Continuaré un análisis sin prisas de la implementación de tipos básicos en CPython, anteriormente se consideraron
diccionarios y
enteros . Se alienta a aquellos que piensan que no puede haber nada interesante y astuto en su implementación a unirse a estos artículos. Aquellos que ya los han leído saben que CPython tiene muchas características interesantes y características de implementación. Pueden ser útiles para saber al escribir sus propios guiones, o como una guía para soluciones arquitectónicas y algorítmicas. Las cadenas no son una excepción aquí.
Comencemos con una breve digresión en la historia. Python apareció en 1990-91. Inicialmente, cuando se desarrollaba la codificación de base en Python, había un simple byte, un viejo ascii. Pero, aproximadamente al mismo tiempo (un poco más tarde), la humanidad estaba cansada de lidiar con el "zoológico" de codificaciones, y en 1991 se propuso el estándar Unicode. Sin embargo, la primera vez tampoco funcionó. Comenzó la introducción de codificaciones de dos bytes, pero muy pronto se hizo evidente que dos bytes no serían suficientes para todos, se propuso una codificación de 4 bytes. Desafortunadamente, asignar 4 bytes para cada carácter parecía un desperdicio de espacio en disco y memoria, especialmente en aquellos países donde un ascii de un solo byte era suficiente antes. Se recortaron varias muletas en una codificación de 2 bytes para admitir más caracteres, y todo esto comenzó a parecerse a la situación anterior con el "zoológico" de codificaciones.
Pero en 1993 se introdujo utf-8. Lo cual fue un compromiso: ascii era un subconjunto válido de utf-8, todos los demás personajes lo expandieron, sin embargo, para admitir esta posibilidad, tuve que separarme de una longitud fija de cada personaje. Pero fue él quien estaba destinado a
gobernar a todos para que se convirtieran exactamente en Unicode, es decir, una sola codificación compatible con la mayoría de los programas en los que se almacenan la mayoría de los archivos. Esto fue especialmente influenciado por el desarrollo de Internet, ya que las páginas web usualmente usaban solo utf-8.
El soporte para esta codificación se introdujo gradualmente en lenguajes de programación que, como python, se desarrollaron antes de utf-8 y, por lo tanto, utilizaron otras codificaciones. Hay
PEP con un buen número 100 que discutió el soporte Unicode. Y en
PEP-0263 se hizo posible declarar la codificación de los archivos fuente. La codificación seguía siendo la codificación base, el prefijo `u` se usaba para declarar cadenas unicode, trabajar con ellas todavía no era lo suficientemente conveniente y natural. Pero hubo una oportunidad para crear la siguiente herejía:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
El 3 de diciembre de 2008, tuvo lugar un evento histórico para toda la comunidad de Python (y dada la gran difusión de este lenguaje ahora, tal vez, para todo el mundo), se lanzó Python 3. Se decidió poner fin a los problemas de una vez por todas debido a muchas codificaciones y, por lo tanto, Unicode se ha convertido en la codificación base. Pero recordamos que la codificación es complicada y no funciona la primera vez. Esta vez tampoco funcionó.
El gran inconveniente de utf-8 es que la longitud del carácter no es fija, lo que lleva al hecho de que una operación tan simple como acceder al índice tiene una complejidad O (N), ya que el desplazamiento del elemento no se conoce de antemano, además, conociendo el tamaño del búfer, asignado para almacenar una cadena, no puede calcular su longitud en caracteres.
Para evitar todos estos problemas en Python, se decidió utilizar codificaciones de 2 y 4 bytes (dependiendo de la plataforma). El manejo del índice se simplificó: solo era necesario multiplicar el índice por 2 o 4. Sin embargo, esto conllevaba sus problemas:
- Cada plataforma tenía su propia codificación, lo que podría generar problemas con la portabilidad del código.
- Aumento del consumo de memoria y / o problemas de codificación para caracteres complicados que no caben en dos bytes
Se propuso una solución a estos problemas en
PEP-393 , y hablaremos de ello.
Se decidió dejar las líneas como una matriz de caracteres, para facilitar el acceso por índice y otras operaciones, sin embargo, la longitud de los caracteres comenzó a variar. Al crear una cadena, el intérprete escanea todos los caracteres y asigna a cada uno el número de bytes que es necesario para almacenar el "más grande", es decir, si declara una cadena ascii, todos los caracteres serán de un solo byte, sin embargo, si decide agregar un carácter a la cadena de cirílico, todos los personajes ya serán de dos bytes. Hay tres opciones posibles: 1, 2 y 4 bytes por carácter.
El tipo de cadena (PyUnicodeObject) se declara de la
siguiente manera :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
A su vez, PyCompactUnicodeObject representa la
siguiente estructura (proporcionada con algunas simplificaciones y mis comentarios):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
Por lo tanto, son posibles 4 representaciones de línea:
- cadena heredada, lista
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- cadena heredada, no lista
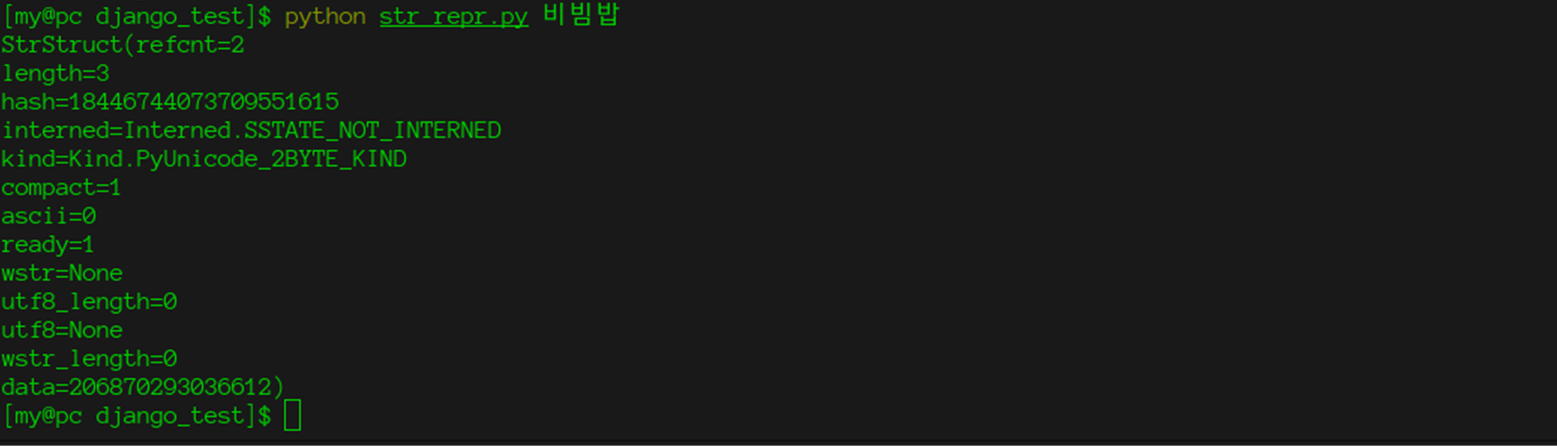
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- ascii compacto
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- compacto
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
Cabe señalar que python 3 también admite la sintaxis para declarar cadenas unicode a través del prefijo `u`.
>>> b = u"" >>> b ''
Esta característica se agregó para facilitar el código de portabilidad de la segunda versión a la tercera en
PEP-414 en Python 3.3 solo en febrero de 2012, permítame recordarle que Python 3 se lanzó en diciembre de 2008, pero nadie tenía prisa con la transición.
Armados con este conocimiento y el módulo ctypes estándar, podemos acceder a los campos internos de la cadena.
import ctypes import enum import sys class Interned(enum.Enum):
E incluso "rompe" al intérprete, como hiciste en la
parte anterior .
DESCARGO DE RESPONSABILIDAD: El siguiente código se proporciona tal cual, el autor no asume ninguna responsabilidad y no puede garantizar el estado del intérprete, así como la salud mental de usted y sus colegas, después de ejecutar este código. El código se prueba en cpython versión 3.7 y, desafortunadamente, no funciona con cadenas ASCII.
Para hacer esto, cambie el código descrito anteriormente a:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
Estos ejemplos usan la interpolación de cadenas agregada en
python 3.6 . Python no llegó inmediatamente a este método de salida de cadenas: se intentó% sintaxis, formato, algo así
como Perl (
aquí se puede encontrar una descripción más detallada con ejemplos).
Quizás este cambio para su época (antes de python 3.8 con su operador `: =`) fue el más controvertido. La discusión (y condena) se llevó a cabo tanto en
reddit como incluso en forma de
PEP . Las ideas de mejora / corrección se expresaron en la forma de agregar
líneas i para que los usuarios pudieran escribir sus analizadores, para un mejor control y para evitar inyecciones SQL y otros problemas. Sin embargo, este cambio se pospuso, para que las personas se acostumbren a las líneas f e identifiquen problemas, si los hay.
Las líneas F tienen una peculiaridad (inconveniente): no puede especificar caracteres especiales con barras diagonales, por ejemplo, '\ n' '\ t'. Sin embargo, esto se puede evitar fácilmente declarando una línea separada que contenga caracteres especiales y pasándola a la línea f, que se realizó en el ejemplo anterior, pero puede usar paréntesis anidados.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
Como puede ver, las cadenas almacenan su hash; hubo una
sugerencia de usar este valor para comparar cadenas, basado en una regla simple: si las cadenas son las mismas, entonces tienen el mismo hash, y se deduce que las cadenas con diferentes hashes no son lo mismo. Sin embargo, no se cumplió.
Al comparar dos cadenas, se verifica si los punteros a las cadenas se refieren a la misma dirección; de lo contrario, se inicia una comparación carácter por carácter o memcmp en los casos en que esto sea válido.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
Sin embargo, el valor hash afecta indirectamente a la comparación. El hecho es que en cpython, las cadenas están internadas, es decir, almacenadas en un solo diccionario. Esto no es cierto para todas las líneas; todas las constantes, claves de diccionario, campos y variables, y líneas ascii con una longitud de menos de 20 están internados.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
Y la cadena vacía es generalmente singleton
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
Como podemos ver, cpython fue capaz de crear una implementación simple, pero al mismo tiempo, eficiente del tipo de cadena. Fue posible reducir la memoria utilizada y acelerar las operaciones en algunos casos, gracias a las funciones memcmp, memcpy, en lugar de las operaciones carácter por carácter. Como puede ver, el tipo de cadena no es tan simple de implementar como podría parecer la primera vez. Pero los desarrolladores de cpython han abordado con habilidad su negocio y, por lo tanto, podemos usarlo y ni siquiera pensar en lo que hay debajo del capó.