Durante los últimos años, he estado diseñando y fabricando una máquina que puede reconocer y clasificar piezas LEGO. La parte más importante de la máquina es la
Unidad de captura , un compartimento pequeño, casi completamente cerrado, en el que hay una cinta transportadora, iluminación y una cámara.
Iluminando verás un poco más abajo.La cámara toma fotos de las partes de LEGO que pasan por el transportador y luego transfiere las imágenes de forma inalámbrica a un servidor que ejecuta un algoritmo de inteligencia artificial para reconocer la parte entre miles de posibles elementos de LEGO. Te contaré más sobre el algoritmo de IA en futuros artículos, y este artículo se centrará en el procesamiento que se realiza entre la salida sin formato de la cámara de video y la entrada a la red neuronal.
El principal problema que tenía que resolver era convertir la transmisión de video del transportador en imágenes separadas de partes que una red neuronal podría usar.
El objetivo final: cambiar de un video sin formato (a la izquierda) a un conjunto de imágenes del mismo tamaño (a la derecha) para transferirlas a una red neuronal. (en comparación con el trabajo real, el gif es aproximadamente la mitad de lento)Este es un gran ejemplo de una tarea que en la superficie parece simple, pero en realidad plantea muchos obstáculos únicos e interesantes, muchos de los cuales son exclusivos de las plataformas de visión artificial.
La recuperación de las partes correctas de una imagen de esta manera a menudo se denomina detección de objetos. Eso es exactamente lo que necesito hacer: reconocer la presencia de objetos, su ubicación y tamaño, para que pueda generar
rectángulos delimitadores para cada parte en cada marco.
Lo más importante es encontrar buenos cuadros delimitadores (mostrados arriba en verde)Consideraré tres aspectos para resolver el problema:
- Prepararse para eliminar variables innecesarias
- Crear un proceso a partir de operaciones simples de visión artificial
- Mantener un rendimiento suficiente en una plataforma Raspberry Pi con recursos limitados
Eliminación de variables innecesarias.
En el caso de tales tareas, es mejor eliminar tantas variables como sea posible antes de usar técnicas de visión artificial. Por ejemplo, no debería preocuparme por las condiciones ambientales, las diferentes posiciones de la cámara, la pérdida de información debido a la superposición de algunas partes por otras. Por supuesto, es posible (aunque muy difícil) resolver todas estas variables mediante programación, pero afortunadamente para mí, esta máquina se creó desde cero. Yo mismo puedo prepararme para una solución exitosa, eliminando toda la interferencia incluso antes de comenzar a escribir código.
El primer paso es fijar firmemente la posición, el ángulo y el enfoque de la cámara. Con esto, todo es simple: en el sistema, la cámara se monta sobre el transportador. No necesito preocuparme por la interferencia de otras partes; Los objetos no deseados casi no tienen posibilidades de entrar en la unidad de captura. Un poco más complicado, pero es muy importante garantizar
condiciones de iluminación constantes . No necesito el reconocedor de objetos para interpretar erróneamente la sombra de una parte móvil a lo largo de la cinta como un objeto físico. Afortunadamente, la unidad de captura es muy pequeña (todo el campo de visión de la cámara es más pequeño que una barra de pan), por lo que tenía un control más que suficiente sobre las condiciones del entorno.
Unidad de captura, vista interior. La cámara está en el tercio superior del marco.Una solución es hacer que el compartimento esté completamente cerrado para que no entre la iluminación exterior. Intenté este enfoque usando tiras de LED como fuente de iluminación. Desafortunadamente, el sistema resultó ser muy malhumorado: solo un pequeño agujero en la caja es suficiente y la luz penetra en el compartimento, lo que hace imposible reconocer objetos.
Al final, la mejor solución era "obstruir" todas las otras fuentes de luz llenando el compartimento pequeño con luz fuerte. Resultó que las fuentes de luz que se pueden utilizar para iluminar locales residenciales son muy baratas y fáciles de usar.
¡Consigue las sombras!Cuando la fuente se dirige al compartimento pequeño, obstruye completamente toda posible interferencia de luz externa. Tal sistema también tiene un efecto secundario conveniente: debido a la gran cantidad de luz en la cámara, puede usar una velocidad de obturación muy alta, obteniendo imágenes perfectamente claras de las piezas incluso cuando se mueve rápidamente a lo largo del transportador.
Reconocimiento de objetos
¿Cómo logré convertir este hermoso video con iluminación uniforme en los cuadros delimitadores que necesitaba? Si trabaja con IA, podría sugerirme que implemente una red neuronal para el reconocimiento de objetos como
YOLO o
Faster R-CNN . Estas redes neuronales pueden hacer frente fácilmente a la tarea. Desafortunadamente, estoy ejecutando el código de reconocimiento de objetos en
Raspberry pi . Incluso una computadora poderosa tendría problemas para ejecutar estas redes neuronales convolucionales a la frecuencia que necesitaba alrededor de 90FPS. Y Raspberry pi, que no tiene una GPU compatible con AI, no podría hacer frente a una versión muy reducida de uno de esos algoritmos de AI. Puedo transmitir video desde Pi a otra computadora, pero la transmisión de video en tiempo real es un proceso muy cambiante, y las demoras y las limitaciones de ancho de banda causan serios problemas, especialmente cuando se necesita una alta velocidad de transferencia de datos.
¡YOLO es muy genial! Pero no necesito todas sus funciones.Afortunadamente, pude evitar una solución difícil basada en inteligencia artificial utilizando las técnicas de visión artificial de la "vieja escuela". La primera técnica es
la sustracción de fondo , que trata de aislar todas las partes cambiadas de la imagen. En mi caso, lo único que se mueve en el campo de visión de la cámara son los detalles de LEGO. (Por supuesto, la cinta también se mueve, pero como tiene un color uniforme, parece estacionaria para la cámara). Separe estos detalles de LEGO del fondo, y la mitad del problema está resuelto.
Para que funcione la sustracción del fondo, los objetos en primer plano deben ser significativamente diferentes del fondo. Los detalles de LEGO tienen una amplia gama de colores, así que tuve que elegir el color de fondo con mucho cuidado para que estuviera lo más alejado posible de los colores de LEGO. Es por eso que la cinta debajo de la cámara está hecha de papel: no solo debe ser muy uniforme, sino que tampoco puede consistir en LEGO, de lo contrario, ¡será del color de una de las partes que necesito reconocer! Elegí el rosa pálido, pero cualquier otro color pastel, a diferencia de los colores habituales de LEGO, servirá.
La maravillosa biblioteca OpenCV ya tiene varios algoritmos para sustracción de fondo. MOG2 Background Subtractor es el más complejo de ellos y, al mismo tiempo, funciona increíblemente rápido incluso en frambuesa pi. Sin embargo, alimentar fotogramas de video directamente a MOG2 no funciona muy bien. Las figuras de color gris claro y blanco están demasiado cerca del brillo de un fondo pálido y se pierden en él. Necesitaba encontrar una manera de separar más claramente la cinta de las partes en ella, ordenando al sustractor de fondo que mirara más de cerca el
color y no el
brillo . Para hacer esto, fue suficiente para mí aumentar la saturación de las imágenes antes de transferirlas a un sustractor de fondo. Los resultados han mejorado significativamente.
Después de restar el fondo, necesitaba usar operaciones morfológicas para eliminar el mayor ruido posible. Para encontrar los contornos de las áreas blancas, puede usar la función findContours () de la biblioteca OpenCV. Al aplicar varias heurísticas para desviar los bucles que contienen ruido, puede convertir fácilmente estos bucles en cuadros delimitadores predefinidos.
Rendimiento
Una red neuronal es una criatura voraz. Para obtener los mejores resultados en la clasificación, necesita imágenes de la máxima resolución y en la mayor cantidad posible. Esto significa que necesito dispararlos a una velocidad de cuadro muy alta, manteniendo la calidad y resolución de la imagen. Tengo que exprimir al máximo la cámara y la GPU Raspberry PI.
Una
documentación muy detallada
para picamera dice que el chip de la cámara V2 puede producir imágenes de 1280x720 píxeles de tamaño con una frecuencia máxima de 90 cuadros por segundo. Esta es una cantidad increíble de datos, y aunque la cámara puede generarlos, esto no significa que una computadora pueda manejarlos. Si tuviera que procesar imágenes RGB sin formato de 24 bits, tendría que transferir datos a una velocidad de aproximadamente 237 MB / s, que es demasiado para la pobre GPU de la computadora Pi y SDRAM. Incluso cuando se usa compresión acelerada por GPU en JPEG, no se pueden lograr 90 fps.
La Raspberry Pi es capaz de mostrar imágenes YUV sin filtrar y sin procesar. Aunque es más difícil trabajar con él que con RGB, YUV en realidad tiene muchas propiedades convenientes. El más importante de ellos es que almacena solo 12 bits por píxel (para RGB es de 24 bits).
Cada cuatro bytes de Y tienen un byte U y un byte V, es decir, 1.5 bytes por píxel.Esto significa que, en comparación con los cuadros RGB, puedo procesar el
doble de cuadros YUV, y esto sin contar el tiempo adicional que la GPU ahorra al convertir a imagen RGB.
Sin embargo, este enfoque impone restricciones únicas en el proceso de procesamiento. La mayoría de las operaciones con un cuadro de video de tamaño completo consumirán una cantidad extremadamente grande de memoria y recursos de CPU. Dentro de mis estrictos límites de tiempo, ni siquiera es posible decodificar un marco YUV de pantalla completa.
Afortunadamente, no necesito procesar todo el marco. Para el reconocimiento de objetos, los rectángulos delimitadores no tienen que ser precisos, la precisión aproximada es suficiente, por lo que todo el proceso de reconocimiento de objetos se puede realizar con un marco mucho más pequeño. La operación de alejamiento no es necesaria para tener en cuenta todos los píxeles de un cuadro de tamaño completo, por lo que los cuadros se pueden reducir muy rápidamente y sin costo. Luego, la escala de los rectángulos delimitadores resultantes aumenta nuevamente y se usa para cortar objetos de un marco YUV de tamaño completo. Gracias a esto, no necesito decodificar o procesar el marco completo de alta resolución.
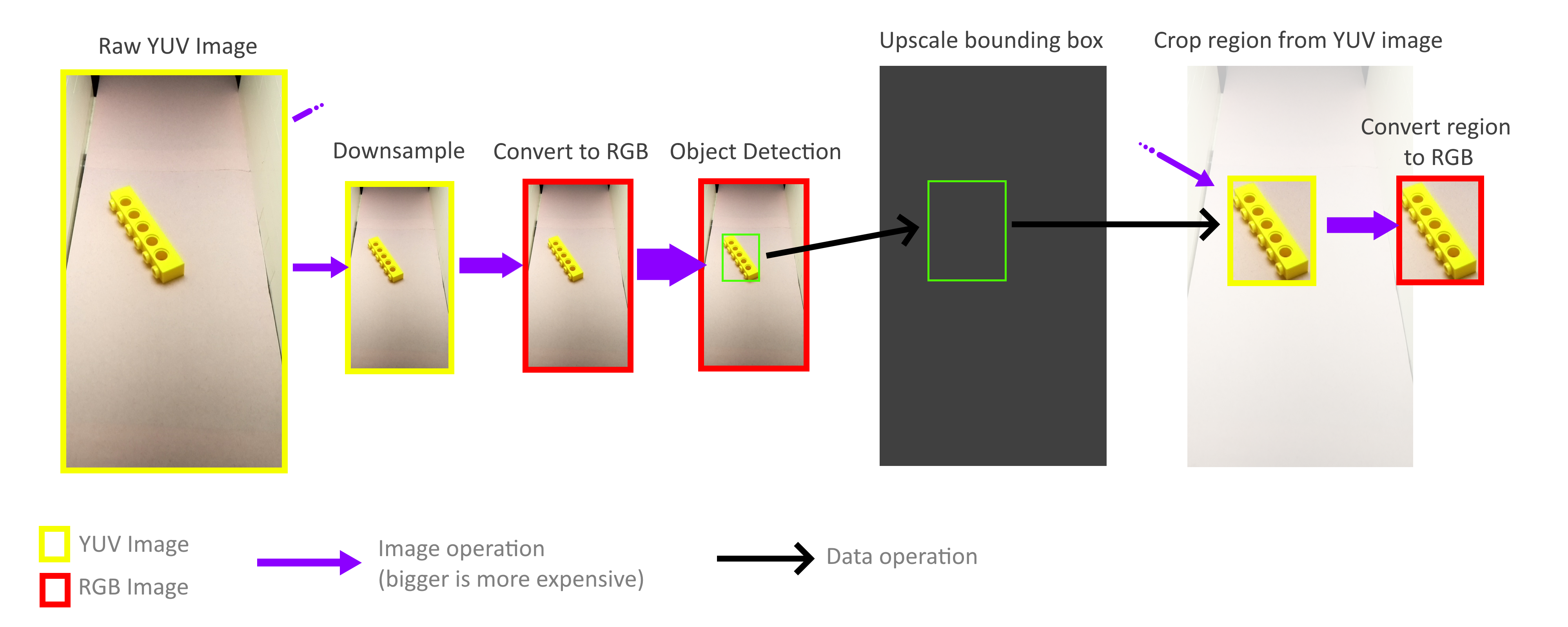
Afortunadamente, gracias al método de almacenamiento de este formato YUV (ver arriba), es muy fácil implementar operaciones de recorte y zoom rápidas que funcionan directamente con el formato YUV. Además, todo el proceso puede ser paralelo a cuatro núcleos Pi sin ningún problema. Sin embargo, descubrí que no todos los núcleos se utilizan en todo su potencial, y esto nos dice que el ancho de banda de la memoria sigue siendo el cuello de botella. Pero aun así, logré alcanzar 70-80FPS en la práctica. Un análisis más profundo del uso de la memoria podría ayudar a acelerar las cosas aún más.
Si quieres saber más sobre el proyecto, lee mi artículo anterior,
"Cómo creé más de 100 mil imágenes LEGO etiquetadas para el aprendizaje" .
Video del funcionamiento de toda la máquina de clasificación: