado en datos de enero de 2016 a diciembre de 2018 en el intervalo de tiempo de prueba de enero a agosto de 2019, luego capacitamos al modelo en el intervalo de tiempo de enero de 2016 a enero de 2019 y observamos cómo se comporta el modelo en los datos de febrero a Agosto de 2019. La calidad de los modelos fue estudiada por la estabilidad de la contribución de los factores publicitarios en diferentes muestras de capacitación como el pronóstico en la muestra de prueba.
- El último paso fue preparar una presentación basada en los hallazgos. Aquí establecimos un puente de modelos matemáticos con conclusiones comerciales prácticas y una vez más probamos los modelos desde el punto de vista del sentido común de los resultados.
Los detalles del análisis del comercio electrónico y las dificultades que surgen en el proceso.
- En la etapa de recopilación de datos, surgieron dificultades con la evaluación correcta del interés de búsqueda en el recurso. En Google Trends no hay forma de agrupar consultas de búsqueda y usar palabras clave negativas como en Yandex Wordstat. Era importante estudiar el núcleo semántico de cada tienda en línea y cargar la solicitud central. Por ejemplo, M.Video debe estar escrito en ruso: esta es la solicitud central de este sitio.
Para las tiendas que venden productos tanto en línea como fuera de línea, los colegas de Data Insight adoptaron el siguiente enfoque en los datos de Yandex wordstat:
Asegúrese de que no haya preguntas irrelevantes (lo principal no es estimar el volumen de la demanda, sino rastrear los cambios en la dinámica). Somos lo suficientemente resistentes como para filtrar palabras de búsqueda. Cuando existía un riesgo por parte de la marca de recoger solicitudes inapropiadas, tomamos estadísticas sobre combinaciones de teclas. Por ejemplo, "tienda de ozono" en lugar de "ozono": con este enfoque, se subestima la popularidad de búsqueda del minorista, pero la dinámica de la demanda se mide de manera más confiable y se elimina el "ruido". En relación con las estadísticas de búsqueda, existe un problema metodológico que aparentemente no tiene una solución confiable: para muchos minoristas, estas estadísticas están distorsionadas por las herramientas de SEO que optimizan los resultados de búsqueda a través de factores de comportamiento, pero distorsionan las estadísticas sobre la demanda real. - En la etapa de combinar datos de diferentes fuentes, se hizo necesario llevar los datos a una granularidad única: los datos para la publicidad televisiva y el tráfico de SimilarWeb eran diarios, los datos para las consultas de búsqueda eran para semanas y los datos para pedidos y datos de medidores eran para meses. Como resultado, formamos una base de datos separada con campos de fecha que le permiten agregar datos en el nivel requerido, y una base de datos de agregación mensual en caché para seguir trabajando con todos los detalles de los datos de ventas.
- En la etapa de validación cruzada de los datos, encontramos discrepancias notables en la dinámica de las ventas con nuestros propios datos. Esto requirió una discusión de la situación con colegas de Data Insight. Como resultado, gracias a una comprensión precisa de los meses en que ocurren los errores más grandes, los analistas han identificado dos errores que se encuentran en el fondo del algoritmo para evaluar la dinámica de ventas mensuales.
- En la etapa de desarrollo del modelo, surgieron varias dificultades. Para evaluar correctamente el efecto de la publicidad, fue necesario aislar los factores externos. Cualquier dinámica de ventas (y el comercio electrónico no es una excepción) está asociada no solo con la publicidad, sino también con muchos otros factores: cambios de UX / UI en el sitio, precios, surtido, competencia, fluctuaciones de divisas, etc.
Para resolver este problema, utilizamos un enfoque basado en el análisis de regresión de datos durante un largo período, desde enero de 2016 hasta agosto de 2019. Como parte de este enfoque, analizamos los cambios (oleadas) en la dinámica de los pedidos que se pueden atribuir a la publicidad en este período.
Es importante comprender que si en algún momento se inició un anuncio, pero el valor esperado de las ventas, según el modelo, no fue mayor que el real, entonces el modelo mostrará que este anuncio no funcionó durante este período. Por supuesto, tal comportamiento de ventas puede ser una superposición de varios factores (por ejemplo, aumentos de precios / lanzamiento de competidores al mismo tiempo que comienza la campaña publicitaria o un sitio que ha "caído" por la afluencia de clientes).
Dado que promediamos los efectos durante un largo período de tiempo en una gran cantidad de marcas, el efecto de tales coincidencias aleatorias debe nivelarse en una muestra grande, aunque puede conducir a efectos sobreestimados o subestimados para marcas individuales. Como resultado, esto nos permitió determinar reglas y patrones generales para la categoría de comercio electrónico en su conjunto. Al mismo tiempo, para un análisis detallado de la influencia de la publicidad dentro de las marcas individuales, por supuesto, todavía es necesario estudiar todo el conjunto de factores de influencia.
Conclusión
Como parte de este estudio, nos propusimos el objetivo de obtener los resultados más confiables basados en datos de fuentes heterogéneas. Por sí mismos, estos datos no son valores exactos, sino solo una evaluación de estos valores por medio de monitoreo de terceros (monitoreo de resultados publicitarios, dinámica de tráfico, interés de búsqueda y, finalmente, pedidos).
Cada enlace tiene limitaciones en la calidad de los datos, y este es un problema que los analistas e investigadores enfrentan a una escala u otra todos los días. Esperamos que en el marco de este artículo podamos mostrar qué métodos pueden garantizar la fiabilidad de las conclusiones de un estudio analítico, al tiempo que conservamos el poder explicativo de los resultados.