Mi colega Rafael Grigoryan eegdude escribió recientemente un artículo sobre por qué la humanidad necesitaba EEG y qué fenómenos significativos se pueden registrar en él. Hoy, en continuación del tema de las interfaces neuronales, utilizamos uno de los conjuntos de datos abiertos registrados en un juego utilizando la mecánica P300 para visualizar la señal EEG, ver la estructura de los potenciales llamados, construir los clasificadores principales, evaluar la calidad con la que podemos predecir la presencia de dicho potencial llamado.
Permítame recordarle que P300 es un potencial llamado (VP), una respuesta específica del cerebro asociada con la toma de decisiones y los estímulos distintivos (que veremos a continuación). Generalmente se usa para construir BCI moderno.
Para hacer la clasificación EEG, puedes llamar a tus amigos, escribir un juego sobre mapaches y demonios en realidad virtual, escribir tus propias reacciones y escribir un artículo científico (hablaré de esto en otro momento), pero afortunadamente, científicos de todo el mundo realizó algunos experimentos para nosotros y solo queda descargar los datos.
Se puede encontrar un análisis de cómo construir una interfaz neuronal en el P300 con código y visualizaciones paso a paso, así como un enlace al repositorio debajo del gato.
El artículo muestra solo los puntos principales del código, la versión completa reproducible en el cuaderno jupyter para buscar aquí
Desde el punto de vista de un EEG, el P300 es solo una explosión en un momento determinado en ciertos canales. Hay muchas formas de llamarlo, por ejemplo, si se concentra en un objeto y se activa en un momento aleatorio (cambia de forma, color, brillo o salta en algún lugar). Así es como se implementó en la antigüedad.
En términos generales, el esquema es el siguiente: hay varios estímulos (generalmente de 3 a 7) en el campo de visión de una persona. Una persona elige uno de ellos y se enfoca en él (una buena manera es contar el número de activaciones), luego cada objeto parpadea en un orden aleatorio. Conociendo el tiempo de activación de cada estímulo, ahora podemos mirar el próximo EEG y determinar si hubo un pico característico en él (lo veremos en las visualizaciones a continuación). Como la persona se concentró en un solo estímulo, el pico debería ser uno. Por lo tanto, en estas interfaces neuronales, se selecciona una de varias opciones (letras para escribir, acciones en el juego y Dios sabe qué más). Si hay más de siete opciones, puede colocarlas en la cuadrícula y reducir la tarea a seleccionar una fila + columna. Así es como se escribe arriba el clásico deletreador de matriz P300.
En el caso del conjunto de datos considerado hoy, la parte visual (como el nombre) fue tomada de los famosos proveedores de espacio del juego. Se veía algo como esto

De hecho, este es el mismo deletreador, solo las letras son reemplazadas por extraterrestres.
El video del proceso del juego y los informes técnicos también se conservaron.
De una forma u otra, los datos recopilados con este juego aparecieron en Internet y podemos acceder a ellos. Los datos consisten en 16 canales de EEG y un canal de eventos, que muestran en qué momentos se activaron el objetivo (hecho por el jugador) y los incentivos no objetivo, y trabajaremos con ellos.
La mayoría de los conjuntos de datos para BCI fueron grabados por neurofisiólogos, y estos son tipos a los que realmente no les importa la compatibilidad, por lo que los formatos de datos son muy diversos: desde diferentes versiones de archivos .mat hasta formatos "estándar" .edf y .gdf .
Lo más importante que necesita saber sobre estos formatos es que no desea analizarlos o trabajar con ellos directamente.
Afortunadamente, un grupo de entusiastas de NeuroTechX escribió descargadores para algunos conjuntos de datos directamente en numpy.
Estos gestores de arranque son parte del proyecto moabb que dice ser una solución universal para BCI.
Descargar conjunto de datos sin procesar
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
En esta etapa, obtuvimos una estructura RawEDF que contiene registros EEG. Esta es una estructura del paquete mne , los biólogos generalmente la usan para interactuar con las señales: esta estructura tiene métodos incorporados para filtrar, visualizar, almacenar etiquetas, y nunca se sabe. Pero no iremos por este camino desde la interfaz del paquete tiende a ser inestable (la versión actual es 0.19 , pero usaremos 0.17 ya que la nueva versión ya no lee el conjunto de datos) y está mal documentada, a través de esto nuestros resultados pueden volverse irreproducibles.
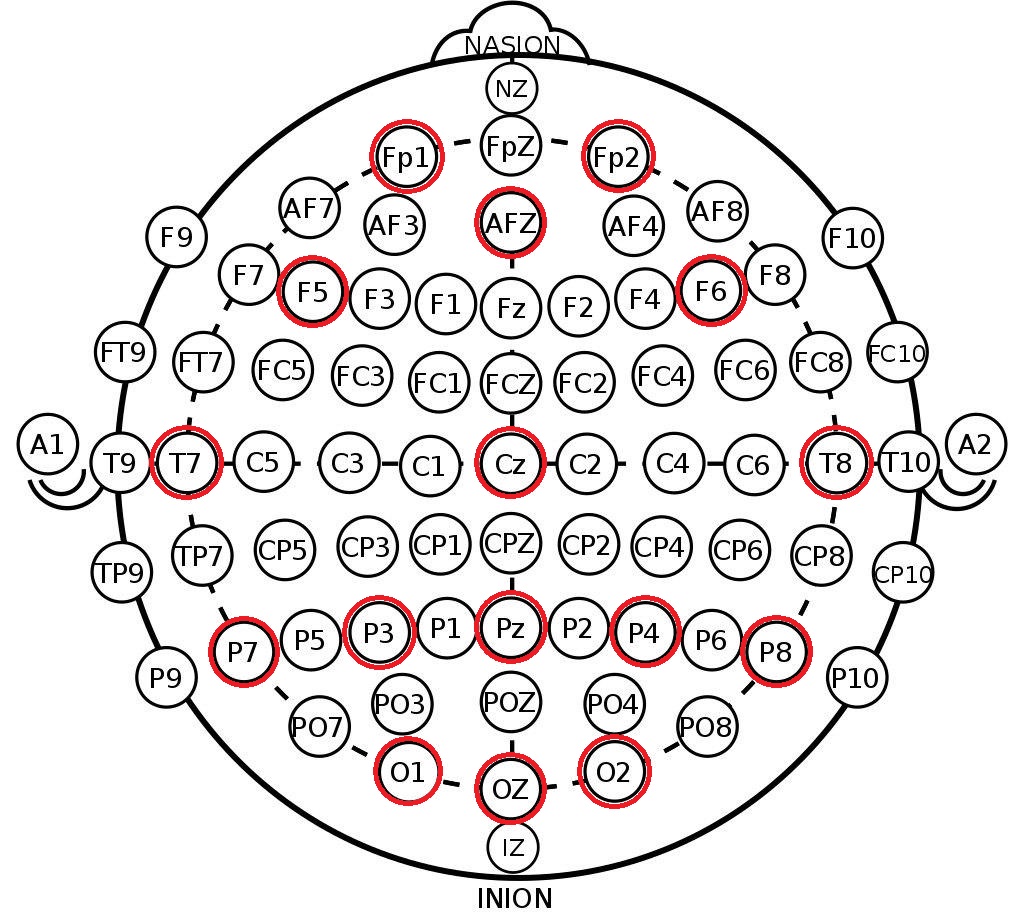
Lo que tomamos de la estructura resultante son las etiquetas de canal en el sistema 10-20 . Esta es una disposición internacional de electrodos en la cabeza de una persona, creada para que los científicos puedan correlacionar las zonas del cerebro y las ubicaciones de los canales de EEG. A continuación se muestra la disposición de los electrodos en el sistema 10-10 (difiere de 10-20 por el doble de la densidad de marcado) y los canales que se registraron en este conjunto de datos están marcados en rojo.
print(m_data[1]['session_1']['run_1'])
Primero, a partir de los datos descargados para cada sujeto, asignamos matrices de EEG continuo durante 16 segundos y todas las etiquetas para este intervalo (en los datos, este es solo otro canal en el que se señalan los comienzos de los eventos que nos interesan).
En esta etapa, mantenemos la longitud máxima del EEG continuo para no encontrar efectos de borde durante el filtrado posterior.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
Filtrado y Separación
En general, para revisar los métodos de preprocesamiento y clasificación del EEG, puedo recomendar una excelente visión general de los maestros de las interfaces de neurocomputadoras. Además, no hace mucho tiempo se lanzó una revisión más reciente de las pruebas de redes neuronales.
El preprocesamiento mínimo de la señal EEG para la clasificación incluye 3 pasos:
Para implementar estos pasos, utilizaremos el viejo sklearn y su paradigma para transformadores y tuberías para que nuestro preprocesamiento pueda ser fácilmente extensible.
El código de los transformadores se coloca en un archivo separado, a continuación describiremos algunos detalles.
Diezmacion
Por alguna razón, en algunos artículos y ejemplos de procesamiento, encontré una disminución en la frecuencia de la señal simplemente arrojando muestras en el estilo eeg = eeg[:, ::10] . Esto es completamente incorrecto (por qué, vea cualquier libro sobre procesamiento de señales). Utilizamos la scipy estándar scipy .
Filtrado
Aquí, también confiamos en filtros scipy seleccionando un filtro de paso de banda Butterworth de 4 órdenes y aplicándolo en la dirección hacia adelante y hacia atrás ( filtfilt ) para mantener la fase. Frecuencias de corte: de 0,5 a 20 Hz, este es el rango estándar para nuestra tarea.
Escalamiento
Utilizamos un StandardScaler por canal (resta el promedio, se divide por la desviación estándar), que ve todas las señales de la muestra. De hecho, se introduce una pequeña fuga de datos en este punto. formalmente, el escalador también ve datos de la muestra de prueba, pero con volúmenes de datos suficientemente grandes, la media y la desviación son las mismas.
La masturbación se realiza canal por canal para que dentro del mismo conjunto de datos sea posible agregar datos de diferentes sensores que tengan diferentes órdenes de magnitud y naturaleza (por ejemplo, reacción galvánica de la piel (RAG) )
Además de las operaciones anteriores, también fue posible distinguir artefactos en el EEG (parpadeo, movimientos de masticación, movimientos de la cabeza), pero este conjunto de datos ya está muy limpio, así que vamos a dejarlo hasta la próxima.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
A continuación, aplicaremos la tubería de preprocesamiento a nuestros datos y cortaremos la señal EEG continua en épocas. Llamaremos a la época el período de tiempo inmediatamente después de la activación del estímulo con una duración característica de 0.5-1 segundo, en nuestro caso, la duración es de 900 ms, aunque puede acortarse.
En nuestro conjunto de datos hay 16 canales de EEG, después de aplicar el diezmado, la frecuencia caerá a 50 Hz, por lo que una época se describirá mediante una matriz (16, 45) - 900 ms a 50 Hz son 45 muestras de tiempo.
Las etiquetas en este conjunto de datos son solo binarios: marcan las señales objetivo (ocultas por el jugador, activo, 1) y no objetivo (vacío, 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
Entonces obtuvimos un Pytorch de Pytorch estilo Pytorch en el que el primer índice cuenta a diferentes personas. Con esta estructura, podemos realizar una validación cruzada dentro de los datos de una persona y probar la tolerancia del clasificador entre diferentes personas (el llamado aprendizaje de transferencia, predicción sin calibración). Los datos de una persona consisten en una serie de eras y etiquetas de clase. El número de eras para cada persona varía ligeramente debido a las características de la grabación.
Investigación y visualización de datos.
Primero, eche un vistazo a una de las señales continuas antes de dividir en épocas.
A pesar de que ya se ha filtrado, no muestra ninguna activación en el ojo y se parece más a algún tipo de ruido.
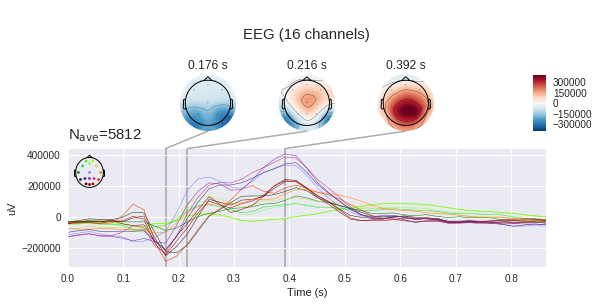
Si consideramos solo una época objetivo de nuestro conjunto de datos, entonces veremos un aumento característico en el intervalo de 400-600 ms. Este es nuestro potencial buscado P300.
En total, en nuestro conjunto de datos hay aproximadamente 35 mil épocas, es decir, activación de estímulo. Cada persona tiene aproximadamente 1300 a 1750 (esto se debe al hecho de que alguien derribó a los alienígenas más rápido y alguien más lento).
También hay un notable desequilibrio en las clases: 1 a 5 a favor de los estímulos vacíos. Tenemos 6 filas y columnas en la matriz y solo una de ellas es el objetivo. Más tarde volveremos a esto cuando discutamos las métricas obtenidas.
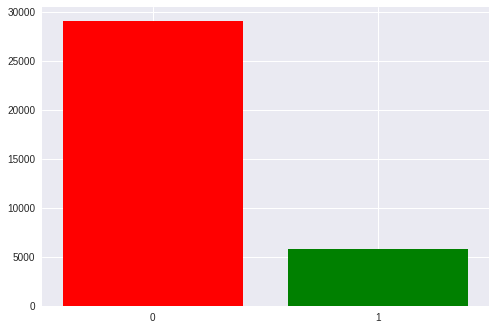
Ahora es el momento de ver la diferencia entre la señal objetivo y la no objetivo
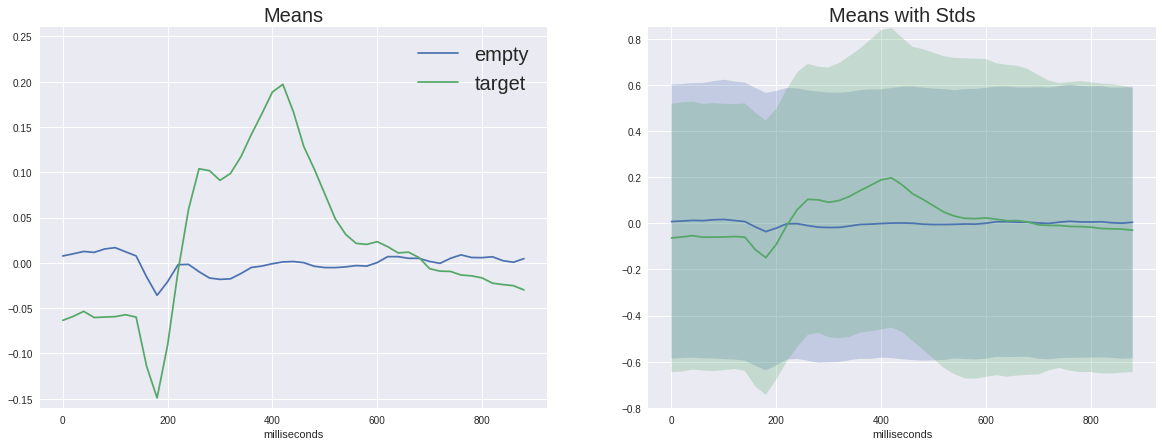
En el gráfico de la izquierda, puede ver que las señales promedio varían mucho, y ambas tienen una respuesta no específica en la región de 180 ms, pero el objetivo tiene mucha más amplitud, el objetivo también tiene una joroba característica de 250 a 500 ms: este es el notorio P300.
Con tal diferencia en la señal, nuestra tarea puede parecer un poco insignificante, pero si agregamos la desviación estándar en cada punto al gráfico, veremos que la imagen no es tan optimista: la señal es bastante ruidosa. Y esto a pesar del hecho de que la relación señal / ruido para el P300 se considera una de las más altas en neurofisiología.
(En realidad, estos gráficos no se construyen con honestidad, ya que la señal vacía se promedia en cinco veces más muestras diferentes, por lo que las desviaciones aleatorias se ahogan más, pero como podemos ver en la dispersión del mismo orden, esto no ayuda demasiado)

También es útil observar las señales promedio de una persona.
Aquí se encuentra el comentario anterior sobre el promedio "deshonesto": la señal vacía es notablemente más amplitud que con el promedio sobre todo. Además, el pico de P300 en una persona es mayor debido a un promedio menor.
Es importante tener en cuenta otra característica de la señal de una persona: tiene una forma ligeramente diferente a la generalizada. La variabilidad interpersonal de las reacciones neurofisiológicas es bastante alta, aún veremos la influencia de este factor en el trabajo de los clasificadores. Sin embargo, las diferencias intrapersonales (una persona en un estado de ánimo diferente, nivel de estrés, fatiga) también es bastante grande.

A continuación, vemos el barrido canal por canal de las señales. El punto de vista aquí coincide con la imagen de arriba, que representa la posición de los electrodos: nariz arriba, etc.
La respuesta de cada parte de la cabeza es diferente. En Fp1,2, se pronuncian dos picos negativos que preceden al pico positivo. Además, en algunos canales hay dos picos positivos, y en algunos, uno o algo de transición entre ellos.
Los diferentes canales son de diferente importancia para determinar la presencia de P300, se puede estimar usando diferentes métodos: calcular información mutua (información mutua) o el método de agregar-eliminar (también conocido como regresión gradual). La aplicación de estos métodos nos ocuparemos en otro momento.
Vale la pena recordar que medimos la diferencia de potencial entre los electrodos con electrodos, lo que significa que podemos construir mapas de voltaje para toda la cabeza en ciertos puntos en el tiempo usando cambios de voltaje en puntos individuales. Está claro que si hay 16 electrodos, la precisión de dicha tarjeta deja mucho que desear, pero se debe formar algo de comprensión. ( mne por defecto espera ver microvoltios, pero ya hemos aplicado la escala, por lo que los valores absolutos no son correctos)

Clasificación
Finalmente, es hora de aplicar métodos de aprendizaje automático a nuestra muestra.
Se eligieron varios básicos como clasificadores: un registro. Regresión, el método de vector de soporte (SVM) y varios métodos que utilizan el análisis de correlación del paquete pyriemann (los detalles de cada método se pueden encontrar en la documentación), vale la pena señalar que estos métodos fueron especialmente desarrollados para su aplicación al EEG y con su ayuda se ganaron varios concursos kaggle
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

El esquema más común de las interfaces neuronales es "calibración + trabajo", es decir Primero, es necesario que una persona se concentre en los estímulos previamente indicados durante algún tiempo, y solo después de eso predecimos su elección. Este enfoque tiene la desventaja obvia de una etapa inicial aburrida.
Para evaluar el rendimiento de nuestros métodos en este modo, realizaremos la validación cruzada dentro de las eras de una persona.
La métrica de precisión en este caso no es relevante debido al desequilibrio del conjunto de datos (la línea base aquí es 5/6 ~ 83%), por lo que prefiero mirar el tres de precisión de recuperación-f1.
Para revisar todo el conjunto de datos, promediamos los resultados de dicha validación cruzada en todas las personas. En general, el rendimiento de los mejores modelos es bastante alto en comparación con lo que tenemos en Neiry en las condiciones de "campo" de un parque de atracciones (recuerdo que este conjunto de datos se registró en el laboratorio).
En este conjunto de datos solo hay etiquetas binarias para los datos. En general, necesitamos resolver el problema multiclase de elegir uno de los estímulos (por cierto, está equilibrado ya que cada estímulo se activa el mismo número de veces). Para resolverlo, el número de activaciones de cada estímulo generalmente se fija (por ejemplo, 6 estímulos de 5 activaciones cada uno) y todos los estímulos se activan aleatoriamente (30 veces), se obtienen 30 épocas y se suman las probabilidades de sus activaciones para ser objetivo, después de lo cual el estímulo que ha alcanzado el máximo El importe se reconoce como objetivo. Demostraremos la implementación de este enfoque en una publicación futura en un conjunto de datos adecuado.

El segundo esquema se llama transferencia de aprendizaje, es decir, la transferencia del clasificador entre personas. El hecho es que cuando hacemos la calibración, en realidad volvemos a entrenar a la forma máxima de una persona, por lo que podemos predecirlo bien en las pruebas posteriores. En ausencia de calibración, el clasificador pre-entrenado debería poder aislar el concepto P300 sin conocer de antemano la forma de onda de una persona en particular.
Llevaremos a cabo dos experimentos: entrenaremos el clasificador en una persona, y pronosticaremos cinco, y luego aumentaremos la muestra de entrenamiento a 10 personas y compararemos los resultados para asegurarnos de que los modelos puedan aumentar su capacidad de generalización.
Entrenamiento para 1 persona

Entrenamiento para 10 personas.
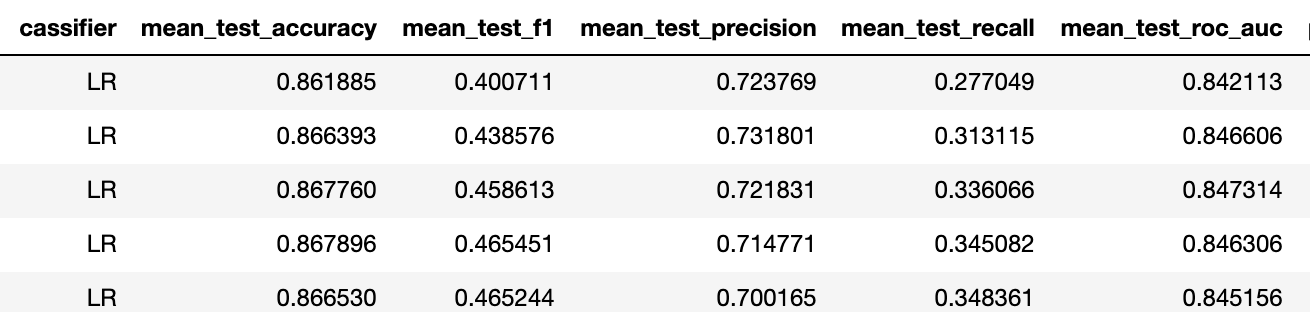
Entonces f1 subió de 0.23 a 0.4 para un mejor clasificador (en ambos casos es una regresión logarítmica con la misma regularización).
Esto significa que la capacidad predictiva ha aumentado de "no" a "aceptable". Según nuestra experiencia, con tales métricas del problema binario, 5 activaciones de cada estímulo son suficientes para lograr la precisión del problema multiclase de aproximadamente el 75%.
Al final, quiero señalar que el método anterior es bastante primitivo, lo que se puede ver, por ejemplo, por un alto grado de regularización de la regresión logarítmica: los canales en los datos están bastante correlacionados y hay varios enfoques para resolver esta circunstancia.
Conclusión
Hoy, nos familiarizamos más con el potencial evocado del P300 y construimos una tubería simple para la interfaz neuronal. Recomiendo a aquellos interesados en abrir una computadora portátil por su cuenta (ubicada en el repositorio ) y experimentar con opciones de visualización y clasificadores.
Teniendo una comprensión básica de los métodos de trabajo con la señal EEG, podremos examinar más a fondo este tema: aplicar métodos avanzados de preprocesamiento, así como redes neuronales, para resolver los problemas de la construcción de interfaces neuronales. Continuará ...