Hola a todos! Mi nombre es Denis Oleynik, trabajo como director técnico en 1Service.
En nuestra empresa, dedicamos mucho tiempo a trabajar con los requisitos. A medida que adquirimos experiencia, comenzamos a darnos cuenta de que las herramientas comúnmente utilizadas en el desarrollo de productos de software nos llevan a un estado en el que no podemos decir que implementamos exactamente lo que el cliente quería de nosotros. Precisamente porque en algún momento hay una brecha de los requisitos inicialmente recopilados de su implementación de software y pruebas posteriores.
Esta línea se encuentra entre los requisitos registrados en Confluence y las tareas para su implementación en Jira. Otra línea va entre los casos de prueba en la herramienta de prueba y los mismos requisitos en Confluence, con un ojo en el código asociado con las tareas en Jira. La falta de respuestas claras a las preguntas: "por qué / por qué lo hicimos de esta manera" o "hicimos todo lo que el cliente quería de nosotros", nos causó una gran preocupación.
Y en algún momento nos pareció que el concepto de "documentación es código" (documentación como código) nos permitirá encontrar respuestas a estas preguntas. El concepto "documentación es código" supone que almacenamos requisitos, soluciones arquitectónicas, instrucciones para el usuario en forma de archivos de texto simples que pueden ser versionados usando sistemas de clase
(D) VCS , idealmente los modelos de datos de entrada-salida también deben almacenarse en un plano forma de texto Los documentos reales "legibles" (así como los módulos ejecutables) aparecerán como resultado del ensamblaje del proyecto. En este caso, la documentación técnica se desarrollará junto con el desarrollo de todo el proyecto con los mismos principios de control de versiones del código, lo que le permitirá satisfacer los criterios de trazabilidad, verificación y relevancia de extremo a extremo. Además, este enfoque resuelve de forma nativa el problema de organizar la llamada "versión básica de requisitos" (líneas de base), que para muchos sistemas de gestión de requisitos se convierte en un problema real. En particular, en Confluence se recomienda resolver este problema creando una copia del espacio original en el que se hicieron los requisitos, mientras se pierde cualquier conexión y herencia de los requisitos. En realidad, este artículo está dedicado a la investigación de campo de este concepto en nuestra empresa.
Antecedentes
Lo que, en nuestra opinión, detiene el uso generalizado de este concepto entre las masas es la miseria de las herramientas para la representación visual y la gestión de requisitos en forma de texto plano. Esto significa que no mostrará los archivos de texto plano Propietario del producto para que vea Project Scope en ellos, no puede mostrar archivos de texto en la página de presentación para las partes interesadas, no tienen gráficos, cuadros e imágenes en la etapa de edición, y esto ya molesta a los analistas de negocios que esencialmente debería generar contenido. Y solo los desarrolladores están contentos y gritan: “¡genial! solo hardcore! ¡más compromisos! ”y otra herejía.
Hay otro punto bastante sutil. Por alguna razón, los apologistas del concepto "la documentación es código" están seguros de que tan pronto como la documentación se encuentre junto al código en el repositorio, esto llevará a su adaptación obligatoria y sincronización con los cambios en el código, lo que permitirá mantenerlo actualizado (
Sección 1.2.1 ) Pero en nuestra opinión, este momento seguirá siendo una cuestión de disciplina, porque nadie se molesta en cambiar el código, y la documentación no cambia. Es decir, la relevancia de la documentación con tal implementación del concepto se deja a la gestión del proceso de desarrollo, donde el paso obligatorio antes del lanzamiento es "verificar la relevancia de la documentación". En este caso, "la documentación es un código" no se aleja de los archivos de Word, si no tiene en cuenta alguna automatización en materia de compilación de los documentos resultantes.
Bueno, sí, en primer lugar, es "inconveniente, querido, seco", y en segundo lugar, los chips técnicos "cubren con un paño" el problema de actualizar la documentación. Hay un estereotipo común: "estamos ajail - ¡pero no necesitamos documentación en ajail! Para decirlo suavemente, esto no es del todo cierto. Me gusta refutar este error comparando los enfoques de casos de uso e historias de usuario del excelente libro de Karl Wigers "Desarrollo de requisitos de software" [4]. Si relacionamos los enfoques de desarrollo basados en Historias de usuarios con la metodología Agile, Wigers formula la evolución de los requisitos basados en Historias de usuarios de esta manera:
Historial de usuarios → (discusiones) → Historial de usuarios actualizado (con criterios de aceptación) → (discusiones) → Pruebas de aceptación
(p. 169, Fig. 8-1). Por lo tanto, la documentación de salida como resultado de la evolución de los requisitos iniciales en los proyectos de desarrollo ágil son las pruebas de aceptación. Hoy en día, una técnica bastante común para organizar las pruebas de aceptación es utilizar scripts de prueba escritos en el lenguaje
Gherkin [5], almacenados en los llamados archivos de características (texto simple).
Por lo tanto,
para respaldar la implementación del concepto "la documentación es código" en proyectos ágiles, necesitamos una herramienta que acompañe la evolución de los requisitos desde el formato de la Historia del usuario hasta las pruebas de aceptación , que, como resultado de su ejecución exitosa, generará la documentación relevante. Desafortunadamente, hasta la fecha, no existe una herramienta que respalde completamente este proceso (o al menos postule su deseo de apoyarlo).
Arquitectura de herramientas de investigación
Entonces, no hay una herramienta, pero quiero explorar el concepto. De la desesperanza, tuvimos que desarrollarlo. Si tal herramienta (llamémosla StoryMapper) ya existiera, ¿qué tipo de arquitectura tendría para integrarse discretamente, con un estrés mínimo, en un ecosistema existente del proceso de desarrollo? Si esto ya es un proceso de desarrollo desarrollado, entonces el ciclo
CI / CD probablemente ya se estaría ejecutando en él, y el sistema de control de versiones, muy probablemente basado en git, ciertamente se usaría. En este caso, el siguiente diagrama muestra el lugar de StoryMapper durante el proceso de desarrollo:
Fig. 1 Lugar de la herramienta StoryMapper en la estructura del proceso de desarrolloPor lo tanto, StoryMapper interactuará directamente con los servicios de alojamiento de repositorios git y con el bucle
CI / CD . La integración con los servicios de alojamiento de git es necesaria para obtener la colección actual de archivos de características (si corresponde), así como para poner los resultados de los cambios en los archivos de características, archivos de servicio relacionados con la documentación de estructuración, ejemplos de datos de entrada y salida de vuelta al repositorio, etc. . etc. Interacción con el
CI contorno
/ CD necesita para ser capaz de ejecutar la prueba escenario montaje (manual o programada), y para los resultados de pruebas subsiguientes - para que coincida con ellos con la correspondiente característica-archivos (tal Obra º será verificar y comprobar la relevancia de documentación).
Tienes que entender que StoryMapper apenas tiene que reclamar el título de "otro editor de Gherkin". Sí, la capacidad básica para editar archivos de características debe establecerse, pero somos conscientes de que si
BA o
QA optaron por VSC, Sublime, Notepad ++ o incluso vi (¿por qué no?), Entonces convencerlos de que trabajen con los requisitos solo en StoryMapper la tarea no es tan desagradecida, sino más bien incorrecta. Por lo tanto, suponemos que debe establecerse la posibilidad de un uso diverso de StoryMapper, en particular: el desarrollo de características en su editor favorito, y StoryMapper se utiliza para estructurar archivos de características ya hechos. Más sobre esto en la sección de instrucciones de investigación.
Funcionalidad mínima requerida
Dado que StoryMapper se encuentra actualmente en el estado MVP, estos son los requisitos mínimos que hicimos para que realmente pueda comenzar a usarse:
- Mapeo de historias basado en Git;
- Pepinillo-editor;
- Lanzar el ensamblaje de pruebas de escenarios (manualmente y de acuerdo con el cronograma);
- Reflexión de los resultados de las pruebas de escenarios en el mapa de historias de usuarios.
No me detendré en la funcionalidad de la herramienta, ya que el tema de este artículo es el curso de la operación y no el bisturí del cirujano.
Areas de investigacion
La idea principal es esta:
si, utilizando el concepto de "documentación es código", no se salta los requisitos del cliente y escribe algún tipo de documentación arbitraria a medida que escribe el código, entonces dicha documentación morirá y se volverá irrelevante tan pronto como la versión con archivos en formato MS Palabra Por lo tanto, queríamos pensar y explorar la opción de usar el concepto en relación con el ciclo completo de desarrollo. Por otro lado, también estábamos interesados en el momento de transición cuando el equipo no usa el concepto "la documentación es un código", pero existe el deseo de aplicarlo, ¿cómo actuar en este caso?
Entonces, StoryMapper es una herramienta, no regula el único caso de uso verdadero. Por el contrario, cada usuario potencial puede ver sus opciones para usar la herramienta. Nos centramos en tres áreas principales:
- Desarrollo flexible: desde un mapa de historia hasta pruebas de aceptación;
- Estructurar y visualizar una colección de archivos de características;
- Monitoreo de productividad.
A continuación describiré en detalle qué resultados hemos logrado en cada dirección.
Desarrollo flexible: desde tarjetas de historias hasta pruebas de aceptación
Esta dirección implica el desarrollo de un nuevo producto o el refinamiento de uno existente. El trabajo en esta dirección se llevó a cabo bajo el nombre en clave "BDDSM": como una combinación de la técnica Story Mapping y la metodología de desarrollo
BDD . Y echó raíces.
Entonces, para empezar, se crea un repositorio git para archivos de características, se le asigna una rama para interactuar con StoryMapper. Se crea un proyecto en StoryMapper, está conectado a analistas de negocios que trabajarán en el proyecto. Al comunicarse con las partes interesadas, los analistas de negocios comienzan a formular una visión común del producto y lo arreglan en forma de un esqueleto de un mapa de historia de usuario [1,2], primero un bosquejo del primer nivel de
UF :
 Fig. 6 Esqueleto de nivel superior del mapa de historias de usuarios (se puede hacer clic)
Fig. 6 Esqueleto de nivel superior del mapa de historias de usuarios (se puede hacer clic)Y luego gradualmente llenando el segundo nivel de actividades del usuario:
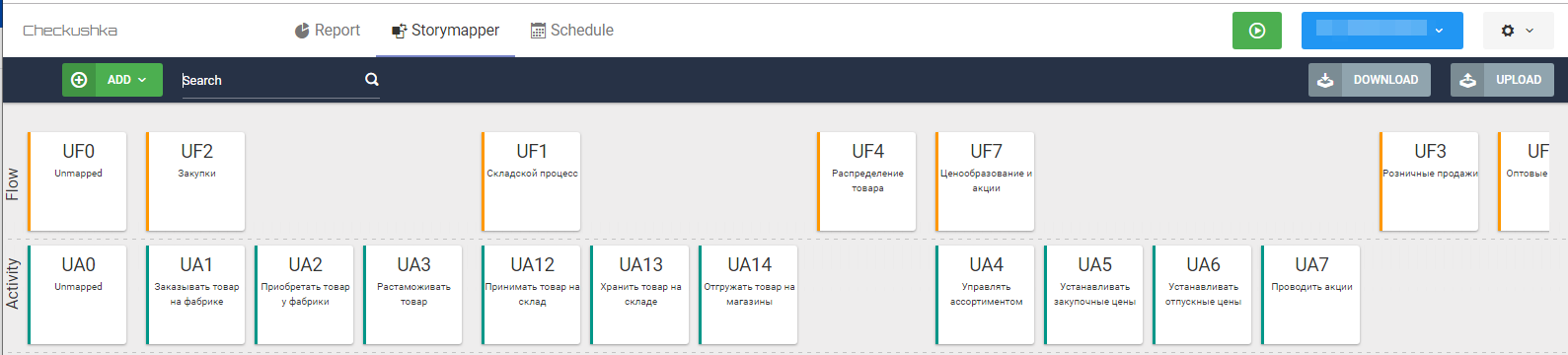 Fig. 7 Esqueleto de segundo nivel del mapa de historias de usuarios
Fig. 7 Esqueleto de segundo nivel del mapa de historias de usuariosDado que cada tarjeta es un archivo de texto, ya sea en la etapa de recopilación de requisitos (si la tarjeta se compila en el curso de la comunicación con el usuario) o en la etapa de procesamiento posterior de las entrevistas, los resultados de la comunicación se transfieren directamente a las tarjetas
UF y
UA . Esta es la base para una mayor descomposición de los requisitos en el nivel de historias de usuarios.
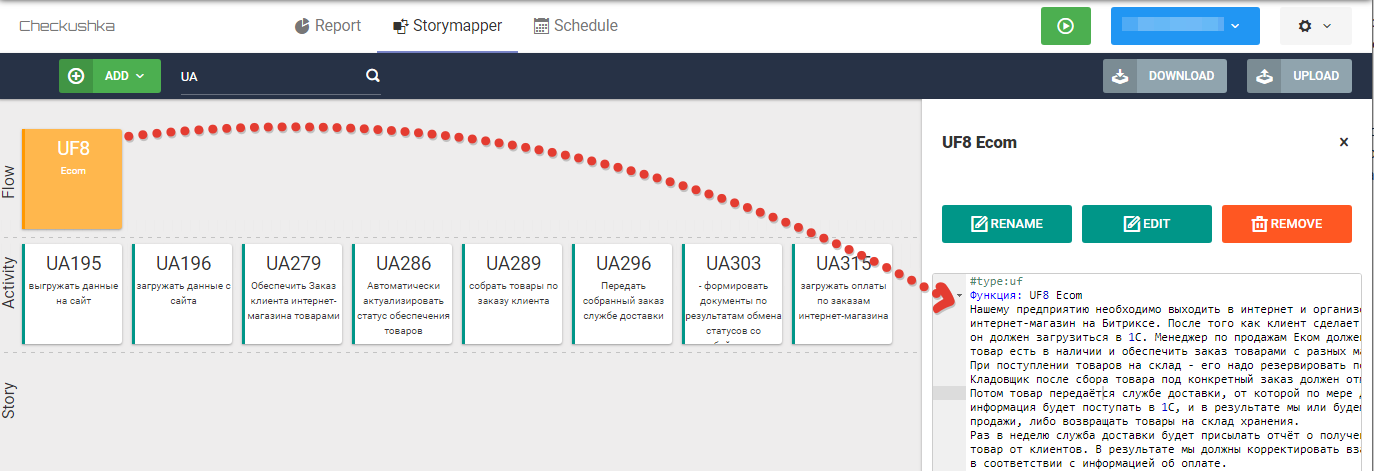 Fig. 8 Texto de requisitos sin sintaxis de Gherkin a nivel UF
Fig. 8 Texto de requisitos sin sintaxis de Gherkin a nivel UFLuego, los analistas de negocios se dan cuenta de cómo descomponer las actividades de los usuarios en historias de usuarios, y formar un tercer nivel de mapa en StoryMapper -
EE .
UU . El aislamiento de los
EE. UU. Está asociado con la formulación de criterios de aceptación, es decir, si "usted como alguien quiere algo", verificaremos después de que lo haya recibido [3]. Los criterios de aceptación para principiantes también se pueden corregir en los
EE .
UU. Como texto plano.
Una vez que los criterios de aceptación se han establecido y acordado con las partes interesadas, los analistas de negocios los ponen en forma de guiones en el lenguaje Gherkin. De hecho, el texto "Escenario: KP-No" se adjunta a cada criterio de aceptación, lo que convierte la historia de usuario hasta ahora abstracta en un archivo de características.
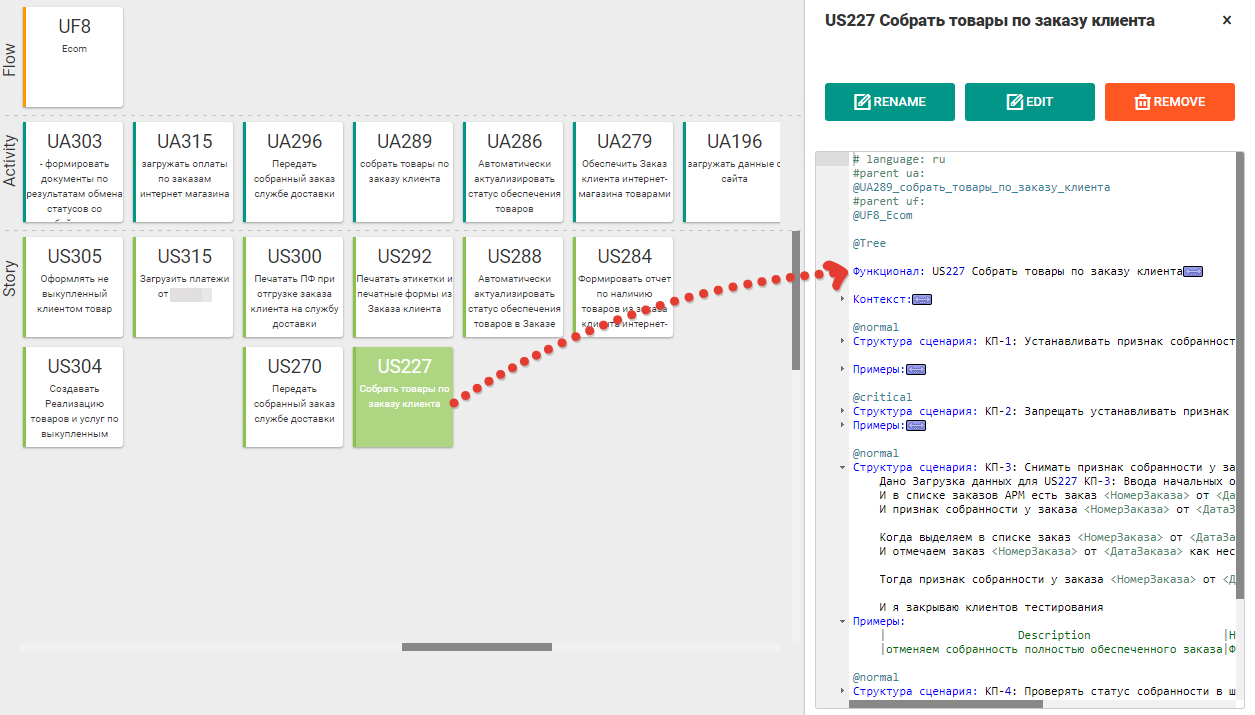 Fig. 8.1 Criterios de aceptación para historias de usuarios como scripts en Gherkin
Fig. 8.1 Criterios de aceptación para historias de usuarios como scripts en GherkinDespués de eso, cada escenario se descifra mediante varios pasos ampliados que revelan cómo se verificará exactamente un criterio de aceptación específico. Además, estos pasos los programan los desarrolladores o se escriben desde la biblioteca de pasos del marco Gherkin utilizado y se exportan para exportar scripts.
Paralelamente, se organiza un banco de pruebas en el que el servidor de ensamblaje ejecutará pruebas funcionales y esperará el momento en que los
EE. UU. Con scripts estén listos. A medida que el producto y los escenarios que implementan los criterios de aceptación están listos, el servidor de ensamblaje comienza a emitir informes en formato Allure y Cucumber y los envía a StoryMapper, que a su vez proyecta el resultado del ensamblaje en formato Cucumber en el mapa de historia del usuario:
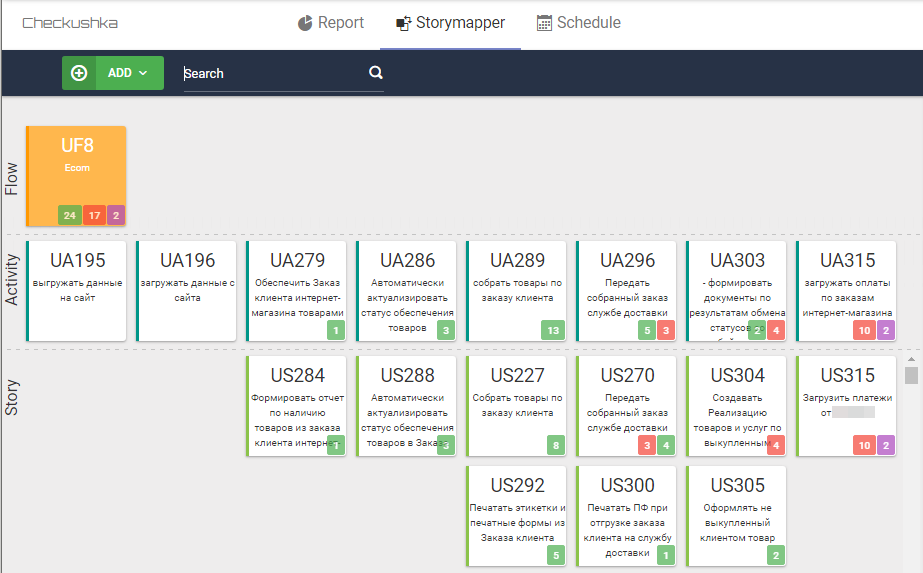 Fig. 9 Mapa de historias de usuarios con resultados de secuencias de comandos
Fig. 9 Mapa de historias de usuarios con resultados de secuencias de comandosAl mismo tiempo, StoryMapper proporciona tres niveles de comprensión de la preparación del producto: UF es el nivel superior que muestra la cantidad de scripts que funcionan correctamente (que cumplen los criterios de aceptación), que funcionan con errores y aún no están listos. Es decir, de hecho, el nivel superior es un indicador de la preparación del producto y un indicador de cuánto queda por hacer (este es el nivel del propietario del producto). Los niveles más bajos le permiten determinar exactamente qué tipo de actividades de usuario tienen dificultades y dónde debe hacer esfuerzos para completar el producto (este es el nivel de maestros de scrum en mayor medida y el propietario del producto en menor medida). El nivel inferior de
EE. UU. Es el nivel en el que interactúan los analistas de negocios, los desarrolladores y el control de calidad, desarrollando conjuntamente el producto que los interesados esperan de ellos.
Además, en uno de los pasos finales de la línea de ensamblaje, se crea la documentación automática. Puedes leer más sobre esto con
tus colegas . Esta no es la única opción, planeamos incluir el paquete
Pickles en nuestra herramienta, el estándar de facto en el mundo de la "documentación en vivo".
Estructurar y visualizar una colección de archivos de características
Trabajando en esta dirección, consideramos tal caso. El equipo de desarrollo, a raíz de la publicidad sobre el tema de BDD, las pruebas funcionales y los estándares de desarrollo de la industria, se comprometió a escribir archivos de características. Y rompiendo las espinas, ha acumulado una colección bastante grande en el repositorio. Sin embargo, cuando tiene 10 archivos en su colección, el informe en formato Allure aún ofrece una imagen confiable del estado del producto. Pero si la cantidad de archivos de características se mide en docenas, y algunas veces en cientos, tarde o temprano querrá estructurarlos de alguna manera. Lo primero que viene a la mente es ordenarlos en carpetas temáticas. ¿Y para que? ¿Por partes interesadas, por metadatos, por subsistemas? Estas están lejos de ser preguntas inactivas. Y si más tarde resulta que los archivos de características se escribieron originalmente como Dios lo pondría en el alma, y hay secuencias de comandos relacionadas con varias carpetas a la vez, ¿cómo?
Por lo tanto, este caso de uso implica un deseo de limpiar su documentación para cambiar de "características por separado, documentación por separado" a "la documentación es un código". Cuando dicho repositorio está conectado a StoryMapper, todos los archivos de características se ubican en la primera columna bajo UF0 y UA0. El siguiente paso en la estructuración es componer el esqueleto de la estructura. En StoryMapper, estos son todos los mismos
UF y
UA , pero nadie insiste en considerarlos solo desde este ángulo. Pueden considerarse simplemente como 2 niveles de jerarquía, bajo los cuales es posible colocar archivos de características previamente no estructurados. Después de establecer la estructura, los archivos de características de la primera columna se separan debajo del
UA correspondiente. Sin lugar a dudas, este proceso provoca un ataque de reflexión y refactorización de las características, ya que a medida que arrastra, toda la profundidad del caos que tuvo lugar durante su escritura inicial se vuelve clara. A veces es suficiente transferir el script de un archivo a otro, a veces dividir un archivo grande en varios para restaurar la conectividad semántica, y a veces simplemente tirarlo a la basura, porque antiguos manuscritos no ejecutables yacían en el repositorio.
Si la línea de ensamblaje ya se ha configurado (bueno, dado que hay un repositorio de archivos de características, entonces se deben recopilar en algún lugar), entonces debe agregar un paso para enviar los resultados del ensamblaje a StoryMapper. El resultado final será la última imagen de la sección anterior (Fig. 9): archivos de características estructurados con marcas en los resultados de sus scripts.
¿Cómo usar una imagen así? Se puede mostrar al equipo de gestión para informar sobre los resultados del equipo y demostrar el grado de preparación / calidad del producto. Puede ser utilizado por el equipo para realizar una retrospectiva para corregir
DoD o para corregir de alguna manera el proceso. Se puede usar para la preparación del trabajo atrasado, pero esto ya requiere trabajo de acuerdo con el escenario descrito en la sección anterior, cuando después de la estructuración inicial de los requisitos, se llevará a cabo un mayor desarrollo en un ciclo completo (o al menos teniendo en cuenta) StoryMapper.
Monitoreo de producto
Otro caso de uso secundario que se ha arraigado en nuestra práctica. De hecho, es un tema moderno y de moda: probar directamente en el producto por qué no. Después de todo, no hay error, no, y sí, se abrirán camino. Esto se vuelve especialmente relevante si la actividad de TI no es el perfil de la empresa y el desarrollo se externaliza, en particular, se trata de tiendas en línea pequeñas y medianas.
Tal como lo vemos. Una opción simple: del conjunto de pruebas funcionales, se selecciona un cierto subconjunto de pruebas de base de datos no modificables que verifican el front-end. : , -, , , -, , . , . StoryMapper Allure, , — , , , IT- .
, , . , , , , - .
, , :
- , ;
- , , ;
- StoryMapper ;
- StoryMapper .
Direcciones de desarrollo
, StoryMapper MVP. , « », , , , . , , « ». , :
- « », « — »;
- (, etc. );
- / / Excel;
- - Jira ( , ).
, , , . , .
( ), , ( !) —
telegram , .
- , . , ., , 2017.
- , . , .-.-, , 2012.
- Gojko Adjic, Specification by Example, NY, Manning Publication, 2011.
- , , , .: ; .: -, 2014.
- BDD «What's in a story»
- « — » «Write the docs»
- « — » " docToolchain "