Ciencia de datos para principiantes1. Análisis de sentimientos

Vea la implementación completa del proyecto Data Science utilizando el código fuente -
Proyecto de análisis de sentimientos en R.El análisis de sentimientos es un análisis de palabras para identificar estados de ánimo y opiniones que pueden ser positivas o negativas. Este es un tipo de clasificación en la que las clases pueden ser binarias (positivas y negativas) o plurales (felices, malvadas, tristes, desagradables ...). Implementaremos este proyecto de Data Science en el lenguaje R y utilizaremos el conjunto de datos en el paquete janeaustenR. Utilizaremos diccionarios de uso general, como AFINN, bing y loughran, para realizar una unión interna, y al final crearemos una nube de palabras para mostrar el resultado.
Idioma: R
Conjunto de datos
/ paquete: janeaustenR

Este artículo fue traducido con el apoyo de EDISON Software, una compañía que hace probadores virtuales para tiendas multimarca , y también prueba software .
2. Detección de noticias falsas
Lleva tus habilidades al siguiente nivel trabajando en el proyecto Data Science para principiantes:
descubriendo noticias falsas usando Python .
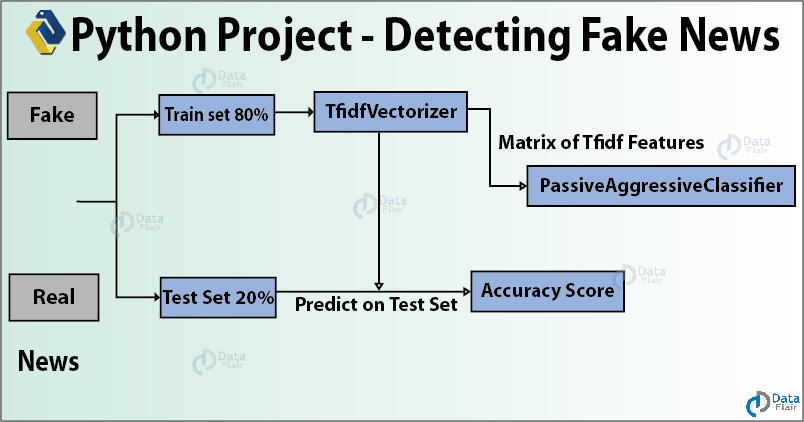
Las noticias falsas son información falsa difundida a través de las redes sociales y otros medios en línea para lograr objetivos políticos. En esta idea de proyecto de Data Science, usaremos Python para construir un modelo que pueda determinar con precisión si las noticias son reales o falsas. Crearemos un TfidfVectorizer y usaremos el PassiveAggressiveClassifier para clasificar las noticias en "reales" y "falsas". Usaremos el conjunto de datos del formulario 7796 × 4 y ejecutaremos todo en el Laboratorio Jupyter.
Lenguaje: Python
Conjunto de datos
/ paquete: news.csv
3. Detección de la enfermedad de Parkinson (detección de la enfermedad de Parkinson)
Siga adelante con la idea del proyecto de ciencia de datos:
identificar la enfermedad de Parkinson con XGBoost .
Comenzamos a usar Data Science para mejorar la atención médica y los servicios: si podemos predecir la enfermedad en una etapa temprana, tendremos muchos beneficios. Entonces, en esta idea de proyecto de Data Science, aprenderemos cómo detectar la enfermedad de Parkinson usando Python. Esta es una enfermedad neurodegenerativa y progresiva del sistema nervioso central que afecta el movimiento y causa temblor y rigidez. Afecta a las neuronas productoras de dopamina en el cerebro, y cada año afecta a más de 1 millón de personas en la India.
Lenguaje: Python
Conjunto de datos
/ paquete: conjunto de datos UCI ML Parkinsons
Proyectos de ciencia de datos de complejidad media4. Reconocimiento de la emoción del habla
Consulte la implementación completa del proyecto de muestra de Data Science:
Reconocimiento de voz con Librosa .
Ahora aprendamos a usar diferentes bibliotecas. Este proyecto de Data Science utiliza librosa para el reconocimiento de voz. SER es el proceso de determinar las emociones humanas y los estados afectivos a partir del habla. Dado que utilizamos tono y tono para expresar emociones en voz, SER es relevante. Pero como las emociones son subjetivas, el sonido de anotación es una tarea desalentadora. Usaremos las funciones mfcc, chroma y mel y usaremos el conjunto de datos RAVDESS para reconocer las emociones. Crearemos un clasificador MLPC para este modelo.
Lenguaje: Python
Conjunto de datos
/ paquete: conjunto de datos RAVDESS
5. Detección de género y edad
Sorprenda a los empleadores con el último proyecto de Data Science:
Determinación de género y edad con OpenCV .

Esta es una ciencia de datos interesante con Python. Usando solo una imagen, aprenderá a predecir el género y la edad de una persona. En esto, le presentaremos la visión por computadora y sus principios. Construiremos una
red neuronal convolucional y utilizaremos modelos entrenados por Tal Hassner y Jill Levy para el conjunto de datos Adience. En el camino, utilizaremos algunos archivos .pb, .pbtxt, .prototxt y .caffemodel.
Lenguaje: Python
Conjunto de datos
/ paquete: Adience
6. Análisis de datos de Uber
Vea la implementación completa del proyecto Source Science Data Science, el
Proyecto de Análisis de Datos Uber en R.
Este es un proyecto de visualización de datos con ggplot2, en el que utilizaremos R y sus bibliotecas y analizaremos varios parámetros. Utilizaremos el conjunto de datos de Uber Pickups en Nueva York y crearemos visualizaciones para diferentes períodos de tiempo del año. Esto nos dice cómo el tiempo afecta el viaje del cliente.
Idioma: R
Conjunto de datos
/ paquete: Uber Pickups en el conjunto de datos de la ciudad de Nueva York
7. Detección de somnolencia del conductor
Mejore sus habilidades mientras trabaja en el Proyecto de ciencia de datos principales:
un sistema de detección de sueño con OpenCV y Keras .
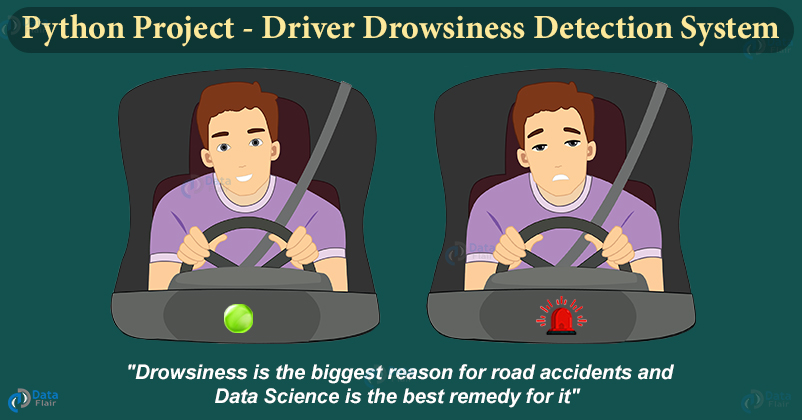
Conducir con sueño es extremadamente peligroso, y cada año se producen alrededor de mil accidentes debido al hecho de que los conductores se quedan dormidos mientras conducen. En este proyecto de Python, crearemos un sistema que pueda detectar controladores somnolientos, así como notificarlos con una señal de sonido.
Este proyecto se implementa utilizando Keras y OpenCV. Usaremos OpenCV para detectar la cara y los ojos, y con Keras clasificaremos el estado del ojo (abierto o cerrado) utilizando técnicas de redes neuronales profundas.
8. Chatbot
Cree un
chatbot con Python y
dé un paso adelante en su carrera:
Chatbot con NLTK y Keras .

Los chatbots son una parte integral del negocio. Muchas empresas tienen que ofrecer servicios a sus clientes, y su servicio requiere mucho trabajo, tiempo y esfuerzo. Los chatbots pueden automatizar la mayoría de sus interacciones con los clientes respondiendo algunas de las preguntas comunes que los clientes hacen. Básicamente hay dos tipos de chatbots: dominio específico y dominio abierto. Un bot de chat específico de dominio a menudo se usa para resolver un problema específico. Por lo tanto, debe configurarlo para que funcione de manera efectiva en su campo. A los bots de chat de dominio abierto se les puede hacer cualquier pregunta, por lo que se requiere una gran cantidad de datos para entrenarlos.
Conjunto de datos
: archivo json de intenciones
Lenguaje: Python
Proyectos avanzados de ciencia de datos9. Generador de subtítulos de imagen
Consulte la implementación completa del proyecto con el código fuente:
generador de subtítulos de imágenes con CNN y LSTM .

La descripción de lo que hay en la imagen es una tarea fácil para las personas, pero para las computadoras, una imagen es solo un conjunto de números que representan el valor de color de cada píxel. Esta es una tarea difícil para las computadoras. Comprender lo que hay en la imagen y luego crear una descripción en lenguaje natural (por ejemplo, en inglés) es otra tarea difícil. Este proyecto utiliza métodos de estudio en profundidad en los cuales implementamos una red neuronal recurrente (CNN) con una red neuronal recurrente (LSTM) para crear un generador de descripción de imagen.
Conjunto de datos: Flickr 8K
Lenguaje: Python
Marco: Keras
10. Detección de fraude con tarjeta de crédito (Definición de fraude con tarjeta de crédito)
Haz tu mejor esfuerzo trabajando en la idea del proyecto Data Science:
detectar fraudes con tarjetas de crédito mediante el aprendizaje automático .

Por ahora, ha comenzado a comprender los métodos y conceptos. Pasemos a algunos proyectos avanzados de ciencia de datos. En este proyecto, utilizaremos el lenguaje R con algoritmos como
árboles de decisión , regresión logística, redes neuronales artificiales y el clasificador de refuerzo de gradiente. Utilizaremos un conjunto de datos de transacciones con tarjeta para clasificar las transacciones con tarjeta de crédito como fraudulentas y genuinas. Seleccionaremos diferentes modelos para ellos y crearemos curvas de rendimiento.
Idioma: R
Conjunto de datos
/ paquete: conjunto de datos de transacciones con tarjeta
11. Sistema de recomendación de películas
Aprenda a implementar el mejor proyecto de ciencia de datos con el código fuente:
sistema de recomendación de películas en R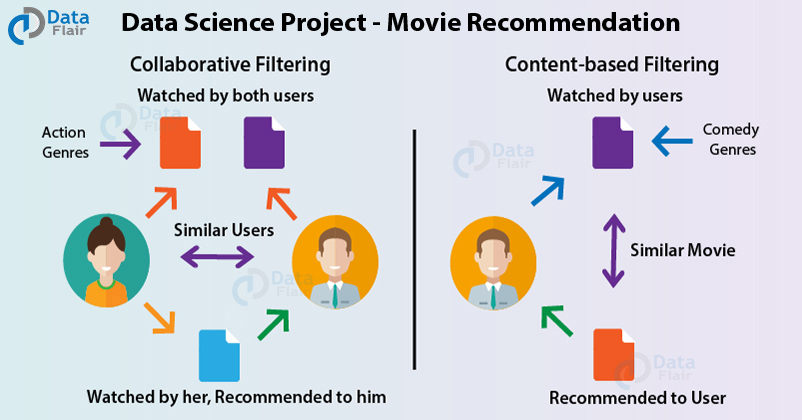
En este proyecto de Data Science, usaremos R para cumplir con las recomendaciones de la película a través del aprendizaje automático. El sistema de recomendaciones envía sugerencias a los usuarios a través de un proceso de filtrado basado en las preferencias de otros usuarios y el historial de navegación. Si a A y B les gusta Solo en casa, y a B le gustan las chicas malas, entonces puedes ofrecer A, a ellos también les puede gustar. Esto permite a los clientes interactuar con la plataforma.
Idioma: R
Conjunto de datos
/ paquete: conjunto de datos MovieLens
12. Segmentación del cliente
Impresione a los empleadores con un proyecto de ciencia de datos (incluido el código fuente):
segmentación de clientes mediante el aprendizaje automático .

La segmentación de clientes es una aplicación de
aprendizaje popular
no supervisada . Mediante la agrupación, las empresas definen segmentos de clientes para trabajar con una base de usuarios potenciales. Dividen a los clientes en grupos de acuerdo con características comunes, como género, edad, intereses y hábitos de gasto, para que puedan vender sus productos de manera efectiva a cada grupo. Utilizaremos el
agrupamiento K-means , así como visualizaremos la distribución por género y edad. Luego analizamos sus ingresos anuales y el nivel de gastos.
Idioma: R
Conjunto de datos
/ paquete: conjunto de datos Mall_Customers
13. Clasificación del cáncer de mama
Vea la implementación completa del proyecto Data Science en Python -
Clasificación del cáncer de mama con aprendizaje profundo .

Volviendo a la contribución médica de la ciencia de datos, aprendamos a detectar el cáncer de seno usando Python. Utilizaremos el conjunto de datos IDC_regular para detectar el carcinoma invasivo del conducto, la forma más común de cáncer de seno. Se desarrolla en los conductos lácteos, penetrando en el tejido fibroso o graso de la glándula mamaria fuera del conducto. En esta idea de un proyecto de recopilación de datos científicos, utilizaremos
Deep Learning y la biblioteca Keras para la clasificación.
Lenguaje: Python
Conjunto de datos
/ paquete: IDC_regular
14. Reconocimiento de señales de tránsito
Lograr la precisión en la tecnología de autoconducción con el proyecto de
reconocimiento de signos de Data Science
utilizando CNN Open Source.

Las señales de tránsito y las normas de tránsito son muy importantes para que todos los conductores eviten accidentes. Para seguir la regla, primero debe comprender cómo se ve una señal de tráfico. Una persona debe aprender todas las señales de tráfico antes de que se le otorgue el derecho de conducir cualquier vehículo. Pero ahora el número de vehículos autónomos está creciendo, y en el futuro cercano, las personas ya no podrán controlar la máquina de forma independiente. En el proyecto "Reconocimiento de señales de tráfico", aprenderá cómo el programa puede reconocer el tipo de señales de tráfico al aceptar una imagen como señal de entrada. La Lista de verificación de reconocimiento de señales de tráfico alemanas (GTSRB) se utiliza para construir una red neuronal profunda para reconocer la clase a la que pertenece la señal de tráfico. También creamos una interfaz gráfica simple para interactuar con la aplicación.
Lenguaje: Python
Conjunto de datos
: GTSRB (Benchmark de reconocimiento de señales de tráfico alemán)
Leer mas

Lee también el blog
Empresa EDISON:
20 bibliotecas para
espectacular aplicación para iOS