 Que?
Que? Un códec de video es una pieza de software / hardware que comprime y / o descomprime video digital.
Para que? A pesar de ciertas limitaciones en términos de ancho de banda,
y en términos de la cantidad de espacio de almacenamiento, el mercado requiere más y más videos de alta calidad. ¿Recuerdas cómo en la última publicación calculamos el mínimo necesario para 30 fotogramas por segundo, 24 bits por píxel, con una resolución de 480x240? Recibió 82.944 Mbps sin compresión. La compresión es la única forma de transferir HD / FullHD / 4K a pantallas de TV e Internet. ¿Cómo se logra esto? Ahora consideraremos brevemente los métodos principales.

La traducción se realizó con el apoyo del software EDISON.
Nos dedicamos a la integración de sistemas de videovigilancia , así como al desarrollo de una microtomografía .
Códec vs Contenedor
Un error común de los novatos es confundir un códec de video digital y un contenedor de video digital. Un contenedor tiene cierto formato. Un contenedor que contiene metadatos de video (y posiblemente audio). El video comprimido se puede considerar como una carga útil de contenedor.
Por lo general, una extensión de archivo de video indica un tipo de contenedor. Por ejemplo, el archivo video.mp4 es probablemente un
contenedor MPEG-4 Parte 14 , y el archivo llamado video.mkv es probablemente una
muñeca rusa. Para tener plena confianza en el códec y el formato del contenedor, puede usar
FFmpeg o
MediaInfo .
Un poco de historia
Antes de llegar a
¿Cómo? , profundicemos un poco en la historia para comprender un poco mejor algunos códecs antiguos.
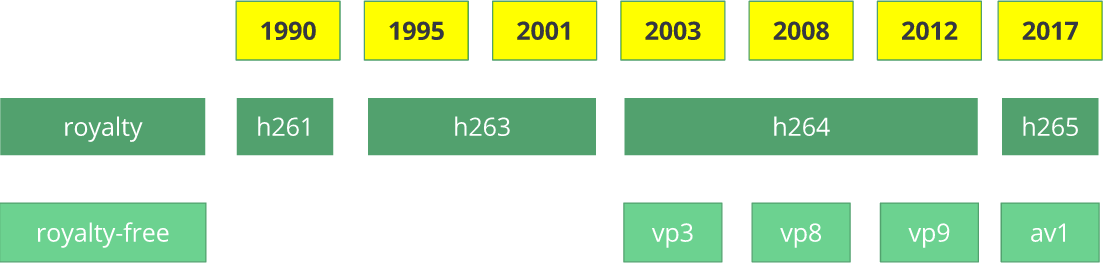
El códec de video
H.261 apareció en 1990 (técnicamente, en 1988) y fue creado para trabajar con una velocidad de transferencia de datos de 64 Kbps. Ya ha utilizado ideas como submuestreo de color, macrobloques, etc. En 1995, se publicó el estándar de códec de video
H.263 , que se desarrolló hasta 2001.
En 2003, se completó la primera versión de
H.264 / AVC . En el mismo año, TrueMotion lanzó su códec de video gratuito que comprime el video con pérdida llamado
VP3 . En 2008, Google compró esta compañía, lanzando
VP8 en el mismo año. En diciembre de 2012, Google lanzó
VP9 , y es compatible en aproximadamente ¾ del mercado de navegadores (incluidos los dispositivos móviles).
AV1 es un nuevo códec de video de código abierto gratuito desarrollado
por Open Media Alliance (
AOMedia ), que incluye compañías conocidas como Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel y Cisco . La primera versión del códec 0.1.0 se publicó el 7 de abril de 2016.
Nacimiento de AV1
A principios de 2015, Google trabajó en
VP10 , Xiph (que pertenece a Mozilla) trabajó en
Daala y Cisco creó su códec de video gratuito llamado
Thor .
Luego,
MPEG LA anunció por primera vez los límites anuales para
HEVC (
H.265 ) y una tarifa 8 veces mayor que para H.264, pero pronto cambiaron las reglas nuevamente:
sin límite anual,
tarifa de contenido (0.5% de los ingresos) y
los costos unitarios son aproximadamente 10 veces más altos que para H.264.
Open Media Alliance fue creada por empresas de diversos campos: fabricantes de equipos (Intel, AMD, ARM, Nvidia, Cisco), proveedores de contenido (Google, Netflix, Amazon), fabricantes de navegadores (Google, Mozilla) y otros.
Las compañías tenían un objetivo común: un códec de video sin regalías. Luego viene
AV1 con una licencia de patente mucho más simple. Timothy B. Terriberry hizo una presentación sorprendente, que se convirtió en la fuente del concepto actual de AV1 y su modelo de licencia.
Te sorprenderá saber que puedes analizar el códec AV1 a través de un navegador (los interesados pueden ir a
aomanalyzer.org ).

Códec universal
Analicemos los mecanismos básicos que subyacen al códec de video universal. La mayoría de estos conceptos son útiles y se utilizan en códecs modernos como
VP9 ,
AV1 y
HEVC . Te advierto que muchas cosas explicadas se simplificarán. A veces se usarán ejemplos del mundo real (como es el caso con H.264) para demostrar la tecnología.
1er paso: dividir la imagen
El primer paso es dividir el marco en varias secciones, subsecciones y más.

Para que? Hay muchas razones Cuando dividimos la imagen, podemos predecir con mayor precisión el vector de movimiento utilizando pequeñas secciones para pequeñas partes móviles. Mientras que para un fondo estático, puede restringirse a secciones más grandes.
Normalmente, los códecs organizan estas secciones en secciones (o fragmentos), macrobloques (o bloques de un árbol de codificación) y muchas subsecciones. El tamaño máximo de estas particiones varía, HEVC establece 64x64, mientras que AVC usa 16x16, y las subsecciones se pueden dividir hasta 4x4.
¿Recuerdas las variedades de marcos del último artículo? Lo mismo se puede aplicar a los bloques, por lo tanto, podemos tener un fragmento I, un bloque B, un macrobloque P, etc.
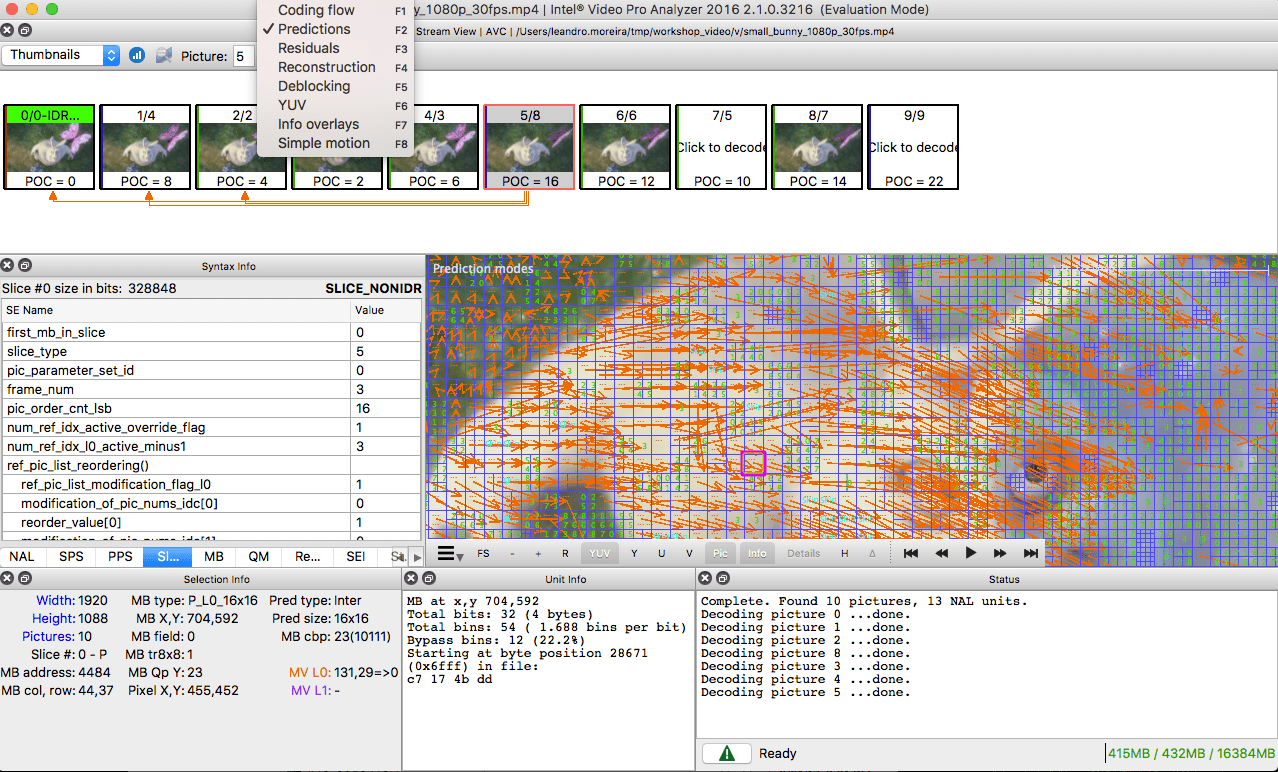
Para aquellos que quieran practicar, miren cómo se dividirá la imagen en secciones y subsecciones. Para hacer esto, puede usar el
analizador Intel Video Pro ya mencionado en el artículo anterior (el que se paga, pero con una versión de prueba gratuita, que tiene un límite en los primeros 10 cuadros). Las secciones de
VP9 se analizan aquí:

2do paso - pronóstico
Tan pronto como tengamos secciones, podemos hacer pronósticos
astrológicos sobre ellas. Para
la predicción INTER, es necesario transferir los
vectores de movimiento y el resto, y para la predicción INTRA, se transmiten la
dirección del pronóstico y el resto.
3er paso - conversión
Después de obtener el bloque residual (la sección predicha → la sección real), es posible transformarlo de tal manera que sepa qué píxeles se pueden descartar, manteniendo la calidad general. Hay algunas transformaciones que proporcionan un comportamiento preciso.
Aunque existen otros métodos, consideremos con más detalle la
transformada discreta del coseno (
DCT - de la
transformada discreta del coseno ). Características clave de DCT:
- Convierte bloques de píxeles en bloques de coeficientes de frecuencia de igual tamaño.
- Sella la potencia, ayudando a eliminar la redundancia espacial.
- Proporciona reversibilidad.
2 de febrero de 2017 Sintra R.J. (Cintra, RJ) y Bayer F.M. (Bayer FM) publicó un artículo sobre conversión tipo DCT para la compresión de imágenes, que requiere solo 14 adiciones.
No se preocupe si no comprende los beneficios de cada artículo. Ahora, con ejemplos concretos, verificaremos su valor real.
Tomemos un bloque de 8x8 píxeles como este:
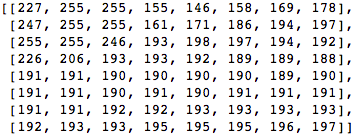
Este bloque se representa en la siguiente imagen de 8 por 8 píxeles:
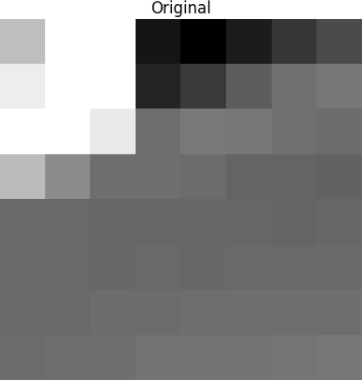
Aplique DCT a este bloque de píxeles y obtenga un bloque de coeficientes de tamaño 8x8:
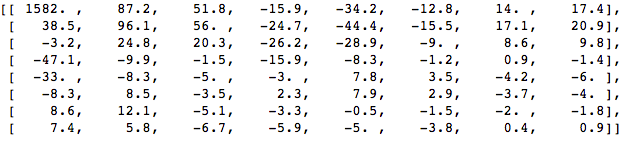
Y si representamos este bloque de coeficientes, obtenemos la siguiente imagen:
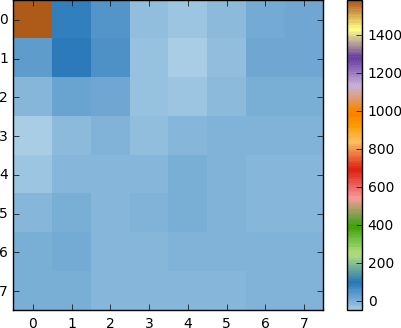
Como puede ver, esto no es como la imagen original. Puede notar que el primer coeficiente es muy diferente de todos los demás. Este primer coeficiente se conoce como un coeficiente DC que representa todas las muestras en la matriz de entrada, algo similar al valor promedio.
Este bloque de coeficientes tiene una propiedad interesante: separa los componentes de alta frecuencia de los de baja frecuencia.
En la imagen, la mayor parte de la potencia se concentra a frecuencias más bajas, por lo tanto, si convierte la imagen en sus componentes de frecuencia y descarta los coeficientes de frecuencia más altos, puede reducir la cantidad de datos necesarios para describir la imagen sin sacrificar demasiado la calidad de la imagen.
Frecuencia significa qué tan rápido cambia la señal.
Intentemos aplicar el conocimiento adquirido en el ejemplo de prueba convirtiendo la imagen original a su frecuencia (bloque de coeficientes) usando DCT, y luego descartando algunos de los coeficientes menos importantes.
Primero, conviértalo al dominio de frecuencia.
A continuación, descartamos parte (67%) de los coeficientes, principalmente el lado inferior derecho.
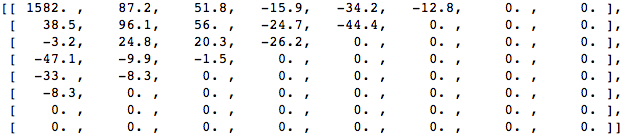
Finalmente, restauramos la imagen de este bloque de coeficientes descartado (recuerde, debe ser reversible) y lo comparamos con el original.
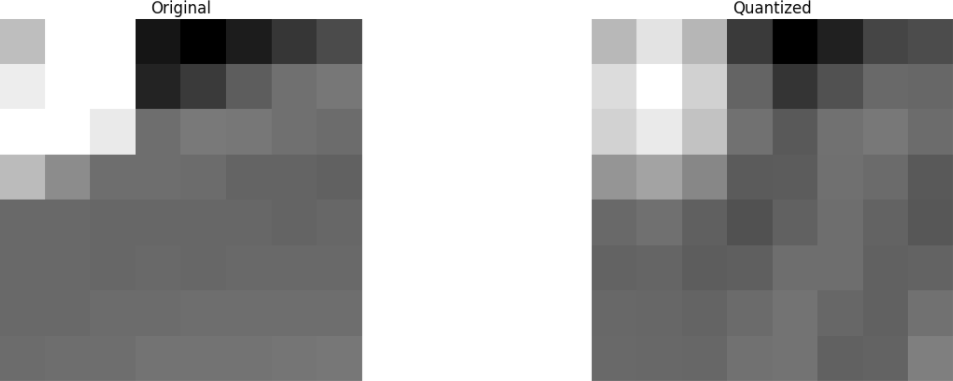
Vemos que se parece a la imagen original, pero hay muchas diferencias con respecto a la original. Lanzamos 67.1875% y todavía obtuvimos algo que se parece a la fuente original. Podrías descartar más deliberadamente los coeficientes para obtener una imagen de mejor calidad, pero este es el siguiente tema.
Cada coeficiente se genera utilizando todos los píxeles.
Importante: cada coeficiente no se muestra directamente en un píxel, sino que es una suma ponderada de todos los píxeles. Este sorprendente gráfico muestra cómo se calculan los coeficientes primero y segundo utilizando pesos únicos para cada índice.
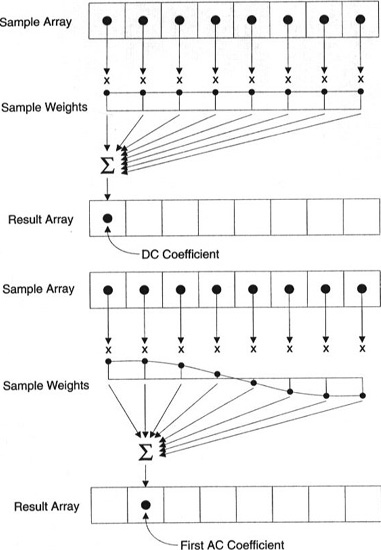
También puede intentar visualizar DCT mirando imágenes simples basadas en él. Por ejemplo, aquí está el símbolo A generado usando cada peso de coeficiente:

4to paso - cuantización
Después de arrojar algunos coeficientes en el paso anterior, en el último paso (transformación), producimos una forma especial de cuantización. En este punto, está permitido perder información. O, más simplemente, cuantificaremos los coeficientes para lograr la compresión.
¿Cómo se puede cuantificar un bloque de coeficientes? Uno de los métodos más simples será la cuantización uniforme, cuando tomamos un bloque, lo dividimos por un valor (por 10) y redondeamos lo que sucedió.
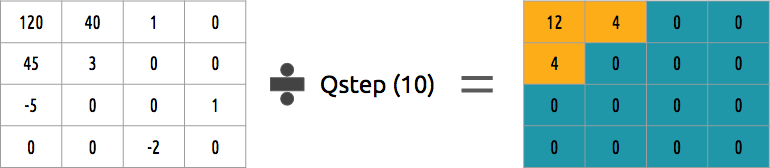
¿Podemos revertir este bloque de coeficientes? Sí, podemos multiplicar por el mismo valor por el que dividimos.
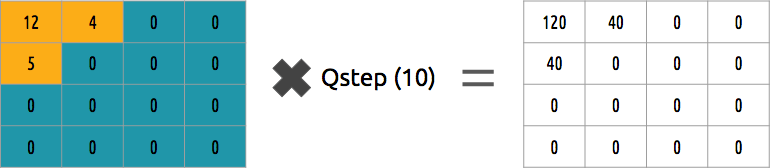
Este enfoque no es el mejor, ya que no tiene en cuenta la importancia de cada coeficiente. Se podría usar la matriz cuantificadora en lugar de un solo valor, y esta matriz podría usar la propiedad DCT, cuantificando la mayor parte de la parte inferior derecha y una minoría de la parte superior izquierda.
5 pasos - codificación de entropía
Después de cuantificar los datos (bloques de imagen, fragmentos, cuadros), aún podemos comprimirlos sin pérdida. Hay muchas formas algorítmicas para comprimir datos. Vamos a conocer brevemente algunos de ellos, para una comprensión más profunda, puede leer el libro "
Comprender la compresión: compresión de datos para desarrolladores modernos " ("
Comprender la compresión: compresión de datos para desarrolladores modernos ").
Codificación de video con VLC
Supongamos que tenemos una secuencia de caracteres:
a ,
e ,
r y
t . En esta tabla se presenta la probabilidad (que varía de 0 a 1) de la frecuencia con la que cada símbolo ocurre en la secuencia.
Podemos asignar códigos binarios únicos (preferiblemente pequeños) a los más probables, y códigos más grandes menos probables.
Comprimimos la secuencia, suponiendo que al final gastemos 8 bits para cada personaje. Sin compresión en un personaje, se necesitarían 24 bits. Si cada personaje se reemplaza con su código, ¡obtenemos ahorros!
El primer paso es codificar el carácter
e , que es 10, y el segundo carácter es
a , que se agrega (no matemáticamente): [10] [0], y finalmente, el tercer carácter
t , que hace que nuestro flujo de bits comprimido final sea igual [10] [0] [1110] o
1001110 , que requiere solo 7 bits (3,4 veces menos espacio que en el original).
Tenga en cuenta que cada código debe ser un código único con un prefijo.
El algoritmo de Huffman ayudará a encontrar estos números. Aunque este método no está exento de fallas, hay códecs de video que aún ofrecen este método algorítmico para la compresión.
Tanto el codificador como el decodificador deben tener acceso a la tabla de símbolos con sus códigos binarios. Por lo tanto, también es necesario enviar una tabla en la entrada.
Codificación aritmética
Supongamos que tenemos una secuencia de caracteres:
a ,
e ,
r ,
syt , y su probabilidad está representada por esta tabla.
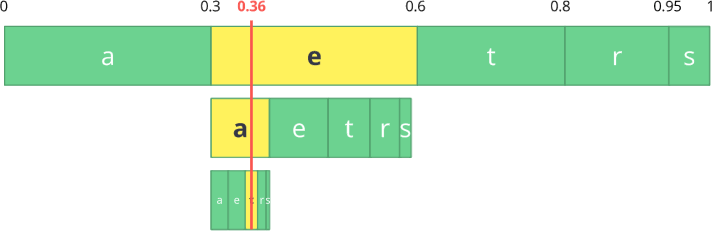
Con esta tabla, construimos rangos que contienen todos los caracteres posibles, ordenados por el número más grande.

Ahora codifiquemos una secuencia de tres caracteres:
comer .
Primero, seleccione el primer carácter
e , que está en el sub-rango de 0.3 a 0.6 (sin incluir). Tomamos este subrango y lo dividimos nuevamente en las mismas proporciones que antes, pero ya para este nuevo rango.

Sigamos codificando nuestra secuencia de
comer . Ahora tomamos el segundo símbolo
a , que está en el nuevo subrango de 0.3 a 0.39, y luego tomamos nuestro último símbolo
t y, repitiendo el mismo proceso nuevamente, obtenemos el último subrango de 0.354 a 0.372.
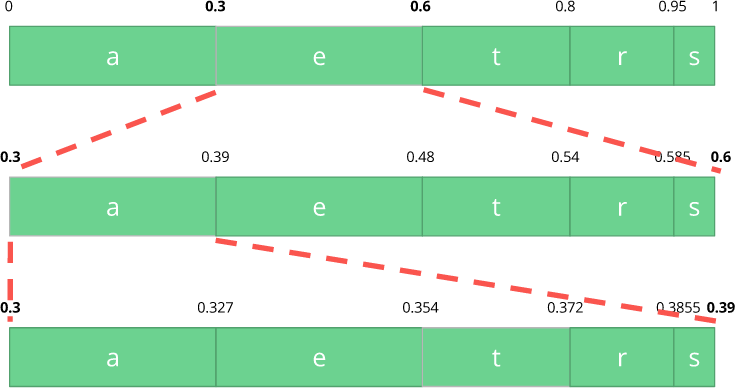
Solo necesitamos seleccionar un número en el último subrango de 0.354 a 0.372. Elijamos 0.36 (pero puede elegir cualquier otro número en este subrango). Solo con este número podemos restaurar nuestro flujo original. Es como si estuviéramos dibujando una línea dentro de los rangos para codificar nuestra secuencia.
La operación inversa (es decir, la
decodificación ) es igual de simple: con nuestro número 0.36 y nuestro rango inicial, podemos comenzar el mismo proceso. Pero ahora, usando este número, revelamos la secuencia codificada usando este número.
Con el primer rango, notamos que nuestro número corresponde a un segmento, por lo tanto, este es nuestro primer carácter. Ahora, de nuevo, compartimos esta subbanda, realizando el mismo proceso que antes. Aquí puede ver que 0.36 corresponde al carácter
a , y después de repetir el proceso, llegamos al último carácter
t (formando nuestro flujo codificado original como
comer ).
Tanto el codificador como el decodificador deben tener una tabla de probabilidades de símbolos, por lo tanto, es necesario enviarlo en los datos de entrada.
Bastante elegante, ¿no es así? Alguien a quien se le ocurrió esta solución fue muy inteligente. Algunos códecs de video usan esta técnica (o, en cualquier caso, la ofrecen como una opción).
La idea es comprimir un flujo de bits cuantificado sin pérdidas. Seguramente en este artículo no hay toneladas de detalles, razones, compromisos, etc. Pero usted, si es desarrollador, debería saber más. Los nuevos códecs están intentando utilizar diferentes algoritmos de codificación de entropía, como
ANS .
6 pasos - formato de flujo de bits
Después de hacer todo esto, queda por desempaquetar los cuadros comprimidos en el contexto de los pasos tomados. El decodificador debe ser informado explícitamente de las decisiones tomadas por el codificador. Se debe proporcionar al decodificador toda la información necesaria: profundidad de bits, espacio de color, resolución, información de pronóstico (vectores de movimiento, predicción INTER direccional), perfil, nivel, velocidad de cuadros, tipo de cuadro, número de cuadro y mucho más.
Echaremos un vistazo al flujo de bits
H.264 . Nuestro primer paso es crear un flujo de bits H.264 mínimo (FFmpeg por defecto agrega todos los parámetros de codificación, como
SEI NAL ; un poco más, descubriremos de qué se trata). Podemos hacer esto usando nuestro propio repositorio y FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Este comando generará un flujo de bits
H.264 sin formato con un cuadro, resolución 64x64, con el espacio de color
YUV420 . La siguiente imagen se usa como marco.

H.264 Bitstream
El
estándar AVC (
H.264 ) define que la información se enviará en marcos macro (en la comprensión de la red) llamada
NAL (este es un nivel de abstracción de red). El objetivo principal de NAL es proporcionar una presentación de video "amigable para la red". Este estándar debería funcionar en televisores (basados en transmisiones), en Internet (basados en paquetes).

Hay un marcador de sincronización para definir los límites de los elementos NAL. Cada marcador de sincronización contiene el valor
0x00 0x00 0x01, con la excepción del primero, que es
0x00 0x00 0x00 0x01. Si ejecutamos
hexdump para el flujo de bits H.264 generado, identificaremos al menos tres patrones NAL al comienzo del archivo.
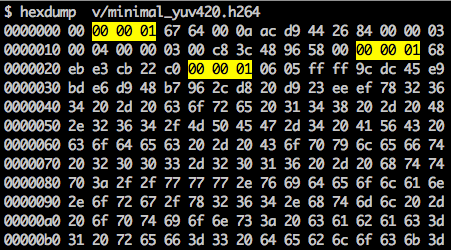
Como se indicó, el decodificador debe conocer no solo los datos de la imagen, sino también los detalles del video, el marco, el color, los parámetros utilizados y mucho más. El primer byte de cada NAL define su categoría y tipo.
Por lo general, el primer flujo de bits NAL es
SPS . Este tipo de NAL es responsable de informar variables de codificación comunes, como perfil, nivel, resolución y más.
Si omitimos el primer token de sincronización, podemos decodificar el primer byte para averiguar qué tipo de NAL es el primero.
Por ejemplo, el primer byte después del marcador de sincronización es
01100111 , donde el primer bit (
0 ) está en el campo f
orbidden_zero_bit . Los siguientes 2 bits (
11 ) nos
indican el campo
nal_ref_idc, que indica si este NAL es un campo de referencia o no. Y los 5 bits restantes (
00111 ) nos
indican el campo
nal_unit_type, en este caso es un bloque
NPS SPS (
7 ).
El segundo byte (
binario =
01100100 ,
hexadecimal =
0x64 ,
dec =
100 ) en el SPS NAL es el campo
profile_idc, que muestra el perfil que utilizó el codificador. En este caso, se utilizó un perfil alto limitado (es decir, un perfil alto sin soporte para un segmento B bidireccional).

Si nos familiarizamos con la especificación del flujo de bits
H.264 para SPS NAL, encontraremos muchos valores para el nombre, la categoría y la descripción del parámetro. Por ejemplo, veamos los
campos pic_width_in_mbs_minus_1 y
pic_height_in_map_units_minus_1 .
Si realizamos algunas operaciones matemáticas con los valores de estos campos, obtendremos permiso. Puede imaginar
1920 x 1080 usando
pic_width_in_mbs_minus_1 con un valor de
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) . Nuevamente, ahorrando espacio, en lugar de codificar 1920 lo hicieron con 119.
Si continuamos verificando nuestro video creado en forma binaria (por ejemplo:
xxd -b -c 11 v / minimal_yuv420.h264 ), entonces podemos ir al último NAL, que es el marco en sí.

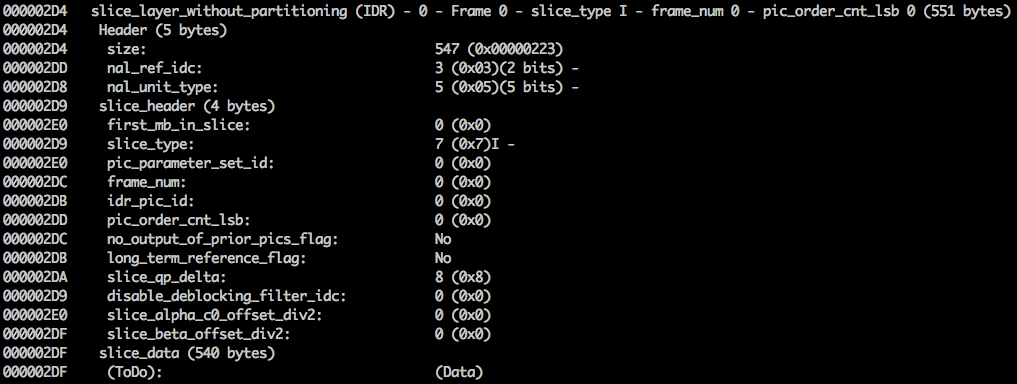
Aquí vemos sus primeros valores de 6 bytes:
01100101 10001000 10000100 00000000 00100001 11111111 . Como se sabe que el primer byte indica el tipo de NAL, en este caso (
00101 ) este es un fragmento IDR (5), y luego será posible estudiarlo más a fondo:

Usando la información de especificación, será posible decodificar el tipo de fragmento (
slice_type ) y el número de cuadro (
frame_num ) entre otros campos importantes.
Para obtener los valores de algunos campos (
ue (
v ),
me (
v ),
se (
v ) o
te (
v )), necesitamos decodificar el fragmento utilizando un decodificador especial basado en el
código exponencial de Golomb . Este método es muy efectivo para codificar valores variables, especialmente cuando hay muchos valores predeterminados.
Los valores
slice_type y
frame_num de este video son 7 (fragmento I) y 0 (primer fotograma).
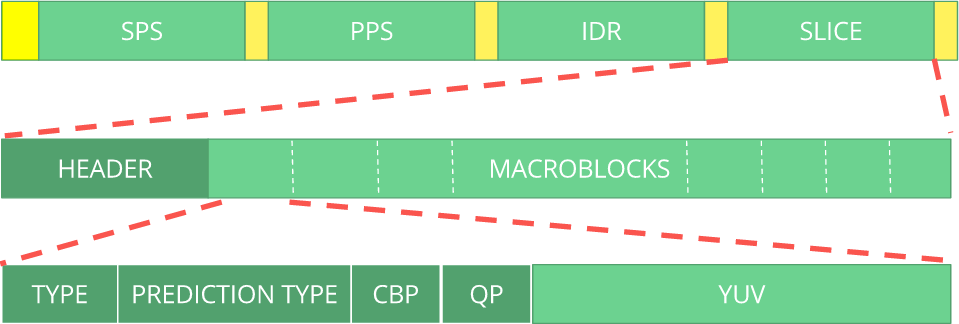
Bitstream puede considerarse como un protocolo. Si desea saber más sobre el flujo de bits, debe consultar la especificación
ITU H.264 . Aquí hay una macro que muestra dónde están los datos de la imagen (
YUV en forma comprimida).
Puede explorar otros flujos de bits, como
VP9 ,
H.265 (
HEVC ), o incluso nuestro nuevo mejor flujo de bits
AV1 . ¿Son todos iguales? No, pero haber tratado con al menos uno es mucho más fácil de entender el resto.
¿Quieres practicar? Explore el flujo de bits H.264
Puede generar video de un solo cuadro y usar MediaInfo para examinar el flujo de bits H.264 . De hecho, nada le impide siquiera mirar el código fuente que analiza el flujo de bits H.264 ( AVC ).
Para practicar, puede usar Intel Video Pro Analyzer (ya dije que el programa es de pago, pero ¿hay una versión de prueba gratuita con un límite de 10 fotogramas?).
Revisar
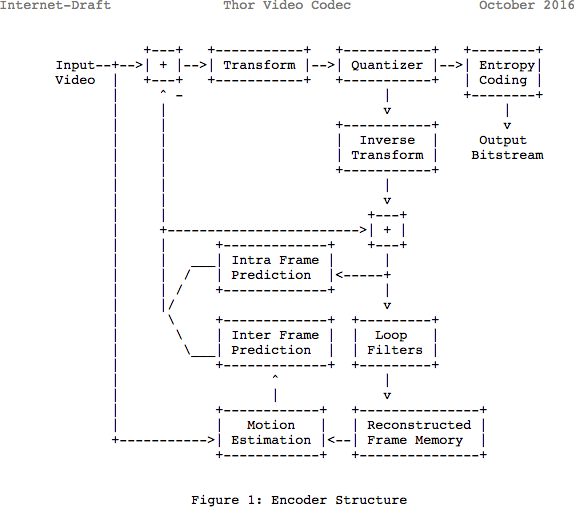
Tenga en cuenta que muchos códecs modernos usan el mismo modelo que acaban de aprender. Aquí, echemos un vistazo al diagrama de bloques del códec de video
Thor . Contiene todos los pasos que hemos tomado. El objetivo de esta publicación es que al menos comprenda mejor las innovaciones y la documentación en esta área.
Anteriormente, se estimaba que se necesitarían 139 GB de espacio en disco para almacenar un archivo de video que dura una hora con una calidad de 720p y 30 fps. Si usa los métodos que se discutieron en este artículo (pronósticos internos y entre cuadros, conversión, cuantización, codificación de entropía, etc.), entonces puede lograr (suponiendo que gastemos 0.031 bits por píxel), el video es de una calidad bastante satisfactoria, que ocupa solo 367.82 MB, no 139 GB de memoria.
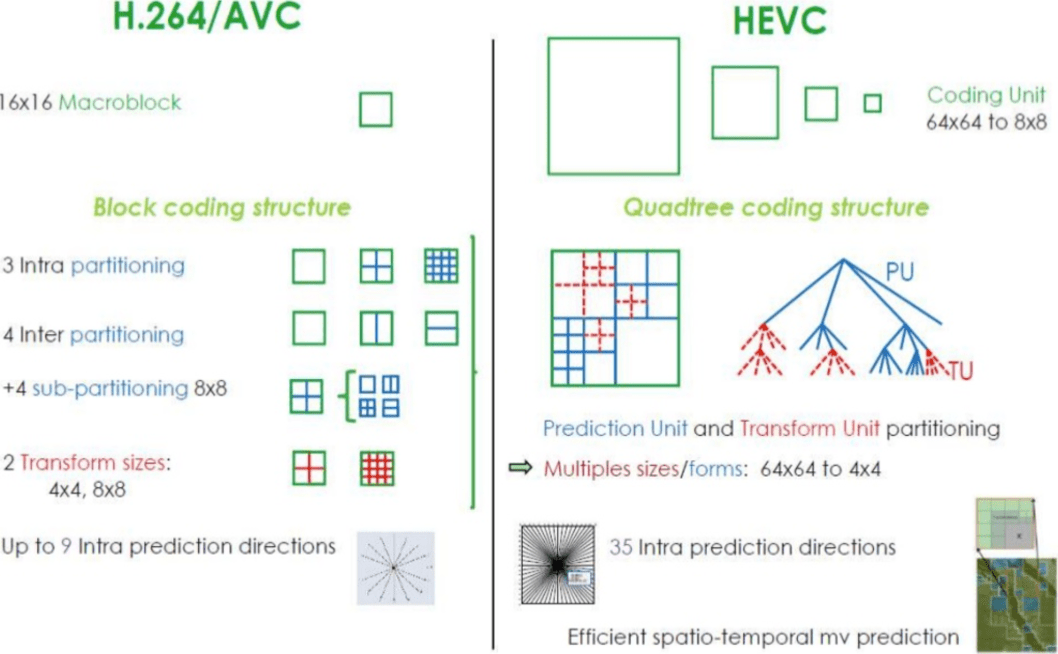
¿Cómo logra H.265 una mejor relación de compresión que H.264?
Ahora que sabe más sobre cómo funcionan los códecs, es más fácil entender cómo los nuevos códecs pueden proporcionar una resolución más alta con menos bits.
Al comparar
AVC y
HEVC , no debe olvidar que esto casi siempre es una elección entre una mayor carga de CPU y una relación de compresión.
HEVC tiene más opciones para secciones (y subsecciones) que
AVC , más instrucciones para pronósticos internos, codificación de entropía mejorada y mucho más. Todas estas mejoras hicieron que
H.265 fuera capaz de comprimir un 50% más que
H.264 .

Lee también el blog
Empresa EDISON:
20 bibliotecas para
espectacular aplicación para iOS