Último año escolar, abril. Los estudiantes cada vez más a menudo comienzan a asistir a la idea de que sería necesario hacer una tesis. Hacerlo es, en el sentido, descubrir cómo cocinar rápidamente algo que esté al menos en sintonía con el tema que, al parecer, fue aprobado por el supervisor. Y sí, necesita al menos 80 páginas, también debe cumplir con todo tipo de GOST ... Está claro, no tiene tiempo para escribir tanto texto conectado usted mismo (¡e incluso pueden entrar en la esencia del trabajo, bueno!). Obviamente, debe tomar el trabajo terminado que ya ha sido defendido, trabajo de calidad, probado y aprobado. La situación nos es familiar a todos. La única pregunta que queda abierta es cómo asegurarse de que el trabajo sea probado para tomar prestado ... Las búsquedas en Internet y la comunicación con colegas en desgracia llevan al estudiante a las siguientes opciones para resolver el problema:
Escribe el trabajo tú mismo;- Para reformular el texto (costoso y difícil);
- Superar al sistema con "soluciones técnicas".

Veamos qué son las rondas técnicas, cómo las atrapamos y por qué su uso no es una buena idea ...
Reformular puede ayudar a pasar el texto de otra persona como suyo si se hace bien. Sin embargo, la reformulación de alta calidad en sí misma es un proceso muy laborioso para el cual el estudiante probablemente no tiene el tiempo y el dinero. Los métodos simples de reformulación (por ejemplo, sinonimización) darán un resultado que no solo será detectado por el sistema antiplagio, sino que también, muy probablemente, divertirá al supervisor y al comité de certificación.
Por lo tanto, llegamos a la herramienta más creativa y más popular entre los estudiantes, soluciones técnicas, transformaciones de documentos que, sin cambiar la visualización del documento original, cambian el texto extraído por el sistema de verificación .
Desde el punto de vista de trabajar con rondas técnicas (en adelante las llamaremos simplemente "rondas"), el sistema antiplagio tiene dos tareas:
- Detección de posibles derivaciones y notificación al usuario sobre ellas;
- Borrar el texto verificado de los rastreos.
El esquema general de las rondas de procesamiento se puede describir de la siguiente manera:
- Detección de derivaciones, guardando información sobre ellas;
- Borrar el texto extraído de los rastreos;
- La definición de "sospecha" del documento basada en los desvíos;
- Mostrar información sobre sospechas al usuario, visualización de desvíos encontrados.
Así es como se ve en la práctica.
Documento en formato docx:
Comprobación de un documento sin funcionalidad de detección de rastreo:
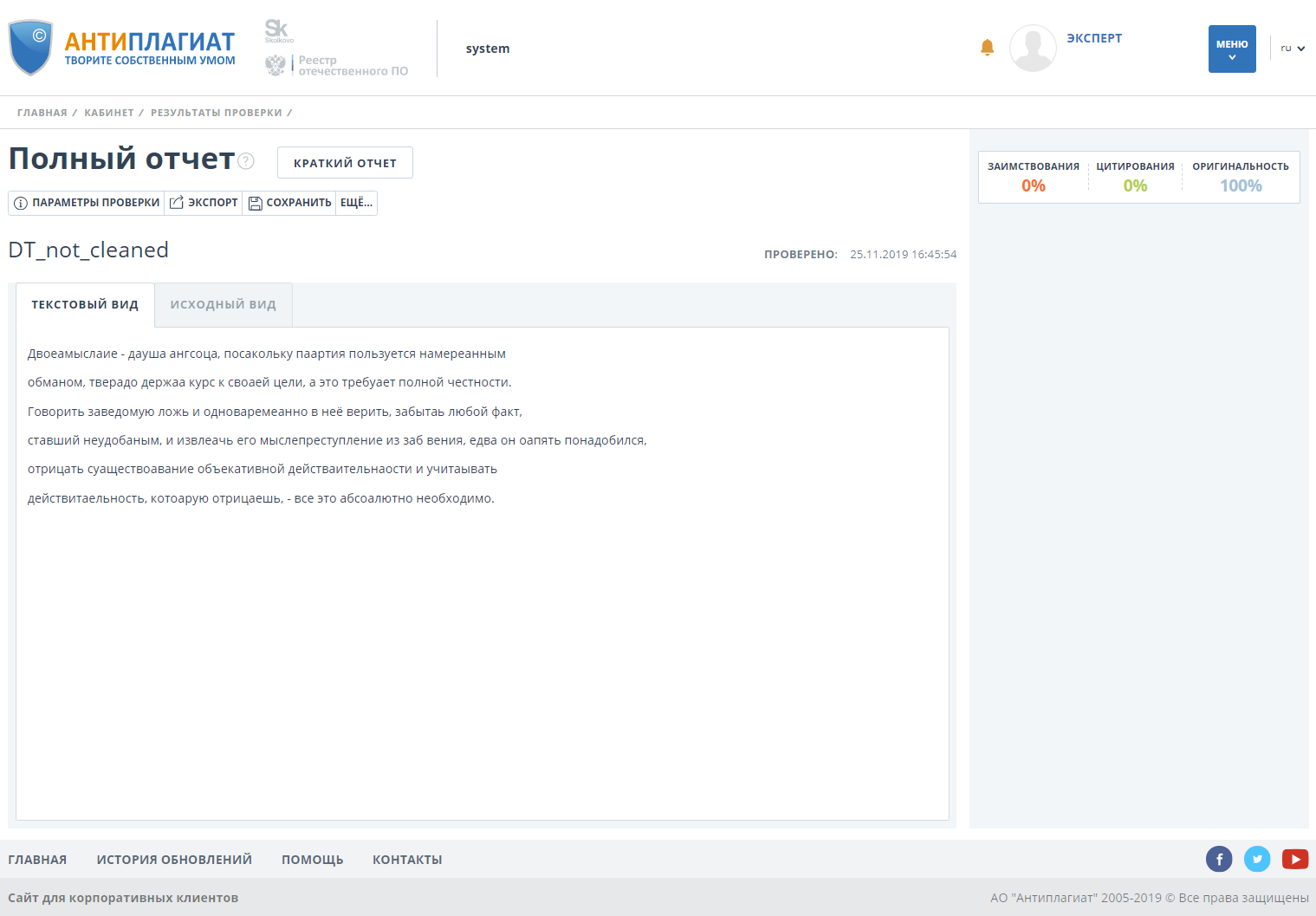
El documento tiene cien por ciento de originalidad.
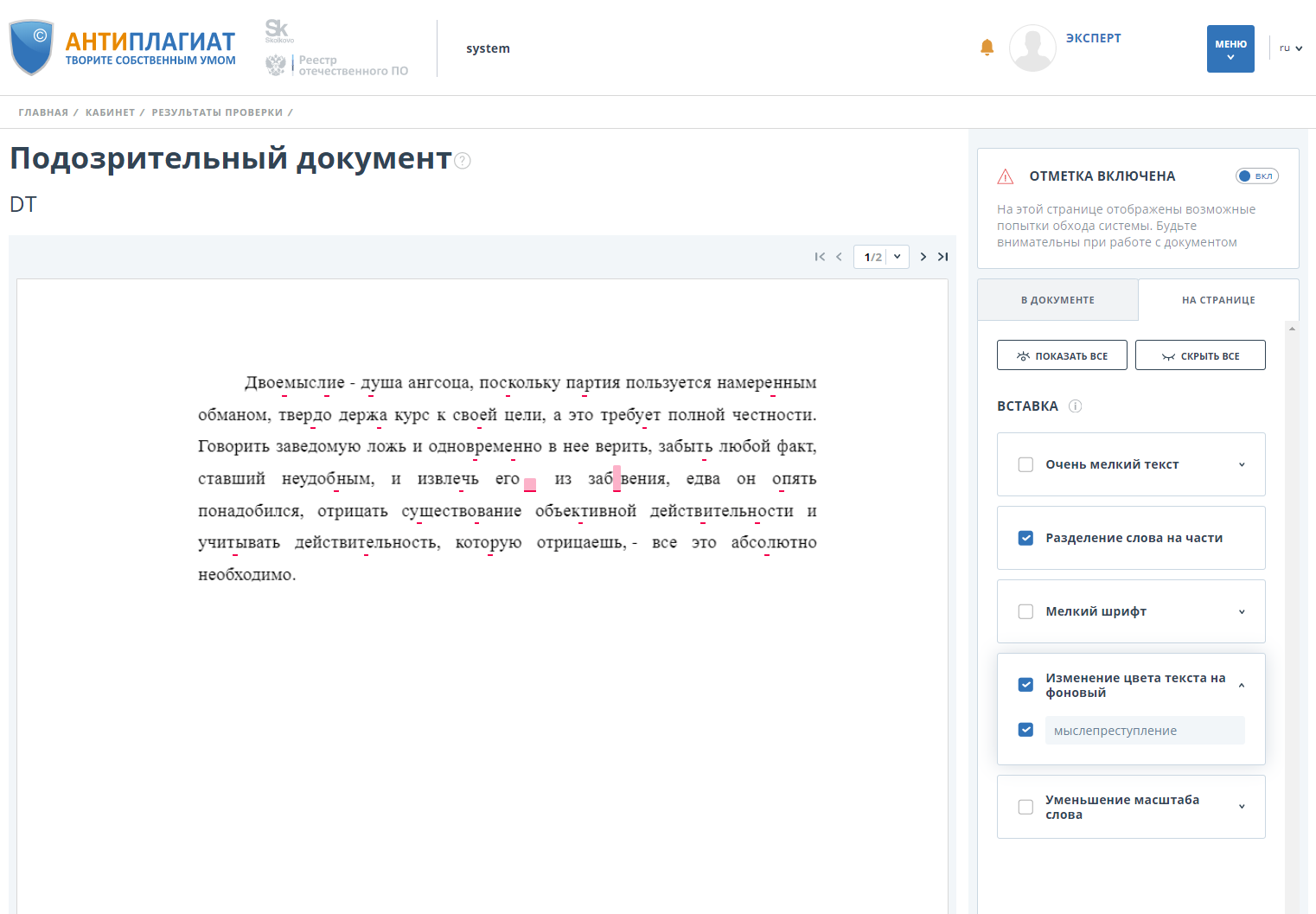
Verificamos el documento con la funcionalidad de detección de bypass activada y vemos que la originalidad cae a 0.

Además, el sistema marca el documento como "sospechoso" y muestra al usuario dónde y qué desvíos se detectaron:
Dado que el propósito de las soluciones técnicas es aumentar la originalidad de un documento, es interesante clasificarlas de acuerdo a cómo afectan la verificación del documento. Basado en el hecho de que el elemento principal de verificar un documento para pedir prestado son las palabras del documento, las soluciones pueden dividirse en los siguientes tipos según su efecto en las palabras extraídas del documento:
- Cambiar la palabra (la palabra en el texto extraído difiere de la palabra que se muestra en el documento fuente);
- Agregar una palabra (la palabra no está visible en el documento fuente, aparece en el texto extraído del documento);
- Eliminar una palabra (la palabra es visible en el documento fuente, no en el texto extraído del documento);
- Separación de palabras (en el documento original, la palabra se muestra normalmente, en el texto curado se divide en dos o más partes);
- Fusionar palabras (varias palabras se muestran en el documento fuente, se fusionan en una sola palabra en el texto extraído).
Veamos a qué soluciones nos enfrentamos. Comencemos por los simples y avancemos hacia los más interesantes.
Rastreos de texto
Las omisiones de este tipo no están vinculadas de ninguna manera con el formato del documento; cambian el valor de cadena de las palabras para que sigan pareciendo idénticas a las palabras originales.
Omoglifos
Una de las primeras soluciones que registramos fue reemplazar las letras con omoglifos, caracteres que son visualmente similares a las letras originales y tienen diferentes significados. Omoglyphia se ha utilizado desde los primeros días de la existencia del sistema antiplagio , y a pesar de que lo hemos atrapado durante mucho tiempo, todavía encontramos desvíos similares en el trabajo de los estudiantes.
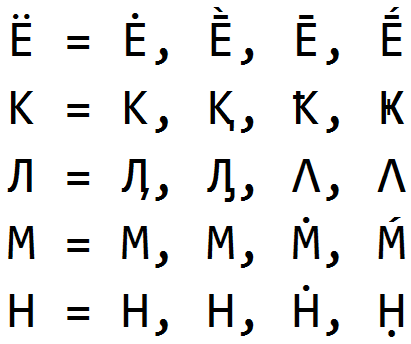
Los omoglifos son fáciles de encontrar y limpiar cuando se conoce el idioma de cada palabra. Podemos determinar con bastante precisión el idioma de cada palabra del texto, incluso cuando el texto contiene varios idiomas y una gran cantidad de "basura" (homoglifos y otros caracteres adicionales). Cómo es un tema para un artículo separado. Al tener la palabra idioma y una lista de posibles homoglifos para el idioma, restauramos las letras del idioma original y guardamos información sobre los homoglifos encontrados.
Caracteres no imprimibles
Otra forma de cambiar el valor de cadena de las palabras sin cambiar significativamente su visualización es usar caracteres Unicode invisibles o débilmente visibles. La inserción de tales caracteres en una palabra cambia el significado de la cadena de la palabra, mientras que prácticamente no cambia su visualización.
Muchos de estos personajes están en las categorías Unicode de "Otro, Control" y "Marca, sin espaciado" .
El sistema simplemente elimina estos caracteres y, cuando hay un gran número de ellos, notifica al usuario la sospecha del documento, mostrando caracteres borrados no imprimibles en el informe.
Soluciones de PDF
Como dijimos anteriormente , el formato clave para procesar documentos es pdf. Convertimos todos los demás tipos de documentos a pdf, de modo que la lógica básica de procesamiento de documentos nos hemos unificado para todos los formatos compatibles. Por lo tanto, las soluciones que se pueden implementar en documentos PDF son de particular interés para nosotros.
Texto pequeño
Una solución alternativa que uno de los primeros viene a la mente es hacer algo pequeño e invisible. El texto así obtenido no es visible cuando se visualiza el documento original, pero el sistema lo recupera. La implementación es muy simple: establezca el tamaño de fuente mínimo para el texto, cambie el color del texto. Capturar bypass de este tipo es igual de simple: simplemente verifique el tamaño de fuente del texto y las dimensiones geométricas de palabras individuales. Debido a su pequeño tamaño, los estudiantes a menudo agregan párrafos enteros de dicho texto oculto a la página:

Visualización de un intento de rastreo detectado:

Cambiar el color del texto a fondo
A pesar de que este método se usa a menudo en combinación con el anterior, su uso independiente es más interesante. El hecho es que para que detectemos y borremos el bypass, es suficiente determinar que al menos un parámetro de la palabra / símbolo tiene un valor "sospechoso". Y, si la definición de tamaños pequeños de una palabra es trivial, entonces la definición de texto cuyo color coincide con el fondo es un procedimiento más complicado.
La detección de un texto invisible se complica por las siguientes circunstancias:
- No siempre es posible obtener el color de un carácter específico de pdf;
- El fondo de la palabra puede no ser blanco. Además, la palabra puede estar en el fondo de la imagen;
- Las palabras y los símbolos pueden toparse entre sí.
Para eliminar las dos primeras dificultades, la "invisibilidad" del texto se determina analizando la imagen renderizada de la página del documento:
- Determine el área de la página que contiene la palabra;
- Calculamos la varianza de la región obtenida. Si la varianza está por debajo de cierto umbral: en el área analizada tenemos un color uniforme, no hay letras visibles. Por lo tanto, hay un intento de evitar el sistema.
Palabras y símbolos escondidos uno tras otro
Los caracteres invisibles no se pueden detectar analizando el área en la que se encuentran si estos caracteres están ocultos detrás de otros caracteres "visibles". Por lo tanto, para detectar dichos caracteres "ocultos", tenemos un procedimiento separado que analiza la intersección de las áreas de símbolos y marca aquellos caracteres que otros solapan en gran medida.

Bypass detectado:
Texto como imágenes
¿Qué sucederá si tomamos y reemplazamos parte del texto con imágenes que contienen este texto? Con la precisión adecuada, todo se verá como si nada hubiera cambiado en el documento, pero cuando extrae una capa de texto, naturalmente, las palabras de las imágenes no se extraerán. Para cerrar esta brecha, utilizamos el reconocimiento óptico de texto.
Soluciones alternativas con las funciones de conversión de docx a pdf
Convertir documentos a pdf no es una tarea trivial. Puede leer acerca de cómo elegimos la solución más adecuada para nosotros aquí . Desafortunadamente, incluso la mejor de las opciones que hemos analizado convierte imperfectamente documentos a pdf. Algunas "características" de conversión se utilizan activamente cuando se trata de evitar el sistema.
Fórmulas
Las fórmulas y otros objetos que contienen texto se "pierden" después de la conversión a pdf. Por lo tanto, puede intentar ocultar todo el párrafo del texto o, por ejemplo, cada segunda palabra del texto:

Al convertir a pdf, obtenemos el siguiente resultado:

Para detectar y limpiar esta y otras soluciones, agudizadas por las características de convertir docx a pdf, analizamos y limpiamos el archivo docx de origen. En particular, si se encuentra un número significativo de fórmulas en un documento, las reemplazamos con texto sin formato, que se guardará cuando el documento se convierta a pdf. Además, recordamos las posiciones de las fórmulas que procesamos y, si es necesario, informamos al usuario sobre la sospecha del documento que se está revisando y resaltamos el texto que restauramos a partir de las fórmulas.
Escala, pequeño espacio entre símbolos / línea
Al convertir a pdf, no se tienen en cuenta una serie de propiedades de texto: escala, intersímbolo y espacio entre líneas. Esto le permite agregar texto que es invisible en el documento fuente (por ejemplo, tiene una escala muy pequeña), que en pdf se convierte en un texto normal que no se destaca. Implementación de derivación (docx):

El resultado de la conversión a pdf (cambiamos el color nosotros mismos):

La única forma de atrapar este texto es encontrarlo en docx y guardar información al respecto. Si encontramos mucho de ese texto en el documento, marcamos el documento como sospechoso y le mostramos al usuario dónde encontramos texto con atributos sospechosos en el documento.
Romper una palabra en pedazos
Un caso especial interesante de aplicar las propiedades descritas en el párrafo anterior es agregar un espacio a la palabra y ocultarla. En el documento original, la palabra se verá normal, combinada, y después de convertir el documento a pdf se dividirá en dos partes, a medida que el espacio se vuelva de tamaño completo. Capturamos una finta similar con nuestros oídos de la misma manera que en el párrafo anterior. Implementación de derivación (docx):

El resultado de la conversión a pdf:

Visualización de un desvío de desvío:

Debajo del viejo castaño, a la luz del día, te traicioné, y tú a mí ...
Hablamos sobre lo básico, pero de ninguna manera todas las formas técnicas de implementar soluciones alternativas. Por supuesto, es poco probable que podamos hacer que la defensa sea absoluta. Sin embargo, estamos mejorando constantemente nuestro sistema, dejando cada vez menos oportunidades para "engañarlo". En la sesión, tratamos de cerrar las lagunas detectables especialmente rápidamente, a menudo desde el momento en que se descubre una brecha hasta que se cierra en el producto, solo pasan unos días. Es por eso que es un poco ridículo y, al mismo tiempo, triste leer las "promesas" publicitarias de las empresas que están listas para ayudar a los estudiantes a aumentar la originalidad de su trabajo y dar una garantía para su trabajo, a veces llegando a los 30 días. ¡Estudiante, serás traicionado! En el mejor de los casos, esta "garantía" puede devolverle el costo de los servicios de la compañía de rastreadores, pero no ayudará de ninguna manera con un diploma fallido y una posible expulsión de la universidad ...
¡Crea con tu propia mente!